
基于空间角度解耦融合网络的光场重建
2022-09-28 08:59:38张洪基邓慧萍向森吴谨
液晶与显示 2022年10期
张洪基,邓慧萍,向森,吴谨
(武汉科技大学 信息科学与工程学院,湖北 武汉430081)
1 引 言
光场相机可以在一次摄影曝光中从多个视角捕捉一个场景,记录场景的二维空间信息和二维角度信息,在深度估计、三维重建等领域具有重要的研究价值[1-2]。然而,由于光场相机内部传感器分辨率有限,捕获的光场图像在满足空间分辨率需求时只能在角度域稀疏采样。因此,通过稀疏采样光场合成中间视图的光场重建[3-5]成为光场应用的关键技术。光场角度分辨率重建又称为视点合成或视点绘制。依据是否依赖深度图的辅助可分为直接三维重建和基于深度辅助的光场重建。
传统的三维重建常采用信号的频域分析方法。Shi等人[6]只对边界或对角线子孔径图像进行采样,利用傅里叶域的稀疏性分析来恢复全光场,然而这种方法需要以特定的模式捕获光场,这限制了它的应用。Vagharshakyan等人[7]对光场极平面图像(Epipolar Plane Image,EPI)进行频域分析,在傅里叶域中采用了一种自适应的离散剪切变换来消除引入混叠效应[8]的高频光谱。Pendu等人[9]新提出了一种称为傅里叶视差层的光场表示方法,通过移动不同的视差层对光场进行重建。以上从频域重建的方法在一定程度上能获取密集采样的光场,但是针对深度层次较多的复杂场景时,光场的频域特点难以分析,频谱更加复杂,频域混叠问题难以解决。
基于深度学习的三维重建方法,利用卷积神经网络强大的学习能力,通过堆叠的卷积层将稀疏采样光场映射到密集采样光场。Yeung等人[10]将整个四维光场输入一个伪四维卷积网络,并提出了一种空间-角度交替卷积来迭代细化重建结果。Meng等人[11-12]使用密集连接的4D卷积对光场进行上采样和优化,实现了在空间或角度维度的多个尺度上的重建。虽然4D卷积可以同时提取光场的空间和角度信息,但是会导致过拟合并且计算代价非常高。以上利用深度学习的直接重建方法虽然无需对频谱进行分析,但是以稀疏采样的光场,特别是大基线光场作为输入时,提供的信息十分有限,尽管使用了高维卷积来提取特征,仍然难以建立起稀疏输入和密集光场之间的关系,需要复杂的优化网络进行后处理。
基于深度辅助的光场重建由于增加了光场的深度信息,往往能取得更好的重建质量。经典的3D warping算 法[13-14]就 是 通 过深度 信 息 的辅助,使参考视点与待合成视点建立几何映射关系,从而合成新视点。目前,也有不少工作将深度信息利用到基于深度学习的光场重建框架中。Flynn等人[15]利用颜色、深度和纹理先验,首次实现了使用神经网络来预测新视图。Kalantari等人[16]采用顺序卷积网络估计深度和颜色,然后使用连续的二维空间卷积层融合从不同输入视点映射到新视点的视图来产生最终的重建。以上早期的重建网络考虑到了使用颜色等先验信息辅助重建,但是颜色等信息只是光场空域特征的一部分,空间信息未能得到充分利用。Jin等人[17]首先估计出新视点的深度图,然后通过空间角度交替细化进行重构。该网络在细节方面能保持较好的效果,但由于是将所有子孔径图像一同输入顺序连接的卷积层来估计深度,忽略了光场视图之间的方向信息,导致了严重的遮挡问题。
除了显式的深度估计以外,Wu等人[18]利用编解码网络对不同剪切值的EPI进行评估,网络隐式地使用深度信息来选择重建良好的EPI,然后使用金字塔分解重建技术融合多个剪切EPI来得到密集采样EPI。该方法不需要显式地估计出深度图,但是EPI只是四维光场的二维采样,使用EPI进行重建没有完全利用到光场的空间角度信息。Zhou等人[19]提出了一种新的基于学习的多平面图表示方法,通过对不同图像的alpha通道进行融合来合成新的视图。Mildenhall等人[20]进一步提出利用多平面图来合成一个局部光场。基于多平面图的方法对小基线视图有着不错的重建效果,但这种未显式估计出深度图的方法由于受深度平面数量的限制,在面对大基线输入时会超出极限外推范围,使重建视图边缘产生伪影。
综上所述,利用深度辅助的光场重建算法由于引入了额外的深度信息,有利于提高大基线条件下稀疏光场的角度超分辨率重建质量,但是现有的基于深度的方法还存在几个方面的问题与挑战。首先,视点间基线增大会使深度估计面临严重的遮挡问题,遮挡区域的深度估计错误将会导致重建视图边缘模糊;其次,现有的方法仅考虑了光场角维度的重建,没有充分利用到光场空域信息,未能充分挖掘光场蕴含的四维特征,使重建视图在纹理重复区域发生错误。因此,本文从提高深度估计的准确性并充分利用空域信息的角度出发,提出了一种基于空间角度解耦融合的光场重建网络。该网络主要包含一个多路输入的深度估计模块和一个整合光场空间角度信息的光场融合模块,在获得较为精确的重建视图的同时,保留了更多的纹理细节。该深度学习网络具有以下特点:
(1)充分利用光场的多方向信息,采用多支路输入方式,更好地解决遮挡问题;对每条支路使用空洞空间卷积池化金字塔模块(Atrous Spatial Pyramid Pooling,ASPP)以引入多尺度信息,通过增大感受野来捕捉更多的视差信息并获取丰富的上下文信息,提高深度估计的准确性。
(2)设计了空间角度解耦融合模块(Spatial-
Angular Decouple and Fuse Module,SADFM),提取了光场空间维度蕴含的纹理信息和角维度蕴含的视差信息并使之融合。在模块内使用残差连接方式将浅层特征与融合之后的深层特征连接,获取更丰富的特征表示。引入空间信息辅助角度超分辨率,使重建结果在纹理重复区域更加清晰。
2 光场重建算法
2.1 整体网络结构
一个4D光场可以表示为L(x,u),其中x=(x,y)是空间坐标,u=(u,v)是角度坐标。光场角度超分辨率可以解释为:

其中L(x,u)为输入稀疏采样的光场,为密 集 采 样 的 光 场=为 密 集 光 场 的 角 度坐标,f表示要学习的重建过程的函数。
重建过程的整体框架如图1所示。本文利用了具有多个特征提取支路的深度估计模块来获取密 集 采 样 光 场 的 深 度 图D(x,̂),然 后 通 过3D warping将 输 入 视 点L(x,u)映 射 到 深 度 图D(x,̂)上,映 射 得 到 的 初 始 光 场 记 为W(x,̂,u)。再把W(x,̂,u)输入空间角度解耦融合模块以充分探索光场空间角度之间的关系,最后通过3D卷积得到重建的残差图fb(W(x,̂,u))。

图1 本文的整体框架Fig.1 Overall framework of the proposed network
最终重建的密集采样光场可以表示为:

其中W(x,̂,u1)是从第一个输入视图u1映射到深度图D(x,̂)的光场,fb表示光场视图融合过程的函数。
2.2 深度估计模块
深度估计模块利用输入的稀疏采样光场估计出待重建密集采样光场各视点的深度,可以表示为:

其中fd为表示深度估计过程的函数。
深度估计的准确性对光场重建的结果至关重要,但是在图像边缘等区域,特别是大基线输入视图的边缘,估计出的深度图往往具有严重的遮挡问题。本文采用多路输入形式,将每一个输入子孔径图像单独作为一个支路进行特征提取,各个支路之间权重共享。多路输入形式可以获取每个子孔径图像独特的位置信息和方向信息,在一定程度上解决了遮挡问题。
在每条支路上,为了获取大基线输入视图之间的视差信息,需要一个具有密集像素采样率的大接受域来提取层次特征。本文使用两个交替的ASPP模块和残差块作为特征提取模块。ASPP模块如图2所示,首先对输入的每张子孔径图像进行1×1卷积,生成初始特征,然后输入ASPP模块进行深度特征提取,在每个ASPP块中,利用3个3×3空洞卷积(空洞率分别为1、2、4)并行合并,引入了多尺度信息并增大感受野,提取到丰富的上下文信息和有密集采样率的层次特征。用参数为0.1的leaky ReLU层进行激活后,将这三个分支的特征通过1×1的卷积连接和融合。

图2 空间空洞金字塔模块Fig.2 ASPP module
在4张子孔径图分别经过特征提取之后,将提取的特征进行拼接并使用6个连续的卷积层来重建深度图,在加深网络的同时增大了感受野,进一步解决大基线问题。
2.3 视图3D warping模块
基于得到的密集采样光场各视点的深度图,可以通过3D warping建立稀疏采样光场和该深度图的映射关系,获取一系列从不同输入视图warping的光场图像,具体过程如式(4)所示:

由于不同的子孔径图像拥有各自的视点信息,对于待合成的目标子孔径视图有着不同的视角贡献,本文使用了从输入视点warping到其他待合成视点的所有视图进行融合。在框架中没有使用真实深度图,通过最小化warping光场的重建误差为深度估计网络提供适当的指导。此外,通过惩罚空间梯度来确保每个深度图的平滑性。深度估计模块的训练损失ld如式(5)所示:
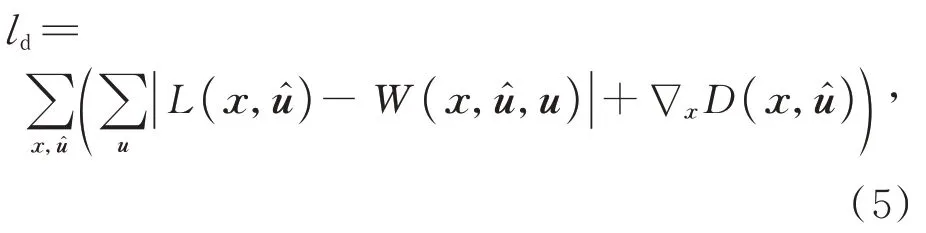
其中L(x,̂)为真实光场图像。
2.4 光场融合模块
在3D warping之后,需要融合从不同输入视点warping的光场视图来得到残差图,然而,在warping过程中子孔径图像之间的视差不一致性将不可避免地造成高频损失。为了缓解这种高频损失,需要在角度重建过程中充分挖掘光场空域蕴含的二维图像信息。现有的融合方式未能利用完整的光场空间信息[16],或者未能提取到光场空域的浅层特征[17]。这些方法不能充分利用光场所蕴含的空间信息,造成重建视图纹理重复区域的模糊。因此,在重构光场的过程中除了要关注角度信息,还要注重光场的空域特性。
本文利用空间卷积和角度卷积来分别提取光场的空间和角度信息,并设计了SADFM来充分探索光场空间角度之间的关系。在重构过程中额外引入的空间信息可以增强空域细节,使重建视图的纹理重复区域更加清晰。SADFM如图3所示,空间和角度卷积将特征张量分别变换为空间图像的堆栈X×Y×UV和角块堆栈U×V×XY,其中X、Y表示空间维度的大小,U、V表示角维度的大小,然后实行相应的卷积操作。
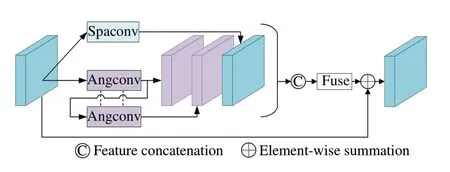
图3 空间角度解耦融合块Fig.3 Spatial-angular decouple and fuse module
卷积核的大小设置为3×3,步长为1,在空间卷积上设置空洞率为2以增大空间感受野,保证在较大基线光场中仍能捕获细节特征。由于光场特征张量XY×UV中空间维度XY远大于角维度UV,在重建步骤中可利用的角度信息远小于空间信息,因此本文利用了一次空间卷积和两个级联的角度卷积来分别提取空间信息和角度特征,然后将所有特征进行连接并输入1×1卷积进行深度特征融合。级联的角度卷积权重共享,不仅能减小模型大小,还能加深网络,提取更深层次的角度特征。然后使用残差连接方式将初始特征与融合之后的特征进行连接,用浅层特征强化特征张量,形成层次表示。
本文以残差连接方式级联6个SADFM加深网络,在空间角度信息不断的解耦和融合步骤中整合信息流,充分探索光场视图空间角度之间的关系,进一步提高重建视图的质量。光场融合模块的损失函数为lb,通过在最小化预测光场的重构误差来监督光场后续的重建:

考虑到高质量的重建光场在EPI上应有严格的线型结构,因此,本文使用了一种基于EPI梯度的损失函数le来对输出EPI添加额外的约束[17],以进一步保持光场的视差结构,增加新视点之间的视觉连续性。
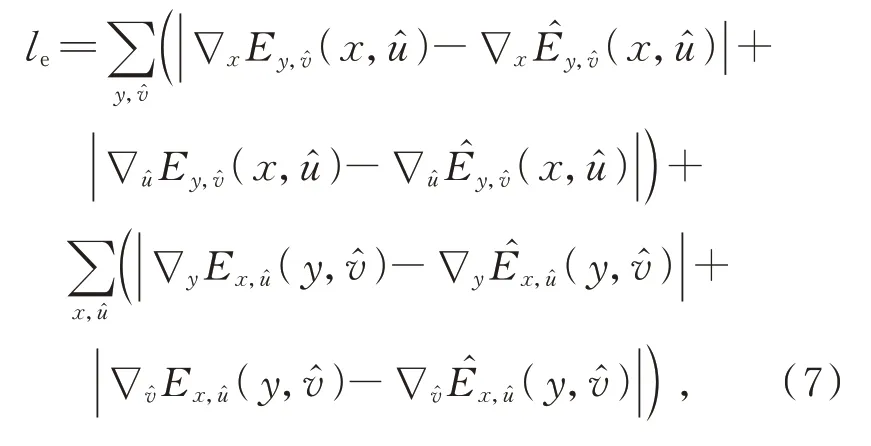
其中,le为重建EPI(̂)和真实EPI(E)梯度之间的l1距离,梯度在水平和垂直EPI上沿空间和角度尺寸计算。
3 实验结果及分析
3.1 实验设置
本文提出的网络使用合成光场图像HCI[21]、HCI old[22]和Lytro Illum相机 拍 摄 的 真实 光 场 图像30 scenes[16]进行训练和测试。从以上数据集的9×9个视点中选取左上角的7×7个视点作为真实密集采样光场,然后对其进行稀疏下采样,获取7×7子孔径阵列的4个角落的视图作为稀疏输入的光场,实验采用提出的方法从2×2稀疏采样光场重建出7×7的密集采样光场。
具体来说,使用来自HCI数据集的20张合成图像进行训练,使用HCI、HCI old中的测试集和来自LytroIllum相机拍摄的30 scenes进行测试。这些数据集涵盖了评价光场重建方法的几个重要因素,合成数据集包含高分辨率的纹理,以测量保持高频细节的能力。真实数据集30 scenes包含了丰富的遮挡场景,可以评估不同方法在自然照明和实际相机失真下对遮挡的处理能力。此外,合成光场数据集包含视差范围为[-4,4]的大基线光场图像。在7×7的光场中,视图之间的基线范围是视差的6倍,即在[-24,24]的范围内,远远大于商业相机捕获的光场的视差范围。这验证了本文提出方法在大基线输入的有效性。
所有用于训练的图像的空间分辨率为512×512。在训练过程中,为了解决数据量不足的问题,把每张图像随机裁剪成96×96的块进行训练。为了保持空间分辨率不变,所有卷积层都使用了零填充。模型在NVIDIA GTX3080Ti GPU上运行,采用PyTorch实现。实验使用了Adam优 化 器[23]进 行 优 化。β1和β2分 别 设 置 为0.9,0.999。学习率最初设置为1e-4,每5e3个周期降低0.5倍。Batch size设为1,训练大约花了6天时间。最终的损失函数为min(ld+lb)+λle。其中,λ为EPI梯度损失的权重。
为了验证本文所提方法的有效性,将本文的实验结果与一些利用深度信息的光场重建方法进行了定性和定量的比较。对比的方法有Kalantari等人[16]、Wu等人[18]、Jin等人[17]的方法。为了公平比较,本文使用作者直接公布的光场重建结果或者使用它们公开的参数和代码进行了测试。
3.2 定量与定性分析
本文采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结 构 相似 度 指 数(Structural Similarity,SSIM)来评估光场重建算法的性能。表1、2、3显示了在HCI、HCI old以及30 scenes上的定量比较。每个场景的最优值用加粗表示。
从表1、2、3中可以看出,本文算法的PSNR和SSIM在除了stillLife的所有场景上均高于所比较的算法,在stillLife场景中略低于Jin等人[17]的方法,处于次优值。在HCI、HCI old和30 scenes数据集上的平均PSNR比次优算法分别提高了1.0,0.68,0.6 dB,平均SSIM提高了0.013,0.001,0.002。

表1 不同方法在HCI数据集上的PSNR(dB)/SSIMTab.1 PSNR(dB)/SSIM of different methods over HCI datasets

表2 不同方法在HCI old数据集上的PSNR(dB)/SSIMTab.2 PSNR(dB)/SSIM of different methods over HCI old datasets

表3 不同方法在30 scenes数据集上的PSNR(dB)/SSIMTab.3 PSNR(dB)/SSIM of different methods over 30 scenes datasets
实验在HCI、HCI old两个大基线合成数据集中选取了具有丰富纹理信息的bicycle和buddha,在真实场景数据集30 scenes上选取了具有丰富遮挡的IMG1528和IMG1555来定性分析所提出算法的有效性。
在具有丰富高频特征的合成数据集上,对纹理重复区域的重建效果进行比较,如图4所示。由于引入了空间信息来指导角度重建,本文方法在bicycle的镂空金属网格区域和buddha的白色纹理区域都取得了较为清晰的重建效果。
Kalantari等人[16]和Wu等人[18]未能充分利用光场空间信息,纹理重复区域重建模糊;Jin等人[17]在重建过程中引入了空间卷积,因此在上述纹理重复区域重建出较为清晰的结果。但是他们的方法未能使用浅层特征,在自行车(bicycle)的金属网格区域产生了比本文方法模糊的效果。
为了证明本文算法对遮挡的处理能力,在合成和真实世界数据集上对各个方法进行比较,如图4、图5所示。Wu等人[18]隐式地利用了深度信息。受限于剪切值的数量,他们的方法不能应对复杂遮挡的区域,会产生严重的模糊和伪影,如IMG1528和IMG1541;Kalantari等人[16]的方法虽然显式地估计了深度图,但是他们的网络过于简单,仅使用4层顺序连接的卷积,同样在遮挡附近出现了模糊;Jin等人[17]使用了9层顺序连接的卷积估计深度图,在融合步骤使用了空间角度卷积来提取光场空间角度特征,在大多数场景取得了次优的效果。但是他们的深度估计模块未能利用光场子孔径图像蕴含的多方向信息,不能很好地解决遮挡问题。从自行车中的后座边缘、IMG1528的树枝和IMG1555的树叶等场景可以看出,本文提出的方法能更好地应对各种遮挡问题。

图4 不同方法对合成光场数据集的重建结果Fig.4 Reconstruction results of synthetic light field data set by different methods

图5 不同方法对真实世界数据集的重建结果Fig.5 Reconstruction results of real-world data sets by different methods
从所有场景的EPI结果可以看出,本文提出算法的EPI在物体边缘等区域保留了更好的线型结构,进一步验证了本文算法能较好地处理遮挡问题。
3.3 消融实验
本文通过多个消融实验来验证本文所提出的多路输入模式和空间角度解耦融合模块在光场重建过程中所起到的作用和对最终结果的贡献程度,定性和定量地评估了本文的多路输入和空间角度解耦融合模块的有效性,给出了消融不同模块下重建光场的局部放大图。

表4 不同模块的消融实验Tab.4 Ablation experiments of different modules
图6给出了重建中心子孔径图像局部放大图。可以看到多路输入使重建视图在遮挡区域保持良好的效果,但是空间纹理部分产生较粗糙的结果,并且会出现一些不适定区域。多路输入加上解耦融合模块充分探索了光场空间角度内在关系,并以空间信息辅助角度重建,使结果在纹理重复区域更加清晰,并且消除了不适定区域。

图6 消融不同模块的对比效果Fig.6 Comparative effects of different ablation modules
4 结 论
本文提出了一种基于空间角度解耦融合的光场重建算法。本文方法充分利用光场蕴含的深度信息和神经网络强大的学习能力,通过显式估计场景深度和充分探索空间角度信息来实现有效的大基线光场重建。实验结果表明,本文方法对比Jin等人[17]的方法,在HCI、HCI old和30 scenes数据集上的平均PSNR分别提高了1.0、0.68和0.6 dB,平均SSIM提高了0.013、0.001和0.002。本文方法具有更高的重建质量,在遮挡区域、纹理重复区域保持了更好的重建效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科学(2020年5期)2020-01-05 07:03:12
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
常州工学院学报(2017年3期)2017-09-16 03:48:25
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:10
