
融合知识表征的多模态Transformer场景文本视觉问答
2022-09-20 09:13余宙俞俊朱俊杰匡振中
中国图象图形学报 2022年9期
余宙,俞俊,朱俊杰,匡振中
杭州电子科技大学计算机学院复杂系统建模与仿真教育部重点实验室,杭州 310018
0 引 言
视觉问答(visual question answering,VQA)(Antol等,2015)是计算机视觉和自然语言处理的交叉方向的典型任务,也是近年来相关领域的研究热点。它以一幅图像和一个问题作为输入,旨在设计模型对多模态的输入进行信息融合与推理,最终以自然语言的形式输出问题的答案。图1(a)展示了视觉问答任务的一个示例。模型对图像和问题细致的理解后进行推理,从而实现准确的答案预测,因此它是一项极具挑战性的任务。近年来,研究人员在视觉问答任务中取得了重大进展,在一些常用的视觉问答基准测试集上(Antol等,2015)取得了接近人类水平的准确率,但是这些方法大多忽视了对图像中“场景文本”这一重要信息的理解,从而限制了其对场景理解的深度。另外,视觉问答技术在现实生活中的一个典型应用场景是视障人群的辅助,而对于这些特殊人群来说,理解场景中的文字也是他们真正关心的痛点问题。

图1 传统视觉问答和场景文本视觉问答任务示例Fig.1 Examples of VQA and scene TextVQA((a) VQA; (b) scene TextVQA)
Singh等人(2019)和Biten等人(2019)提出将文本内容融入到视觉问答中,形成面向场景文本视觉问答任务,同时构建了TextVQA(text visual question answering)(Singh等,2019)和ST-VQA(scene text visual question answering)(Biten等,2019)两个基准数据集。图1(b)展示了场景文本视觉问答任务的一个示例,该任务问题涉及图像中相关的场景文本,需要模型建立问题、视觉对象和场景文本之间的统一关联后开展推理以生成正确的答案。为了理解图像中的场景文本,场景文本视觉问答模型通常需要引入一个光学字符识别(optical character recognition,OCR)系统来检测并识别图像中的文本对象。基于抽取到的OCR对象,一些方法相继提出(Singh等,2019;Hu等,2020;Kant等,2020)。LoRRA(look read reason and answer)(Singh等,2019)方法在视觉问答模型的基础上,扩展了一个用于场景文本编码的OCR注意分支。M4C(multimodal multi-copy mesh)(Hu等,2020)方法通过多模态Transformer融合所有输入特征模态内和模态间的信息,并采用迭代解码生成答案。但是M4C中Transformer的自注意力层是完全连接的,将注意力分散到整体上下文中,而忽略了围绕特定对象或文本的局部上下文的重要性。
在场景文本视觉问答任务中,部分问题涉及推理对象间的相对空间关系。例如,图像右侧的标识牌上写了什么内容?或图像左边球员的球衣上写了什么数字?针对这类问题,SA-M4C(spatially aware M4C)(Kant等,2020)方法通过引入12种预先定义的空间关系(Yao等,2018)对视觉对象和OCR对象构建联系,获得了增强的相对空间关系知识,并将其融合到 Transformer每个注意力层中,改进并提升了M4C方法的性能。但是人工构建的空间关系的空间量化策略不够精准,对于空间关联紧密的目标表达不够精准。
本文提出了一种融合知识表征的多模态Transformer的场景文本视觉问答方法KR-M4C(knowledge-representation-enhanced M4C),通过将“空间关联”和“语义关联”两种互补的先验知识进行统一建模后融入M4C模型框架,提升模型对复杂场景的理解能力。空间关联知识对视觉对象和OCR对象间的相对空间位置进行编码表征,有效对两两对象间细粒度的空间关系进行精准刻画。语义关联知识对OCR对象对应的单词和预测答案单词之间的语义相似性,对存在上下文语义关联的单词进行编码表征,提升答案生成过程模型的准确性和可靠性。为了评估提出的KR-M4C方法的有效性,分别在Text-VQA和ST-VQA两个公开数据集上进行实验。实验结果表明,相较于目前最好的方法,KR-M4C在两个数据集上均取得显著的性能提升。本文主要贡献如下:1)提出一种基于知识表征增强的多模态Transformer场景文本视觉问答模型KR-M4C,通过引入增强的知识,获得了更丰富的信息表示;2)建模了视觉对象间“空间关联”和单词间的“语义关联”这两种互补的先验知识,更准确地引导模型定位关键物体对象和文本对象;3)在TextVQA数据集和ST-VQA数据集上进行了充分的对比实验和消融实验。实验结果表明, KR-M4C 与现有最好方法相比具有更出色的表现。
1 相关工作
多模态学习旨在设计模型对来自不同模态的信号(如视觉、听觉和语言等)进行信息关联,并在此基础上学习统一的语义表达。得益于深度学习的快速发展,多模态学习逐渐成为计算机视觉和自然语言处理领域的研究热点,提出了一系列重要的多模态学习任务。如视觉问答(Antol等,2015;Kim等,2018;Yu等,2019)、视觉定位(Yu等,2017a)、图文检索(Karpathy和Li,2015;Lee等,2018)和图像描述(Anderson等,2016;Veit等,2016)等。在这些任务中,视觉问答是一个典型且具有挑战性的任务。
VQA是多模态领域近年来的研究热点。VQA任务的核心在于如何进行图像和问题的多模态信息融合。Zhou等人(2015)和Antol等人(2015)使用的是特征拼接或对应元素相加的线性融合方法。而后,得益于双线性模型在细粒度识别领域取得的良好效果,Fukui等人(2016)、Kim等人(2017)、Ben-Younes等人(2017)和Yu等人(2017b)设计了不同的近似双线性池化模型用于多模态特征的细致语义融合。随着对注意力机制研究的深入,提出了深度共同注意力模型用于多模态融合和注意力学习。Yu等人(2019)将模块化的思想引入视觉问答中,设计两种注意力单元并进行模块化组合,构建深度模块化协同注意力网络,建模多模态数据间细粒度的交互关联。随着多模态预训练研究的兴起,研究人员不再聚焦于单一的视觉问答模型设计,而是将研究重心聚焦如何基于Transformer这种通用架构设计合适的预训练策略,在大规模数据集上进行预训练,并在得到的模型权重基础上利用VQA数据进行模型权重微调。Lu等人(2019)、Tan和Bansal(2019)、Chen等人(2020)和Cui等人(2021)提出了各种多模态预训练框架,并逐步刷新视觉问答任务基准评测集上的最好成绩。
场景文本视觉问答任务是一种特殊的视觉问答任务。相比一般视觉问答任务,场景文本视觉问答更侧重图像中的文本信息,不仅它的问题主要围绕图像中的文本信息,而且它的回答也需要使用图像中的文本信息。这要求模型对问题单词、图像的物体对象和图像的文本对象构建联系,并经过推理生成正确答案。由于该任务具有重要的研究和应用价值,研究人员提出了一系列的解决方案。LoRRA(Singh等,2019)扩展了面向传统视觉问答的Pythia(Jiang等,2018)方法,使用现有的OCR系统检测图像中的文本对象,额外增加了一个用于场景文本编码的OCR注意分支,通过对固定词汇表中的单词和OCR识别得到的单词进行推理,选择其中概率最大的单词作为答案。由于LoRRA没有构建丰富的OCR对象特征,因此无法充分理解OCR对象蕴含的信息。此外,其采用的浅层注意力融合模型无法进行深度推理。为解决该问题,Hu等人(2020)提出了M4C模型,该模型是该任务上的一个强有力的基线方法,它通过一个多模态Transformer(Antol等,2015)结构,将不同模态的特征嵌入到一个共同的语义空间中进行融合。在这个语义空间中,模态间和模态内的关联由自注意力模型自动学习得到。M4C将场景文本视觉问答作为一个序列生成任务,结合一个动态指针网络模块实现精准的答案生成。然而,M4C没有考虑到图像中对象之间的相对空间关系,因此在涉及相对空间关系的问题上表现不理想。为解决M4C模型存在的问题,SA-M4C(Kant等,2020)在M4C的基础上,通过12种空间关系(Yao等,2018)对物体对象和OCR文本对象构建联系,获得了增强的知识,进一步提升了准确率,但是预定义的空间关系建模方法对空间关系的表达粒度不够细致,对相近位置对象难以区分。
2 融合知识表征多模态Transformer
针对场景文本视觉问答任务,本文在M4C模型(Hu等,2020)基础上进行改进,通过对“空间关系”和“语义关系”两种互补先验知识进行联合建模,构建知识表征增强的M4C模型。
2.1 M4C模型概述
M4C模型以问题和图像两种模态的数据作为输入,在进行多模态数据统一表征后,输入一个多层Transformer网络对多模态信息深度融合,最后输入一个动态指针网络进行迭代式答案预测。
2.1.1 多模态数据统一表征
如图2所示,M4C对问题和答案中的单词分别进行词向量表征,对图像分别提取视觉对象区域和OCR对象区域,并针对提取区域进行视觉对象表征和OCR对象表征。
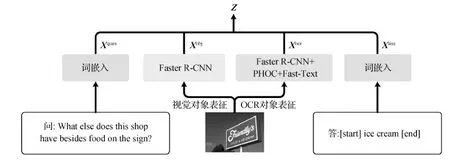
图2 M4C多模态表征流程示意图Fig.2 Flowchart of the multimodal representations of M4C
给定由至多K个单词组成的问题,使用经过预训练的BERT-base(bidirectional encoder representation from transformers-base)模型(Devlin等,2019)将每个单词映射到d维特征向量,最后将每个单词的表征拼接后得到问题特征Xques∈RK×d。

针对图像中的文本,首先使用外部OCR系统从图像中提取至多N个文本对象区域并得到相应的单词表示。对第n个文本对象(其中n∈{1,…,N})抽取如下4种特征:基于Fast-Text方法(Bojanowski等,2017)的词向量特征、基于PHOC(pyramidal histogram of characters)方法(Almazn等,2014)的字符特征、基于Faster R-CNN的视觉特征和文本区域的包围框坐标特征。然后使用线性映射将上述4种特征统一映射到d维空间,得到每个文本对象表征最后将N个文本对象表征拼接后得到Xocr∈RN×d。

将上述4组多模态特征Xques、Xobj、Xocr和Xans通过拼接得到融合特征Z∈R(K+M+N+T)×d,然后将其输入层的Transformer编码器模型(Vaswani等,2017)进行特征的深度融合。
2.1.2 自回归答案预测
由于答案可能包含OCR单词与词汇表单词合并形成的短语,M4C引入结合动态指针网络的自回归答案预测模块,将在OCR单词和预先构建的答案词汇表中进行的自适应选择作为t时刻的预测输出,并将本次预测结果作为下一次解码的输入,迭代解码,直至输出终止符。

(1)
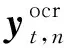
最后,将上述两个向量进行拼接得到预测向量,通过计算预测答案与正确答案的BCE(binary crossentropy)累计损失,实现对整个M4C模型的端到端优化。
2.2 KR-M4C模型的整体结构
得益于多层Transformer模型强大的建模表达能力,M4C模型可以学习得到不同模态特征之间的细粒度语义关联。但其存在两个弱点:1)尽管每个视觉对象和OCR对象中包含了其对应空间位置信息,然而这种空间位置特征与其他类型特征进行特征融合失去了明确的空间坐标含义,使得M4C模型难以准确理解对象间的空间关系;2)在进行答案预测时输出的单词需要从OCR对象单词和词汇表单词中进行选择,而这些不同来源的单词之间的语义关联在M4C中并未显式地建模,在进行答案预测过程中难以准确理解多来源单词之间的语义关联。
为了解决上述问题,本文在图像中的视觉对象和OCR对象之间提取空间关联知识表征,在OCR对象提取得到的单词和预测单词之间提取语义关联知识表征,并针对这两种关联知识表征,在M4C架构基础上提出一种知识表征增强的改进方法KR-M4C对知识进行编码表达。KR-M4C整体框架如图3所示,视觉对象与OCR对象间的“空间关联”、OCR单词与预测答案单词间的“语义关联”有助于提升场景文本视觉问答的准确性。

图3 KR-M4C整体框架图Fig.3 An overview architecture of KR-M4C
1)空间关联知识表征。场景文本视觉问答需要模型理解图像中视觉对象与OCR对象之间的空间关系,并在此基础上进行推理。如图4所示,给定问题What’s the licence number of the car? 模型首先要检测到图像中的车牌对应的视觉对象,然后推断出号码与车牌之间的关系,判断只有车牌对象内的数字才是需要回答的车牌号。
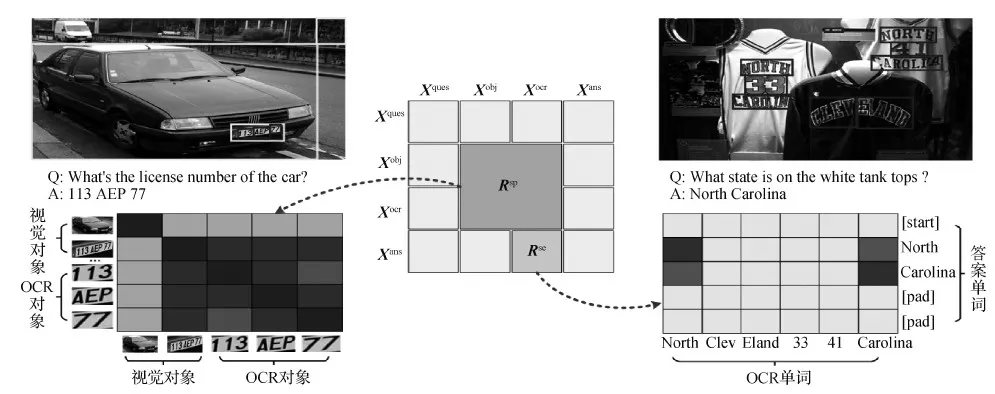
图4 空间关联知识表征与语义关联知识建模示意图Fig.4 Schematic diagram of spatial relationship knowledge representation and semantic relationship knowledge modeling

(2)
对于M+N个对象,使用上述方式得到相应的空间位置表征Xsp∈R(M+N)×(M+N)×4。进一步,将Xsp使用两层全连接网络,得到最终的空间关系知识表征Rsp∈R(M+N)×(M+N)。具体为
Rsp=relu∘line1∘relu∘lined(Xsp)
(3)
式中,relu表示ReLU层,∘表示两个层之间的顺序连接。
2)语义关联知识表征。部分问题也可能会涉及空间上不相邻的多个单词组合,如图4所示的North和Carolina。如何去挖掘这些单词之间隐含的语义关系,这直接影响最后预测的精度。此外,由于答案中单词来源由OCR单词和固定词汇表两方面组成,并通过两个独立的分类器预测得到,因此需要模型学习理解两种不同来源单词之间的语义关联。
为解决上述问题,本文在OCR对象对应的单词与预测的答案输出单词之间构建语义关联知识,使用预训练的词向量表征之间的相似度计算单词之间的相对语义关系。具体而言,给定第i个OCR对象对应的单词和预测答案的第j个单词,它们对应的GloVe(global vectors for word representation)词向量(Pennington等,2014)表征为ei和ej。使用两个词向量间的余弦相似度(cossim)作为对应单词相对语义关系,即
(4)
给定N个OCR对象和长度为T的答案,通过对所有答案单词和OCR单词进行计算,得到语义关联知识表征Rse∈RT×N。对于长度不足T的答案,使用一个特殊单词[pad]表示。[start]、[end]和[pad]这3个特殊单词与OCR单词之间的相似度不进行计算,并将其设置为0。
3)知识表征增强自注意力模块。在原生M4C模型中,多模态融合得到的特征Z输入由L个自注意力模块堆叠而成的Transformer编码器。每个模块由一个多头注意力(multi-head attention,MHA)模块和一个两层感知机构成的前向神经网络(feed-forward networks,FFN)模块堆叠而成。MHA利用h个并行的自注意力函数的输出特征拼接,形成多个注意力函数融合的多样性特征表达。其中,第j个自注意力函数定义为
headj(Z)=SA(linedh(Z),linedh(Z),linedh(Z))
(5)
(6)
式中,dh=d/h为每个注意力函数的输出特征维度,softmax表示softmax激活函数。
受Hu等人(2018)提出的空间关系建模方法的启发,本文将其应用在KR-M4C模型中,将式(5)中的自注意力函数改写为知识先验引导的自注意力函数。具体地,将Rsp和Rse合并后得到一个统一的知识表征矩阵R。为了使Rsp和Rse的数值范围相近,需要对Rsp进行变换,令Rsp=log(Rsp+ε),其中ε=10-6为预设的常数项,防止计算过程中的数值下溢。提出的知识表征增强自注意力函数KRSA(knowledge-representation-enhanced self-attention)为
(7)
式中,Q、K、V均对应特征个数为P=K+M+N+T的多模态拼接后的特征Z。为了实现式(7)中的知识融合,得到知识表征R∈RP×P,将Rsp和Rse按照图4所示的方式进行排布,R中其余位置使用0进行填充。需要指出的是,KRSA中Rsp和Rse的使用非常灵活,既可以支持两者同时输入,也可以支持任意一种知识输入。此外,当R为全0元素填充时,KRSA退化为标准的SA(self-attention)模块,对应标准的M4C模型。通过将KRSA与式(5)中多头注意力机制结合,得到知识表征增强的多头注意力模块KRMHA(knowledge-representation-enhanced multi-head attention),具体为
KRMHA(Z)=lined([head1(Z),…,headh(Z)])
(8)
4)KR-M4C主干网络。通过将原生M4C模型中的MHA模块替换为知识表征增强的KRMHA模块,KR-M4C的主干模型为L层的深度结构。具体为
(9)
(10)
式中,Z0=Z,norm()表示层标准化处理,FFN()表示2层感知机构成的前馈神经网络。输出特征ZL接入M4C中的自回归答案预测模块实现迭代式答案预测。
3 实 验
为验证本文KR-M4C的有效性,在场景文本视觉问答任务的TextVQA数据集和ST-VQA数据集上进行验证,并与现有的场景文本视觉问答模型的结果进行对比,对模型生成的样例进行分析。
3.1 实验设置
3.1.1 数据集

3.1.2 实现细节
实验环境为装载了Nvidia Titan Xp GPU的工作站。使用PyTorch框架(Paszke等,2019)实现KR-M4C模型。遵循先前的工作(Kant等,2020),模型设计和训练的超参数如表1所示。

表1 KR-M4C模型超参数Table 1 Hyperparameter choices for KR-M4C
3.2 消融实验
为了验证不同模型架构对KR-M4C的效果,在TextVQA 数据集上进行消融实验。为公平对比,消融实验中的所有模型使用Microsoft OCR提取图像中的文本信息,并使用主干网络为ResNeXt-152的Faster R-CNN模型进行视觉特征表达(Xie等,2017)。实验结果如表2所示。

表2 TextVQA数据集上的消融实验Table 2 Ablation experiments on the TextVQA dataset
1)不同类型知识的增强效果。以M4C模型架构为对照,验证不同类型知识引入后的增强效果。首先对比表2第1、3行结果,发现在模型层数相同(均为6层)情况下,本文提出的KR-M4C方法显著优于M4C方法(Hu等,2020),证明了引入知识表征增强的有效性。其次对比第1、3、4、5行结果,发现仅建模空间关联知识Rsp或语义关联知识Rse的方法均带来一定程度的性能下降,但相较M4C方法仍有一定提升,证明引入的两种知识均对模型具有一定程度的贡献,且两种知识具有良好的互补特性。最后对比第2、5行结果,尽管SA-M4C(Kant等,2020)和只包含空间关联Rsp的KR-M4C使用了相近的知识表征增强策略,但SA-M4C的空间关联建模粒度比KR-M4C更粗,因此其准确率稍逊于KR-M4C方法。
2)不同模块组合的影响。在SA-M4C(Kant等,2020)中,将不同类型的注意力模块进行组合,如2个M4C中标准的自注意力(N)和4个SA-M4C中的空间感知注意力模块(S),可以提升模型的表达能力。因此,在表2第3、8—11行的结果中,保持模型层数L= 6不变,探索不同类型的注意力模块即M4C中的标准注意力模块(N)和KR-M4C中的知识表征增强注意力模块(K)的深度组合方式对结果的影响。引入知识的6(K)架构的每一层都取得了最好效果,相比第7—9行中a(N)→(6-a)(K)架构准确率至少提升0.5%。但该结果与SA-M4C论文中的结果并不一致。原因或是SA-M4C的空间信息编码策略约束过强,在前几层中会削弱对问题语义的理解。相比之下,KR-M4C在每一层知识融合时引入了一组独立的可学习的参数,使模型可以自适应地学习在不同层中知识融合的程度,从而获得更好的融合效果。
3)不同堆叠深度的影响。保持L(K)的架构设计,探索不同深度L下模型的表现。从表2第3、10、11行结果可以看出,随着深度L从4增加到10,KR-M4C模型性能先上升然后逐渐下降。在L= 6时取得最优结果。造成该现象的原因是过深的模型会导致模型优化困难,限制了模型的表达能力。该问题或许可以通过引入更多的训练数据得到缓解。
3.3 与现有方法的对比实验
基于消融实验的结果,使用6(K)的最优架构在TextVQA数据集上与目前最好方法对比,包括LoRRA(Singh等,2019)、MM-GNN(multi-modal graph neural network)(Gao等,2020)、M4C(Hu等,2020)、SMA(structured multimodal attentions)(Gao等,2021)、CRN(cascade reasoning network)(Liu等,2020)、LaAPNet(localization-aware answer prediction network)(Han等,2020)和SA-M4C(Kant等,2020),结果如表3所示。额外训练数据表示除Text-VQA数据集以外的数据,如ST-VQA数据集。
表3展示了不同条件下(如特征提取主干网络、OCR系统和外部训练数据)的公平对比结果。特征提取主干网络包括基于Faster R-CNN的特征提取器与ResNet和ResNeXt两种主干网络的组合。OCR 系统包括各方法采用的OCR系统。大部分方法沿用了M4C 中的策略,使用Facebook提供的Rosetta-ml和Rosetta-en系统(Borisyuk等,2018),SA-M4C采用了识别性能更好的Google OCR 系统。本文使用了总体效果更好的Microsoft OCR系统。从实验结果中可以得到如下结论:1)在使用 Rosetta-en OCR系统、Faster R-CNN主干网络使用ResNet-101的条件下,KR-M4C在验证集和测试集上准确率为41.78%和42.99%(第7行),相比最好结果提升1.1%和2.5%;2)增加ST-VQA数据集作为额外训练数据,KR-M4C在验证集、测试集上准确率分别为42.78%和43.51%(第10行),均为同等条件下的最好结果;3)将OCR系统由Google OCR系统替换成效果更好的Microsoft OCR系统,在不增加额外数据的情况下,KR-M4C模型结果相较于同等条件下的SA-M4C模型,在验证集上准确率提升1.7%(第13行);4)增加ST-VQA数据集作为训练数据,KR-M4C模型在验证集和测试集上准确率最好,分别为49.27%和49.63%,比同等情况下的SA-M4C分别提升了1.3%和1.1%。
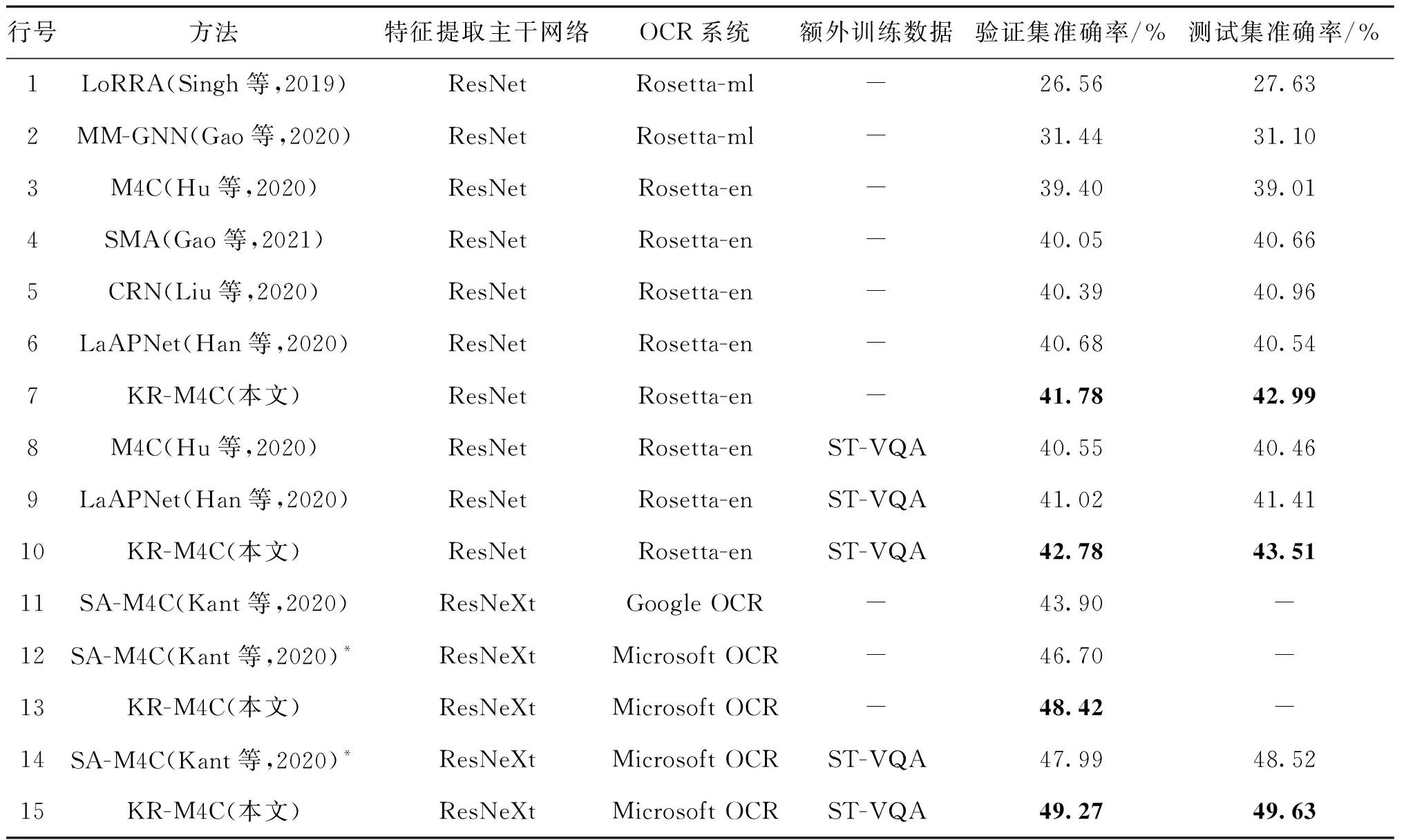
表3 TextVQA数据集上与现有最好方法的对比结果Table 3 Comparative results with existing state-of-the-art methods on TextVQA dataset
为进一步验证KR-M4C方法的有效性,在ST-VQA数据集上也进行了对比实验,结果如表4所示。可以看出,KR-M4C方法比现有最好结果在验证集上的准确率提升了4.7%,在验证集和测试集上的ANLS指标均提升了5%。

表4 ST-VQA数据集上的结果Table 4 Comparative results on ST-VQA dataset
此外,为进一步分析M4C、SA-M4C和KR-M4C模型之间的差异,对算法的模型尺寸和复杂度进行对比,结果如表5所示。可以看出:1)6(R)的KR-M4C相较6(N)的M4C和2(N)+ 4(S)的SA-M4C,模型参数量和FLOPs几乎没有增长,这是因为KR-M4C模型在式(6)中引入的模型参数和计算量相比Transformer主干网络几乎可以忽略;2)相比M4C和SA-M4C,KR-M4C在平均推理时间上用时分别增加48%和12%,增加的时间主要用于计算预测答案单词与OCR单词之间的余弦相似度。如何优化这部分计算过程以进一步提升方法的计算效率是未来拟开展的重要工作。

表5 模型复杂性的对比结果Table 5 Comparative results of model complexity
3.4 典型样例分析
为了更好地理解KR-M4C的表现,本文挑选若干典型样例进行分析,相关结果如图5所示。可以看出,1)KR-M4C相比M4C和SA-M4C获得了总体上更好的结果,体现了引入知识增强后模型对场景文本理解能力的提升。2)SA-M4C和KR-M4C在涉及相对空间关系时的表现相比M4C具有明显优势,可以准确回答“What is the first word on the top left of the boy’s t-shirt on the left?” 这样需要复杂空间推理才能准确回答的任务。3)得益于KR-M4C建立的语义关联知识,模型可以发现预测答案与OCR单词间隐含的语义关联,因此在涉及多个单词的答案时表现比只考虑空间关联的SA-M4C方法表现更好。4)面对部分场景信息确实,需要“联想”能力才能理解的复杂场景时,所有方法均表现不佳。这反映了现有场景文本视觉问答框架的性能瓶颈,有待后续更深入的研究。

图5 M4C、SA-M4C和KR-M4C模型的预测结果示例Fig.5 Examples of the predictions of M4C, SA-M4C and KR-M4C models
4 结 论
本文提出一种融合知识表征的多模态Transformer的场景文本视觉问答方法,在基线方法M4C基础上引入“空间关联”和“语义关联”两种互补的先验知识,提出知识表征增强的KR-M4C模型,实现两种知识与多模态数据的统一建模表达。本文在TextVQA和ST-VQA两个常用的场景文本视觉问答数据集上进行实验验证,相比现有最好方法取得了明显的性能提升。本文提出的知识表征增强的多模态Transformer框架具有通用性,除了应用于场景文本视觉任务,也为其他相关多模态学习任务的方法改进提供了平台。
相比现有方法,本文提出的KR-M4C方法带来了显著的性能提升,但其性能受限于外部的OCR系统的识别能力。如何在模型中引入OCR识别模块,进行端到端的联合优化是未来一个有意义的研究方向。此外,现有方法的性能与人工标注的训练样本数量紧密相关。如何突破这种标注数据制约,利用天然的弱标注数据实现模型的预训练以支撑更大更深模型的有效训练,进一步提升模型的表达能力也是值得探索的重要方向。
猜你喜欢
计算机应用与软件(2022年5期)2022-07-07
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
成长·读写月刊(2018年8期)2018-08-30
长江学术(2015年1期)2015-02-27
新课程学习·中(2013年3期)2013-06-14
计算机辅助工程(2012年5期)2012-11-21
中学数学研究(2008年3期)2008-12-09
