
基于自学习边权重图卷积网络的用户用能分类①
2022-09-20 04:11李文峰邓晓平孟宋萍
计算机系统应用 2022年9期
李文峰, 邓晓平, 彭 伟, 孟宋萍
(山东建筑大学 信息与电气工程学院, 济南 250101)
智能电表作为一种末端设备, 在智能电网中早已得到了广泛的应用. 智能电表记录的高分辨率数据涵盖了消费者用电行为的海量信息, 为分析用户能耗行为提供了重要参考. 同时, 电力服务部门和公司开始以用户为导向, 通过深入挖掘用电数据和客户潜在需求,提供稳定, 安全, 便捷, 高效, 环保的个性化综合用能服务. 用户分类是智能电表数据分析的重要领域, 旨在通过智能电表数据对不同的负荷或用户进行分类. 通过对智能电表数据进行分类, 电力部门不仅可以了解区域内不同用户的特征及构成, 改善用户用电质量, 还可根据用户分布协调区域用能总量, 提高资源利用率. 因此, 用户分类在电网智能化发展和智能电表数据应用上具有重要意义, 并在能耗预测[1], 窃电检测[2]和个性化电价设计[3]等其他领域发挥着重要作用.
用户分类的方法可分为无监督分类方法和监督分类方法. 其中, 无监督分类方法以聚类[4]作为主要的分类手段, 常用的方法包括模糊C均值算法[5], 层次聚类[6]和自组织映射[7]等. 但上述方法的分类性能受算法参数, 先验知识和异常数据的影响. 因此, 无监督方法不适合大规模数据集和复杂场景下的分类任务.
监督分类方法旨在建立用能数据与用户标签之间的映射关系, 从而实现用户分类. 随着深度学习的兴起,许多深度学习方法开始被应用于有监督的用户分类领域, 如极限学习机[8], 深度置信网络[9]和卷积神经网络[10]等. 在文献[11]中, 研究人员使用递归算法去除冗余特征, 并提出了一种基于极限学习机和支持向量机的混合网络以实现用户分类和预测. 文献[12]构建了一种基于卷积网络的分类架构, 并在该分类网络上实现了多种优化算法的性能比较. 除此之外, 文献[13]通过基于样本的过采样方法解决分类数据不平衡问题,并在此基础上构建长短期网络提取用户特征, 输出用户类别. 该方法有效提高了在不平衡数据集上的分类精度. 但深度学习方法的提取特征多为抽象特征, 难以直观表示数据之间的相互关系. 此外, 各种分类方法在用户分类的精度仍需进一步提高.
近年来, 图神经网络[14]作为一种新兴的深度学习技术, 已成功地应用于多领域分类任务中, 如图像识别[15], 文本分类[16]和交通预测[17]等. 与现有方法相比,图神经网络不仅可以直观地表示数据之间的关系, 而且特征学习也更加多样化. 因此, 图神经网络在用户用能分类领域提供了一条有效的思路, 但需要解决由离散数据到图数据的转化问题.
在相关工作的启发下, 本文提出了一种基于自学习边权重的图卷积网络分类方法(AEW-GCN), 实现了不同社会信息下的用户分类. 本文的主要贡献为: (1) 构建了一种自学习边权重的图卷积分类网络, 通过构建图卷积分类器, 提高了用户分类的准确率; (2) 给出了一种基于注意力机制的图转化方法, 实现了由智能电表数据到图数据的自动转换, 并自动学习图数据特征,从而减少了对人工特征的依赖; (3) 在实际数据集中与现有分类方法进行了对比, 在不同社会信息下的分类实验验证了本文方法的有效性和优越性.
1 相关介绍
1.1 用户用能分类问题
用户用能分类旨在寻找用户能耗数据与用户标签之间的最优映射函数. 用户用能分类过程如图1所示,其主要包括用户特征的表示和用户分类两个过程. 特征表示是将实例从输入空间映射到特征空间的过程.假设用户能耗数据为 X, 用户标签为Y , 特征表示的过程可表示为:

其中, C f 是用户特征, E 是特征提取函数, θe为特征函数的参数.
对于已知的用户特征C f 和用户标签Y , 用户分类的过程是通过构建分类器筛选用户特征并根据相应特征输出用户类别, 此过程可表示为:

由上述特征表示和分类过程可以得出, 分类问题的实质在于寻找一组最优参数, 该组参数使得网络的分类正确率最高或误差最小.
1.2 图神经网络
图是一种特殊的数据结构, 它对实例(节点)进行建模, 并表示实例之间(边)的关系. 在一个图中, 节点的数据及其邻居节点的边包含了大量的潜在信息. 图神经网络旨在从节点数据及其边中提取所需的特征,并根据提取的特征输出相应的结果. 图神经网络的学习过程可以表示为:
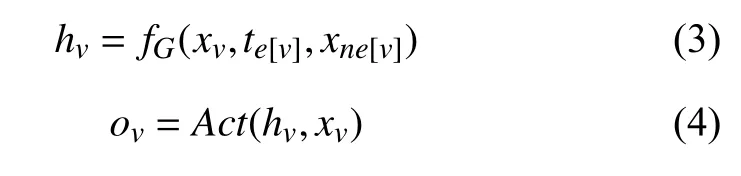
其中, hv为特征向量, fG为图神经网络内置函数, xv,te[v]和 xne[v]分别为节点数据、节点的边权重和邻居节点数据. A ct 和ov为激活函数与网络输出. 图神经网络的学习过程可由图2表示.
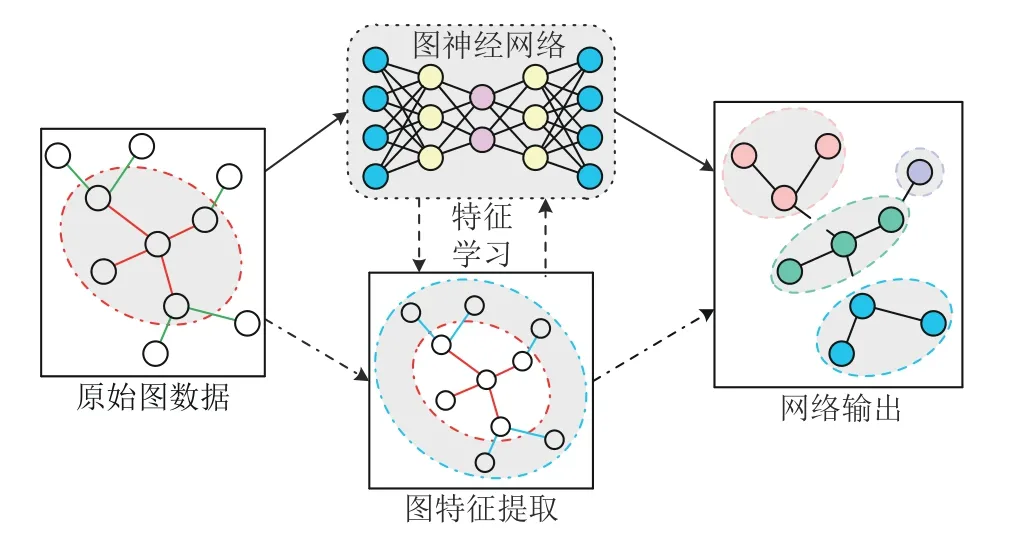
图2 图神经网络学习过程
2 自学习边权重的图卷积分类网络
本文提出了一种自动学习边权重的图卷积分类网络(AEW-GCN), 其利用图卷积网络构建分类器, 并引入带有注意力机制图转化方法 能够有效提升用户分类的精度, 自动学习特征并减少对人工特征的依赖. 该网络由3部分组成, 分别为图初始化层、特征提取与变换层和图卷积分类层. 其中, 图初始化层完成图数据转换, 特征提取与变换层实现图上特征的提取和筛选, 图卷积分类层输出最终分类结果, 整个分类网络的架构如图3所示. 下面将对网络的每个部分展开介绍.
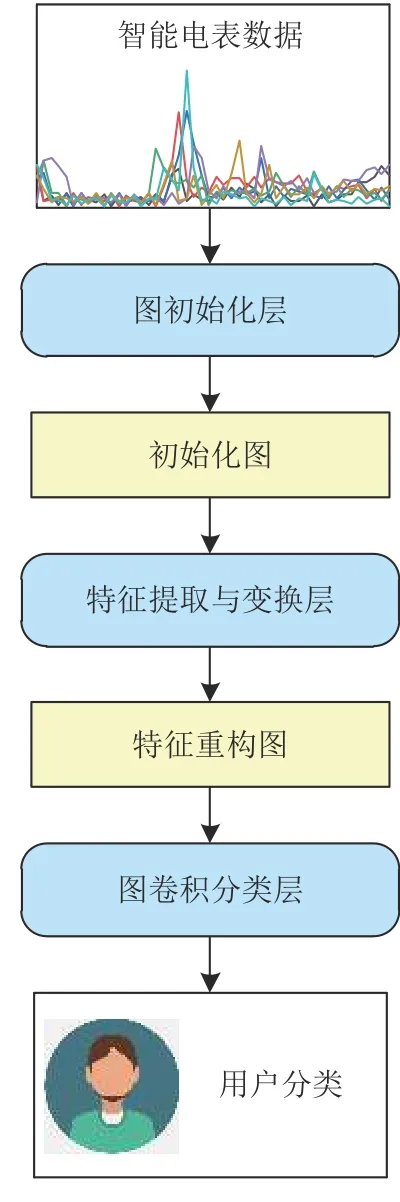
图3 自学习边权重图卷积分类网络图
2.1 图初始化层
由于原始用能数据不能直接被图神经网络处理,为此, 本文建立了一个带有注意力机制的图初始化层以实现由原始数据到图数据的转化. 图初始化层主要有两个功能, 一方面, 图初始化层将原始时间序列数据转化为无向完全图; 另一方面, 注意力机制的应用使得网络能够自动学习图的边的权重参数, 并随网络更新参数. 将原始数据转化为图的过程分为以下几个步骤.
首先, 能耗数据由GRU-CNN混合层处理, 该混合层由一层GRU和CNN堆栈而成. 混合层的目的是提取原始数据的时序特征, 并输出状态参数R. 状态参数R的计算过程可表示为:
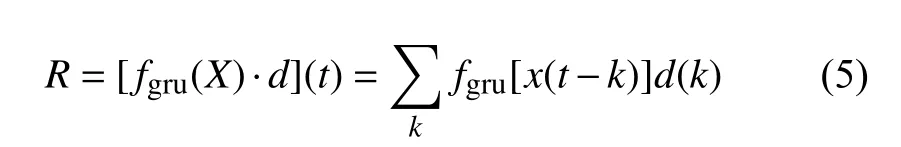
其中, X 为输入数据, fgru是 GRU网络内置函数, d是卷积核, k为卷积通道数.
其次, 图初始化层以状态参数R 作为初始值, 根据注意机制计算节点权重矩阵W . 权重矩阵的计算过程可表示为:
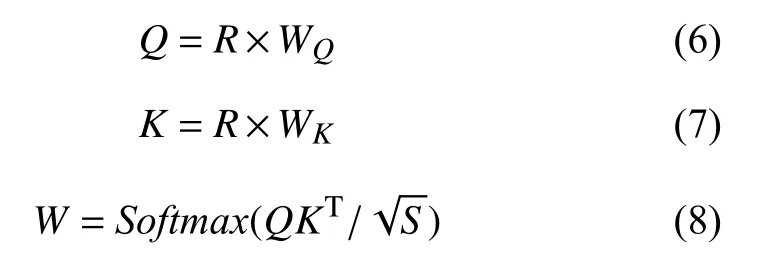
其中, Q和 K 为查询值和键值, WQ和WK分别为 Q 和 K 的参数, S为输入的维度, Softmax表示Softmax函数.
最后, 图初始化层以权重矩阵W 作为邻接矩阵, 生成图数据. 生成的图数据可表示为:

其中, Xv是 节点数据, N 为图上节点数目.
2.2 特征提取与变换层
特征提取与变换层旨在提取图中的特征并输出新的特征重构图. 为了更全面地提取图数据特征, 本文引入图傅里叶变换(GFT)和离散傅里叶变换(DFT)作为特征提取方法. 其中, 图傅里叶变换可以充分考虑图结构特点, 离散傅里叶变换则提取节点数据特征. 特征提取过程可表示为:

其中, G和F 分别为图傅里叶变换与离散傅里叶变换,Gf为特征数据.
特征提取完成后, 本文使用多层门控线性单元(GLU)对特征进行筛选, 为提高原始特征的利用率, 本文在特征筛选中引入跳跃连接机制, 这使得每一层GLU网络输出由当前层和它之前层的输出共同决定.第 p层的特征筛选过程可表示为:
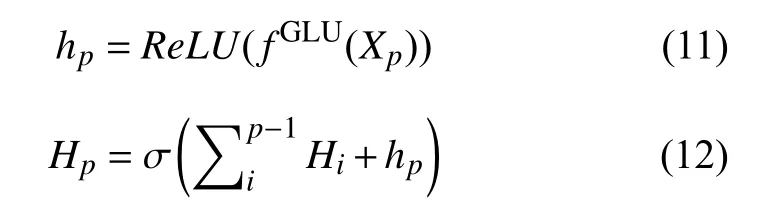
其中, Xp是第p 层输入, fGLU表 示GLU内置函数,ReLU为ReLU函数, Hi为 p 层 之前的特征输出, Hp为 第 p层输出, σ为Sigmoid函数. 特征筛选网络架构可如图4所示.
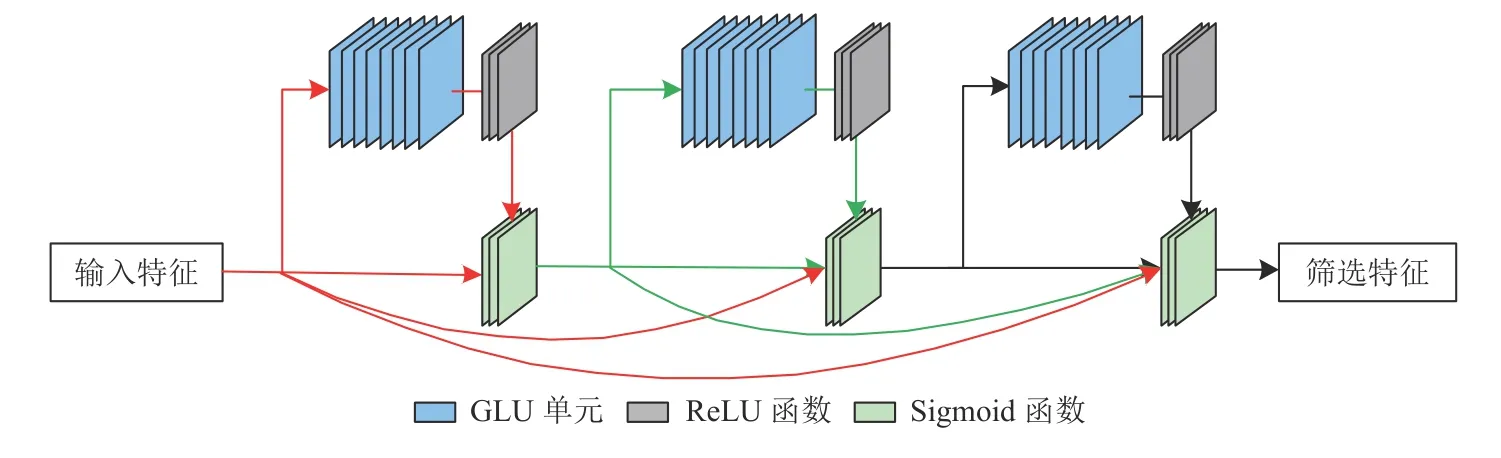
图4 特征筛选网络架构
根据筛选特征, 特征重构图可被表示为:
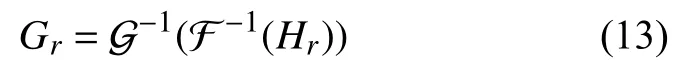
其中, G-1和F-1分别表示图傅里叶与离散傅里叶的逆变换过程, Gr代表输出特征重构图, Hr为重构特征.
2.3 图卷积分类层
图卷积分类层实现特征重构图上的卷积运算, 并输出分类结果. 图上的卷积过程可表示为:
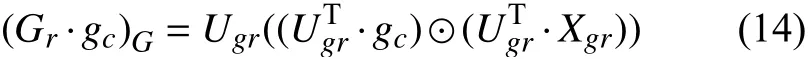
其中, Gr是特征重构图, Xgr为重构节点数据, gc是图卷积算子, Ugr是重构特征图的特征向量矩阵, ⊙表示哈达玛积.
为了减少卷积运算中的参数和计算量, 本文使用切比雪夫卷积核代替传统的图卷积核, 则图卷积过程可被重新表示为:
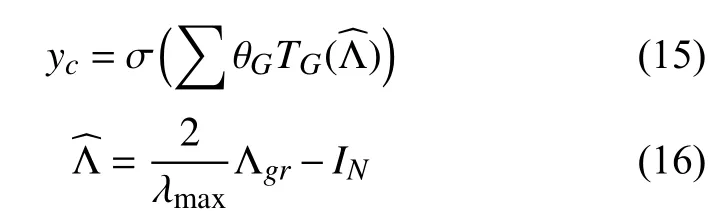
其中, yc为卷积输出, θG和TG为切比雪夫卷积核参数,可由特征重构图的特征值矩阵Λgr计 算得出, λmax是中最大的特征值, IN为单位矩阵, σ是Sigmoid函数.
最后, 网络通过全连接层输出最后的分类结果︿y ,该过程可表示为:
其中, Wu和 bu是 全连接层的参数与偏置值, σ为Sigmoid函数.
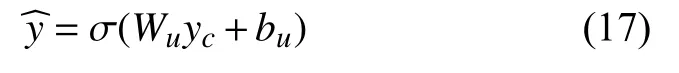
3 实验
3.1 实验数据
本文所采用的实验数据是由爱尔兰能源管制委员会(CER)[18]提供, 该委员会提供了包含了超过4 300个用户530天的电力和天然气消费信息. 数据采样间隔为30 min. 为了充分证明该方法的有效性, 本文选取70%的数据进行训练, 10%的数据作为验证集, 剩余20%的数据作为测试集. 此外, CER数据集中还包含两份问卷, 问卷中包含了用户的人口统计学信息、生活方式和家庭规模等多种社会信息. 本文从问卷中选取了4种典型的社会信息, 并将每种社会信息下的不同类别作为智能电表数据的标签, 以此实现不同社会信息下智能电表数据的用户分类, 并验证所提出方法的有效性. 本文所选的4种社会信息及其类别如表1所示.
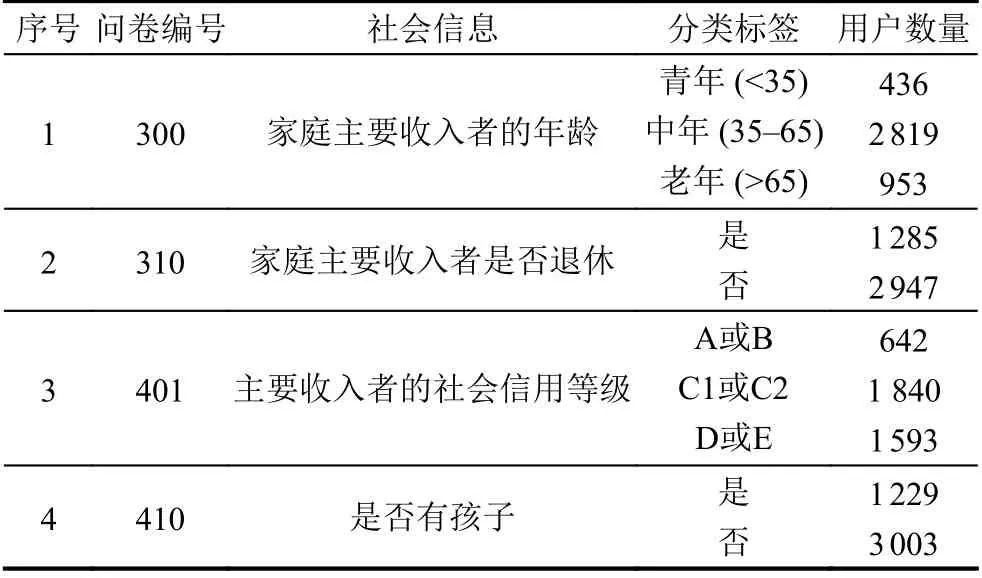
表1 智能电表数据的社会信息及分类表
3.2 对比方法
为了充分验证本文提出的方法的性能, 本文将提出的方法与3种典型的分类方法进行了比较, 下面对对比方法进行简要介绍.
(1) 支持向量机(SVM): 支持向量机是一种分类领域的典型方法, 因此, 本文将SVM方法作为对比方法之一. 在SVM方法中, 原始数据将不做任何处理直接输入至SVM网络中.
(2) 主成分分析支持向量机(PCA+SVM): PCA是一种常用的数据处理手段, 本文应用PCA方法对原始用能数据进行降维处理, 并选取一定数量的相关特征作为SVM网络的输入. 由于特征数目影响分类精度,我们选择实验中精度最高的特征作为该方法的精度.
(3) 卷积神经网络(CNN): 与支持向量机相比, 卷积神经网络可以自动学习数据特征并输出用户类别.本文也将其作为一种典型的分类方法进行比较.
3.3 性能指标
考虑到多个用户信息分类的不平衡性, 本文使用准确率(Acc)和F1值对模型进行用户分类性能评估.Acc代表了分类正确的样本数占样本总数的比例, 它能够客观评价模型在多类别中的分类能力. F1值是精确率(Pre)和召回率(Rec)的调和均值, 可作为模型在不平衡数据集上性能的重要参考. 在实际分类任务当中,模型的Acc与F1越高, 表示模型的分类性能越好. 相关公式表达如下:
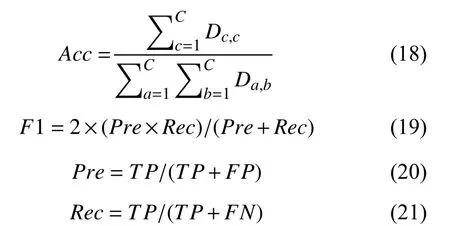
3.4 实验配置
本文使用交叉熵损失函数[19]作为目标函数以评估模型的优劣, 具体表达为:
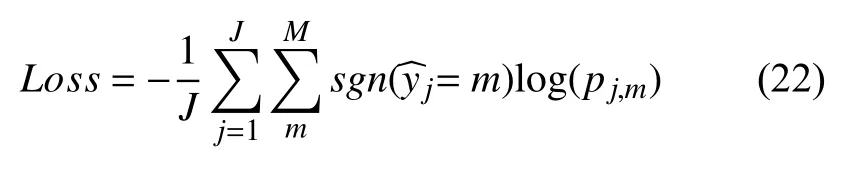
其中, J 为样本总数, M 为类别数, m是样本实际类别,sgn 为符号函数, pj,m代表样本 j 被分入m 类的概率.
在模型训练过程中, 采用Adam优化算法[20]以寻找最优参数. 与传统的梯度下降法相比, Adam优化器计算当前梯度的一阶动量和二阶动量以实现自适应参数优化, 这种优化方式使得梯度更新过程更加平滑, 具有更好的寻找最优解的能力. 决定Adam优化器的参数主要有学习率α, β1, β2和 ε, 通常分别设为0.001, 0.9,0.999和1 0-8.
3.5 实验结果
本文方法在不同社会信息上的分类准确率和F1值如表2所示. 在4种不同社会信息中, 准确率和F1值得均值分别为74.9%和71.9%, 分类模型在#2社会信息(主要收入者是否退休)和#4社会信息(是否有孩子)的正确率均超过80%, 在#1社会信息(主要收入者年龄)的准确率超过75%, 在#3社会信息(主要收入者的社会等级)的分类准确率保持在60%左右. 其中,在#3社会信息上的分类结果说明用户社会等级并不能显著影响用户用能行为. 从以上结果来看, 本文提出的AEW-GCN方法能够实现基于用户信息的分类任务.

表2 AEW-GCN分类结果
表3和表4分别显示了对比方法对4种社会信息分类的准确率和F1值. 可以看出, 所有方法在4种社会信息上的分类性能分布相似, 它们均在#2社会信息和#4社会信息上表现出较好的分类性能. 这证明了这两类社会信息可以用于区分不同的用户. 在3种对比方法中, 与原始SVM方法相比, 使用主成分分析(PCA)进行特征处理的分类性能略有提高(其分类性能在Acc上提升为1.2%). 与两种SVM方法相比,CNN的分类效果得到了更好的结果, 其分类性能在两种评价指标上提高了约3.2%和3.8%. 与上述方法相比, 本文提出的方法则实现了进一步的性能提升, AEWGCN方法的分类准确率分别提高了10.9%, 9.7%和6.5%, F1值提高了12%, 16.4%和9.2%, 这充分证明了本文所提出的方法在基于社会信息的用户分类上的有效性和优越性.
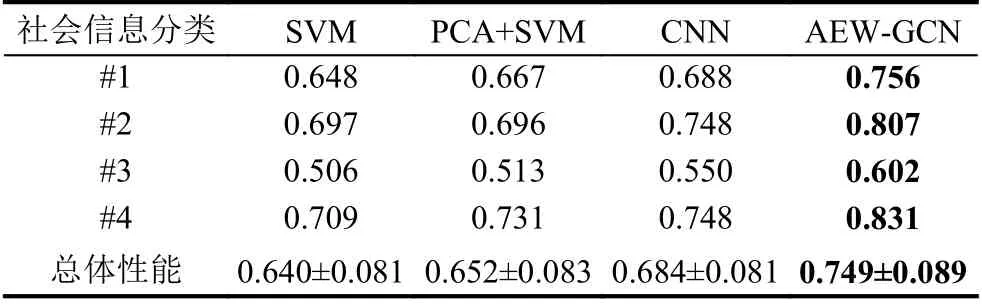
表3 不同方法在4种社会信息分类的准确率
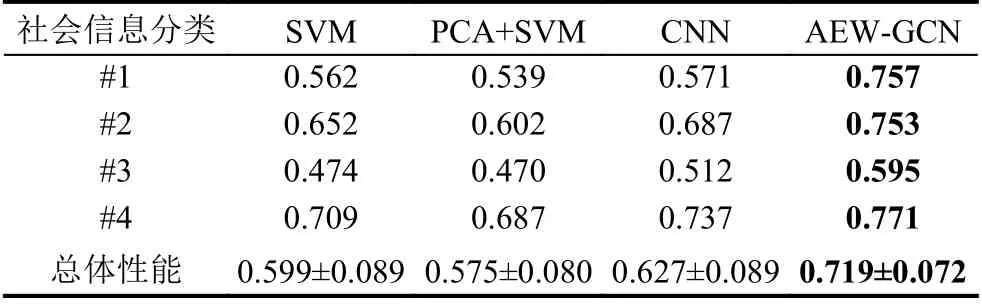
表4 不同方法在4种社会信息分类的F1值
4 结语
本文提出了一种自学习边权重的图卷积网络, 实现了不同社会信息下智能电表数据的用户分类. 该方法引入注意力机制实现图的初始化, 利用包括傅里叶变换在内的多种手段进行特征提取和特征选择, 最后应用图卷积层输出分类结果. 为了证明本文方法的有效性, 我们在智能电表数据集上与其他分类方法进行了比较. 实验结果表明, 本文提出的方法取得了较好的分类性能. 在今后的工作中, 我们将进一步探讨所提方法在更多社会信息中的分类性能, 并在智能电表数据的用户分类过程中考虑环境和天气因素对用户用能行为的影响.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
数学大王·低年级(2018年5期)2018-11-01
环球时报(2018-09-11)2018-09-11
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
