
基于大数据技术的停电计划辅助决策研究
2022-09-20 12:26:30吕风磊胡鹏飞王银忠王燕陈晓琳车文学
电力大数据 2022年3期
吕风磊,胡鹏飞,王银忠,王燕,陈晓琳,车文学
(国网山东省电力公司东营供电公司,山东 东营 257091)
目前电网停电计划制定的主要流程为:检修单位根据设备运行状态,报送检修初步计划,运维检修部依据各个工区工期安排、工作地点等因素开展人工分析,制定停电计划预安排报送调度,调度组织计划平衡会,人工统筹考虑停电计划协调、电网安全约束等多方面因素,最终发布停电计划[1-2]。
整个流程中计划人员人工统筹工作量大,特别是当计划发生临时调整、追加工作多、停电窗口稀缺时,人工分析耗时耗力;当前面临着高速、高铁等民生工程相关停电工作时间要求较高,设备调度计划统筹协调性要求提高,人工编制的计划往往只是可行计划,不是最优计划,停电计划智能化编制急需解决;随着客户对用电可靠性要求的提高,各种停电检修计划的约束条件将不断增多,提升计划智能化排定水平迫在眉睫。在能源互联网发展的背景下[3-6],当前电网数据中规模庞大的负荷信息中蕴含着一定的变化规律,本文借助大数据[7-10]分析工具,探索系统主动学习和大数据挖掘技术[11-13],将负荷信息纳入计划考量因素,运用向量自回归、聚类算法分析负荷波动规律,基于Python编程实现检修基本信息“一键”输入、停电计划“一键”输出的功能,构建基于负荷信息的停电计划辅助决策模块,进一步优化停电计划安排的合理性、全面性,实现停电检修流程的数字化智能提升。
1 总体架构
基于检修提报的初步计划、历史负荷信息、N-1历史校核数据,针对当前数据挖掘浅、人工分析慢,通过大数据挖掘技术的预测、分类等功能,借助时间序列算法预测检修计划时间内负载波动情况,利用聚类分析对负荷分布进行算法归类并确定权重分配,进而结合检修工期安排、安全性校核、工作承载力等要求,实现停电计划的自动编制及发布展示,达到停电检修设备基本信息“一键”输入、停电计划“一键”输出的效果,实现滚动修订年度、追加、月度、临时停电计划的功能,辅助开展停电计划批量自动安全校核和后分析,为制定停电计划工作提供智能辅助决策。
本文引入电网中的历史负载率、安全校核历史数据,利用负荷预测、聚类分析模块评价未来时段不同线路的权重值,运用关联性分析计算线路的关联性关系,通过N-1校核分析线路越限情况,将三个模块输出的负载率权重、线路关联性关系、越限统计数与检修初始文本中的优先级、承载力、预安排时间作为考量因素输入优化编制模块中,经过算法优化得到停电检修计划发布版。
为实现上述功能,总体架构可分为四部分:基础数据读取(初步检修计划、负荷数据、安全校核历史数据)、算法分析(负荷预测、聚类分析、关联性分析、N-1校核)、优化编制模块(自动校核)、计划产品发布,产品流程简图如图1所示 。

图1 整体架构图Fig.1 Overall architecture
2 基础数据
电力基础数据应用涉及电网企业各业务方向,典型应用场景包括规划、建设、运行、检修、营销、运监、企管、服务等方向。在规划方面,通过应用用电大数据,提高中长期负荷预测的准确度,指导电网规划。在运行方面,通过应用用电大数据,提高短期和日前负荷预测的准确度,指导调度计划的制定;通过应用电网运行大数据,优化电网运行方式;通过应用新能源发电大数据,提高新能源发电预测水平,提升电网消纳新能源发电的能力。在营销方面,应用用电大数据,刻画电力客户用电行为特征,优化客户管理策略。在服务方面,应用用电大数据,为政府部门提供产业转移、产业发展、房屋空置率等社会经济指标;应用客服大数据,对热点问题的资源进行优化配置。
基于负荷信息的停电计划辅助决策模块第一部分基础数据分为:检修提报初步计划信息、2020年某地区历史负荷数据、某地区N-1校核历史数据,其中检修提报的初步计划数据主要包含施工优先级、承载力、施工开始结束日期等因素;2020年负荷数据为电网调度控制系统采集的电网设备日负荷信息及拓扑模型的相关ID等数据;某地区N-1校核历史数据为电网仿真模型中N-1扫描的历史数据。负荷数据如表1所示。

表1 负荷信息数据Tab.1 Load information data
抽取这些特征是数据挖掘的一个至关重要的阶段,而特征提取阶段通常与数据清洗阶段并行进行,以便估计或校正丢失的数据以及错误的数据。初步计划信息、2020年某地区历史负荷数据、某地区N-1校核历史数据三类基础数据,其格式往往不适合直接进行处理,需把基础数据转化为对数据挖掘算法较为合适的格式。采用数据过滤、数据清洗、数据识别等手段将上述三类数据转化成多维数据、时序数据或者半结构化数据等。
3 算法分析
本文决策模块第二部分算法分析,将已有数据直接转化成一个标准的数据挖掘问题,转化成关联模式挖掘、聚类、分类以及异常检测这四个典型问题中的某一个,这四类问题具有很广泛的覆盖性,可以构成数据挖掘任务的基本模块,而大多数应用都能由这些作为基本模块的组件拼搭实现。利用大数据向量自回归、聚类分析等技术,对基础数据进行深度挖掘,分别输出负荷权重Q、线路关联性R、N-1越限数L。
3.1 负荷权重
该部分引入2020年负荷历史数据,经过向量自回归负荷预测、聚类分析输出2021年负荷的权重值,衡量负载轻重及持续水平。
按照预测周期的不同,电力负荷预测可划分为短期、中期和长期预测。短期负荷预测(short-term load forcast, STLF)包含未来几分钟、一小时、一天、一周的负荷预测,用于经济调度和电力系统的安全评估,确保电网安全、经济、稳定的运行。中期负荷预测(medium-trem load forcast, MTLF)是指月至年的负荷预测,它是确定机组能够稳定运行的主要依据。准确的MTLF能够使需求和发电平衡,并影响成本采购的策略,同时也促进了经济增长。长期负荷预测(long-trem load forcast, LTLF)是指未来几年或几十年的负荷预测,主要是电网改造和扩建的远景规划。
目前,负荷预测有许多方法,可分为传统的经典方法和人工智能方法两大类。对于传统方法,是基于统计理论的时间序列模型,如回归模型、平滑技术和自回归移动平均(autoregression moving average, ARMA)模型等。这些算法在一些数据集上易于实现,但是与复杂度更高的机器学习算法相比,它们的预测精度通常较低,机器学习算法可以提供更高的精度和更强的学习能力。负荷预测[14-19]常用的机器学习方法有神经网络、时间序列分析等方法,本文针对中长期时间尺度采用向量自回归时间序列分析方法。
3.1.1 向量自回归算法
向量自回归(vector auto-regression,VAR)模型[20],简称VAR模型,是计量经济中的常用的一种时间序列分析模型,该模型是用所有当期变量对所有变量的若干滞后变量进行回归。VAR模型用来估计联合内生变量的动态关系,而不带有任何事先约束条件。VAR模型是AR模型的推广,可同时回归分析多个内生变量,即同时构建多个时间序列回归方程。
对2020年东营地区线路负荷采用向量自回归时间序列预测方法,预测2021年线路负荷情况。将2020年负荷信息作为初始数据,利用ID进行数据连接,筛选出东营地区设备信息数据,结合天气信息以及限产信息,进行数据整合,作为输入数据。
针对多元时间序列数据,向量自回归模型采用了一种更为灵活的时序建模策略:给定多元时间序列数据为Y∈RN*T,则对于任意第t个时间间隔存在如下的线性表达式:
(1)
其中,Ak∈RN*N,k=1,2,3,……,d表示向量自回归模型的系数矩阵;εt可视为高斯噪声。利用向量自回归算法得到2021年负荷预测数据YT。
3.1.2 聚类分析算法
聚类分析(clustering analysis, CA)提供了样本集在非监督模式下的类别划分,聚类的基本思想是“物以类聚、人以群分”,将大量数据集中相似的数据样本区分出来,并发现不同类的特征。聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。聚类根据数据自身的距离或相似度将他们划分为若干组,划分原则是组内样本最小化而组间距离最大化。利用聚类分析的特点,将负荷预测模块输出的2021年负荷预测信息Yt作为输入数据,通过聚类分类和幅值计算整合计算线路负荷的权重值Q,衡量线路负荷轻重及持续水平。
首先,结合常见的线路及负荷变化曲线,以一天24小时为观察周期,可以归纳出8类典型波动曲线(如图2所示),并且波动型、双峰平缓型、双峰陡峭型、单峰平缓型、单峰陡峭型、夜间型、白天型、稳定型8类曲线波动性依次减小。利用曲线波动型的差别,结合K-means聚类算法,将数据通过标准化处理(标准化处理方式为原数据与均值的差除以标准差),对2021年负荷预测曲线开展的波动率聚类[21-24]分析,实现数据波动性分类。过程步骤如下:
(1)首先,从数据中随机选择8个样本作为初始聚类中心[λ1,λ2,λ3,……,λ8];
(2)计算剩余样本到聚类中心的欧氏距离,并将其分配到最近的聚类中心,形成8个簇,距离的度量公式如公式(2)给出,
(2)
式中n表示空间的维数;ak和bk分别是a和b的第k个属性;
(3)通过距离度量方法更新聚类中心,更新为隶属该簇的全部样本的均值;
(4)重复步骤(2)和(3),直到算法收敛为止,最终得到每个设备的波动性分类J。
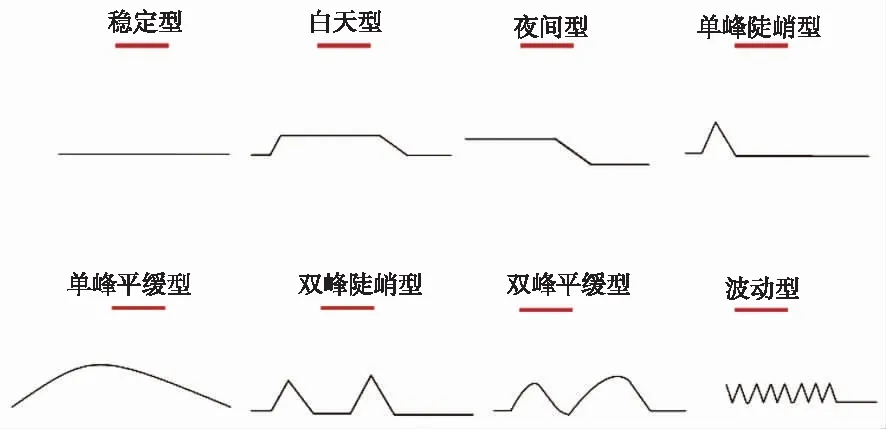
图2 负荷曲线图Fig.2 Load curves
其次,在波动率分析的同时,使用2021年负荷预测信息YT,开展负荷幅值分布分析,将线路每天96个数据点相加求均值,通过G衡量负荷均值水平,
(3)
将负荷均值G和波动性J相乘得到线路负荷权重Q。使用组合数据加权得到负荷的权重值,用于统计分析负荷变动综合特性,权数大小反映了负荷轻重及波动程度,权数大的负荷重、波动大。
3.2 关联性关系和N-1越限数
将2020年历史负荷分布和2021年检修计划表进行数据连接,选出典型日,计算典型日内负荷波动间的关联性关系[25-26](假设每个影响因素与目标之间是线性关系,利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计方法),采用关联性系数分析方法,将高于系数阈值(结合系数统计及历史经验定为0.7)线路建立关联性关系表,相关性高表示尽量不要同时停电检修。随机变量X、Y的相关系数为
(4)
其中,cov(X,Y)表示X,Y方差,σ(X)σ(Y)表示X,Y的标准差。
形成的相关性矩阵为:
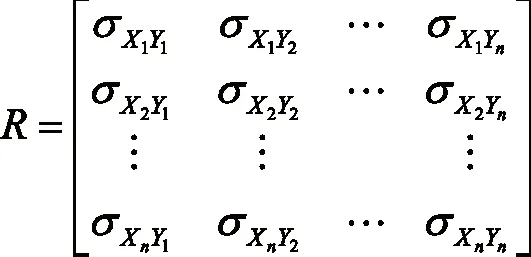
(5)
接下来处理N-1越限数。电力系统中N-1原则:判断电力系统安全性的一种准则,电力系统的N个元件中任一种独立元件(发电机、输电线路、变压器等)发生故障而被切除后,应不造成因其他线路过负荷跳闸而导致用户停电,不破坏系统的稳定性,不出现电压崩溃等事故。从调控云中导出线路N-1校核故障集信息文本,运用数据集成中分词方法、数据清理中缺失值处理方法、数据归纳中属性过滤方法、数据变换中数据连接手段分析N-1安全校核历史数据,建立线路越限信息表,通过越限次数判断线路实施检修的合理性。
L=[α1,α2,……,αn]
(6)
αn为0表示不存在越限情况,为1代表存在越限。
4 优化编制和计划发布
综合上述模块计算输出到的负荷权重、N-1越限表、关联性关系表以及初步检修计划排定的优先级、承载力等因素,使用Python编程算法按照下面流程,优化计划排定:
1)优先级为0,则检修日期直接排定;
2)优先级不为0,按时间段内负荷权重排序,选取权重最低的日期安排检修;
3)计算安排日内N-1是否越限,若有,选定权重最优日;
4)计算安排日期的承载力分析,如承载力已满,更换次优日,循环;
5)判断安排日期是否有关联性线路,若有,更换次优日,循环;
6)符合流程条件,排定安排日期,计算日期承载力;
7)输出计划。
最终,通过基础数据读取、算法分析模块、优化编制模块数据整合输出计划发布表,模型结构详见图3。整个架构充分利用Python的可扩展、可移植、易维护的特点,有条不紊地通过将其分离为多个文件或模块加以组织管理,结构简单、语法清晰,为后续功能应用的升级打下坚实的基础。
本文引入网上电网中的历史负荷、安全校核历史数据,利用负荷预测、聚类分析[27-31]模块评价未来时段不同线路的权重值,运用关联性分析计算线路的关联性关系,通过N-1校核分析线路越限情况,将三个模块输出的负荷权重、线路关联性关系、越限统计数与检修初始文本中的优先级、承载力、预安排时间作为考量因素输入优化编制模块中,经过算法优化得到停电检修计划发布版。决策模块实现了检修设备基本信息“一键”输入、停电计划“一键”输出的功能,具有“全、快、简”的效用。
全:全面分析计划编制的因素点;
快:运用大数据算法模型,计算快速实用;
简:自动优化编排,简化计划制定流。
另一方面,实现了停电计划适时调整、快速响应、批量处理的功能,如遇非计划停运或临时变更,只需调整输入信息,滚动修订年度、追加、月度、临时停电计划,能够根据不同的思路调节检修安排停电优先级、工期等信息,跟踪管控,强化停电计划编制合理性、可执行性,对停电计划进行批量自动安全校核,智能化给出调整策略,实现停电计划后分析功能。
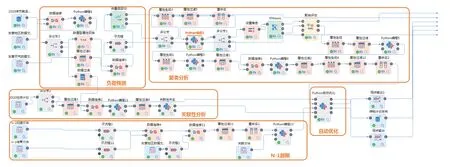
图3 模型结构图Fig.3 Structural drawing of method model
5 结论
基于负荷信息的停电计划辅助决策模块可通过可视化进行展示,在停电计划校核安排等工作中高频使用,按每月使用至少25天、每天使用软件功能至少20次计算,年使用天数超300天,年使用频次超6000次。避免大量重复的人工分析,减少不必要的沟通协商环节,提升停电计划的编制合理性、高效性。
模块可减少人工获取相关信息、分析电网方式、校核检修计划可行性、优化计划安排等人工工作量,在每个检修计划校核、审批与安排过程中,平均能够缩短20分钟的工作时间,按年使用频次6000次计算,可节省2000人小时的工作量,节约大量人工成本。
模块实现了停电计划适时调整、快速响应、批量处理的功能,如遇非计划停运或临时变更,只需调整输入信息,滚动修订年度、追加、月度、临时停电计划,能够根据不同的思路调节检修安排停电优先级、工期等信息,跟踪管控,强化停电计划编制合理性、可执行性,对停电计划进行批量自动安全校核,智能化给出调整策略,实现停电计划后分析功能。可扩展性强,未来可引入客户反馈信息等系统数据,为用户提供供电参考、全寿命周期管理,实现输入输出数据全方位扩展,为计划制定提供多维度支撑。
电力大数据与经济、社会存在广泛紧密的联系,电力大数据的价值不仅体现在电力行业内部,更体现在国民经济运行、社会进步及各行业创新发展等多个方面。随着能源互联网的建设,电力行业积累的海量数据,将为社会发展提供强大的动力支撑。
猜你喜欢
大电机技术(2022年5期)2022-11-17 08:13:02
中国交通信息化(2020年12期)2020-02-06 09:09:12
当代工人(2019年24期)2019-01-17 03:13:38
电子测试(2017年15期)2017-12-18 07:19:27
电子制作(2016年19期)2016-08-24 07:49:56
设备管理与维修(2016年5期)2016-03-16 02:20:41
智能系统学报(2015年4期)2015-12-27 09:38:39
中国石油石化(2015年12期)2015-04-20 09:04:36
电子设计工程(2015年6期)2015-02-27 12:04:53
水电站机电技术(2014年4期)2014-10-13 08:30:06
