
基于BBCM-TextRank的文本摘要提取算法研究
2022-09-28 09:17王名扬周文远
东北师大学报(自然科学版) 2022年3期
井 钰,王名扬,周文远
(东北林业大学信息与计算机工程学院,黑龙江 哈尔滨 150036)
0 引言
文本摘要是对文本进行处理从而生成简洁、精炼的内容,可以帮助读者快速理解文本的中心内容.现有文本摘要方法可以分为生成式(abstractive)摘要[1]和抽取式(extractive)摘要[2]两大类,前者通过归纳文本整体语义来生成具有概括性信息的摘要;后者则是从原文中抽取与中心思想相近的一些句子作为摘要.抽取式摘要从方法上可以划分为基于统计特征方法[3-4]、基于主题模型方法[5-6]、基于图模型方法[7-8]和基于机器学习方法[9-10]等.其中,基于图模型方法的图排序算法因其充分考虑文本图的全局信息,且不需要人工标注训练集的特性,被广泛应用于文本摘要领域[11].
TextRank算法作为一种经典的文本图排序算法,利用文本自身信息和结构特征来获取文本摘要.2004年,Mihalcea等[7]借鉴PageRank算法思路提出了TextRank算法,该算法将句子间的相似关系看成是一种推荐或投票关系,据此构建TextRank网络图,并通过迭代计算得到句子的权重值.自TextRank算法被提出以来,基于该算法的自动文本摘要的研究受到广泛的关注.考虑到关键词对文本摘要提取的重大作用,李峰等[12]基于TextRank并使用关键词扩展来提取文本摘要.汪旭祥等[13]结合了文本中句子位置、关键词覆盖率以及线索词等因素提出SW-TextRank算法来提取文本摘要.但上述工作主要通过TF-IDF对关键词进行统计,该方法只以关键词在语料库中的分布作为权值,结构过于单一,无法充分提取文本中的重要信息[14].
近年来,利用深度学习的方法进行命名实体识别引起了研究者的关注.考虑到文本中时间、地点、人物等实体对句子语义理解的重要性,如果能获取到文本中的这些关键实体,则能更加准确的衡量句子的重要性,从而获得更能反映文本核心内容的摘要.Huang 等[15]人通过双向长短时记忆神经网络(BiLSTM)获得能够体现文本上下文信息的语义向量,然后利用条件随机场(CRF)[16]对BiLSTM输出的数据进行解码,该模型在CoNLL2003英文数据集上获得较好的效果.类似的,廉龙颖[17]将BiLSTM-CRF应用在网络空间安全领域实体识别中,李健龙等[18]将BiLSTM-CRF应用到军事命名实体识别上,均取得不错的效果.但中文存在字与词的区别,基于词特征抽取的BiLSTM-CRF模型实体识别效果受到分词效果的限制,无法有效表征一词多义的现象,因而实体识别性能有待进一步提高.Devlin等[19]提出基于双向Transformer编码的BERT模型,该模型通过超大数据、巨大模型和极大计算,能够捕捉到任意字符间的语义关系特征,可以更好地表征不同语境中的语义信息.
最大边际相关算法(MMR)也被用在摘要抽取的任务中,该算法最初用来查询目标文本和被搜索文档之间的相似度,然后据此对文档进行排序.Carbonell 等[20]将MMR作为一种反冗余措施应用到文本摘要领域,并在TREC主题相关新闻数据集中证明了其去除冗余的有效性.王亚卓[21]将MMR应用于计算机行业专利文本摘要冗余处理,进一步证明了MMR可以有效降低文档摘要的内容冗余,对于提升文档摘要的全面性起到充分的支持作用.
考虑到关键实体在摘要抽取中的作用,以及摘要抽取任务对降低摘要冗余度的要求,本文提出一个集成的BBCM-TextRank(BERT-BiLSTM-CRF-TextRank-MMR)算法,拟在充分考察文本中的实体特征的基础上,从文本中抽取能较好概括文本中心主题且具有较低冗余度的摘要.其中,在命名实体识别过程中,拟采用BERT-BiLSTM-CRF框架,利用BERT预训练模型生成字符的表示向量,利用BiLSTM-CRF架构在字符向量基础上完成文本的命名实体识别.在摘要抽取过程中,基于Word2Vec词向量得到句子特征向量;利用TextRank算法得到每个句子的权重值,并结合BERT-BiLSTM-CRF框架识别出的实体对句子的权重做进一步优化;结合句子权重和MMR算法对句子进行冗余处理,保留权重值较大的句子作为文本候选摘要;最后按文本原顺序排列句子并输出摘要.本文算法的具体流程如图1所示.

图1 BBCM-TextRank抽取摘要流程
1 基于BBCM-TextRank的文本摘要提取算法
1.1 TextRank
1.1.1 TextRank算法
TextRank是一种用于文本的基于图排序的无监督方法.TextRank算法将文本中的句子作为文本网络图的节点,句子间的相似度作为节点之间的权重值,从而构建出一个无向有权图.通过对文本网络图的迭代计算完成对文本中句子重要性的排序,选出重要性最高的几个句子作为文本摘要.
TextRank算法的文本网络图可表示为一个无向有权图G=(V,W),其中V为节点的集合,W为各边上权重的集合,假设V={V1,V2,…,Vn},则记W={wij|1≤i≤n,1≤j≤n},其中wij为节点Vi与Vj间边的权重值.
对于一个包含n个句子的文本D,记D={S1,S2,…,Sn}.TextRank算法一般将句子抽象成节点V,即Vi=Si,句子之间的相似度抽象为节点之间的权重值W,即wij=similarity(Si,Sj),进而得到一个n×n的相似度矩阵Sn×n,公式为
根据G和Sn×n可计算出每个节点的权重值,公式为
(1)
其中:Score(Vi)为节点Vi的权重;wji为图中节点Vj到Vi的边的权值;d为阻尼系数,表示从当前节点指向其他任意节点的可能性;In(Vi)和Out(Vj)分别为指向节点Vi的节点集合和从节点Vj出发的边指向的节点集合.
则基于TextRank算法的文档D中句子Si的权重值为
(2)
1.1.2 句子相似度计算
TextRank算法构建的文本网络图中,句子的权重取决于句子之间的相似度.因此,摘要提取的关键在于如何准确衡量句子之间的相似度.Word2Vec[15]基于大规模语料学习向量之间的相似性表示,可以更加准确地表征词语之间的语义关系.
句子是由词语组合而成,故句子向量可以用词向量相加求平均表示,公式为
(3)
其中:Vecs表示句子s的向量,w为s中的词语,Cs为s中的词语的数量.
句子之间的相似度通过两个句子在向量空间中的余弦相似度衡量,公式为
(4)
其中:cos(Vecsi,Vecsj)表示句子向量Vecsi和Vecsj之间的余弦相似度,n为句子向量的维数,Vecsik为Vecsi向量第k维的值.
1.2 基于BERT-BiLSTM-CRF的命名实体识别
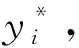

图2 基于BERT-BiLSTM-CRF的命名实体识别流程
1.2.1 BERT预训练语言模型
BERT模型是通过超大语料数据、基于巨大模型和消耗大规模算力训练出的能够充分表达文本语义特征的预训练模型.如图3所示,BERT模型采用了双向多层Transformer结构,该结构可以反映任意位置上两个字之间的相关程度,从而使输出的各个字向量都充分融合了上下文的信息,有效解决了一词多义的问题.

图3 BERT模型结构
Transformer的每个编码单元由多头自注意力机制层(Multi-Head Self-Attention)、全连接层(FeedForward)、残差连接和归一化层(Add&Normal)组成.如图4所示,输入字向量经过多头自注意力层获得反映与当前文本中各个字向量之间关系的增强语义向量;利用残差网络避免深层网络条件下性能退化问题,通过归一化将各输入特征转化成均值为0方差为1的数据;全连接层引入非线性激活函数ReLu,通过变换输出向量的空间来增加模型的表现能力.

图4 Transformer编码单元结构
Encoder的关键模块是Multi-Head Self-Attention,其中Self-Attention研究的是句子中的每个字和句子中各个字之间的关系,Head指的是某个特定语义空间,Multi-Head即是多个语义空间.具体过程如下:
首先计算出当前字和句子之间的注意力向量:
(5)
其中:Q是当前字的向量;K是文本中各个字的向量;V是各个字的原始向量;dk是缩放因子,作用是缩小QKT的点乘结果,使模型的梯度更稳定.
则不同头下的Attention向量为
(6)

可以得出,Multi-Head Self-Attention将句子置于不同语义空间下做Self-Attention计算并将结果进行拼接,再通过一次线性变换将拼接结果转换成和原始向量维度相同的多头自注意力向量,从而得到每个字的增强语义向量.
MultiHead(Q,K,V)=Concat(head1,head2,…,headn)W0.
(7)
其中W0是附加权重.
1.2.2 BiLSTM
LSTM[16]是一种可以有效利用文本数据中时序信息,且不具备梯度消失缺陷的改进型RNN.如图5所示,LSTM由输入门、输出门、遗忘门3个控制单元和一个记忆单元构成.输入门决定什么样的信息会被保留,遗忘门决定什么样的信息会被遗弃,输出门决定有多少信息可以输出,记忆单元则是对信息进行管理和保存.通过LSTM单元中3个门的参数可以有效管理记忆单元中的信息,使得有用的信息经过较长的序列也能存储在记忆单元中.

图5 LSTM单元结构

(8)
其中:σ是激活函数sigmoid,tanh是双曲正切激活函数,W和b分别代表门的权重矩阵和偏置向量.
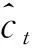
(9)
进而结合输出门ot和当前的细胞状态ct计算出当前隐层状态ht.
ot=σ(Wo·[ht-1,xt]+bo),ht=ot*tanh(ct).
(10)
LSTM仅存储了当前文本的上文信息,而下文信息对于NER任务也有非常重要的参考意义.BiLSTM基于LSTM进行优化,综合考虑了上下文信息,在序列标记任务上具有突出的表现[16].故本文采用BiLSTM模型,其结构见图6.

图6 BiLSTM结构

1.2.3 CRF
CRF是根据设定好的特征函数组对序列标签之间存在的依赖关系进行判断的一种判别式模型.BiLSTM层输出的结果是单独的标签解码,并没有考虑到预测标签信息的前后连贯性,而CRF能够学习输出结果序列标签之间的依赖关系,可以有效解决该问题,保证最终识别结果的合理性.
给定句子x=(x1,x2,…,xn),经过BERT和BiLSTM层输出的不同实体标签得分概率P=(P1,P2,…,Pn),可以得到句子x预测为标签序列y=(y1,y2,…,yn)的概率,公式为
(11)
其中:Pi,yi是第i个字对应标签yi的分值,Wyi,yi+1是从yi标签转移到yi+1标签概率.
(12)
其中Y是所有可能的标签序列集合.
1.3 利用MMR算法筛选摘要句
MMR算法在设计之初是用来计算目标文本与被搜索文档之间的相似度,并对文档进行排序.公式为
(13)
其中:Q是目标文本,C是被搜索文档集合,R是计算的相关度集合,di代表C中的某个句子.
本文将MMR算法与句子权重融合,用当前句子的权重值代替句子和文本的相似度,具体公式为
MMR(si)=max[λ×score(si)-(1-λ)×max[similarity(si,D)]].
(14)
其中:si为D中的第i个句子,score(si)表示句子si的权重值,λ为可变系数.
2 实验结果与分析
2.1 命名实体识别结果
2.1.1 数据集、标注条件及评价方法
使用2014年人民日报语料标注数据集,来验证本文提出的基于BERT-BiLSTM-CRF算法对中文人名、地名、机构名、时间名四类实体进行命名实体识别的效果,数据集的具体信息如表1所示.

表1 人民日报实体标注数据集
本文的命名实体识别序列标注使用BIO标注方法,在实体预测时预测实体边界和类型,待预测的标记有“B_PER”“I_PER”“B_LOC”“I_LOC”“B_ORG”“I_ORG”“B_T”“I_T”和“O”9种,其中B_PER表示实体开始部分、I_PER表示实体非开始部分、O表示非实体部分,其他类型实体标签以此类推.
采用准确率P、召回率R和F1值作为命名实体识别的评价指标.其中实体预测正确的条件是实体的边界和类型全都预测正确.
2.1.2 实验参数
本文实验环境如表2所示.

表2 实验环境
BERT预训练模型采用Google的BERT-Base-Chinese,该模型共12层,768个隐藏单元,12个注意力头,具体超参数设置如表3所示.

表3 模型的超参数
2.1.3 实验结果及分析
为了验证BERT-BiLSTM-CRF模型的有效性,与BiLSTM-CRF模型进行了命名实体识别对比实验,实验结果如表4所示.

表4 不同模型的命名实体识别结果比较
从表4中可以看出,BERT-BiLSTM-CRF模型相对于BiLSTM-CRF模型取得了更为优异的实体识别结果.说明在命名实体识别任务中,BERT预训练语言模型可以较好地表征字的多义性.在后续的文本摘要提取任务中,将采用BERT-BiLSTM-CRF模型进行命名实体的识别.
2.2 文本摘要提取结果
2.2.1 数据集及评价方法
LCSTS数据集[22]采集于新浪微博,其中包含人工打分标记过的短文本-摘要对,得分范围为1到5,得分高低代表短文本与相应摘要之间的相关性大小.本文从LCSTS数据集中随机选取1 000篇短文本-摘要对(评分为5)作为测试文本数据集,评分为5表明相应摘要与短文本之间有较高的相关性,符合文本摘要的要求,可以作为标准摘要来使用,具体信息如表5所示.

表5 LCSTS数据集
本文采用Rouge指标来对算法生成的摘要进行评估,Rouge基于摘要中n元词的共现信息来评价摘要,是一种面向n元词召回率的自动摘要评价方法.其基本思想是将算法自动生成的摘要与测试数据集的标准摘要进行对比,通过统计二者之间重叠的基本单元的数量来评价摘要的质量.本文选取Rouge-1、Rouge-2、Rouge-L 3种评价指标来评价算法生成摘要的质量.
2.2.2 数据集及评价方法
本文TextRank使用基于知乎文本数据的Word2Vec模型[23],阻尼系数d取0.85[7],MMR的λ参数[20]取0.8,实验环境同表2.
2.2.3 实验结果及分析
为了验证BBCM-TextRank算法的有效性,将本文算法TextRank算法及现有研究中基于TextRank的改进算法SW-TextRank[13]等设置对比实验,并通过Rouge-1、Rouge-2、Rouge-L 3种评价指标来对各个算法生成的摘要进行评估.实验结果如表6所示.

表6 算法性能对比
从表6中可以看出,本文提出的BBCM-TextRank算法在Rouge-1、Rouge-2和Rouge-L 3种评价指标上均有明显的提高,BBCM-TextRank算法生成摘要的质量更好.BBC-TextRank相对于TextRank,其Rouge-1、Rouge-2、Rouge-L分别提高了2.71%,1.98%,2.28%,说明通过实体识别获得的实体权重可以有效优化句子权重,提升了摘要反映文本信息的准确性;TextRank-MMR相对于TextRank,其Rouge-1、Rouge-2、Rouge-L分别提高了12.78%,6.7%,9.61%,说明加入MMR算法可以有效去除摘要中的冗余句子,提升了摘要反映文本信息的全面性;BBCM-TextRank结合BBC-TextRank和TextRank-MMR的优势,相对于TextRank,其Rouge-1、Rouge-2、Rouge-L分别提高了18.85%,11.94%和15.1%,说明通过BBCM-TextRank提取的摘要兼顾了反映文本信息的准确性和全面性,并且较最新基于TextRank的改进算法SW-TextRank,其Rouge-1、Rouge-2、Rouge-L分别提高了4.14%,3.8%和3.98%.
综合实验结果可知,BBCM-TextRank算法根据中文文本的特点,考虑文本时间、地点、人名和组织等重要实体因素,可以有效优化句子权重,结合冗余处理,可以明显提高生成摘要的质量.
3 结束语
TextRank算法是在抽取式文本摘要生成中最常用的确定句子权重的方法,但该方法仅依赖文本间相似度来计算句子权重,这容易导致抽取的摘要句间存在较高的冗余.针对这个问题,本文提出了一种结合深度学习算法的BBCM-TextRank模型.该模型采用Word2Vec模型来生成语句向量,相对于传统的TF-IDF更能捕捉语句的上下文语义信息.同时,考虑到中文文本中时间、人物、地点等实体对句子理解和语义保持的重要性,采用BERT-BiLSTM-CRF模型识别文本中的重要实体.结合识别出的实体以及句子间的语义相似性确定句子的权重,考虑到摘要要尽可能多样地反映文本的语义内容,在模型中增加MMR算法,以降低文本摘要的冗余,保证提取摘要的语义多样性.通过与TextRank算法以及与最新的摘要提取算法的对比实验,验证了BBCM-TextRank算法能生成质量更好的摘要.但本文提出的模型也存在一定的局限性,本文主要针对短文本摘要数据集,没有面向长文本摘要数据集.下一步将针对长文本数据集进行摘要研究,强化摘要模型的通用性.
猜你喜欢
当代陕西(2020年17期)2020-10-28
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
人大建设(2018年5期)2018-08-16
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
应用科技(2015年5期)2015-12-09
大连民族大学学报(2015年2期)2015-02-27
