
基于极端梯度提升算法的滑坡易发性评价模型
2022-09-30 04:26赵晓东徐振涛刘福杨华张泰丽
科学技术与工程 2022年23期
赵晓东 , 徐振涛 , 刘福 , 杨华 , 张泰丽
(1.大连大学建筑工程学院, 大连 116622; 2.中国地质调查局南京地质调查中心, 南京 210016 )
中国幅员辽阔,地质环境错综复杂,地质灾害发生的频度高、强度大,每年都会因此造成巨大损失[1-7]。目前,地质灾害(滑坡、崩塌、泥石流)已成为除地震外的第二大自然灾害[2-4]。其中,滑坡是几种破坏模式中危害最为突出、分布最为广泛的一种,在山区中为主要的地质灾害类型[5]。滑坡易发性评价用于预测滑坡可能发生的高危险区域,并最终绘制出关于研究区的地质灾害易发性分布图[4,6-7]。其主要目的是帮助决策部门制定土地利用规划,并为制订防灾减灾政策提供基础资料[6,8-9]。
现阶段的滑坡易发性分析模型一般分为物理模型、知识驱动模型和数据驱动模型三类[8,10]。其中,基于物理的模型分析结果虽然较为客观和准确,但是需要相当庞大的地质和水文数据,在特定边坡的易发性评估中更易发挥其效能[11];基于知识驱动的模型往往更依赖专家自身的经验和知识储备,容易受到主观因素的影响[12];目前,针对大规模的滑坡易发性快速分析,大多采用数据驱动模型[13-23]。而机器学习模型作为数据驱动模型中的主要分类,随着近年来人工智能的快速发展,已逐渐变成应用最普遍的滑坡易发性分析模型[13]。常见的机器学习模型主要包括决策树[14]、支持向量化[15-16]、随机森林[17-18]、逻辑回归[19]、人工神经网络[8,20]模型等。机器学习算法具有超强的自主学习能力,能充分挖掘出数据中各个特征属性之间存在的内在联系,不严重依赖于专家知识,并且能够重复执行目标结果[21]。XGBoost 是一种基于梯度提升决策树(gradient boosting decision tree,GBDT)的集成机器学习算法[24],已被逐渐应用于金融[25]、医学[26]和工业制造[27]等各个领域,且都取得了较好的效果。与传统的机器学习模型相比,XGBoost 具有更快速的计算能力和更强大的泛化能力[22-24]。由于XGBoost 发展历程较短,目前国内外鲜有对其在地质灾害领域的应用研究,值得进一步探索。
现依托于浙江飞云江流域地质灾害调查数据,选取了地形地貌、气象植被、岩土性质等地理信息数据,应用空间分析、表面分析、插值分析等地理信息技术提取并整理出学习样本数据,基于XGBoost构建滑坡易发模型,并与支持向量机(support vector machine,SVM) 模型进行对比,以期建立更为准确有效的地质灾害易发性评价模型。
1 研究区概况及数据
1.1 研究区概况
研究区玉壶流域位于浙江省温州市文成县境内,面积约99.5 km2,研究区位置及高程图见图1。文成县地处浙江省的东南部,飞云江的上游区域,总范围面积约1 296.44 km2,地理坐标为119°46′43″~120°15′09″E、27°34′01″~27°59′16″N。
该地区位于雁荡山和洞宫山之间,域内山岭绵延,地势自西北往东南呈梯形倾斜,地貌类型主要表现为丘陵和山地;区域山地植被覆盖度高,水系发达,雨季多暴雨和持续降雨,属于亚热带季风气候。大部分河谷和缓坡都被开垦为农业用地或住宅建设用地,山区分布人口较为分散;境内人工活动密集,山体稳定性较差,是地质灾害发生的易发区和多发区。
1.2 数据来源
本研究所使用的数据和数据来源见表1。地形数据采用美国国家航空航天局(National Aeronautics and Space Administration, NASA)全球数字高程数据中的30 m 数字高程模型(digital elevation model,DEM);岩土物理力学参数,如内摩擦角、黏聚力、风化层厚度,来自中国地质调查局“浙江飞云江流域地质灾害调查”项目。

图1 研究区位置及高程图Fig.1 The location and elevation map of the study area

表1 数据及数据来源Table 1 Data and source of data
1.3 滑坡影响因子
对于斜坡坡体,无论是自然生成的还是人工活动产生的,都不会静态不变。由于自然环境和人为干预,斜坡一直处于动态变化中。结合研究区域的特点以及相关数据的获取情况,选取了坡度、坡向、坡形、地表覆盖、极端小时降雨量、地形湿度指数、内摩擦角、黏聚力、容重、风化层厚度10 个地理信息因子。其中坡度、坡向和坡形属于地形地貌因子,极端小时降雨量、地表覆盖和地形湿度指数属于气象植被因子,内摩擦角、黏聚力、容重、风化层厚度属于岩土性质因子。影响因子的空间分布如图2所示。
1.3.1 地形地貌
坡度是斜坡稳定的先决要素,太低无法提供充足的下滑动力,太陡又不利于斜坡沉积物的堆积,两者都无法为滑坡提供物质基础。使用ArcGIS 软件Spatial Analyst Tools 下的表面分析工具计算出研究区的坡度,如图2(a)所示。
坡向与降雨以及太阳辐射情况密切相关,并对地表覆盖、地形湿度指数(topographic wetness index, TWI)等因子产生影响。利用GIS 工具生成坡向图,并依次划分为9 个方向,如图2(b)所示:平地(坡向值为-1,表示不具有下坡方向的平坦区域)、北(0°~22.5°,337.5°~360°)、东北(22.5°~67.5°)、东(67.5°~112.5°)、东南(112.5°~157.5°)、南(157.5°~202.5°)、西南(202.5°~247.5°)、西(247.5°~292.5°)、西北(292.5°~337.5°)。
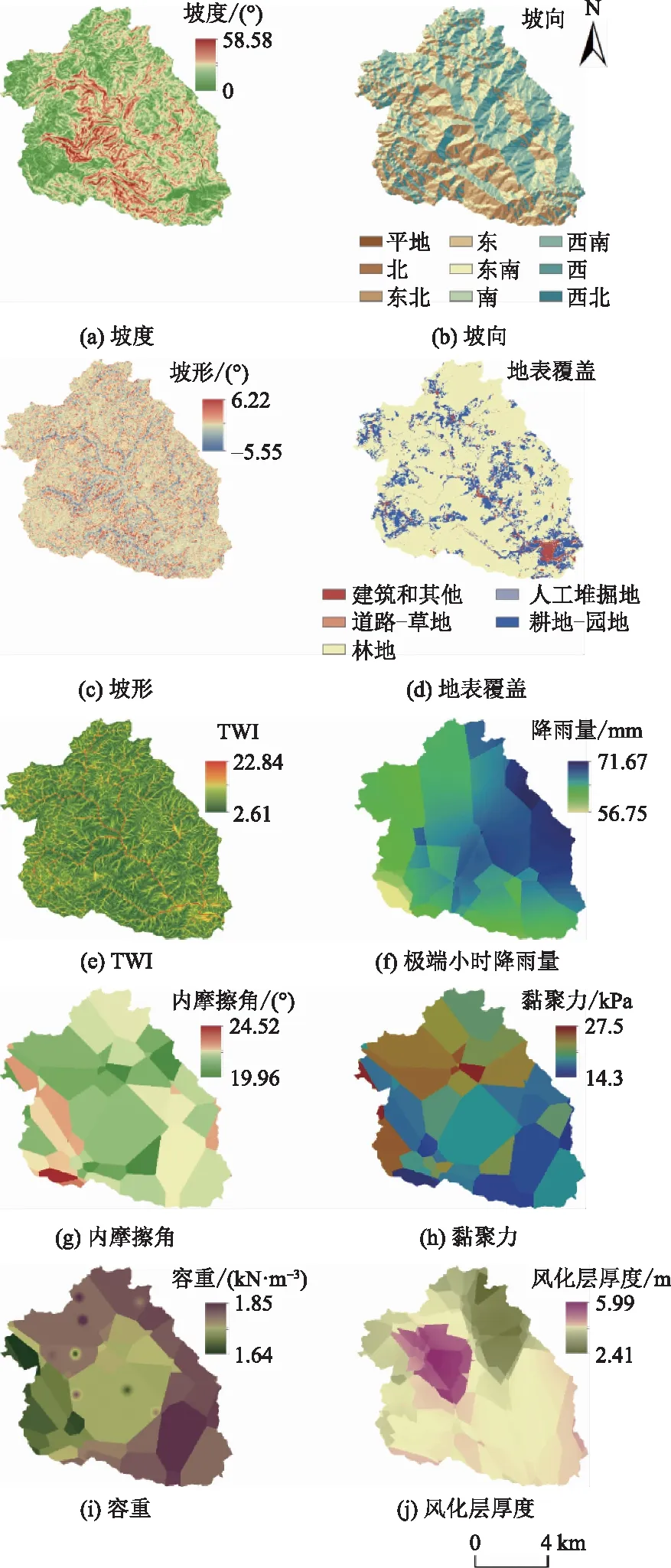
图2 影响因子的空间分布Fig.2 The spatial distribution of influence factors
坡形一般指剖面曲率,用于描述斜坡地形的复杂度,是沿最大坡降方向的斜率大小[28]。坡形数值越高,斜坡在垂直方向上的弯曲变化程度越高,地形越复杂。利用表面分析下的曲率工具计算出研究区坡形,如图2(c)所示。
1.3.2 气象植被
地表覆盖是影响滑坡产生的一个关键因子,区域较高的植被覆盖度,表明该区植被发育良好,对水土的保持能力强;区域较低的植被覆盖度,说明该区植被发育得一般,对水土的保持能力弱。结合国情普查数据,对不同地表覆盖单元,分别划分为建筑和其他、道路-草地、林地、人工堆掘地和耕地-园地五类,如图2(d)所示。
TWI反映土壤水分含量和地下水的分布情况,滑坡常在土壤湿度高的地区发生。利用水文工具下的填洼、流向和流量工具进行栅格计算生成TWI,如图2(e)所示。
极端降雨情况与滑坡的发生密切相关,是诱发滑坡灾害发生的一个重要因子。极端降雨作用下会使斜坡体变形在短时间内激增,造成坡体失稳,进而发生滑坡。根据温州市范围雨量站采集的数据,插值生成研究区内百年一遇小时降雨量作为极端小时降雨量数据,如图2(f)所示。
1.3.3 岩土性质
内摩擦角和黏聚力反映土或岩石内部的作用力,两者与坡体稳定呈正比,值越大坡体越稳定;容重表示土的压实效果,容重越大,表示土的密度越大,坡体越稳定;风化层越厚,地面下的疏松层越厚,坡体越不稳定。利用克里金法插值生成内摩擦角[图2(g)]、黏聚力[图2(h)]、容重[图2(i)]和风化层厚度[图2(j)]的栅格数据。
2 XGBoost评价模型
2.1 XGBoost模型基本原理
XGBoost 是一种基于树的集成算法,它把具有偏好的弱评估器(决策树)作为基学习器,并将其组合起来进行训练学习,由此得到一个集成的强评估器。XGBoost 是GBDT 的高效实现,不同于传统的 GBDT,XGBoost 算法使用Taylor 二阶展开式来优化损失函数,同时加入正则化项用于控制模型的复杂度。与其他机器学习算法相比,大大提高了其运算效力和泛化能力。
XGBoost 模型可以表示[22-25]为
(1)
其目标函数可表示为

(2)

(3)
(4)
进一步简化得到
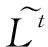
(5)
式中:Ij={i|q(xi)=j},表示ft(xi)这棵树中第j个叶节点的样本集合;γ和λ为预先设置的超参数。
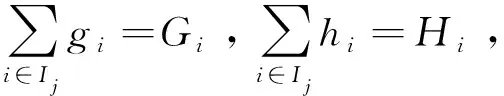
(6)
(7)
2.2 模型实现
利用ArcGIS 软件从数据源中提取致灾因子,并将其转为栅格数据(共110 894 个像元点)。在scikit-learn 机器学习框架下,基于Python 编程语言构建多分类XGBoost 滑坡易发性评价模型,并选取70%的数据作为训练集进行模型学习和训练。将得出的结果与SVM 模型进行比对,通过计算多分类混淆矩阵的评估指标来对模型精度进行分析,模型构建流程见图3。
2.3 模型验证
模型构建完成后,使用混淆矩阵对模型的精度进行检验。混淆矩阵是机器学习分类问题中应用广泛的评价指标体系,又名误差矩阵,是将算法性能可视化的一种特殊矩阵。评估指标包括准确率、精确率、召回率和F1等。其中,如果一个样本的真实类别和预测结果都为正,则为TP(true positive);如果真实类别和预测结果都为负,则为TN(true negative);如果负类样本预测为正,则为FP(false positive);如果正类样本预测为负,那么其为FN(false negative)。
精确率P表示预测值为正的样本中,与真实值相符的比例,计算公式为
(8)
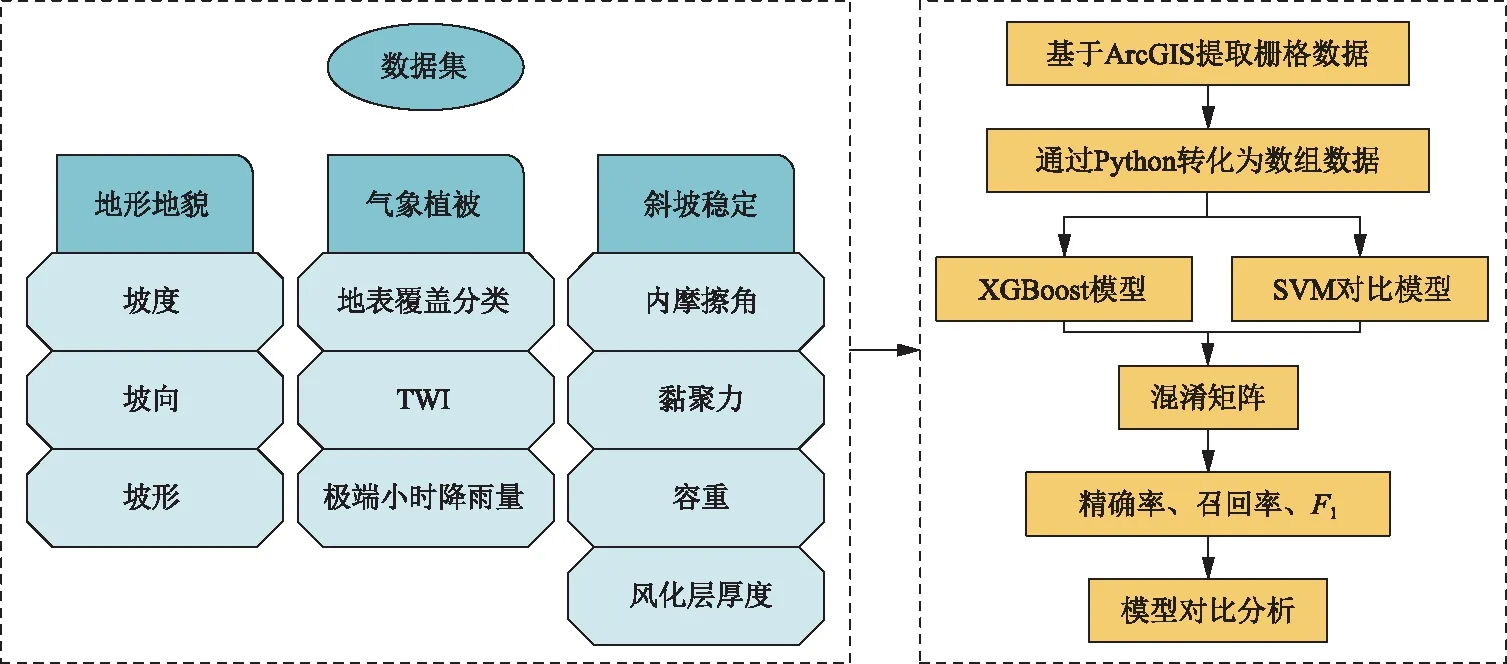
图3 模型构建流程图Fig.3 Model building flow chart
召回率R表示预测为正的样本在所有真实为正的样本中所占的比例,计算公式为
(9)
F1同时兼顾精确率和召回率,将两者的调和平均作为一个综合性指标来考量两者之间的平衡,计算公式为
(10)
3 模型评价与应用
3.1 模型的结果评价
对研究区的地质灾害易发性指数进行计算,所得结果采用自然断点分级法将其划分为极低易发、低易发、中易发、高易发、极高易发5 个等级,绘制出分类标签真值滑坡易发区划图[图4(a) ]。数据集按照7∶3 的比例分为训练数据和测试数据,分别输入XGBoost 、SVM 机器学习模型,对模型进行多次迭代的训练、测试、参数优化,最终根据全数据对模型进行验证,验证结果见表2。将验证结果通过ArcGIS 可视化处理,效果对比如图4所示。
从图4 可以看出,极高易发和高易发分区主要分布在河谷、低山区和丘陵地带。此区域内飞云江支流发育、地质环境较为脆弱,并且此区域多为人工堆掘地、耕地-园地,这间接反映了该地区频繁的人类活动,以及植被和斜坡遭到严重的人为破坏。而低易发区和极低易发分区,主要分布在海拔高于500 m以上的地区和人类住区,一是高海拔的地区远离水源河流,蓄水能力差,斜坡体的含水量较低,不利于滑坡发育;二是这些地区的人类活动较少,自然状态下受到的人类干扰较少。此外,人类聚居区域虽然海拔不高,但区内地势平坦、建筑林立,不具备滑坡发育的条件。

表2 各易发区分布及模型验证情况Table 2 Distribution of each susceptible area and model validation
3.2 精度对比
利用XGBoost 建立滑坡易发分区识别模型,模型对测试集识别的多分类混淆矩阵如表3所示。对于整个研究区,我们最为关注的是极高易发区的识别情况,3 661 组极高易发区数据中,被模型正确识别出来的栅格点有3 585 个,召回率为97.92%;模型识别的极高易发分区栅格点总数量为3 656 个,精确率为98.06%;F1为97.99%。
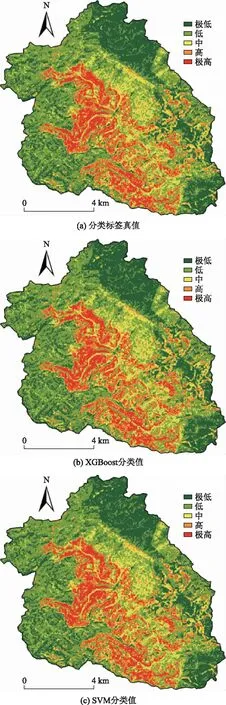
图4 模型预测结果对比Fig.4 Comparison of model prediction results
SVM 是以统计学习理论为发展基础的有监督学习方法,它能较好地解决非线性、高维模式识别问题,广泛应用于滑坡易发性评价研究中。为了比较对比XGBoost 算法与SVM 算法在滑坡易发分区识别模型中的精度,建立了基于SVM 的滑坡易发分区识别模型,用于识别测试集的多分类混淆矩阵如表4所示。3 661 组极高易发区数据中,被模型正确识别出来的栅格点有3 571 个,召回率为97.54%;模型识别的极高易发分区栅格点总数量为3 649 个,精确率为97.86%;F1分别为97.70%。
由于评价滑坡易发最重要的是将高易发区域尽可能的都识别出来,因而相较于精确率,召回率的重要性尤为显著。精度对比结果表明,基于XGBoost 的滑坡易发区识别模型在召回率和精确率评价指标上都略优于SVM ,XGBoost 算法模型在滑坡易发区识别中可以获得较高的精度。
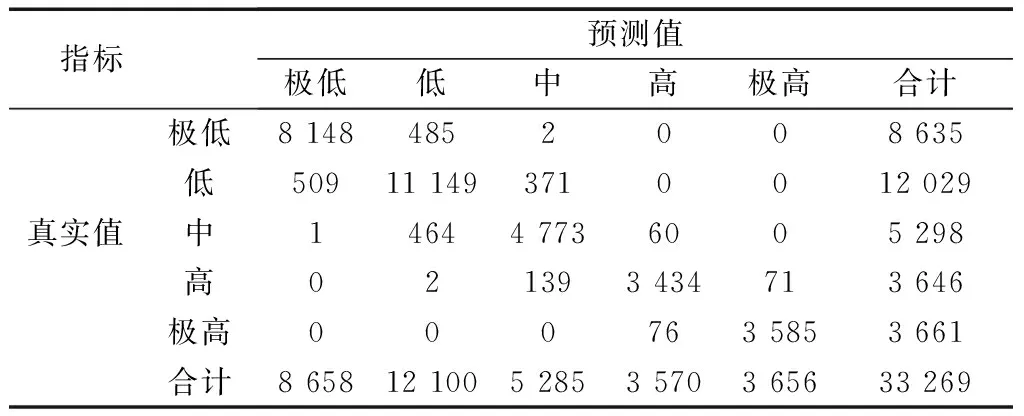
表3 基于XGBoost 的滑坡易发区识别混淆矩阵Table 3 Confusion matrix for landslide prone area identification based on XGBoost
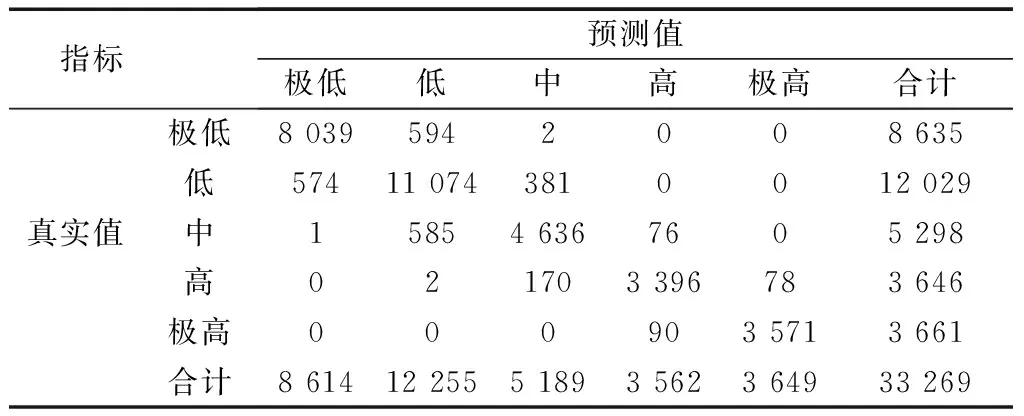
表4 基于SVM 的滑坡易发区识别混淆矩阵Table 4 Confusion matrix for landslide prone area identification based on SVM
4 结论
以浙江省温州市飞云江流域地质灾害的调查数据为依托,选取坡度、坡向、坡形、起伏度、极端降雨、地表覆盖、TWI 等地理信息因子,结合GIS 技术,建立基于XGBoost 的滑坡地质灾害易发性评价模型,对易发分区的多分类问题进行识别分析,得到以下结论。
(1)GIS 技术可以有效地对致灾因子进行提取、分析以及可视化展示,基于Python语言的机器学习模型有开源、模型库广泛,两者结合能极大提高模型建模的效率。
(2)使用浙江省温州市飞云江流域地质灾害数据,基于XGBoost 构建了滑坡易发多分类评价模型,将5 类1 维分类数组映射到2 维空间,生成秩为5 的分类矩阵,通过多分类混淆矩阵对模型精度进行评价。模型极高易发区的召回率和精确率达到了97.92%和98.06%,F1为97.99%,均高于SVM算法。
(3)由于不同地质和气候条件的影响,文中模型仅对飞云江流域滑坡较为有效,将模型应用于其他地区时,需要利用样本训练重新学习,以得到最优参数和最优模型。
猜你喜欢
地球科学与环境学报(2022年4期)2022-08-25
农业工程学报(2022年6期)2022-06-27
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
科海故事博览·中旬刊(2022年4期)2022-04-23
当代陕西(2019年9期)2019-05-20
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
