
基于改进Swin Transformer的森林火灾检测算法
2022-09-24 06:50叶铭亮周慧英李建军
中南林业科技大学学报 2022年8期
叶铭亮,周慧英,李建军
(中南林业科技大学 计算机与信息工程学院,湖南 长沙 410004)
火灾一直以来都是全世界的重大威胁和灾害,每年全球至少有1 000 多人死于森林大火。2018年,发生在美国加利福尼亚的严重森林火灾,导致了66 人遇难以及700 多人失踪。2020年,澳大利亚的森林大火夺走了400 多人的生命[1]。早期预防以及快速检测出火灾是减少火灾发生的重要手段之一。因此,发展森林地区的监测技术并及时高效地预警森林火灾十分重要。森林火灾预警主要是通过获取森林火灾风险因子信息来建立森林火灾预警系统。李哲全等[2]通过使用遥感数据来提取森林火灾风险因子,以森林火灾动态危险性指数模型为基础,利用自然风险灾害指数模型、火险综合预报指数等模型对其进行改进从而得到森林火灾风险预警模型。早期的火灾检测主要是通过火灾探测器,但是单一的火灾探测器检测结果往往不够准确。Ting 等[3]提出了多传感器数据融合算法来融合采集火灾物理参数。不过火灾探测器存在很多不足,比如设备必须接近火源,并且很难清楚地感知到火灾的位置,给火灾检测带来了很大的不便。
随着计算机视觉的快速发展,通过机器学习的火灾检测方法开始被广泛应用[4]。基于视频的火灾检测[5]主要是通过模式识别的方法进行特征的提取,视频火灾检测按检测对象可分为火焰检测和烟雾检测两类[6]。火灾检测技术研究的关键是对火灾特征的提取,大多数都是通过研究火焰和烟雾的静态特征和动态特征。静态特征包含形状特征、纹理特征和颜色特征等;动态特征主要包含形状的变化、运动方向等。另外,大多数基于机器学习的火灾检测方法多是针对单火灾类型或固定场景提出,鲁棒性不佳,在光照、场景和火灾类型发生变化时其检测准确率明显降低,无法满足实际场景下应用的需求。
近年来,基于卷积神经网络的火灾检测取得了显著性进展。Zhang 等[7]通过在一个联合的深卷积神经网络训练了火灾分类器。首先使用全局图像级分类器测试完整图像,如果检测到火灾,则使用细粒度面片分类器检测火灾面片的精确位置。Sharma 等[8]在不平衡数据集上使用VGG16 和Resnet50 这两个预先训练的卷积神经网络(CNN)进行火灾检测,并在完全连接层上进行微调以增强这些网络。Dunnings 等[9]在不依赖时间变化的情况下分析了实时自动火灾探测,并应用了基于inceptionv1 的架构来降低CNN的复杂性。Muhammad 等[10]提出将一种轻量级SqueezeNet 体系结构应用于火灾探测,它使用较小的卷积核,不包含密集层和完全连接层,最后达到了与其他更复杂模型相当的精度。Shen 等[11]利用YOLO 模型实现了火焰检测。Akhloufi 等[12]提出一种Deep-Fire 卷积神经网络算法,在火焰图像的检测上取得了较好的效果。Zhang 等[13]使用Faster R-CNN 对荒地森林火灾烟雾进行检测。任嘉锋等[14]提出基于改进 YOLOv3 的火灾检测与识别的方法,针对YOLOv3 小目标识别性能不足的问题进行了改进,将火灾检测与识别形式转变为多分类识别和坐标回归问题。彭煜民等[15]提出了一种具有注意力机制的火灾检测算法,采用颜色分析的方法检测出图像中火焰和烟雾的疑似区域,再对火焰和烟雾目标的疑似区域进行关注,通过结合深度网络的特征提取能力,得到火灾目标的检测模型。
目前基于卷积神经网络的深度学习算法具有准确性高、成本低、速度快等优势,但是其处理视觉要素和物体之间关系的能力不如Transformer[16-18]。Transformer 是一种基于自注意机制的深度神经网络,最早应用于自然语言处理(NLP)领域。由于其强大的表现能力,目前研究人员提出了许多将Transformer 应用于计算机视觉任务的方法,并且取得了不错的效果,甚至超越了卷积神经网络。Vision Transformer(Vit)首次演示了Transformer 架构也可以直接应用于图像,方法是将图像分为一系列图像块进行处理[19]。DETR 是第一个成功利用Transformer 完成目标检测任务的方法[20]。DETR 在标准CNN 模型(如ResNet-50/101)的基础上增加了一个Transformer编码器和解码器,并使用了集匹配丢失功能。Swin Transformer 引入了CNN 中常用的层次化构建方式构建层次化Transformer,并且提出了一种滑动窗口注意力机制,对无重合的窗口区域内进行自注意力计,每层仅对局部进行关系建模,同时能够不断缩小特征图宽高,扩大感受野[21]。相比于ViT,Swin Transfomer的计算复杂度大幅度降低。
上述的检测算法在目标检测任务中取得了不错的效果,但也存在一些局限性。本文提出将Transformer 应用于森林火灾检测,利用一种改进Swin Transformer 网络的方法对森林火灾图像数据进行识别与检测;使用了随机数据增强的方法将图像经过旋转、裁剪、模糊以及色彩调节等操作后增广至1 900 张;通过对Swin Transformer 网络结构中的窗口自注意力机制进行改进,采用knn注意力替换自注意力机制来提高对小块噪声的识别,不仅提高了模型收敛速度,还提高了检测森林火灾的精确度;最后构建了可供训练的模型,并且可以快速、准确地识别出森林火灾。
1 实验与方法
1.1 数据来源
本研究使用的试验数据集为自制的森林火灾图像数据集。图像通过爬虫从互联网上获得,选取了300 张森林火灾的图像,包括各国真实发生的森林火灾图像和自然状态下的森林、山川的图像,并建立了数据集。通过python 标配工具Labelme对图片进行标注,并且将其制作为coco 数据集格式。利用数据增强技术对数据库中的图像进行预处理,实现了扩充样本和特征增强的效果。使用数据增强后将数据扩充至1 900 张图像,其中训练集包含1 400 张图像,验证集包含500 张图像。
1.2 Swin Transfomer 模型
目前Transformer 应用到计算机视觉领域主要有两大挑战:其一,视觉目标变化大,在不同场景下视觉Transformer 性能未必很好。其二,如果图像分辨率比较高、像素点多的情况下,Transformer 基于全局自注意力的计算会导致计算量较大。针对上述两个问题,Swin Transformer 提出了一种包含滑窗操作,以层次化构建方式构建Transformer 的方法。其中滑窗操作通过将注意力计算限制在一个窗口中,一方面能引入CNN 卷积操作的局部感知,另一方面能节省计算量。Swin Transformer 将计算区域控制在以窗口为单位的这一策略极大减轻了网络的计算量,将复杂度降低到了图像尺寸的线性比例。
Swin Transfomer 主要由以下几部分构成:多层感知机(Multi layer Perceptron)、窗口多头自注意力层(Window Multi-head Self Attention,W-MSA)、滑动窗口多头自注意力层SWMSA(Shifted Window based Multi-head Selfattention)、标准化层(Layer Normalization,LN)。Swin Transfomer 的骨干网络如图1所示。
从图1中可以看出输入到Swin Transformer 骨干网络的特征首先经过标准化层进行归一化,再经过窗口多头自注意力层进行特征的学习,然后计算残差,接着是通过标准化层,多层感知机,最后再进行一次残差运算,得到这一层的输出特征。滑动窗口多头自注意力层的结构和窗口多头自注意力层类似,不同的是滑动窗口多头自注意力层的计算特征部分需要进行滑动窗口的操作。经过骨干网络过程中,每部分的输出表示为公式(1)~(4)所示:

图1 Swin Transformer 骨干网络Fig.1 Swin Transformer Backbone

Swin Transfomer 的整体网络结构如图2所示。随着网络的深入,输入的特征图通过Patch Partition 层,这个图像分割层将图片的最小单位从像素转变为patch,每个patch 看作一个token,输出为H/4×W/4 的三维矩阵。patch merging 层作用是做降采样,用于缩小分辨率,调整通道数进而形成层次化。第一个patch merging 层将2×2的每一组patches 的特征拼接起来,并在拼接特征上连接一个线性层,再经过Swin Transfomer 骨干结构进行特征处理。在“stage1”这一过程中,tokens 的数量保持为H/4×W/4,输出维度设置为C。随后进入“stage2”,tokens 的数量减少了四倍,变为H/8×W/8,输出维度则变为2C,再进行特征处理。“stage2”和“stage1”重复两次。“stage3”“stage4”与之前类似,输出分别为H/16×W/16 和H/32×W/32,输出维度则分别为4C 和8C,分别重复6 次和2 次,每个stage 表示一个层次。这种层次化结构与ResNet 等典型的卷积神经网络相似[22]。因此,Swin Transfomer 所提出的体系结构可以方便地重新设计将骨干网络用于各种视觉任务中。

图2 Swin Transformer 网络结构Fig.2 Swin Transformer network structure
自注意力机制是Transfomer 的关键模块,它的计算方法为公式(5)所示。其中Q,K,V分别为查询(query)、关键字(key)和值(value),d为查询维数。

传统Transformer 结构通常采用全局自注意力,来计算其中一个token 和所有其他tokens 之间的关系,但是全局计算会导致复杂度提升,这使得它不适用于那些需要通过大量标记集来密集预测或表示高分辨率图像的视觉问题。为了高效建立模型,Swin Transfomer 提出在局部窗口内计算自注意力。窗口被安排以不重叠的方式均匀地分割图像。基于h×w个patches 的窗口计算复杂度远远小于基于全局注意力的计算复杂度。
1.3 改进Swin Transfomer 模型
为了使Swin Transfomer 算法适用于森林火灾目标检测,本研究针对Swin Transfomer 算法提出使用knn 注意力机制替换窗口多头自注意力层中的自注意力机制,它的计算方法如公式(6)所示。基于自注意机制的模型可能会将无关斑块和相关斑块混合在一起,特别是在训练开始时,相关斑块之间的相似性并不明显大于无关斑块之间的相似性,这可能会导致模型在初期训练表现不佳,且可能会误将其他类似火焰的目标检测为火灾。而knn Attenton 机制只考虑最前k个最相似的小块,对噪声小块的识别更有效,因此使用knn Attenton机制不仅提高模型收敛速度,还可以提高森林火灾检测的精确度。
由于对每个查询的键和值计算欧几里得距离很慢,本研究采用了一种快速版本的knn Attenton算法。关键思想是利用矩阵乘法运算,其计算和普通自注意力一样,通过点积计算所有的查询和键,不同之处在于knn Attenton 按大小从上至下取k 个元素用于softmax 计算。这个过程如公式(7)所示,其中 Tk运算表示按行顺序的从上至下选择k 个元素,以及通过knn 注意力计算后获得的值。


与CNN 相比,传统Transfomer 的模型通常利用全局依赖关系,使用的是完全连接的自我注意力,它需要所有的标记来计算注意力地图。这种自我注意力不仅容易忽略图像补丁的局域性,而且还在计算中引入了噪声标记,这些问题都会显著减缓训练速度,特别是在背景杂乱的情况下。尽管Swin Transfomer 提出的滑动窗口注意力已经使用了局部注意力,但是在对森林火灾图像数据检测的时候,由于火焰目标形状不规则以及火灾范围通常比较广,使用自注意力机制的Swin Transfomer 可能会错误地检测出一些近似火灾的目标。而knn 注意强调了相似图像特征斑块之间的关系。优化后的模型能够比原模型更加有效且准确地检测到火灾,而且采用knn 注意力机制增加的计算复杂度在实际应用中基本可以忽略,也不会增加模型的大小。
2 结果与分析
2.1 研究环境
本研究环境为:操作系统Windows 10 CPU Inter Core i9-7920X CPU @ 2.90GHZ,16 GB 内存,NVIDIA GeForce RTX 2080Ti,64 位系统。编程语言为Python3.8,GPU 加速库为CUDA10.1。
模型的训练使用pytorch 下的mmcv 库和mmdetection 框架,由于mmdetection 框架先进的模块化设计及其集成的目标检测框架,使得其能够完成目标检测中的许多任务,并且能够更快完成模型训练。本研究使用的试验数据集通过爬虫从互联网上获取了300 张不同背景下森林火灾的图像,使用数据增强的方法,经过旋转、裁剪、模糊以及色彩调节等操作后将图像增广至1 900张,效果如图3所示。

图3 数据增强效果Fig.3 Data enhancement rendering
通过python 标配工具Labelme 对图片进行标注,并且转换为coco 数据集格式。分别对原数据和增强后的数据进行训练,其中原数据集训练集包含240 张图片,验证集包含60 张图片,数据增强后的训练集包含1 400 张图片,验证集包含500张图片,总共1 900 张。本模型在模型训练阶段,批尺寸设置为16,优化器选择AdamW 优化器,权值衰减少值为0.05,学习率为0.000 1。分别对数据增强前后的数据进行训练,训练epoch 数分别设置为50 和20 次。试验结果从训练日志中提取并画图。
2.2 模型训练结果
bbox_mAP、bbox_mAP_50、bbox_mAP_75,这三个指标是目标检测对于coco 数据集的重要指标。IoU 表示交并比,即预测框和标记框的交集比上他们的并集,AP 表示平均精确度,bbox_mAP_50 表示IoU=0.5 的AP,bbox_mAP_75 表示IoU=0.75 的AP,bbox_mAP 表示IoU 在[0.5,0.95]范围内,以0.05 的增量计算模型在各个IoU 值的AP,取平均值。图例中的knn 表示使用knn 注意力机制改进Swin Transfomer 模型,self 则表示使用自注意力机制的Swin Transfomer 模型。
图4所示为未使用数据增强下的数据集对比改进模型和原模型的mAP 曲线图,曲线图均使用了图像平滑使曲线更加平滑。从图4可以看出,优化模型3 种指标的效果都明显优于原模型,随着迭代批次的增加,knn 和self 的mAP 基本上都在epoch为10 之前迅速上升,在epoch 为10~50 之间趋于稳定,在epoch 为35~40 次之间达到峰值。其中,kkn 注意力的bbox_mAP_50 的最高值比使用自注意力的bbox_mAP_50 高了约5.3%,最高值可达到81.5%;bbox_mAP_75 效果更加明显,高出约11.3%,而bbox_mAP 则高出3.7%左右。
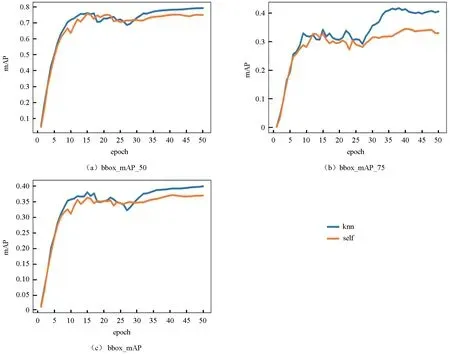
图4 未使用数据增强的mAP 变化曲线Fig.4 mAP change curves without Augmentation
图5所示为使用数据增强后对比改进模型和原模型的mAP 曲线图。从图5可以看出,优化模型经过数据增强后的训练结果依旧优于原模型,优化模型的bbox_mAP 的最高值比原模型的bbox_mAP 高了约1.6%,bbox_mAP_50 高出约1.3%,而bbox_mAP_75 则高出3.7%左右。
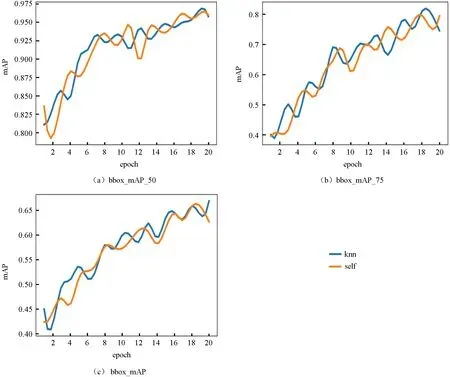
图5 使用数据增强之后的mAP 变化曲线Fig.5 mAP change curves with Augmentation
图6为准确率变化曲线。从图6中可以看出,改进模型和原模型制的准确率整体变化近似,前者最高可以到达98.1%,而后者最高为97.7%左右。图6b 为使用了图像平滑后的准确率变化曲线,可以看出使用改进模型准确率曲线整体上稍高于原模型的准确率曲线。

图6 准确率变化曲线Fig.6 Accuracy curves
如图7a 所示,前15 000 次数迭代过程中,损失值变化很大,在15 000 次迭代次数以后,loss值趋于稳定。通过图像平滑后画出损失曲线如图7b 所示,可以看出改进模型相比原模型的损失曲线整体来说下降得更快。

图7 损失函数下降曲线Fig.7 Decline curves of loss function
表1列出了改进模型和原模型的mAP、准确率以及平均训练时间,并且做了数据增强前后的对比试验。可以看出,虽然改进后模型的平均训练时间稍慢于原模型,但是其训练的mAP 和准确率都超过了原模型,在性能上取得了不错的效果。通过对比未使用数据增强和使用数据增强后的试验结果,我们发现使用数据增强后的各项检测指标都远远超过了在原数据下训练的试验结果,bbox_mAP 和bbox_mAP_50 都提高了20%左右,而bbox_mAP_75 提高了40%左右。

表1 实验结果Table 1 Results of experiments
图8为改进模型(左)和原模型(右)的检测结果,选取白天和黑夜两种背景下的森林火灾进行检测对比。可以发现基于自注意力机制的模型可能会误将一些近似火焰的光线检测为火焰,而基于knn 注意力机制的改进模型能够更加准确检测到火灾。

图8 改进模型(左)和原模型(右)检测结果Fig.8 Test results of the improved model (left) and original model (right)
3 结论与讨论
3.1 结 论
Transformer 是一种基于自注意机制的深度神经网络,Swin Transformer 提出将Transformer应用于计算机视觉任务,构建了一种名为Swin Transformer Blocks 的骨干网络,并且提出了一种滑动窗口多头自注意力机制。本研究中基于Swin Transformer 提出了改进Swin Transformer 的检测模型,已完成的研究工作与结论如下:
总结目前森林火灾检测技术相关的算法,包括传统的火灾探测器、机器学习算法以及目前常用的卷积神经网络、Transformer 等目标检测技术;介绍了本试验改进Swin Transformer 模型的概念、结构以及网络结构;介绍了原模型自注意力机制以及改进模型使用中knn 注意力机制的相关理论。
本研究中从互联网上通过爬虫获得300 张森林火灾的图像,其中包括各国真实发生的森林火灾图像和自然状态下的森林、山川的图像,建立了森林火灾数据集,通过python 标配工具Labelme对图片进行标注,并且将其制作为coco 数据集格式,利用数据增强技术对数据库中的图像数据增强将数据扩充至1 900 张图像。其中训练集包含1 400 张图像,验证集包含500 张图像。
本研究将目前计算机视觉中热门的Transformer技术应用到森林火灾检测中,提出一种改进Swin Transformer 网络的方法对森林火灾图像数据进行识别与检测。试验基于Swin Transformer 的网络构架,调整参数后对模型进行训练,对比发现改进后的模型取得了很好的识别效果。试验结果表明:改进后的算法准确率可达98.1%,且bbox_mAP、bbox_mAP_50 和bbox_mAP_75 分别达到了66.7%、96.4%和81.3%,分别提高了约1.6%,1.1%,3.7%。同时,通过对比试验发现,使用数据增强后训练效果明显提高了,bbox_mAP和bbox_mAP_50 都提高了20%左右,而bbox_mAP_75 提高了40%左右。综合对比准确率和识别速度,得出如下结论:改进前后的模型的准确率均在98%左右,这表明Transformer 应用于森林火灾检测任务存在一定的有效性和可行性;改进后的模型在未进行数据增强的数据集训练后,各项指标都明显高于原模型,而数据增强后依旧小幅高于原模型,这表明本研究改进后的模型在数据规模小的时候性能提升更加明显,而在数据量足够的情况下也能够提高一定的性能;同时,通过对比试验发现使用数据增强后训练效果明显提高了,这表明本研究使用的数据增强方法有效可行,能够在一定程度上提高模型的泛化能力,在使用数据增强后,改进模型的效果依旧比原模型效果更好。
3.2 讨 论
本研究对Swin Transformer 算法进行研究,提出了改进Swin Transformer 算法,对比改进前后的网络模型,发现我们使用的改进算法在森林火灾检测应用上有一定的效果,但是由于研究水平和时间的限制,本试验还有很多需要改进的地方,下面对改进的方向提出展望:
1)本研究的数据集都是从互联网上和一些论文中搜集整理的。但是现实中的森林火灾场景复杂多变,干扰因素也较多,本研究数据集相对来说比较少,且存在图片不够清晰以及大范围森林火灾图像比较容易混淆等问题。后期还可以扩大数据集,做更深层的研究。
2)在静态图像上实现森林火灾检测,主要流程是先确定图像候选区域,对这些区域进行特征提取,再通过分类器进行分类,最终确定图像中的目标。但是在森林火灾检测实际应用中,火灾数据以视频为主,而且视频目标检测中包含的要素更多,可以通过这一特性来解决图像间模糊、失焦等情况。因此,未来会将重点放在对森林火灾的视频检测。
3)本研究主要是对比了Swin Transformer 改进前后的试验结果,但是没有引入传统卷积神经网络模型进行对比,因此无法得出Transformer 相较于CNN 在森林火灾领域更有优势的结论。鉴于以上情况,将会引入一些传统的神经网络检测模型来进行对比试验。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
第二课堂(课外活动版)(2016年2期)2016-10-21
文理导航·趣味课堂(2016年6期)2016-09-09
故事作文·高年级(2009年7期)2009-08-20
中学英语之友·高一版(2008年10期)2008-12-11
