
基于DeepFM和XGBoost融合模型的静脉血栓预测①
2022-09-20 04:12李莉,谢超,吴迪
计算机系统应用 2022年9期
李 莉, 谢 超, 吴 迪
(江苏大学 计算机科学与通信工程学院, 镇江 212013)
1 引言
外周穿刺置入中心静脉导管(PICC)技术是一种从周围静脉导入且末端位于中心静脉的深静脉置管技术, 已经广泛用于中长期静脉治疗手段. 随着PICC置管技术的广泛使用, 其产生的多种并发症及不良反应被医疗工作者所发现, 例如穿刺点出血或感染、穿刺形成静脉炎症或血栓、败血症和局部感染. Abdullah等人[1]提出PICC相关性血栓是PICC置管技术产生的常见且严重的并发症之一. PICC相关性血栓多发生于置管的插入位置[2]以及插入过程由于穿刺、导管直接损伤血管内膜或者基于患者自身基础性疾病影响.因此, 在置管前进行及时的发现和干预能够有效预防血栓的形成.
机器学习方法被广泛运用于医疗领域. Nafe等人[3]使用机器学习方法, 建立了一种新型的学习模型rML绘制血栓的风险概率, 根据风险对患者进行识别和分组, 具有重要的临床意义. Ryan等人[4]使用梯度增强方法拟合决策树, 并用XGBoost机器学习方法将多个决策树结果进行组合, 从而获得血栓风险预测概率.Liu等人[5]通过癌症患者的数据收集, 提出了一种基于LASSO回归的随机森林方法构建了LASSO-RF模型, 用于筛选与血栓形成有关的高风险因子, 能够对PICC相关性血栓进行更精确的评估, 以指导早期预防治疗.Sukperm等人[6]使用逻辑回归、决策树、前馈神经网络、支持向量机和随机森林5种机器学习方法, 对573例患者进行数据进行训练, 通过模型效果对比得出支持向量机具有最佳的模型性能, 能够进行有效血栓风险预测. 实验结果证明, 使用多种机器学习方法构建预测模型, 能够有效地对血栓风险进行评估, 从而辅助临床医学诊断, 对于那些具有高PICC相关性血栓风险的患者, 提前作出判断并尽早干预.
本文提出了一种基于机器学习和深度神经网络方法的PICC相关性血栓预测模型, 构建了一种基于DeepFM和XGBoost的融合模型, 并使用模型基本评价指标来对模型效果进行验证. 本融合模型能够有效地对PICC相关性静脉血栓进行风险预测, 指导临床识别血栓高危风险因素, 提前采取治疗或护理措施对高危患者进行药物或者物理干预, 从而降低患者发生血栓的概率.
2 数据预处理和模型方法
2.1 数据集来源
本研究中引入的所有模型均在同一数据集上进行验证. 本数据集来自于某临床医学数据, 每个实例有30个属性. 包括有原发肿瘤部位、药物性质、深筋脉血栓史、C反应蛋白浓度等人体实际测量指标. 其中,原发肿瘤部位包含4个部位, 纵隔上、纵隔下、全身和头颈部, 由整数1-4表示; 药物性质包含其他药物、化疗、血管生长抑制剂、表皮生长受体酪氨酸酶抑制剂、激素和内分泌, 由整数0-5表示.
2.2 数据预处理
该数据集具有不完整性和维度差异, 因此针对缺失值数量对数据进行筛选. 将包含大量缺失值的患者数据进行剔除, 包含少量缺失特征的数据以及异常数据进行数据填补.
使用随机森林的方法, 通过对原有数据进行训练来进行有误数据的填补. 同时进行数据无量纲归一化,能够将不同量纲的数据进行处理, 使每个变量指标具有同等表现力.
(1)缺失值处理
本临床医学数据集在实际收集构建的过程中, 会产生部分特征项遗漏的情况, 因此需要针对缺失特征数量进行部分删除或者缺失值填补操作. 本数据集具有30维特征, 我们选择直接删除缺失特征数量大于5的实例, 将缺乏少量特征的数据实例使用随机森林的方法进行缺失值填补, 利用随机森林算法进行缺失值填补的流程如下:
Step 1. 首先输入不包含缺失值的PICC相关性血栓数据集作为样本集S:
S={(x1,y1),(x2,y2),···,(xM,yM)}
其中, M为不包含缺失值的样本数.
Step 2. 将数据划分为训练集和测试集, 进行n轮训练(n ∈{1,2···,M}).
Step 3. 在训练的过程中进行n次Bootstrap采样,得到采样后的样本集Sn.
Step 4. 将第n个随机采样样本集Sn输入到第n个决策树模型Gn(x)中. 在训练决策树时, 在样本中选取效果较好的作为决策树的左右子树.
Step 5. 将n轮训练得到的回归预测结果进行算术平均得到预测输出.
(2)无量纲归一化处理
本模型是基于DeepFM和XGBoost的融合模型,首先需要将连续特征按照统一方法缩放至[ 0,1]区间内,这样能够消除数据之间尺度和单位度量的影响, 使得不同量纲之间的数据处于同一量级, 加快梯度下降的收敛速度[7], 提高模型学习效率. 数据无量纲归一化处理计算公式如式(1):
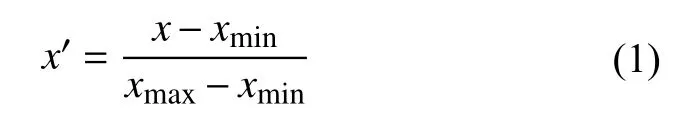
x′和 x 分 别为归一化前后数值, xmin和 xmax分别为同一特征最小值和最大值. 部分无量纲化数据如表1.
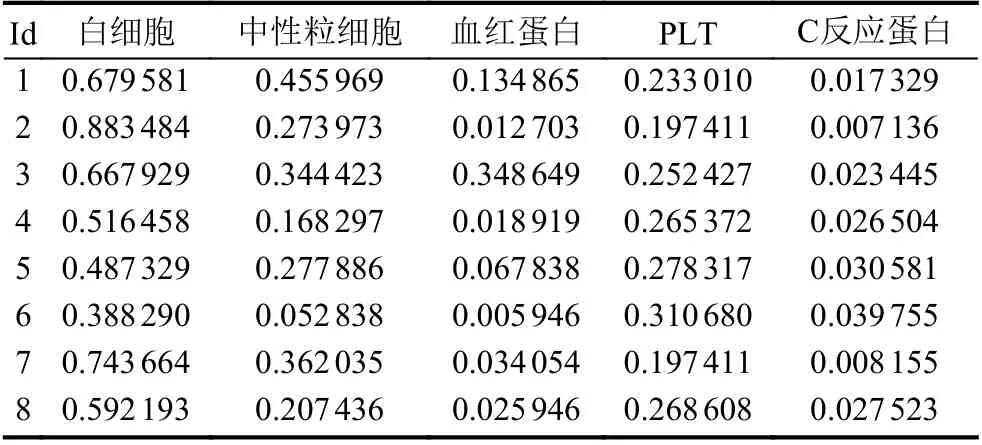
表1 部分无量纲归一化数据
3 基于DeepFM和XGBoost的融合模型
本PICC相关性血栓临床医学数据具有较多特征值为零的情况, 部分特征组合属于稀疏数据. 部分包含0的特征数据如表2所示.

表2 部分稀疏数据
针对这种稀疏数据, 采用基于深度神经网络的DeepFM模型. DeepFM是一种集成了深度神经网络和FM模型的方法, 能够进行稀疏数据的特征组合[8],避免过拟合情况. XGBoost模型同为线型分类器, 能够在目标函数的定义中添加正则化项[9], 具有较好的稀疏感知能力, 适用于本PICC相关性血栓临床医学数据.通过将DeepFM和XGBoost进行模型融合, 不仅能够对本数据集具有可解释性, 还能够具有更好的模型效果, 融合模型能够保持较高准确性的情况下指导临床识别血栓高危风险因素, 及时对血栓风险进行干预, 起到辅助诊断作用.
3.1 DeepFM模型
DeepFM模型是一种继承了深度神经网络和FM模型的方法, 能够有效地结合低阶和高阶的数据特征. 通过将同一数据分别输入FM模型和DNN中, 并使用Sigmoid进行组合得到预测输出.
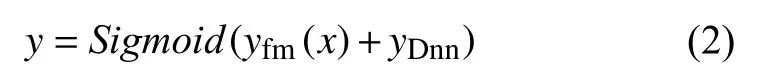
其中, yfm(x) 是 FM层的输出, yDnn是 神经网络层的输出.
FM即因子分解机, 于2010年由Rendle[10]提出,它融合了SVM模型和因子分解法, 能够学习到特征之间的相互关系. 特别是处理稀疏数据时, SVM等模型会产生过拟合现象, 此时FM能够筛选出合适的特征组合. FM模型的思想是基于线性回归模型[11], 一般的线性模型可表示为:
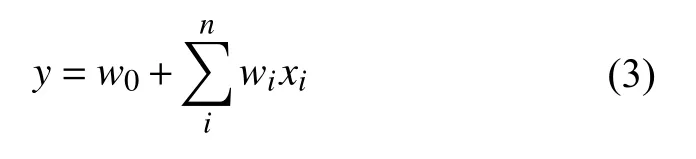
而基于FM的特征融合模型在线性模型上考虑到了特征之间的关联性. 以二阶度量为例, 此时FM线性模型可表示为:
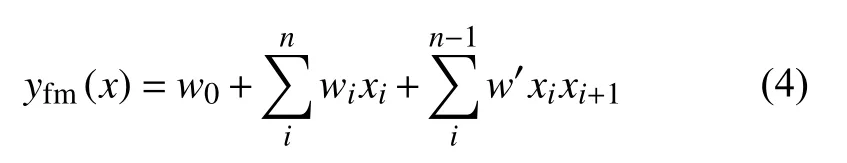
其中, n 表示总项数, w0表示偏置参数, wi表示第i项的权重, xi表 示第i项的值, w′表示第i项与第i+1项之间的关系进行建模.
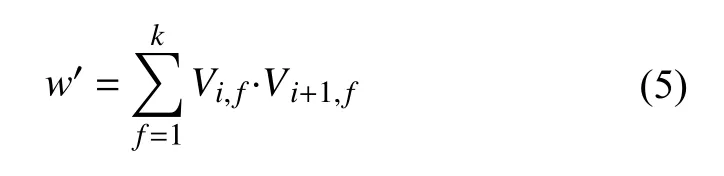
其中, f表示[ 1,k]个 变量参数, Vi,f·Vi+1,f表示系数矩阵V中第i和第i+1维向量的点积.
Deep组件是一种深度神经网络, 能够发挥深度神经网络的特性进行高阶稀疏数据的学习[12].
嵌入层 e1的结构如图1所示, 假设其神经元数目k=3, Vi,f为FM层中潜在的特征向量, 将其作为网络训练权重, 则每个输入只有一个神经元有效, 其值为1.通过结合FM层的特征向量 Vi,f作为网络权重输入至深度神经网络, 实现了一个端到端的模型. 嵌入层的输出表示为:
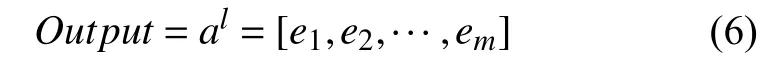
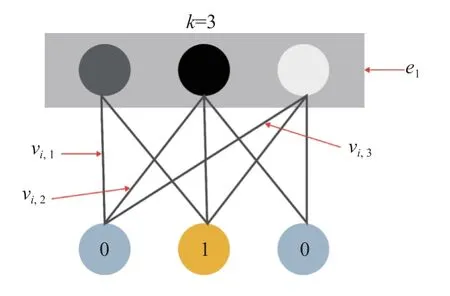
图1 嵌入层结构
然后将其输入到深度神经网络, 可表示为:
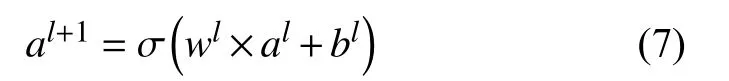
其中, al+1为 下一层的输出值, σ为激活函数, wl、al和bl分别为层数为l的权重、输出和偏差项. 则最终预测输出yDnn为:
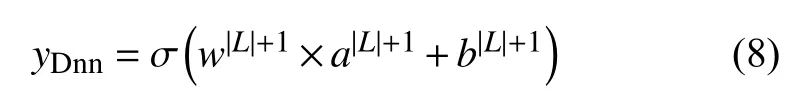
3.2 XGBoost模型
XGBoost是基于梯度下降树GBDT的机器学习方法, XGBoost是具有回归树结构[13], 其决策规则与决策树相同, 内部节点代表着预测的贡献值, 叶子结点代表着预测分数, 最终的预测结果是所有树的预测之和.
首先定义目标函数 O bj , 目标函数O bj 由损失函数和正则项组成.
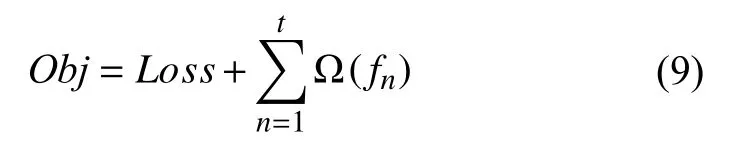
其中, Loss 是真实值yi与预测值之间的损失函数,m为样本数量, 其计算公式如式(10):

Ω(fn)是抑制每棵树复杂度的正则项, 其计算公式如下:
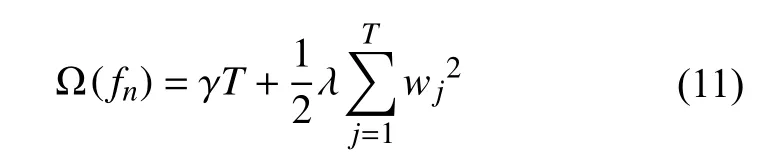
其中, γ 和λ 为常数项系数, T 为总叶子结点的数目,wj为每个叶子结点预测的分数, 则最终预测输出

其中, xi是 第i次训练的样本, fm(xi)是第n棵树的训练分数.
3.3 模型融合
本PICC血栓预测模型是基于DeepFM和XGBoost的融合模型, 首先构建DeepFM模型, 利用模型对线性模型的记忆能力和对深度神经网络的学习泛化能力的特点对数据进行训练并预测. 在训练过程中通过优化其学习率、神经元保留比率等参数使得模型效果达到最优; 然后构建XGBoost模型, 通过调整正则化项等参数优化模型效果; 最后进行模型融合, 使用单一模型DeepFM和XGBoost在测试集上进行血栓概率预测得到 Pd和 Px, 将两个模型预测血栓概率值进行加权求和获得融合模型血栓预测概率Pnew.
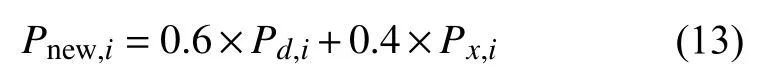
其中, Pnew,i为融合模型获得的第i个测试样本的血栓预测概率, Pd,i和Px,i表示分别使用DeepFM和XGBoost对第i个测试样本的血栓预测概率. 结合判定指标和预先设定的概率阈值判断血栓发生情况.
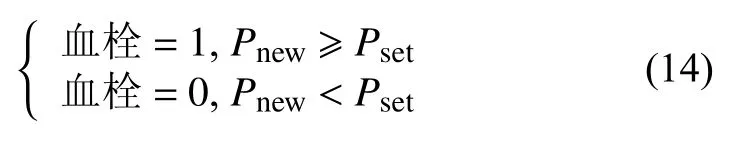
其中, Pset为试验后确定的血栓患病概率阈值.
使用上述判定指标获得模型融合后的患者血栓预测情况, 将其与训练真实值进行对比获得模型评价指标. 实验结果表明, 融合模型相比较DeepFM和XGBoost单一模型在效果上均获得有效提升.
4 模型实现流程
对采集的数据集进行预处理, 填补缺失值和统一量纲, 在处理后的数据样本中随机抽取80%作为训练集, 20%作为测试集, 分别输入DeepFM和XGBoost并进行模型融合.
4.1 模型评价
融合模型目的是预测PICC相关性血栓的发生风险概率. 选取精确率、F1指标和AUC来评价模型效果. 在一个二分类问题中, 如果一个实例是正类, 且被预测为正类, 就是真正类(TP); 如果是负类, 被预测为正类, 为假正类(FP); 如果一个类是真负类被预测成负类, 称为真负类(TN); 如果一个真正类被预测为负类,称为假负类(FN).
精确率(Acc)为预测的正例的总数和总样本之比,计算公式为:
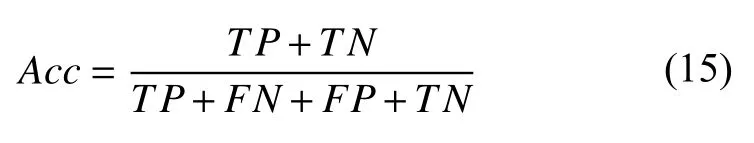
F1是一种综合评价模型指标, 能够有效地展示精确率和召回率的情况, 计算公式为:
ROC针对的是二分类模型[14], 即输出结果只有两类. ROC曲线的 x 轴 和y 轴分别为假正类(FP)的概率和真正类(TP)的概率. AUC是ROC曲线与 x轴围成的面积[15], 随机挑选一个正样本以及一个负样本, AUC 的值则为分类器判定正样本的值高于负样本的概率. 能够有效地评价模型的预测性能, 其取值范围一般在[ 0.1,1].
4.2 模型对比
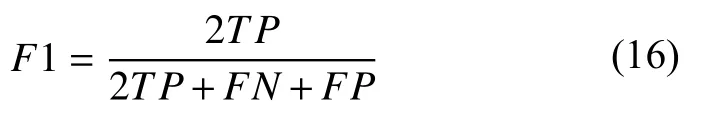
将PICC相关性血栓临床医学数据输入DNN、DeepFM、XGBoost以及其融合模型进行训练. 经过训练得出DNN、DeepFM、XGBoost以及其融合模型的ROC曲线如图2-图5所示.
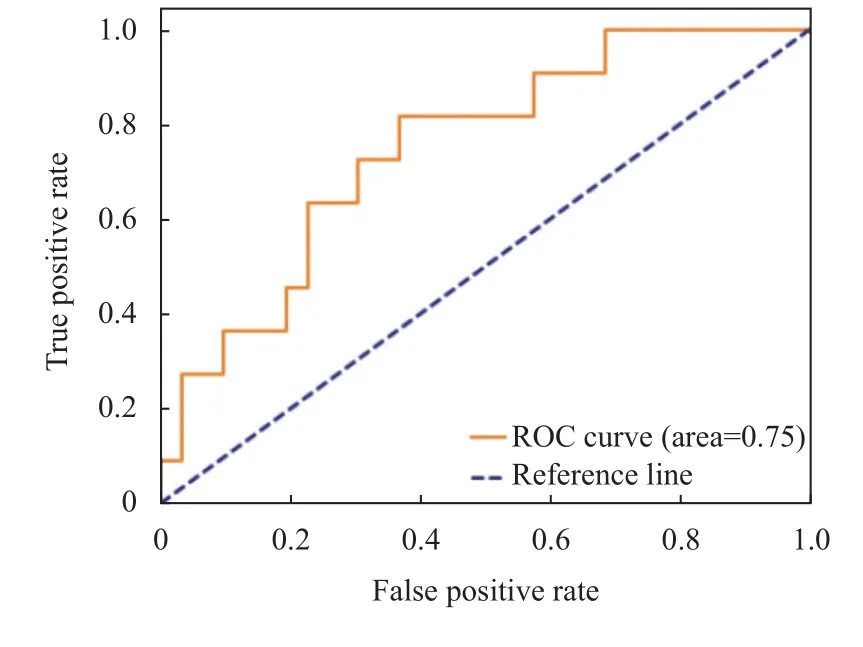
图2 DNN的ROC曲线
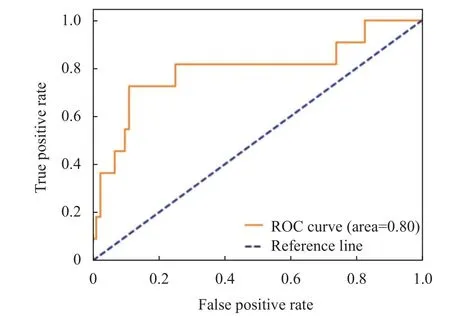
图3 DeepFM的ROC曲线
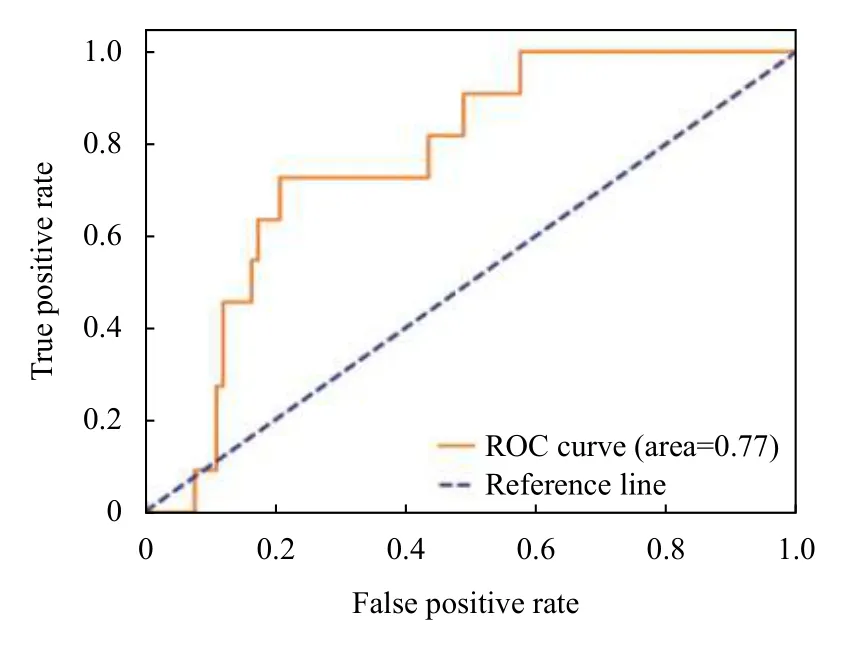
图4 XGBoost的ROC曲线
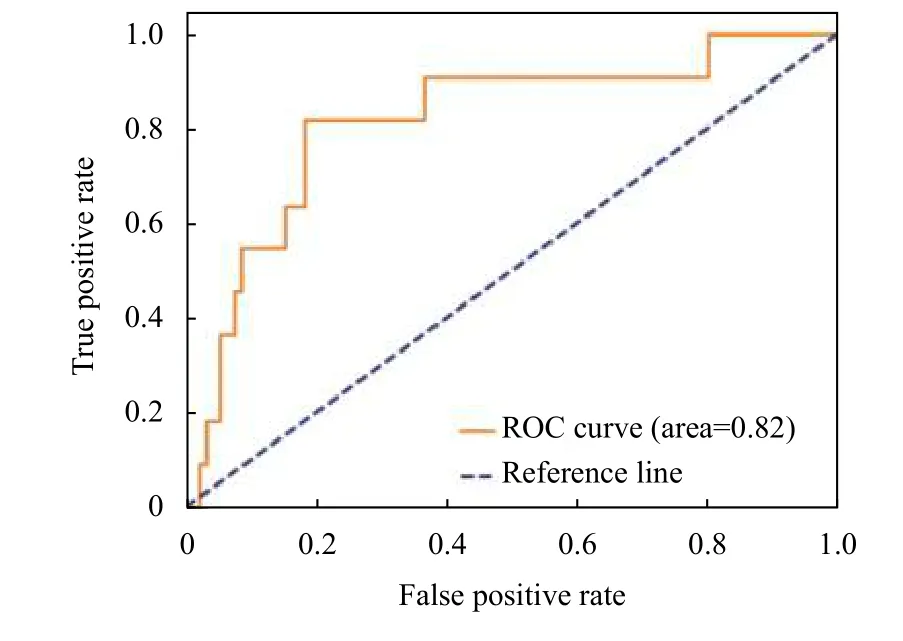
图5 DeepFM和XGBoost融合模型ROC曲线
根据图2和图3对比可以看出单一的深度神经网络DNN在ROC的取值上低于融入深度神经网络和FM模型方法的DeepFM模型, 因此证明DeepFM模型能够有效地解决过拟合问题.
根据ROC曲线可得, 基于DeepFM和XGBoost的融合模型在利用PICC相关性血栓临床医学数据对血栓进行预测能够在20%的假阳率下准确预测出83%的PICC相关性血栓数据, 能够为临床置管前提供有效的辅助诊断.
基于DeepFM和XGBoost的融合模型得出的重要性特征图如图6所示. 重要性特征图能够展示与PICC相关性血栓有关的特征重要程度[16], 从而辅助临床医护工作者判断哪些特征对PICC相关性血栓产生更显著的影响. 如图6所示, 其中尖端是否最佳位置、转移部位高危、深静脉血栓史、急性感染等影响因素为模型所得重要特征, 与医学先验资料相符. 由于影响PICC相关性血栓的特征较多, 导致临床医护工作者很难从众多病人数据中找到重要的影响因素, 因此可以结合本融合模型所得的特征重要性, 更加关注病人重要信息来提前采取预防措施和干预手段, 降低血栓对患者的影响.
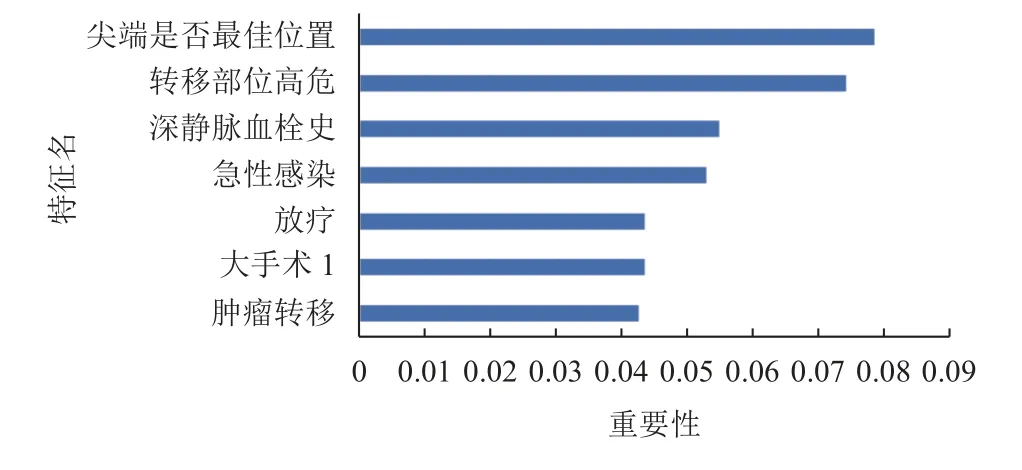
图6 特征重要性
根据实验结果和ROC曲线得出模型精确率、F1指标和AUC对比如表4所示.
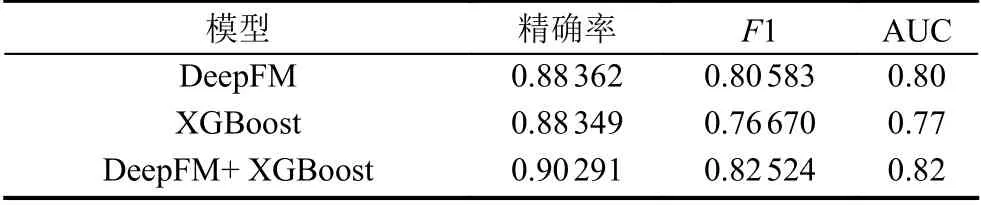
表3 模型精确率、F1和AUC指标对比
从表4可以看出, 针对PICC血栓预测融合模型,其精确率、F1指标和AUC均高于单个机器学习和深度神经网络模型. 融合模型在精确率上比DeepFM和XGBoost分别高出了1.929%和1.942%, 在F1指标上比DeepFM和XGBoost分别高出了1.941%和5.854%,在AUC上比DeepFM和XGBoost分别高出了3%和5%, 在模型效果上均有显著提升.
由上述模型评价指标可知, 基于DeepFM和XGBoost的融合模型相比较单一模型得到了最优的效果, 证明模型融合的合理性和有效性, 因此可以使用基于DeepFM和XGBoost的融合模型进行PICC相关血栓风险的预测与评估, 有利于医护人员对血栓高风险患者进行及时干预, 最大化降低患者由于置管血栓所造成的影响.
5 结论
本文是一种基于DeepFM和XGBoost的融合模型, 使用了机器学习和深度神经网络结合的方法对外周穿刺置入中心静脉导管(PICC)置管血栓进行风险预测. 通过从患者入院检查数据中进行选取有效特征,分别输入DeepFM和XGBoost模型进行训练, 然后使用模型融合方法对模型效果进行优化.
实验结果表明, 基于DeepFM和XGBoost的融合模型在模型评价指标和效果上均优于单一模型, 证明了融合模型的可行性. 本PICC血栓预测模型能够帮助临床在置管前对患者进行血栓风险预测, 对较大血栓风险的患者提早进行药物或者物理干预, 最大化减小血栓对患者本身所带来的影响, 在PICC置管血栓领域具有重要意义.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
华声文萃(2020年4期)2020-05-19
家庭医药(2020年4期)2020-05-14
文萃报·周二版(2020年10期)2020-03-17
老年博览·上半月(2019年4期)2019-09-10
软件(2017年6期)2017-09-23
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
