
基于深度卷积聚合特征的图像检索方法*
2022-09-28 07:26冯庆贺聂广华刘荣升迟明路王元利高雅昆张建霞
河南工学院学报 2022年3期
冯庆贺,聂广华,刘荣升,迟明路,王元利,高雅昆,张建霞
(1.河南工学院 智能工程学院,河南 新乡 453003;2.河南工学院 电气工程与自动化学院,河南 新乡 453003)
0 引言
伴随着个人移动终端、对地观测卫星、医学影像设备和交通视频监控设备的普及应用,海量的人脸图像、遥感图像、医学图像和交通视频监控图像正在不断地被收集和存储[1,2]。由于图像的数量呈现了爆炸式增长,因此高效准确地检索到感兴趣的目标图像,在移动边缘计算领域、遥感卫星观测领域、医学辅助诊断领域和智能交通监控领域都成为一个被广泛关注的研究热点,而有效的特征提取对图像检索系统的准确性和高效性方面都起着关键的作用[3,4]。
纵览国内外研究现状,特征提取方法大致可以划分为图像底层视觉特征提取方法和深度卷积特征提取方法两个方面。图像底层视觉特征提取方法主要包括颜色特征提取、形状特征提取和纹理特征提取三个大类[5,6]。最近几年,深度卷积特征提取开始逐渐走进图像检索领域。不同于图像颜色、形状和纹理特征,深度卷积特征提取方法主要从图像的语义进行考虑[7]。但是基于图像分类任务训练的卷积神经网络模型并不可以直接应用于图像检索任务。其中重要的原因是图像分类任务的目标是将具有相同语义的图像划分到一个类别内[8],然而图像检索任务需要具体到同一个事物。例如在最常用的Pairs-6K地标建筑数据集中进行埃菲尔铁塔图像检索,就需要所检索到的图像中包含埃菲尔铁塔这个地标性建筑。因此从预训练模型抽取的深度卷积特征通常存在严重的冗余影响图像检索准确率的问题。
针对这个问题,提出一种深度卷积聚合(Deep Convolutional Aggregation, DCA)算法用于消减预训练模型抽取的深度卷积特征冗余,以提高图像检索的准确率。所提出算法可以概括为三个步骤:筛选、聚合和池化。在筛选步骤中,提出一种基于熵的卷积描述子筛选策略;在聚合步骤中,卷积描述子通过洪泛算法聚合为目标掩码图;在池化步骤中,卷积特征图内部的目标掩码图区域被池化后再聚合。再通过在公共的地标建筑图像数据集上的定量和定性实验,以验证该算法在特征筛选上的有效性和在地标建筑图像检索上的优越性。
1 深度卷积特征分析
当前预训练的AlexNet、GoogLeNet、VGGNet、ResNet和DenseNet等卷积神经网络模型已经广泛应用于图像检索研究工作,考虑到在ImageNet上预训练VGG16网络模型的良好迁移学习性能,并且当前大多数图像检索的研究工作也都基于VGG16网络模型上进行深度卷积特征提取,为了保证算法和实验对比的有效性和公平性,本文采用预训练的VGG16网络模型作为算法的基础。与此同时,本文也采用文献[9]中的参数设置方案,图像的尺寸被重置为700×700后输入网络模型中,之后抽取模型的池化5层(Pool-5)进行深度卷积特征提取。如图1所示,在Pool-5层解析中,将Pool-5看做一个三维卷积激活张量,其包含K个大小为L×W的卷积特征图集合S,其中任意一个卷积特征图标记为Sk,k∈K。为了方便,本文采用不同的颜色进行卷积特征图的区分[10]。转换空间角度,将Pool-5三维卷积激活张量看作L×W个卷积描述子,其中每一个卷积描述子可以看作一个K维变量标记为Cell(l,w),其中l∈[1,L],w∈[1,W]。
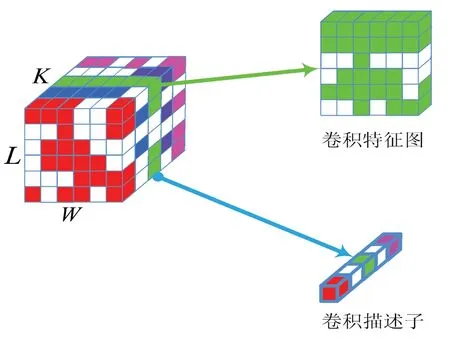
图1 Pool-5层解析
然而,Pool-5却不适合直接作为一个深度卷积特征,主要原因是卷积神经网络模型自身存在严重的参数冗余问题。如文献[10]认为,卷积神经网络模型精度只损失1%的前期下,采用最简单的标量量化方法可以将网络模型参数的总量压缩至原大小的1/16到1/24;卷积神经网络模型中只需要5%的参数,即可重构出剩下95%参数;在卷积神经网络模型精度只损0.58%的情况下,采用通用的网络量化方法可以将网络模型的体积缩减20.34倍,浮点数运算的次数缩减4.06倍。基于以上研究结论,本文推测卷积神经网络模型中Pool-5也存在着严重冗余。为了验证这种推测,本文对Pool-5中所有卷积特征图Sk进行了求和,获得一个掩码图,之后等比放大至原图像大小。如图2所示,可以看到在Oxford-5K和Pairs-6K数据集上不同地标建筑物的Pool-5掩码图定位结果示例,其中掩码区域代表求和后值不为0的区域。从图中可以清楚看到目标掩码图几乎覆盖了整张图像的绝大多数区域,其中包括干扰的天空背景、遮挡的树木、周围建筑等等。如此之多的干扰因素不仅会导致Pool-5的严重冗余问题,更会影响到深度卷积特征的表达能力,增加计算负担和存储花费。如何有效去除冗余是一个值得研究的问题。

(a) Oxford-5K数据集
2 深度卷积聚合特征提取
2.1 基于熵的卷积描述子筛选
熵这个概念最初由Clausius在热力学中将其定义为体系混乱的程度。之后Shannon将信息熵的概念引入信息论,将其定义为变量的不确定度。变量的不确定度通常采用概率分布进行度量。在数学上,设X为一个变量,其取值范围为ϑ,x∈ϑ。变量X的熵被定义为H(X),具体定义如下所示[11]:
(1)
式中,p(x)代表x的概率。通常H(X)越大代表变量X的不确定度越高,所包含的信息也就越多。
受启发于Shannon信息熵理论,本文将卷积层中每个卷积描述子看做一个变量。如果卷积描述子里面存在不为0的值越多,那么代表卷积描述子的不确定度也就越高,对应的熵值也就越大。据此,本文构建了深度卷积聚合算法如图3所示,Pool-5中每一个卷积描述子Cell(l,w)的熵被定义为H(l,w),具体定义如下所示:

图3 深度卷积聚合算法流程图
(2)
式中,p(k)代表k的概率。通常熵H(l,w)的值越大代表卷积描述子Cell(l,w)的不确定度越高。

(3)
(4)
2.2 目标掩码图构建
尽管在2.1节根据熵值去除了池化五层中部分冗余的卷积描述子Cell(l,w),然而实际上所筛选出的感兴趣卷积描述子仍然存在着部分冗余,并不是所有的感兴趣卷积描述子都属于目标区域。为了进一步有效筛选出目标所在的区域,本文利用文献[9]中的洪泛算法,将所有感兴趣卷积描述子聚合为N个候选的感兴趣区域(Region-of-Interest, ROI),返回其中最大的感兴趣区域作为目标掩码图Mask,具体定义如下:
(5)
式中,ROIn表示为第n个感兴趣区域,n∈[1,2,…,N]。在池化五层中,N的值为512。
2.3 多层卷积聚合特征提取算法
接下来,本文将目标掩码图Mask与Pool-5中每一张卷积特征图Sk进行交集运算,用于选取Sk中目标区域(Object-of-Rgion)ORk,具体定义如下所示:
ORk=Mask⊗Sk
(6)
其中符号⊗代表交集运算。
之后,对从特征图Sk中选取的目标区域ORk进行平均池化,获得DCAave。具体定义如下所示:
(7)
为了进一步将DCAave串联为深度卷积聚合特征向量DCA,DCA具体定义如下所示:
DCA=[DCAave(0),DCAave(1),…,DCAave(k-1)]
(8)
3 实验仿真
3.1 实验设置
为保证实验的精准性和可复现性,本文参照文献[12,13]中的实验参数设置方案,把最常用的Oxford-5K和Pairs-6K地标建筑数据集用于测试所提出方法的检索性能。在实验中,DCA特征向量经过L2归一化后利用欧式距离进行相似性度量。定量的检索效果评价指标采用平均准确率(Mean Average Precision, mAP)。
3.2 定性评价
如图4所示,Oxford-5K数据集上的原始Pool-5掩码图几乎被全图覆盖,而所提出的目标掩码图Mask的覆盖区域明显减少。在细节上,可以看到目标掩码图不仅滤掉过原图像中天空区域等冗余,而且准确定位出检索目标所在的区域。如图5所示,在Pairs-6K数据集上,可以观察到所提出的目标掩码图Mask依然可以有效过滤整张图像中的冗余,并准确地定位出地标建筑所在的目标区域。

图4 Oxford-5K和Pairs-6K数据集上掩码图示例

图5 Pairs-6K数据集上掩码图示例
3.3 定量评价
表1列出了在Oxford-5K和Pairs-6K数据集上、Pool-5(原始)、文献[13]中HFCLF方法和DCA(本文)的mAP结果对比。表中粗体数值表示在Oxford-5K和Pairs-6K数据集上的最高mAP。从表1可以看到DCA在Oxford-5K和Pairs-6K数据集上的mAP(%)为59.0和68.8,明显优于Pool-5和HFCLF方法。主要原因在于DCA不仅消减了Pool-5中的冗余,而且聚合不同层增加了特征的表达能力,进而提升了检索的准确率。
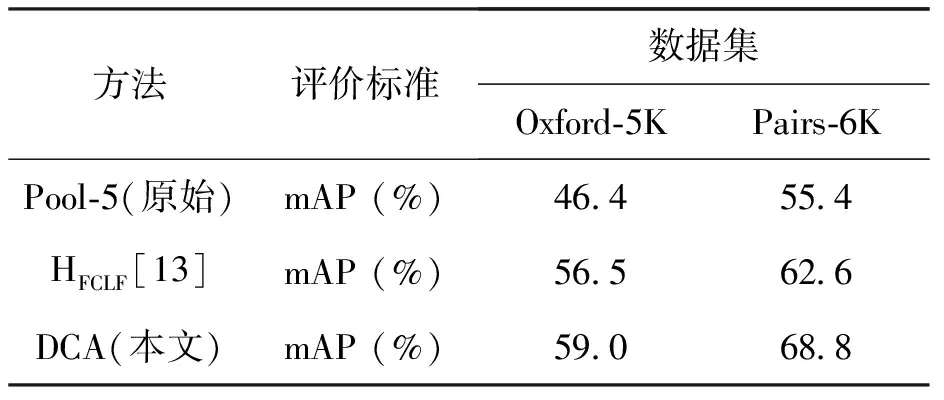
表1 在Oxford-5K和Pairs-6K数据集上平均准确率对比
4 结束语
本文提出了一种深度卷积聚合特征提取算法。受启发于Shannon信息熵理论,提出了利用熵值作为阈值筛选出感兴趣的卷积描述子,之后通过洪泛算法将感兴趣的卷积描述子聚合为目标掩码图,用于卷积特征图中对应区域的筛选,最后筛选出的区域在平均池化后进行串联聚合。通过在Oxford-5K和Pairs-6K图像数据集上的定性和定量实验结果对比证明了本文所提算法的优越性和有效性。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
北京航空航天大学学报(2019年9期)2019-10-26
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2018年19期)2018-11-14
文苑(2015年9期)2015-09-10
