
用于单音音乐音高估计的密集扩张卷积残差网络
2022-09-28 09:17马文芳王天军谢永胜
东北师大学报(自然科学版) 2022年3期
马文芳,胡 英,王天军,谢永胜
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学信息检测和处理重点实验室,新疆 乌鲁木齐 830046;3.国网新疆电力有限公司,新疆 乌鲁木齐 830092)
0 引言
音高估计或基音频率估计对于音乐信息检索和语音分析研究领域中许多任务而言,是不可或缺的重要一步.如在音乐信号处理中,音高跟踪可用于多音轨数据集生成音高注释的方法[1],也是旋律提取系统的核心步骤[2-3].传统的基频(F0)估计器采用基于参数的信号处理方法,有基于时域处理的算法[4-5]、有基于频域处理的算法[6],或者两者兼而有之[7-8],然后使用后处理算法平滑基频轨迹,取得了较好的性能.然而,面对各类待处理音频并非总是如此有效地提取出基频,即使是像pYIN[5]这样性能较好的算法,对于具有挑战性的音频记录(如不常见的乐器声或波动非常快的音高曲线),也会产生嘈杂的结果.近几年,出现了各种基于神经网络的基频/音高估计方法.例如,RNN-BLSTM[9]使用PEFAC算法[10]提取男女两种混合语音信号的频域特征作为输入并建模两种音高轮廓.采用多种神经网络的数据驱动方法用于单音音高估计[11-13]和多音音高估计[14-15].Xu等[16]提出了一种基于神经网络的端到端回归模型,其中语音检测器和提出的F0估计器共同工作以突出音高轨迹.Ardaillon等[17]提出了一种用于语音音高估计的全卷积网络(Fully Convolutional Network,FCN)模型,该模型可以减少计算量,使其更适合于实时估计的目的.Dong等[18]提出了一种用于复调音乐中唱声基频提取的深度卷积残差网络.Gfeller等[19]提出了一种以自监督的方式进行训练的音高估计方法(SPICE).
为了解决梯度消失问题,He等[20]提出了一种具有恒等连接的残差神经网络(Residual Neural Network,ResNet).ResNet可以大大提高训练效率,减少由于跳跃连接和残差映射造成的模型退化.Huang等[21]提出密集连接卷积网络(Densely connected convolutional Network,DenseNet),为了保证网络模型中各个网络层之间的最大信息流动,将网络中所有层(特征图大小相同)进行拼接.与ResNet不同,在特征映射被传递到某一层之前,不是通过求和来融合特征;相反,是通过拼接来组合特征.Yu等[22]提出了一种扩张卷积网络模型,能够聚合多尺度的上下文信息,并且不损失分辨率.Singh等[23]提出了基于扩张因果时间卷积网络(Temporal Convolutional Network,TCN)单基频估计的DeepF0模型.挤压和激励网络(Squeeze-and-Excitation Networks,SENets)最早是由Hu等[24]提出来的,关注通道特征之间的关系.Dauphin等[25]在2017年首次提出了语言模型的门控机制.
受到DenseNet、ResNet的启发,本文提出一种基于CRN-Raw[18]结构的密集扩张卷积残差网络(DDCRN)单音音乐音高估计模型,其中残差模块中权重层采用卷积门控线性单元,每个残差模块的输出都送入通道注意力模块.
1 密集扩张卷积残差网络单音音乐音高估计模型
1.1 密集扩张卷积残差网络
图1是提出的用于单音音乐音高估计的DDCRN.该网络包括密集扩张卷积模块、3个残差模块和3个通道注意力模块.DDCRN直接对原始时域波形按帧为单位进行处理,获得每帧的估计音高.该网络的输入是1 024个时域音频采样点(帧长).将每一帧的样本归一化为零均值和单一方差后再送入DDCRN来获得一个360维的输出向量.图1中最下方F框表示密集扩张卷积(Dense Dilated Convolution,DDC)模块,扩张卷积的扩张因子d分别为1,2,4,8.将不同层的输出特征均按通道维度进行拼接.C和E框表示残差模块(Residual Module),这里采用卷积门控线性单元(Convolutional Gated Linear Unit,ConvGLU)替代单一标准卷积来提取特征.B和D框表示通道注意力模块(Channel-wise Attention Module),关注通道特征之间的相关性.最上方的A框表示全连接层.网络中不同模块数据计算公式为:
xDDC=fDDC(x0);
(1)
x1=f1(xDDC)+f2(f1(xDDC)),
xCA1=fCA(x1);
(2)
x2=f3(xCA1)+f4(f3(xCA1)),
xCA2=fCA(x2);
(3)
x3=f5(xCA2)+f6(f5(xCA2)),
xCA3=fCA(x3).
(4)
式中:x0是DDCRN的时域输入;xDDC是密集扩张卷积模块的输出;xi,i∈{1,2,3}是网络中3个残差模块的输出,其中i是网络中不同残差模块和通道注意力模块的索引,网络中3个通道注意力模块的输出进一步送入下一个残差模块;fCA表示网络中通道注意力操作,f1,f2,…,f6分别表示网络中6个ConvGLUs操作.xCA3是网络最终的输出.
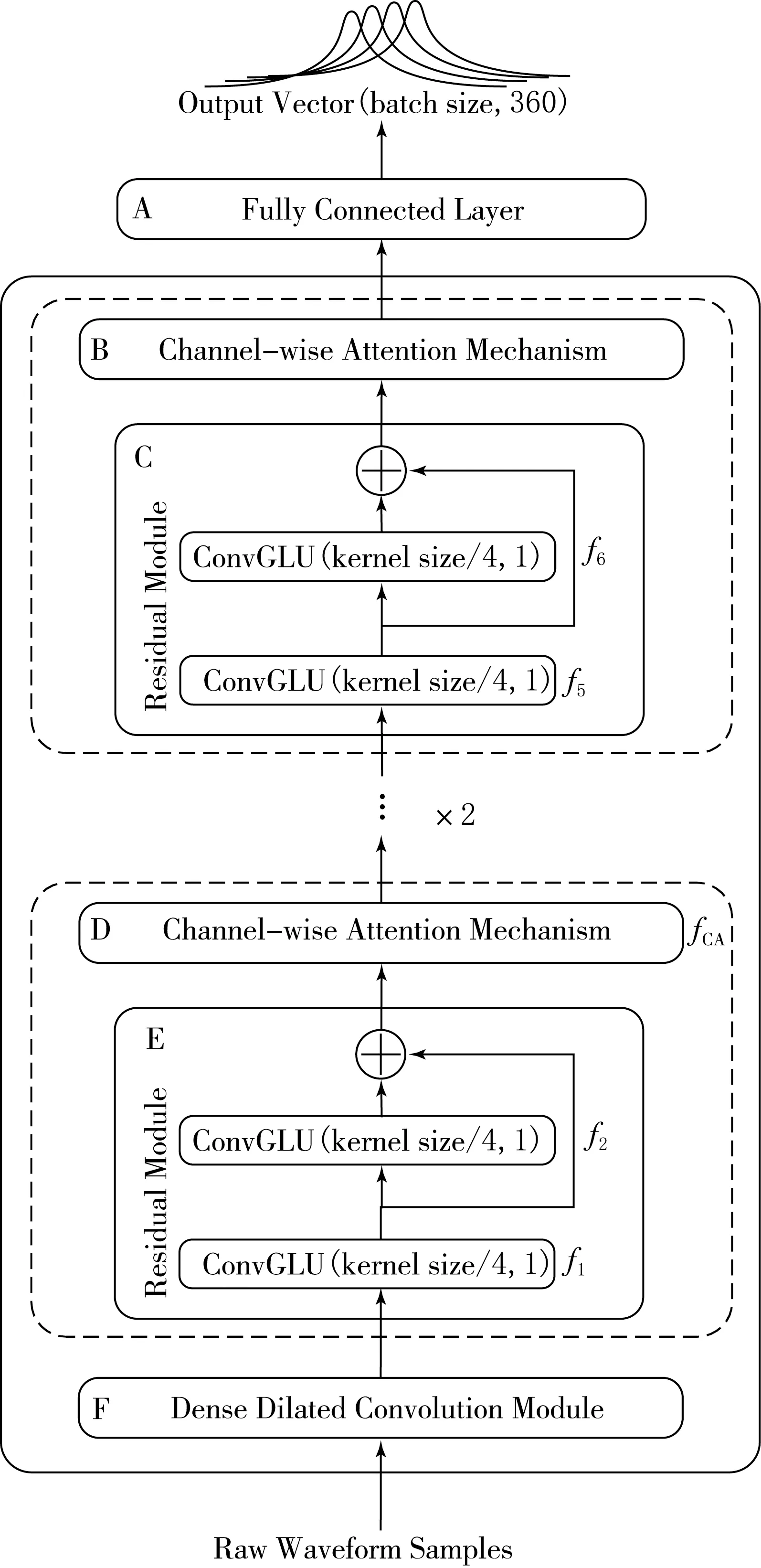
图1 密集扩张卷积残差网络
1.2 密集扩张卷积模块
对图1中DDC模块的详细框图如图2所示.在DDC模块中,所有以前的卷积层的输出特征均送入当前卷积层,而当前卷积层输出的特征又会送入后续的卷积层.这种将所有特征图相互拼接的连接方式可以在一定程度上缓解梯度消失问题,并且能够加强特征映射的传递,还可以重用这些特征.而扩张卷积则可以在不增加计算量和不丢失特征的前提下,增加卷积计算的感受野并系统地聚合多尺度上下文信息.图2中左上角的框表示整个网络的输入,即时域音频信号采样点.该图中前4个框分别表示扩张因子d为1,2,4,8,卷积核为64的一维卷积神经网络层(Conv1d),第5个框表示卷积核为1的标准一维卷积神经网络(Conv1d).第1个扩张卷积层的输出与其输入按通道维度进行拼接后作为第2个扩张卷积层的输入,以此类推.最后将4个扩张卷积层的输出特征与网络的初始输入进行拼接,再经过卷积核为1的标准一维卷积层来整合不同通道的特征.最后,将DDC模块的输出通过一个大小为4×1的平均池化层,对输出特征按照时间维度进行降维操作.DDC中第l层的输出xl接收了前面所有层的特征图,表示为
(5)
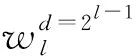

图2 密集扩张卷积模块
1.3 残差模块和通道注意力模块
图1中包含2个卷积门控线性单元和残差跳跃连接的残差模块(Residual Module),其框图如图3所示,其中ConvGLU是卷积门控线性单元.ConvGLU中有2个CNN,它们的卷积核大小(kernel size)、步长(stride)和池化大小(pooling size)都设置为相同的数值.ConvGLU下半部分的卷积学习特征图中每一个重要的特征元素并通过乘法操作重新加权每一个特征元素.图3中第一个ConvGLU(w,4)表示2个卷积操作的卷积核大小设为w、步长设为4,该ConvGLU不仅用于学习输入的特征,还用于对时域特征进行降维操作.第2个ConvGLU(w/4,1)表示包含的2个卷积操作中卷积核大小设为w/4(即为前一个卷积核大小的四分之一)、步长设置为1,因此该ConvGLU只用于学习特征而不改变输入数据的尺寸.将后一个ConvGLU模块的输入与其输出相加,构成残差跳跃连接.在跳跃连接中,信息可以直接从当前层向后传递到下一层,通过加法进行融合.跳跃连接可以避免梯度消失以提高训练的有效性.
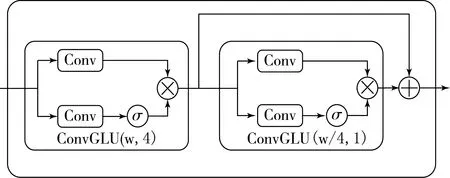
图3 残差模块

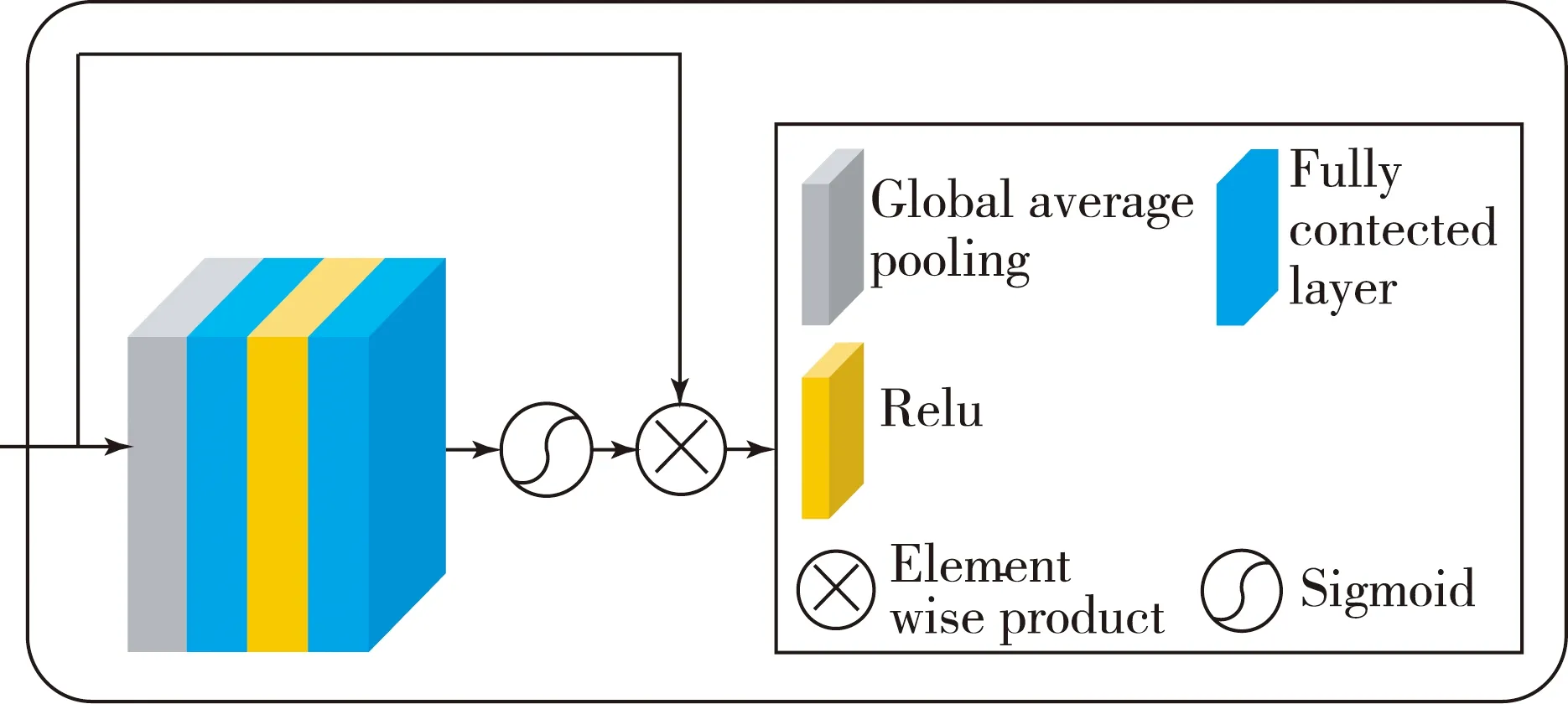
图4 通道注意力模块
2 实验数据和网络参数
本文提出的密集扩张卷积残差网络的单音音乐音高估计模型,分别在iKala[26]、MDB-stem-synth[27]和MIR-1K[28]3个数据集上进行训练.iKala数据集包含252个歌曲片段,每一条音乐的长度都是30 s,采样频率为44 100 Hz.音乐伴奏和歌唱声音分别在左右声道录制.MDB-stem-synth是来自MedleyDB的230个单音音频片段的集合,它使用分析/合成方法[27]生成合成音频,并提供完美的F0注释,以保持原始音频的音色和动态跟踪.该数据集包含230个曲目,25个乐器,总时长为15.56 h.MIR-1K数据集是中文流行歌曲数据集,包含1 000首歌曲剪辑,分别在左声道和右声道录制音乐伴奏和唱声,总长度为133 min.本文仅用iKala和MIR-1K的唱声为样本进行训练.对3个数据集进行了相同的处理.首先,原始音频样本被重新采样到16 kHz.音高估计网络的输入是1 024个采样点(帧长).对数据集做分帧处理,采用的帧移(hop size)分别为160(MDB-stem-synth、MIR-1K)和512(iKala).其次,所有帧样本都被归一化为零均值和单一方差后再送入网络中.
本文采用二进制交叉熵损失函数,ADAM[29]优化器,初始学习率设为0.000 1.每个卷积层之后进行ReLU激活和批规一化(BN),批大小(batch size)为512.DDCRN的输入是原始时域波形,输出属于每个可能音高类的基频概率向量.输出的360个点对应一个特定的音高值,以音分定义.音分是相对于参考音高fref(Hz)的音程单位,定义频率f(Hz)的函数为
(6)

(7)
(8)
按照文献[14]中的设置,为了减轻对接近正确预测的惩罚,目标在频率上是高斯模糊的,以标准差为25音分围绕真实频率能量衰减为
(9)
这样,360维的输出中,高的激活表明输入信号的音高可能接近与高激活节点相关联的音高.
3 实验结果及分析
本文提出一种用于单音音乐音高估计的密集扩张卷积残差网络.同时在iKala、MDB-stem-synth和MIR-1K 3个数据集上验证了残差网络、注意力残差网络、注意力门控残差网络和密集扩张卷积残差网络的评价指标.还探讨了前3种模块中通道数的设置对网络参数量及其性能的影响.根据实验评价指标可知,密集扩张卷积残差网络性能最佳.
3.1 两种通道数设置的各种残差网络性能对比
在iKala、MDB-stem-synth和MIR-1K数据集上分别训练两种通道数设置的不同残差网络.RN表示只包含4个标准卷积残差模块的残差网络,卷积残差模块是由两个一维卷积和一个残差跳跃连接构成,前一个CNN层在学习特征的同时还用于对时间维度特征进行降采样,后一个CNN层则只学习特征并保持数据维度不变,将两个CNN层的输出相加后送入下一个卷积残差模块.+SE表示RN中4个卷积残差模块的输出分别送入4个相同的通道注意力模块的注意力残差网络.+SE+GLU表示在+SE网络的基础上,应用卷积门控线性单元(ConvGLU)替代残差模块中标准卷积的注意力门控残差网络.+SE+GLU+DDC代表的是用DDC模块替代+SE+GLU中的第一个残差模块和第一个通道注意力模块的密集扩张卷积残差网络(DDCRN).这4种网络的输入均是归一化为零均值和单一方差后的帧级时域波形.注意力门控残差网络(+SE+GLU)中包含8个ConvGLU层,每一个ConvGLU层中的卷积核大小、步长以及神经元的个数均如表1所示,表1列出了两种通道数设置:输出_s和输出_t,s和t分别是small和tiny的缩写.本文探讨这两种不同的通道数设置思想来源于CREPE_s、CREPE_t[13].
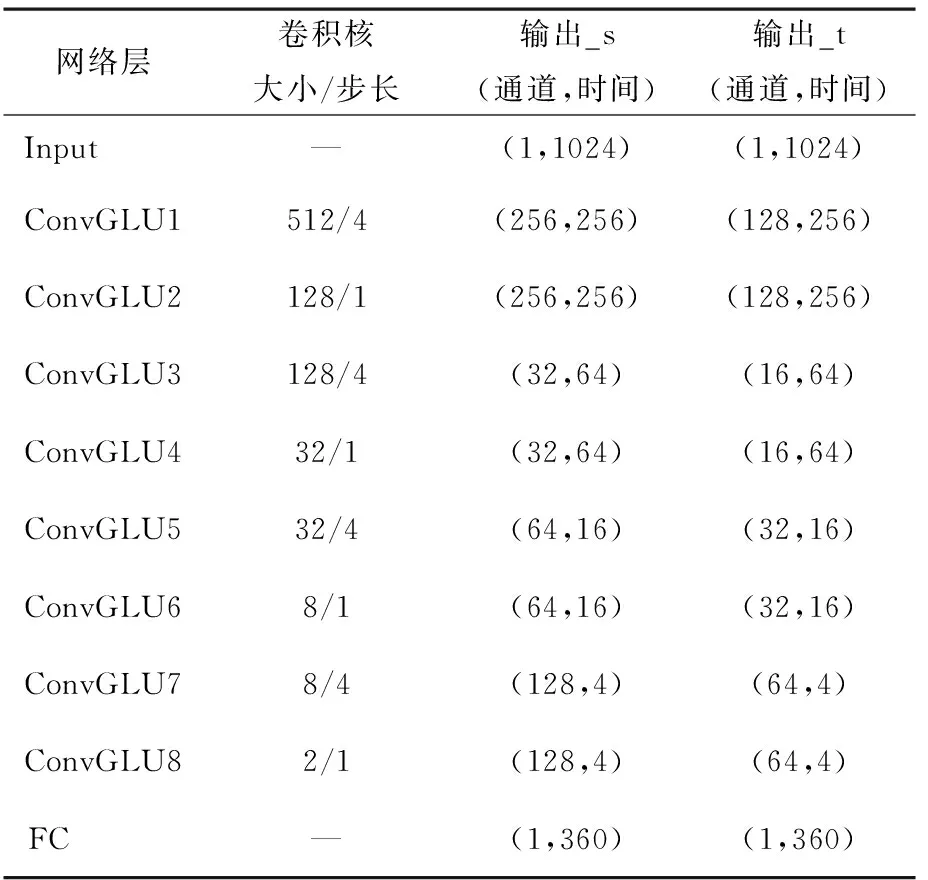
表1 注意力门控残差网络中的参数
原始音高准确率(Raw Pitch Accuracy,RPA)指估计的音高值在真实标签的±1/4音调(50音分)以内的浊音帧所占的比例.原始色度准确率(Raw Chroma Accuracy,RCA)是指估计的音高值和真实标签均映射到同一个八度音后,估计音高值在真实标签的50音分以内的浊音帧所占的比例.它给出了忽略倍频程误差的情况下测量音高准确率的方法.表2列出iKala数据集上不同残差网络的音高估计评价指标.表3显示MDB-stem-synth数据集上不同残差网络的评价指标.表4显示的是表2和3中所有这些网络在MIIR-1K数据集上的评价指标.
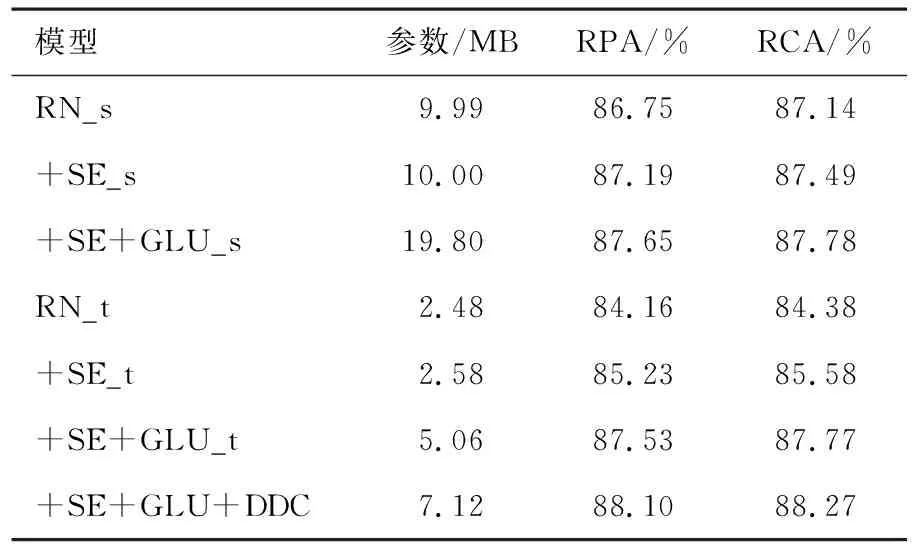
表2 iKala数据集上不同残差网络的评价指标

表3 MDB-stem-synth数据集上不同残差网络的评价指标
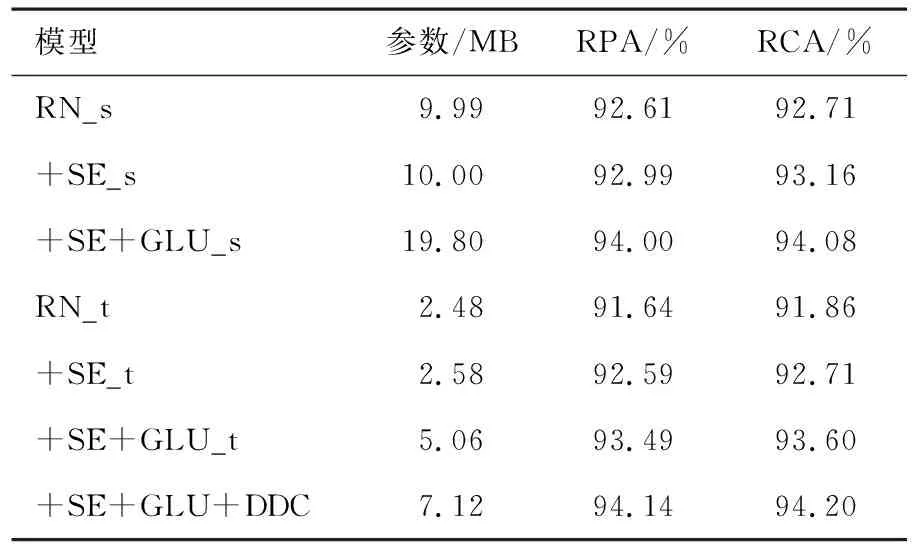
表4 MIR-1K数据集上不同残差网络的评价指标
从表2-4中的消融实验结果可以看出,在3个不同的数据集上不同网络的评价指标不同.在这3个数据集以及两组不同的通道数设置下,+SE、+SE+GLU的评价指标均高于RN.由上述3个表中的评价指标可以看出,RN_s、RN_t的评价指标依次降低,参数也依次降低.本文探究音高估计性能较好的情况下,降低模型的参数.从表2—4中还可以看出RN_s、+SE_s和+SE+GLU_s的参数大约是RN_t、+SE_t和+SE+GLU_t参数的4倍,但性能相差不大.从表2—4中还可以看出,RN、+SE、+SE+GLU、+SE+GLU+DDC的性能逐渐增加.在3个数据集上,+SE+GLU+DDC的参数较小且性能最佳.
在iKala数据集上,可以看出通道注意力模块会少量增加网络的参数,但提升了网络的性能.+SE+GLU_t比+SE_t和RN_t分别高2.30%,3.37%(RPA)和2.19%,3.39%(RCA).+SE+GLU+DDC的结果比RN_t、+SE_t和+SE+GLU_t分别高3.94%,2.87%,0.57%(RPA)和3.89%,2.69%,0.50%(RCA).在MDB-stem-synth数据集上,+SE_s的性能优于RN_s,而+SE+GLU_s比+SE_s和RN_s分别高2.67%,3.24%(RPA)和1.75%,2.80%(RCA).+SE+GLU+DDC的结果比RN_t、+SE_t和+SE+GLU_t分别高7.68%,6.27%,1.85%(RPA)和6.02%,5.29%,1.47%(RCA).在MIR-1K数据集上,可以看出+SE+GLU_s的评价指标比+SE_s、RN_s分别高1.01%,1.39%(RPA)和0.92%,1.37%(RCA).+SE+GLU+DDC的结果比RN_t、+SE_t和+SE+GLU_t分别高2.50%,1.55%,0.65%(RPA)和2.34%,1.49%,0.60%(RCA),由此可知在3种数据集上,密集扩张卷积残差网络参数较小并且性能最佳.
3.2 与其他算法对比
实验中,提出的DDCRN模型还与pYIN[5]、SWIPE[6]、CREPE[13]和SPICE[19]算法进行了对比.pYIN和SWIPE是经典的传统音高估计算法,CREPE是深度卷积神经网络音高估计算法,SPICE是基于自监督训练的神经网络音高估计算法.MIR-1K数据集上不同方法的评价指标见表5.SWIPE的结果来自文献[23].CREPE的结果是将该网络只在MIR-1K数据集上进行训练并测试得到的结果.在文献[19]中,只报道了RPA的值,而没有RCA的值.根据实验结果可知,DDCRN在RPA上的平均得分分别比SWIPE、CREPE和SPICE高5.41%,1.10%和3.54%,在RCA上的值比SWIPE和CREPE高4.96%和1.03%.

表5 MIR-1K数据集上不同方法的评价指标
MDB-stem-synth数据集上不同方法的评价指标见表6.pYIN和SWIPE的结果来自于文献[13].CREPE的评价指标是在MDB-stem-synth数据集上重新训练和测试得到的.在文献[19]中,只报道了MDB-stem-synth数据集上的RPA的值,而没有RCA的值.根据不同方法的评价指标,可以看到DDCRN在RPA上的值比pYIN、SWIPE、CREPE和SPICE高0.71%,0.11%,5.06%和3.51%,在RCA上的值比CREPE高3.33%.

表6 MDB-stem-synth数据集上不同方法的评价指标
分别绘制了DDCRN模型对iKala和MIR-1K数据集中的一个片段估计的音高轮廓及其对数频谱,并将它们与标签进行对比.iKala数据集的音高标签是以半音为单位,任选iKala数据集中的一条语音45422_verse.wav,绘制其中10 s的语音波形,频谱及标签和估计的音高如图5所示.
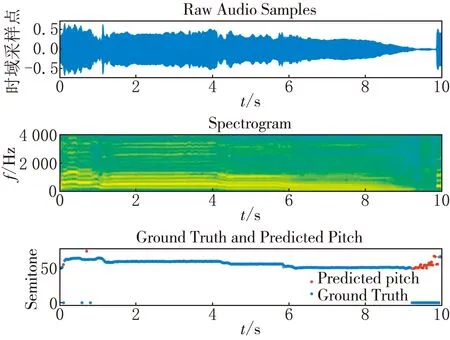
图5 iKala数据集中音乐片段的时域波形、 频谱以及标签和预测音高的对比
DDCRN估计的MIR-1K数据集中的一个片段的音高轮廓及其对数频谱见图6,并将它们与标签进行了对比.
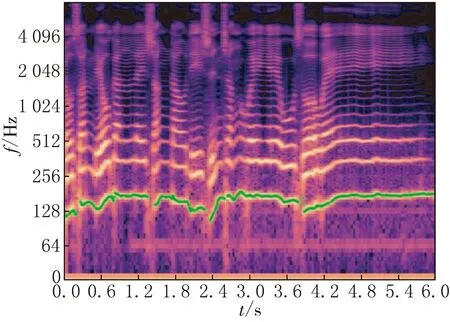
(a)在对数频率谱上绘制真实音高轮廓
4 结束语
本文提出了一种用于单音音乐音高估计的DDCRN,直接对帧级时域波形进行处理.探讨了残差网络(RN)、注意力残差网络(+SE)和注意力门控残差网络(+SE+GLU)在两种不同的通道数设置下的模型大小和评价指标.分别在iKala、MIR-1K和MDB-stem-synth数据集上训练上述残差网络,并且将DDCRN与RN、+SE、+SE+GLU进行了对比,可知DDCRN在3个数据集上的性能最好.然后将DDCRN与已报道的4种算法进行对比.根据实验结果,可以得出以下结论:(1)tiny通道数设置的网络参数量是small通道数设置参数量的1/4,且音高估计性能相差不大.(2)在3个数据集上,DDCRN的性能均优于RN、+SE、+SE+GLU.(3)DDCRN与现有算法进行对比,可以看到在MDB-stem-synth数据集上,本文提出的DDCRN的评价指标优于pYIN、SWIPE、CREPE和SPICE.在MIR-1K数据集上,DDCRN的评价指标优于SWIPE和SPICE.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
乐府新声(2021年1期)2021-05-21
北京航空航天大学学报(2020年10期)2020-11-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
自动化学报(2019年6期)2019-07-23
计算机应用(2018年8期)2018-10-16
乐府新声(2017年1期)2017-05-17
学与玩(2017年5期)2017-02-16
