
基于多特征融合的BiLSTM 恶意代码分类
2022-09-28 14:50刘紫煊
电子设计工程 2022年18期
刘紫煊,王 晨
(1.武汉邮电科学研究院,湖北武汉 430000;2.南京烽火天地通信科技有限公司,江苏南京 210000)
目前,全球使用互联网的人数已经达到47 亿人次,互联网正成为全人类最广泛使用的工具。但与此同时,针对互联网的网络攻击现象也越来越频繁,个人终端遇到的网络攻击行为主要包括恶意代码、恶意病毒、流氓软件等。企业终端除上述攻击外,还包含大量渗透攻击。由于近年混淆器的更新迭代日新月异,病毒使用混淆器的情况也逐渐增多,这就导致了病毒变得更加难以发现,病毒生成速度更快,产生数量更多。恶意代码利用代码变形、反追踪、反虚拟机、代码混淆等技术避开安防系统,攻击计算机的现象时有发生。根据报告,2020 年1-6 月,我国境内共拦截计算机恶意软件约1 815 万个,平均每日传播次数约400 多万次,其中相关恶意软件家族达1 万余个,被感染恶意程序的计算机约300 万台。
1 恶意软件的研究背景
1.1 恶意软件的反检测技术
为了避免恶意软件受到杀毒软件的侦测和查杀,恶意软件开发者通常会加入以下反检测技术。加壳:加壳技术主要包括加密和压缩两个流程,将恶意代码先加密后压缩,从而提高代码被检测到的难度;寡态与多态:寡态是指在恶意代码中植入多组加密器和解密器,恶意代码每一次运行之后,就会随机自动选择其中一组加密器重新加壳;多态技术则是将恶意代码进行加密过程之后,又为解密器添加了一个引擎,该引擎的主要作用是对解密器进行变形,以便将代码混淆。代码混淆:其基本原理是将原始恶意代码的结构打乱重排,使其更加难以被逆向分析,而代码的功能却没有变化,进而躲过查杀。
1.2 恶意软件的分析方式
静态分析技术是指在源代码未被运行的条件下,运用专业的辅助工具,通过分析软件代码的结构、功能、操作码、API 序列、函数调用等对代码进行分析,进而验证其是否为恶意软件以及其所属的类别。动态分析技术是指将代码放置在一个条件可控的实际工作环境或虚拟环境中,运行程序代码,通过定位到代码运行时所执行的指令和调用的函数类型等,进而分析代码的行为轨迹与目的,监测其是否为恶意代码。需要注意的是,动态分析技术所依赖的实验环境是要与外界网络彻底隔绝,避免恶意软件通过网络向外传播,导致其他计算机“中毒”,造成损失。
2 恶意软件数据集的分析与处理
2015 年Microsoft 曾在kaggle 上发起过一个恶意软件分类的挑战赛,引起了全世界网络安全行业相关学者的关注,微软发布比赛的同时,又发布了近1 000 GB 的恶意软件数据集,该数据集共分为九大类,包含超过一万个恶意软件样本。具体分类和数量如表1 所示。
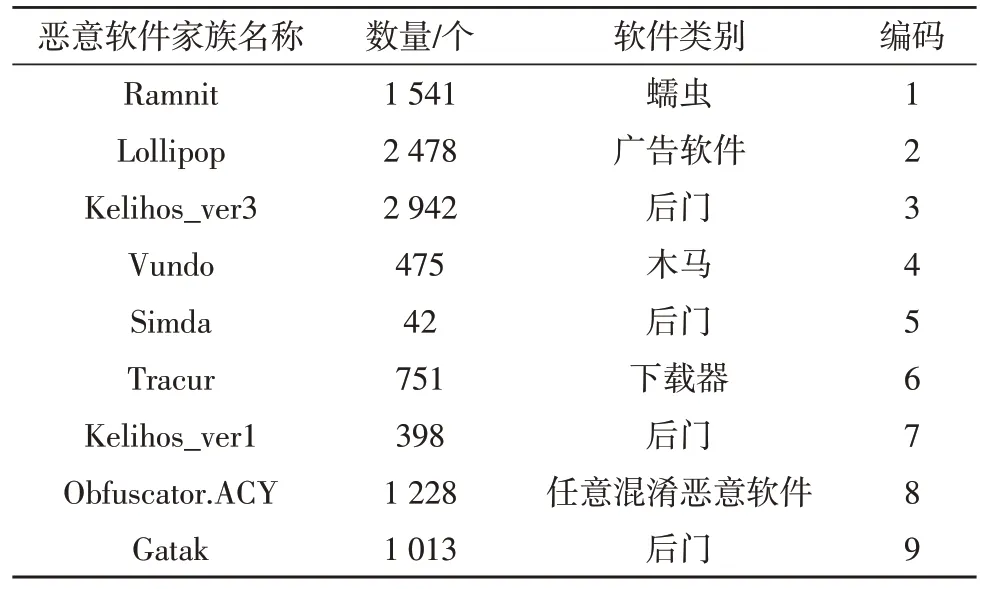
表1 恶意软件家族分类及数量
由于原始数据量过大,解压后占用存储空间近200 GB,并受到机器性能的限制,因此在实验之前,先对数据集进行抽样处理。从10 868 个样本中抽取十分之一作为实验用样本。
2.1 N-Garm特征提取算法
N-Gram 是根据统计学的模型原理生成的一种新算法,将每次滑动的窗口长度设置为N。N-Gram算法原理是提取文本内容,根据设置的窗口长度,将文本内容依此分割成n个片段,得到每个片段的长度为N。每完成一次分割后,便将窗口向后滑动一个单元,经过多次的分割移动,最终形成一个字节长度为N的序列。N-Gram 算法的性能和提取特征的总数取决于窗口的设定值。
每个被分割的片段称为一个Gram 片段,统计被分割的Gram 片段出现的频次,实验前设定一个阈值,并依此过滤出一个Gram 列表,列表中一个Gram片段代表一个特征向量,多个特征向量组合便是该文本对应的特征向量空间[1]。该模型提出的前提是第n个片段只受前面n-1 个片段影响,而不受其他片段影响,整个片段出现的概率等于各个片段出现概率的乘积。常见的N-Gram 算法包括N为2 的Bi-Gram 和N为3 的Tri-Gram。N-Gram 生成的窗 口包含了对应操作码序列的全部子序列,该子序列与其相邻的子序列形成一种联系,根据这种联系,可以得出对应程序的语义。
以片段{push,mou,add,dec,lea,sub,mov} 为例,设窗口每次滑动长度L=3,每个窗口代表这段操作码序列的子序列,每个子序列与其前后序列存在对应关系,如图1所示,由此可以得到子序列集合{(push,mov,add),(mov,add,dec),(add,dec,lea),(dec,lea,sub),(lea,sub,mov)},子序列集合中所包含的子序列个数由n决定,如果一个二进制序列操作码片段长度为L,那么将生成L-n+1个子序列[2],操作码特征提取流程如图1所示。

图1 操作码特征提取流程
根据上述流程,每一个编译文件都可以生成一个集合文件,集合文件中包含多个子序列,生成的子序列可以组成一个子序列集:

A集合中包含了所有操作码的子序列,例如(add,dec,lea)。如果要将该子序列集合作为机器学习模型的输入特征,则需将子序列集特征转化为可以应用到算法模型中的数字特征。假设一个.bytes 文件生成的子序列集合为(push,mov,add,dec,lea),那么可以定义一个数值化操作函数,将其转化为一个维度方向向量:φ(x)=(φa(x))a∈A,其中:
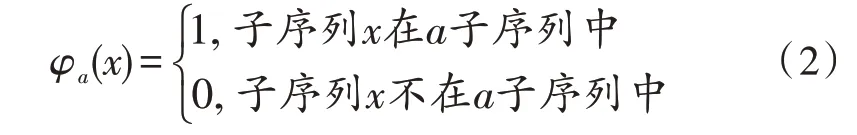
假设,如果全部二进制子序列的总集合A和所需要验证的集合B分别为{(push,mov,add),(mov,add,dec),(add,dec,lea),(dec,lea,mov),(lea,mov,sub)}和φ(push,mov,add,dec,lea)那么可以得到如下子序列:

则向量(1,1,1,0,0)便是该二进制文件的向量化和数值化的子序列,由此可得出集合B与集合A的关系。
2.2 灰度图特征提取算法
B2M 算法的原理是以二进制比特流的形式读取恶意代码源文件,以16 个字节为一个单元,将其转化为十六进制向量,设二进制文件固定宽度width 为2n,长度length 由文件大小和宽度相除获得(length=文件长度/width),生成的向量仿照矩阵格式排列,设置矩阵中元素大小在0~255 之间。
灰度图是指用黑白灰三种颜色描述的图像。灰度图像像素值介于0~255 之间,越靠近0 代表黑色越深,越靠近255 代表白色越深。在灰度图像中,色彩的饱和度通常为零,像素信息由灰度信息与其位置信息共同构成[3-7]。根据算法原理,二进制文件可以灰度可视化成图片。因为设置的矩阵值在0~255 之间,所以要将一个二进制文件转换为灰度图形式,必须把二进制文件按照每8 bits 为一组进行分块,8 bits代表0~28中任意一个数,每个块中的二进制序列可以被转换为对应的整数,那么这个整数必然可以表示为一个灰度[3]。
随机选取以下样本,恶意代码家族1 中的“1u3PmQiD0bX6RcgoCNKe”、“6bu0NZAsYoiUlCjEy H4X”、“8APhEd3UCifDsc4zVemR”,恶意代码家族2中 的“aXMsY6r5HDflGbOjUcu7”、“czxjYgBb4TeOD 38AhNvi”、“DRXe2HIAxJaiFp0joQr1”以及恶意代码家族3 中的“1iFYGHfzdnCJRXA5uby9”、“BLGY8Ek5 f4JlhOvIXxz2”、“ehW19YdIEik3jUpGA8sX”,分别将其灰度化后进行比较。结果发现,同一家族的恶意代码生成的灰度图具有相似的纹理结构。
2.3 决策树与随机森林
随机森林模型主要用作对数据集进行分类,模型根据数据集的特征进行划分,每一棵决策树代表一个特征,根据特征划分数据集,在数据节点特征中找到最优解,进行分裂。随机森林不依赖一棵决策树,而是根据预测的多数票从每棵树中获取预测,并预测最终输出[4]。RF 算法从训练集中选择随机的K个数据点,构建与所选数据点(子集)关联的决策树,为要构建的决策树选择编号N,对于新数据点,找到每个决策树的预测,然后将新数据点分配给赢得多数票的类别[8]。将样本中的训练集生成k个树,这些分类树组成随机森林,分类树投票分数的权重将决定测试数据的分类效果,随机森林的构建流程如下[6]:

随机森林的学习模型原理如图2 所示。
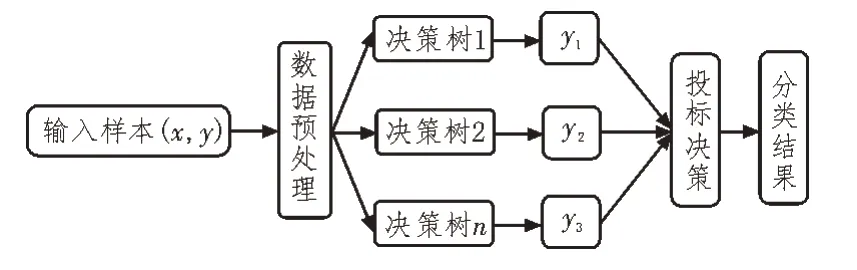
图2 随机森林模型原理图
设单个树误差为a,每个树之间互相独立,则组合树的误差为:
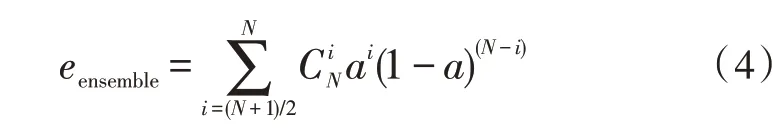
2.4 十折交叉验证
十折交叉验证的具体流程:数据集被平均分成10 份,按顺序选中其中每一份作为测试数据,剩下的9 份作为训练集,进行实验得到10 个值,取10 个值的平均值,作为待验证算法的近似准确率,通常一次实验要进行多次十折交叉验证。K折交叉验证虽消耗的计算资源较高,但可以在数据集较少时获得最优解,之所以选择将K定为10,是因为通过大量数据集测试结果表明,十折交叉验证可以使误差估计最小。该文所使用的算法模型训练和评估测试方法,均是十折交叉验证。
2.5 长短时记忆网络
LSTM 模型示意图如图3 所示。
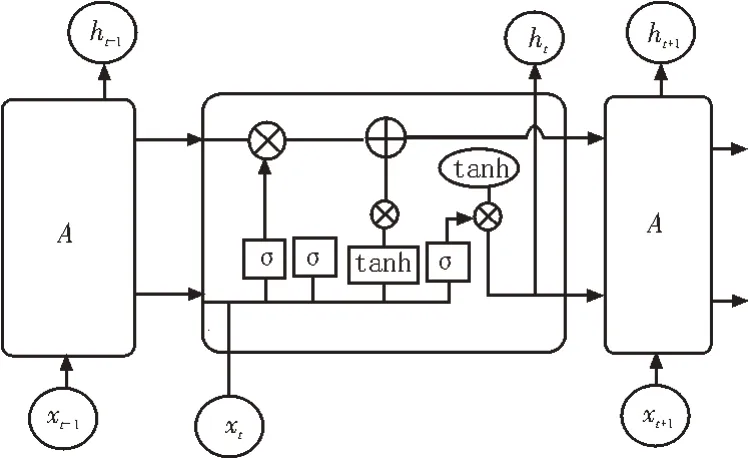
图3 LSTM模型示意图
图3 中的A表示了LSTM 三个时间步的三个单元,其中第二个单元显示了LSTM 内部单元的工作结构。该单元的第一个长方形A表示遗忘门,中间部分表示输入门,右边长方形A表示输出门,σ表示以sigmoid为激活函数的神经元,tanh 表示以双正切函数为激活函数的神经元[2]。多个神经元的组合和运算,可以计算当前时刻输入与输出数据、上一时刻输出数据以及单元状态,并将信息传递到下一个单元结构。每进行到一个时间节点,LSTM 模型便更新一次隐藏状态和单元状态。其中,xt-1、xt、xt+1分别表示不同时刻的输入,ht-1、ht、ht+1分别表示不同时刻的隐藏状态[5]。
在一个给定的输入序列X={x1,x2,…,xt}中,若将LSTM 结构中的输入门、遗忘门、输出门、隐藏状态和单元状态分别设置为it、ft、ot、ht和ct,wc为细胞状态的权重矩阵,bc代表细胞状态的偏置项,附加的权重标记为wi、wf、wo、bi、bf、bo,用σ表示sigmoid 函数,则上述参数的公式表示如下:
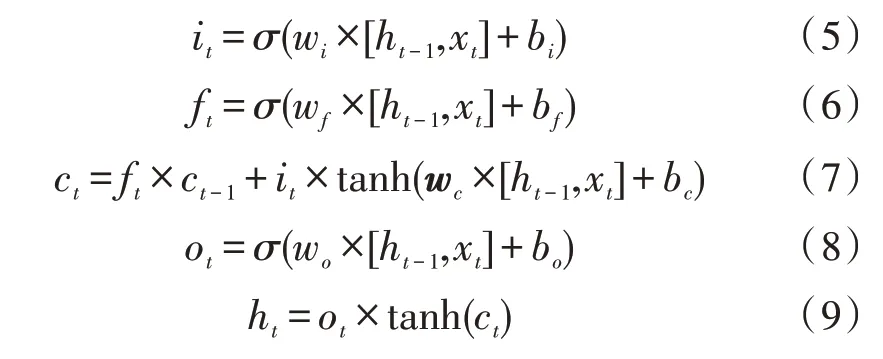
3 实验验证
3.1 基于N-Gram的随机森林算法
采用OpCode N-Gram 的方式作为特征预测,数据集中不同恶意代码文件大小不一,从全部的恶意代码数据集中提取所有操作指令的N-Gram 数量过大,文中对此进一步作特征选择。分别选取不同元组N值为{2,3,4,5,6}进行随机森林分类准确率对比实验,结果如图4 所示。经过测试发现,与随机森林算法结合后,N取值为3 得到的特征准确率和稳定性要略优于N取其他值时的准确率[9]。
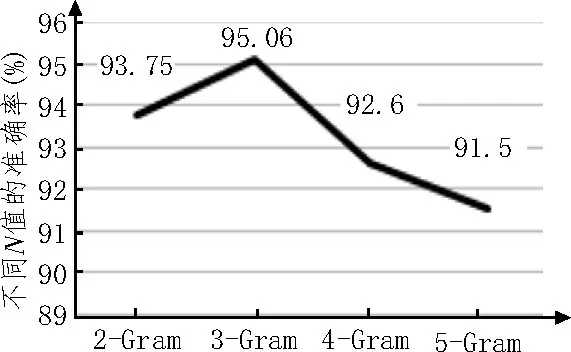
图4 N-Gram算法不同N值得到的准确率
因此,该文采用基于3-Gram 算法的随机森林算法,将特征值输入到算法选择器中,采用十折交叉进行验证,最终得到10 次测试结果如下:[0.950 617 28,0.925 925 93,0.937 5,0.887 5,0.887 5,0.962 5,0.975,0.925,0.937 5,0.987 5],预测准确率平均值等于0.937 65。
3.2 基于asm图像纹理特征的随机森林算法
该文分别选取像素点数目pix值为{1 000,1 500,2 000,2 500}进行对比验证,得到的准确率结果如表2 所示[10]。
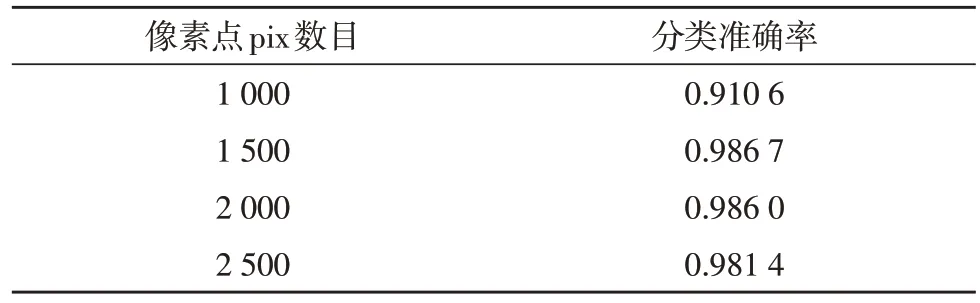
表2 不同像素点数目的分类准确率
根据实验结果显示,像素值pix 的个数在1 500~2 000 之间,分类准确率取得最大值,由此该文选取1 500 个像素进行验证,并将特征值输入到随机森林分类选择器中,采用十折交叉验证,最终得到10 次测试结果如下:[0.975 308 64,0.938 271 6,0.937 5,0.937 5,0.925,0.925,0.967 5,0.975,0.887 5,0.937 5],预测准确率平均值等于0.942 608。
3.3 基于N-Gram与asm联合的随机森林
根据前文实验,N取值为3,像素取值1 500,得到的预测准确率值最大[11]。基于此,将N-Gram 特征和纹理特征两者结合作为联合输入特征,应用到随机森林算法选择器中,并采用十折交叉验证,最终得到10 次测试结果如下:[0.987 654 32,0.950 617 28,0.9625,0.962 5,0.95,0.987 5,0.987 5,0.987 5,0.975,1.0],预测准确率的平均值为0.975 077,三种算法的结果如图5 所示。
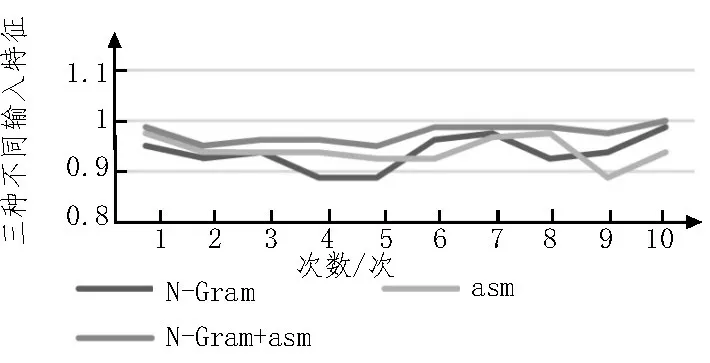
图5 三种不同特征的预测结果准确率
由结果可知,只采用N-Gram 特征或图像纹理特征作为输入特征,得到的预测准确率结果互有胜负,采用二者联合特征作为输入特征,得到的准确率均好于单一特征得到的准确率[12]。
3.4 基于N-Gram 与asm 联合的BiLSTM 双向长短时记忆网络
在LSTM 模型中,模型所包含的递归自然学习能力,能够自动提取N-Gram 和纹理两种特征结合后形成的深层次的特征,然后将融合该特征通过输入门输入到LSTM 模型后,依次经过隐含层中的遗忘门、输入门、输出门,计算出融合特征的特征图,LSTM中每个隐藏神经元都是循环连接,输出层输出的向量大小要与分类的恶意软件的类别数目相等[13]。该实验采用单层长短时记忆网络,模型每层结构采用两个方向相反的LSTM模型,LSTM的隐含神经元个数初始值定为20,BiLSTM 双向长短时记忆网络模型图如图6所示。
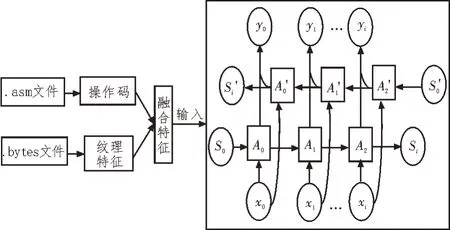
图6 BiLSTM双向长短时记忆网络模型图
针对BiLSTM 模型,通过实验不断调整和优化LSTM 网络结构中的有关参数,调整的参数包括隐藏神经元n_hidden 的个数、学习率lr、批次大小banth_size、网络层数、数据集划分比例、迭代次数epoch 等,使用控制变量法,先将某个参数值固定,通过调整其他参数,使泛化能力达到最优,得到一个最优解[14]。依此类推,直到得到所有的最优化参数,便得到了LSTM 结构的一组最优模型。在后续的融合特征数据作为输入时均采用该最佳的参数组合情况,其最佳参数组合情况如表3 所示[15]。

表3 网络结构最佳参数
通过实验验证,在相同输入特征的条件下,该文提出的BiLSTM 双向长短时记忆网络对恶意软件数据集分类的准确率达到了0.985,结果高于随机森林分类器准确率0.976,也高于KNN、SVM 等传统分类器的准确率[16],不同分类器得到的分类准确率如图7所示,实验结果符合预期。
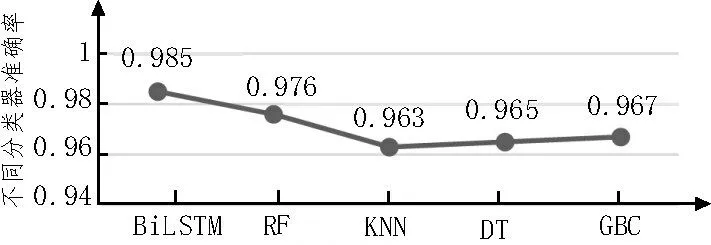
图7 不同分类器得到的分类准确率
4 结论
该文根据恶意代码源文件反汇编生成的.bytes文件和.asm 文件,基于.bytes 文件提取了N-Gram 操作码子序列特征,基于.asm 文件提取了灰度图像纹理特征,并基于随机森林分类算法以及十折交叉算法,分别验证了两种输入特征,得到每一种特征对应的分类准确率。最后将两种特征结合在一起,作为输入特征重复计算,发现预测准确率均高于单一特征的预测准确率。在此基础上,该文基于LSTM 模型,提出一种新的BiLSTM 双向长短时记忆网络结构,在相同的输入特征条件下,该模型的准确率要高于随机森林等传统分类模型准确率。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
天津医科大学学报(2021年1期)2021-01-26
健康体检与管理(2021年10期)2021-01-03
中国信息技术教育(2020年2期)2020-02-02
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
初中生世界·七年级(2017年9期)2017-10-13
