
基于数据分析的新能源汽车充电用户价值评价方法研究
2022-09-20 08:26:22俞倩雯
现代建筑电气 2022年7期
俞 倩 雯
(国网上海市电力公司, 上海 200235)
0 引 言
近年来,新能源汽车产业发展迅猛,为践行“双碳”目标,各地新能源汽车推广量大幅增加,新能源汽车用户数量随之增加,各类企业入场新能源汽车充电服务市场,充电运营服务行业发展迅速,传统充电运营企业在充电设施建设、充电网络规划、充电设备运维等方面都有丰富的经验,但在充电服务经营,尤其是个人充电用户运营、精准营销等方面缺乏经验。在大客户营销服务方面,充电运营企业可以采用配置客户经理等一对一营销策略,但在量大面广的个人充电用户端,由于信息不对称,往往很难开展精准营销服务。用户运营和精准营销是互联网行业优势领域,如何借鉴互联网行业大数据分析技术,对个人充电用户进行用户画像,从而实现差异化服务和精准用户营销,具有重要意义。
用户价值评价是用户画像技术中最基础的环节,RFM模型是评价用户价值最常用的工具,该模型最早由Arthur Hughes提出[1],RFM模型中,R(Recency)代表近度,即最近一次消费距今的时间,F(Frequency)代表频度,即观测期内消费的次数,M(Monetary)代表额度,即观测期内消费的总金额,这三个指标可以有效反映用户的忠诚度和贡献度。近年来,有诸多使用RFM模型对用户进行价值评价的研究,如陈倩舒等采用RFM模型对物流客户价值进行研究[2]。RFM模型在消费用户评价方面有很大的普适性,但在特定领域客户价值评价方面,往往会采用改进的RFM模型来优化评价结果,如包志强等在RFM模型的基础上,引入平均交易间隔和贡献时间,对百度外卖客户进行价值分析[3],杨琳等则在RFM模型的基础上,增加会员入会时长和会员机票平均折扣率对民航客户开展细分研究[4]。
以某充电运营企业的充电交易记录为例,分析充电用户消费特性,建立改进的、适合充电用户的RFM模型,通过数据挖掘与训练,对个人充电用户进行细分价值研究。
1 基于大数据分析的充电用户价值评价方法
1.1 数据获取与清洗
以某充电运营企业2022年2月充电交易数据进行数据分析,2022年2月共产生交易数据281 136条,每条数据包括“用户id”、“充电桩编码”、“充电站”、“交易流水号”、“订单创建时间”、“交易电量”、“交易金额”等56个字段,为确定充电用户、用户充电时间、用户充电电量和充电站点,提取其中“用户id”,“订单创建时间”,“交易电量”和“充电站”等4个字段为研究字段。原始数据字段名及格式如表1所示。

表1 原始数据字段名及格式
由于充电桩故障或通信故障会造成无效订单,需要对原始数据进行数据清洗,定义交易电量为0或大于500 kWh的订单为无效订单,共计37 888条。剔除无效订单后,有效订单共计243 248条。
研究的对象为个人充电用户,故对公交充电用户及有合作关系的大客户等多人共用账号订单做筛除,筛除相关订单后,剩余有效订单145 820条。后续所有数据分析和建模基于此数据样本。
1.2 改进的RFM模型
研究对象为新能源汽车的个人充电用户,这些充电用户具有一般消费者的共性,RFM模型的三个基础参数可以有效反映充电用户的忠诚度和贡献度,但另一方面,由于充电行为是有别于一般互联网消费的线下行为,充电场所可以反映用户的充电习惯,因此,在RFM模型基础上,增加充电用户充过电的充电站数量S,对用户进行建模,以R、F、M、S作为评价用户价值的特征量,具体定义如下:
R:用户最近一次充电距离当前日期(2022年3月1日)的天数;
F:用户在观测期(2022年2月1日—2022年2月28日)内的充电次数;
M:用户在观测期内的充电电量;
S:用户在观测期内充过电的充电站数量。
对数据样本做数据透视,145 820条充电订单共用户48 521个,计算每个用户的R、F、M、S值,所有用户的R、F、M、S统计特性如表2所示。
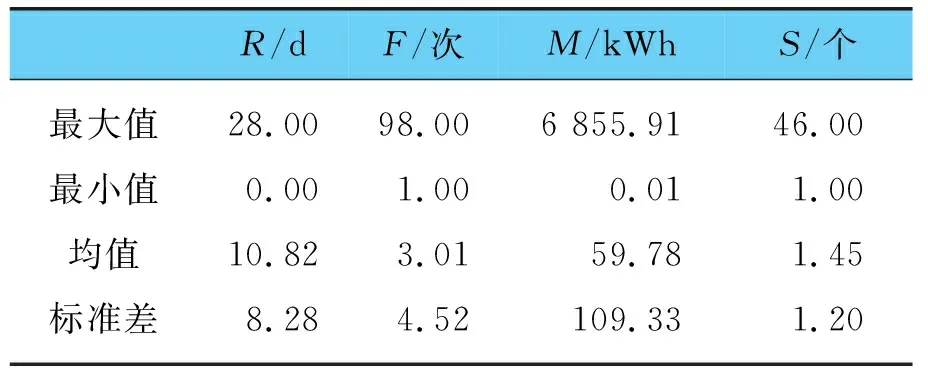
表2 所有用户的R、F、M、S统计特性
由于R、F、M、S量纲不同,对后续模型训练可能造成影响,采用Z-Score方式对R、F、M、S进行标准化处理:
(1)
(2)
(3)
(4)

Ri、Fi、Mi、Si——第i个用户的R、F、M、S值;
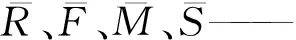
σR、σF、σM、σS——所有用户R、F、M、S的标准差。
定义用户i标准化后的用户评价指标向量为:
(5)
1.3 聚类分析
1.3.1 K-means聚类算法[5]
在改进的RFM模型的基础上,定义用户评价指标向量Wi后,采用K-means的聚类算法对充电用户进行聚类分析,K-means 的算法步骤为:
(1) 选择初始化的k个用户评价指标向量作为初始聚类中心,为减少计算步骤,加快收敛速度,采用K-means的方式确定初始聚类中心。
(2) 对样本中每个用户的评价指标向量,计算它到k个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中,此处距离计算采用欧几里得距离,Dij代表用户i与用户j之间的距离,即两用户评价指标间的差距,由以下公式计算:
(6)
两个用户间评价指标向量间的距离Dij越小,代表这两个用户在评价上越接近。
(3) 针对每个类别,重新计算它的聚类中心,即属于该类的所有用户的评价指标向量的质心。
(4) 重复上面 2、3两步操作,直到聚类中心不再变化,即得到最终的分类。
1.3.2 簇数k的确定
为判断K-means聚类算法的好坏,定义聚类后的标准误差和SSE,SSE越小代表聚类后同簇中用户评价指标向量间距离和越小,则聚类越精细。
(7)
式中:SSEk——簇数为k时的标准误差和;
Ci——第i个簇;
mi——Ci的聚类中心;
w——Ci中的用户的评价指标向量。
计算k为2到7时的标准误差和,并绘制标准误差和图。
标准误差和图如图1所示,由标准误差和图可以发现,k越大,SSE越小,聚类越精细,但当k超过4时,SSE的变化趋于平稳,因此选取k=4,即将充电用户分为4类。

图1 标准误差和图
1.4 模型训练结果
基于改进的RFM模型,通过K-means聚类,可以获得四类充电用户群,每类用户群的数量及聚类中心的R*、F*、M*、S*、R、F、M、S值聚类结果如表3所示。

表3 聚类结果
为直观显示各类用户R、F、M、S分布,绘制各簇用户R、F、M、S的核密度曲线图(Kernel Density Estimation,KDE)。用户群0的R、F、M、S的核密度曲线图如图2所示。用户群1的R、F、M、S的核密度曲线图如图3所示。用户群2的R、F、M、S的核密度曲线图如图4所示。用户群3的R、F、M、S的核密度曲线图如图5所示。

图2 用户群0的R、F、M、S的核密度曲线图
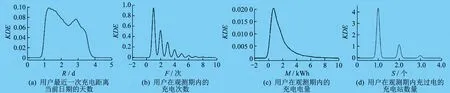
图3 用户群1的R、F、M、S的核密度曲线图

图4 用户群2的R、F、M、S的核密度曲线图

图5 用户群3的R、F、M、S的核密度曲线图
2 用户评价结果
通过基于大数据分析的充电用户价值评价方法,将目标样本充电用户分为四类,通过分析四类用户的R、F、M、S分布,可以对四类用户做出评价,用户评价如表4所示。
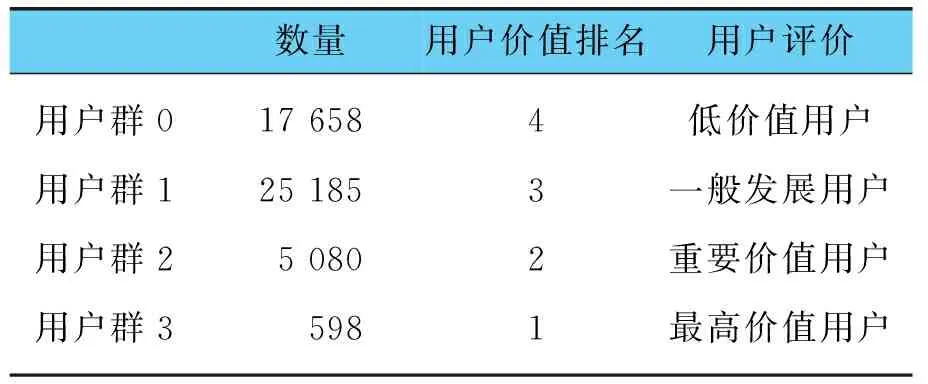
表4 用户评价
用户群3:最高价值用户,共有598个用户,此类用户距最近一次充电时间最短,平均在1.46天前进行最近一次充电,观测期内充电频率最高,平均为29.65次,平均每天超过一次,观测期内充电量最高,平均充电666.86 kWh,是企业具有最高价值的用户,且可以发现这类用户观测期内平均在6.07个充电站充过电,基本可以确定大部分不是两点一线的上班族,而是网约车或出租车等运营车辆(企业应对此类用户精准营销,保持其活跃度和贡献度)。
用户群2:重要价值用户,共有5 080个用户,此类用户距最近一次充电时间较短,平均在3.49天前进行最近一次充电,观测期内充电频率较高,平均为9.59次,观测期内充电量较高,平均充电186.95 kWh,活跃度较高,贡献度较高,忠诚度较高,这类用户观测期内平均在2.84个充电站充过电,多数可能为两点一线的上班族,部分为运营车辆(应重点发展此类用户,进一步将其发展为最高价值用户)。
用户群1:一般发展用户,共有25 181个用户,是所有类型中数量最多的用户群,此类用户距最近一次充电时间低于平均值,平均在5.82天进行最近一次充电,观测期内充电频率较低,平均为2.13次,观测期内充电量较低,平均充电41.72 kWh,此类用户贡献度一般,忠诚度一般,这类用户观测期内平均在1.28个充电站充过电,基本确定为非运营车辆的私家车(可制定专属营销策略,保持或挽留此类用户)。
用户群0:低价值用户,共有17 658个用户,此类用户距最近一次充电时间最长,平均在20.39天前进行最近一次充电,观测期内充电频率最低,平均为1.46次,观测期内充电量最低,平均充电28.33 kWh,贡献度和忠诚度最低,这类用户观测期内平均在1.13个充电站充过电,同样基本确定为非运营车辆的私家车(是企业低价值用户群)。
3 结 语
本文针对传统充电运营企业在充电用户运营、精准营销等方面缺乏经验的现状,借鉴互联网行业大数据分析技术,提出一种基于大数据分析的充电用户价值评价方法。
应用大数据分析的基本思路,选取充电交易数据,首先进行数据清洗,确认分析样本,在RFM模型的基础上,引入充电站数量S,形成评判用户价值的四维评价指标向量W,再通过K-means聚类方法训练模型,最终获得四类用户群。
根据四类用户的R、F、M、S分布,逐一分析特点,最终对四类用户做出价值评价,分为最高价值用户、重要价值用户、一般价值用户和低价值用户,为后续精准化营销策略的制定提供参考依据。
本文在数据选取时,仅选取了用户id、订单创建时间、交易电量、充电站4个字段,事实上,另有52个其他字段描述交易详情。未来,可以考虑将用户习惯充电时间(工作日或周末)、充电时段(早、中、晚或凌晨)、充电支付方式、账户余额等变量引入模型,创建更多维度的用户评价指标向量,实现更深层次和更细致的用户画像。
猜你喜欢
小学生作文·小学低年级适用(2024年4期)2024-05-23 17:59:55
消费电子(2021年6期)2021-07-17 10:47:38
矿山安全信息(2021年21期)2021-07-04 06:33:32
矿山安全信息(2020年37期)2020-12-26 07:25:58
环球时报(2020-12-08)2020-12-08 05:17:49
房地产导刊(2020年6期)2020-07-25 01:31:26
矿山安全信息(2020年2期)2020-03-05 05:13:56
矿山安全信息(2020年3期)2020-03-04 10:18:08
求知导刊(2019年17期)2019-10-18 09:17:04
黑龙江史志(2014年12期)2014-11-24 18:00:58
