
基于YOLOv5的多任务自动驾驶环境感知算法①
2022-09-20 04:11:28张凯祥
计算机系统应用 2022年9期
张凯祥, 朱 明
(中国科学技术大学 信息科学技术学院, 合肥 230027)
随着卷积神经网络的快速发展, 自动驾驶越来越多地出现在我们的视野中, 成为研究人员重点研究的领域. 在自动驾驶中, 环境感知是至关重要的, 可以为控制系统提供不可或缺的环境信息, 保证车辆的正常行驶. 自动驾驶的环境感知一般包括目标检测、车道线检测以及可行驶区域分割. 目标检测主要用于检测行驶道路上的道路交通标志、周边车辆、行人等, 使得车辆可以遵守道路交通规则, 避让行人. 车道线检测是用于提取道路的边缘线, 用于自动驾驶车辆的定位和纠偏, 是平稳安全行驶的重要保障之一. 可行驶区域分割是将自动驾驶车辆行驶的道路进行全景分割, 并检测其中可行驶的区域, 前方道路阻塞, 障碍物挡道等情况下, 可保证车辆行驶安全.
近年来, 人工智能技术的革新进一步推动了自动驾驶领域的发展. 对于单任务的环境感知方法, 目标检测算法通常分为两阶段目标检测和单阶段目标检测[1],两阶段目标检测算法首先对输入图像提取候选框, 再根据第一阶段选定的候选框拟合最后的检测结果, 可以更好地处理类别不均衡的问题, 检测精度更高, 但由于需要进行两阶段计算, 速度较慢, 无法满足实时检测场景; 单阶段目标检测则同时进行分类和检测, 直接生成物体类别概率和位置坐标, 提高了检测速度, 但精度有所下降. 基于卷积神经网络的车道线检测通常作为语义分割任务对输入图片进行分类, 通过后处理拟合出最后的车道线, 但由于车道线像素较少, 造成了类别不平衡的问题, 降低了检测的准确率. 可行驶区域分割一般也是作为语义分割任务, 对输入像素进行二分类,从而分割出背景和可行驶区域.
然而自动驾驶场景需要同时获取道路上的多种信息, 单个任务的环境感知方法无法满足需求, 因此多任务自动驾驶环境感知算法成了开发人员的迫切需要.多任务的环境感知算法通常结合多个任务的特点, 设计符合要求的骨干网络, 多个分支之间共享参数, 从而减少计算量.
基于YOLOv5网络[2], 本文提出了一个用于多任务自动驾驶环境感知算法, 如图1所示, 可根据单张输入图片端到端地输出目标检测, 车道线检测和可行驶区域分割的结果. 编码部分以改进的YOLOv5作为骨干网络, 解码时目标检测头仍使用YOLOv5检测头, 车道线检测和可行驶区域分割作为两个语义分割任务共享骨干网络, 在解码部分采用实时语义分割网络ENet头[3]进行解码, 由于分割任务和目标检测任务存在一定的差异, 因此本文为分割任务单独增加一个FPN结构[4], 以获得更好的分割效果.

图1 多任务环境感知算法处理结果
1 相关工作
1.1 单任务环境感知方法
基于卷积神经网络(CNN)的目标检测根据有无候选框的生成分为两阶段目标检测和单阶段目标检测,对两阶段目标检测算法, Girshick等人首次提出用含有CNN特征区域进行目标检测的算法R-CNN[5], 效果显著优于基础传统图像特征的方法, 但由于存在大量冗余的特征计算, 速度比较低. Lin等人提出了空间金字塔池化网络[4], 使得CNN只需要计算一次特征图,避免了反复计算卷积特征. Ren等人提出Faster-RCNN检测算法[6], 引入了区域生成网络, 是第一个端到端的实时目标检测网络, 但其网络的检测部分仍存在冗余计算. 对于单阶段目标检测算法Redmon等人首次提出单阶段目标检测算法YOLOv1[7], 完全抛弃了提取候选框再验证的检测范式, 而是将图像分割成多个区域, 同时预测每个区域的边界框和检测分类, 但其对于小物体的定位效果较差. Redmon等人先后发布了YOLOv2[8], YOLOv3[9], 通过引入类似于ResNet的残差结构以及FPN等操作, 提高了检测精度. Bochkovskiy等人提出YOLOv4[10], 以CSPDarknet53作为骨干网络, 引入空间金字塔池化(SPP)模块等, 大幅度提高了检测的速度和精度. 同年, Ultralytics提出YOLOv5[2],通过基于训练数据集自动适应锚点框等不仅减少了模型大小, 还大大提高了训练收敛的速度, 根据网络不同的深度和宽度实现了s, l, m, x四个版本, 本文在YOLOv5s v6.0的基础上进行相关算法的实现和改进.
可行驶区域分割是以语义分割任务进行处理的,语义分割是计算机视觉的另一个关键任务, Long等人首次提出全卷积网络FCN[11]用于语义分割. 随后Chen等人[12]提出Deeplab系列的分割网络, 提出了空洞卷积扩大了感受野, 在空间维度上实现金字塔型的空间池化. Zhao等人提出PSPNet[13], 新增金字塔池化模块用于聚合背景并采用了附加损失. 由于以上语义分割的速度都达不到实时, Paszke等人提出实时语义分割网络ENet[3], 使用bottleneck模块以更少的参数量获得更高的精度.
车道线检测方面, 基于深度学习的方法常分为基于语义分割的方法和基于行分类的方法. Pan等人提出基于分割的车道线检测网络SCNN[14], 设计了一个特殊的3D操作, 能够更好地获取全局特征. Hou等人提出基于知识蒸馏的车道线检测算法SAD, 增强了多种轻量级车道线检测模型如ENet-SAD[15], 并在多个数据集取得SOTA效果. 为了提高实时性, 降低计算量, Qin等人提出基于分类的车道线检测算法[16], 转换为逐行分类任务, 提高了检测速度.
1.2 多任务环境感知方法
多任务环境感知是单个深度学习模型能够同时完成两个或两个以上的检测任务, 不同任务之间通过共享参数等减少计算量, 并且有关联的检测任务相互促进可以达到更好的拟合效果. Teichmann等人提出基于编解码结构的多任务网络MultiNet[17], 可同时处理目标检测, 路面分割和场景分类3个任务, 3个任务共享编码结构, 使用3个不同的解码器得到3个任务的结果, 但其在目标检测解码阶段缺乏尺度信息, 对于不同大小的物体检测效果一般, 分割部分采用FCN结构存在较多冗余计算, 速度较慢. Qian等人提出DLT-Net[18],在子任务解码器之间构建了上下文张量共享参数, 能够同时处理目标检测, 车道线检测和可行驶区域分割3个任务, 但由于这种共享方式也导致该网络在车道线稀疏的场景表现效果不佳. Wu等人提出实时多任务网络YOLOP[19], 也是同时处理DLT-Net中的3类任务,只是在参数共享部分, 3个任务仅共享了编码阶段, 在解码时单独处理, 该网络在BDD100K数据集[20]上取得了SOTA效果, 但由于未考虑到分割任务和目标检测任务的差异性, 导致在车道线检测方面的准确率较低.
1.3 本文工作
为了在自动驾驶中同时进行目标检测, 车道线检测和可行驶区域分割, 本文贡献如下: 1) YOLOv5s作为骨干网络, ENet作为分割分支设计了多任务自动驾驶环境感知网络; 2) 在车道线检测任务和可行驶区域分割任务前设计独立的FPN结构, 以提高车道线检测和可行驶区域分割的准确率; 3) 损失计算时使用更优越的 α -IoU[21]计算方法. 实验表明, 本文所提算法优于当前流行的多任务深度学习网络YOLOP等.
2 算法设计和实现
本节从网络结构, 损失函数两部分进行详细介绍本算法结构.
2.1 网络结构
整个网络的结构如图2所示, 网络由特征提取模块, 空间特征池化模块, 检测模块组成.
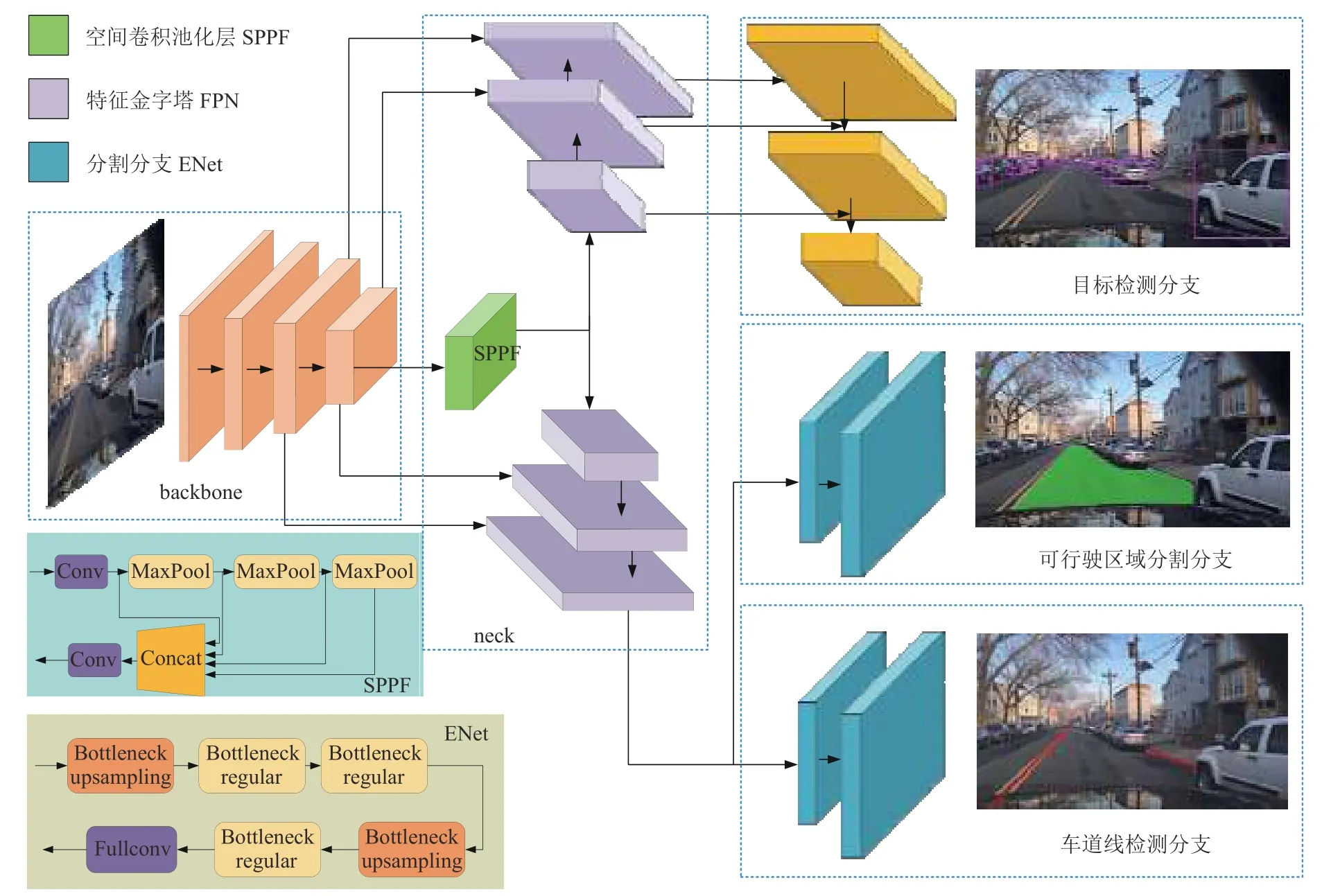
图2 基于YOLOv5的多任务自动驾驶环境感知算法网络结构
(1) 特征提取模块
本文使用YOLOv5s[2]的CSPDarknet作为特征提取模块, 以3通道的图片作为输入, 经过多层卷积后得到的特征图为原图的1/32, v6.0版本YOLOv5的特征提取模块有以下特点. 第一是使用一个等效的卷积层替换了Focus层, 不仅提高了运算速度, 更方便导出模型; 第二是使用模块C3取代之前的BottleneckCSP, 降低了卷积层的深度, 也取消了Concat层之后的卷积层,以达到更快的速度. 第三是标准卷积中封装了3个模块, 包括卷积(Conv2d)、批量标准化(BatchNorm2d)、激活函数, 标准卷积的激活函数使用SiLU函数, 该函数的数学表达式如下所示:
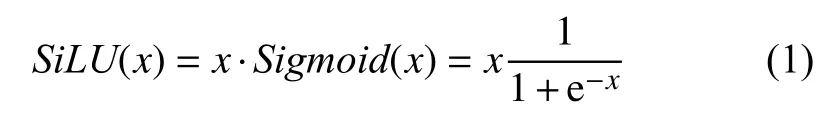
Sigmoid函数在趋向无穷的地方, 容易造成梯度消失, 不利于深度神经网络的反向传播, 而SiLU函数的一阶导数则更加平缓, 更适合提取更深层网络的特征.
(2) 空间特征池化模块
在编码器和解码器之间有一层空间特征池化层,该层包括快速空间卷积池化层(SPPF)和特征金字塔层(FPN), 如图2所示, SPPF层由两个标准卷积层和3个MaxPoll层以及相加层组成, 相对于原YOLOv5的SPP层, 将MaxPool层的kernel_size统一设置为5,通过级联的方式连接3个MaxPool层, 不仅精度未下降, 还大大提高了推理速度. SPPF层主要用于提取不同尺寸的特征图, 将不同感受野的特征融合, 有利于检测不同尺度的物体. FPN实现的具体步骤如表1所示, 表中以输入大小为640×640的3通道图片为例,FPN层的输入是SPPF层的输出, 为原尺寸的1/32,经过多层卷积以及尺度参数为2的上采样层, 经过Concact层与编码器不同尺度的特征融合, 最终得到特征金字塔, 用于下游的检测和分割任务. 本文在实验中发现目标检测任务和其他两类分割任务存在明显差异, 目标检测任务关注的更多是全局特征, 而分割任务则更关注像素级特征, 应设计独立的FPN结构, 以辅助分割分支更好地获取输入图像特征, 拟合最终的结果.

表1 FPN网络结构具体实现
(3) 检测模块
本文将3个任务分别用3个检测头来完成, 目标检测任务的检测头和YOLOv5保持一致, 将车道线检测视为分割任务, 与可行驶区域分割任务一样, 都采用ENet检测头. 如图2所示, 目标检测检测头的输入是自顶向下的FPN结构的不同尺度的特征, 再经过一个自底向上的路径聚合网络(PAN), 最终经过检测头输出不同尺度的计算结果. 为了达到实时检测的效果, 本文的分割任务采用和ENet类似的检测头, Bottleneck upsample层是将卷积和上采样层聚合的模块, Bottleneck regular层由3层卷积和激活函数以及Dropout层构成,Dropout层用于提高模型泛化能力, 防止过拟合, ENet的检测头部的输入是FPN的最后一层的输出特征, 经过多层Bottleneck层后通过全卷积层输出分割结果,由于本文都是二分类, 因此最后的特征图大小是(2, W,H), 分别代表背景类像素和目标像素的概率.
2.2 损失函数
本文的损失函数计算包含3个分支的部分, 目标检测分支的损失记为 Ldet, 该部分的损失包含分类损失Lclass, 回归损失Lbox和 置信度损失Lobject, 3类损失加权后构成了目标检测部分的损失, 如下所示:
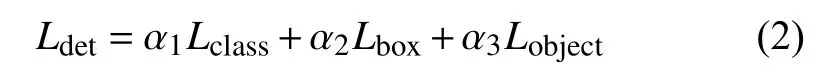
分类损失使用二分类交叉熵损失, 计算公式如下:
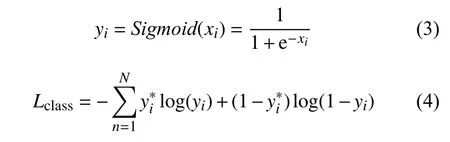
式(3)和式(4)考虑到一个物体可能属于多个类别的问题, N 表示类别总数, xi表示当前类别的预测值,yi代表经过激活函数后的当前类别的概率,表示当前类别的真实值(0或1).
边界框回归损失本文在YOLOv5的基础上进行改进, 原YOLOv5的回归损失采用的是CIoU, 计算公式如下所示:
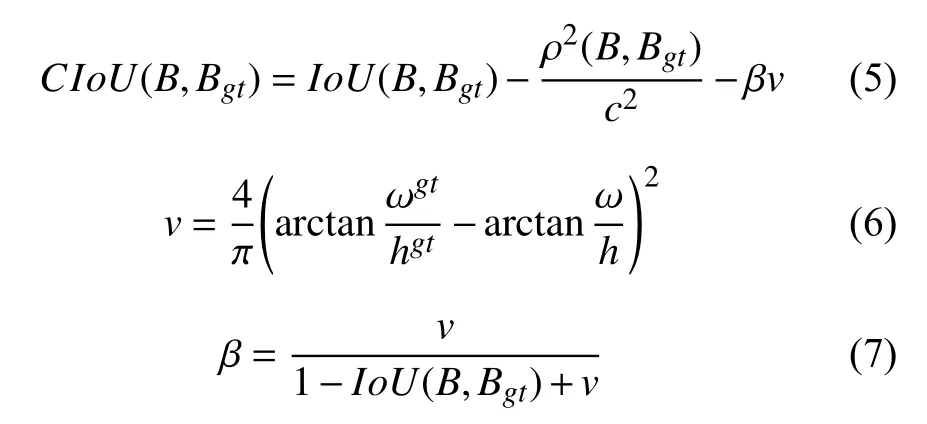
其中, ρ(B,Bgt)为目标框和真实框中心点之间的距离,c为包住目标框和真实框的最小外接框的对角线长度,v 用来度量目标框宽高比的一致性, β为权重函数. 本文在YOLOv5s v6.0的基础上, 使用α-IoU取代CIoU计算边界框回归损失, 计算公式如下:
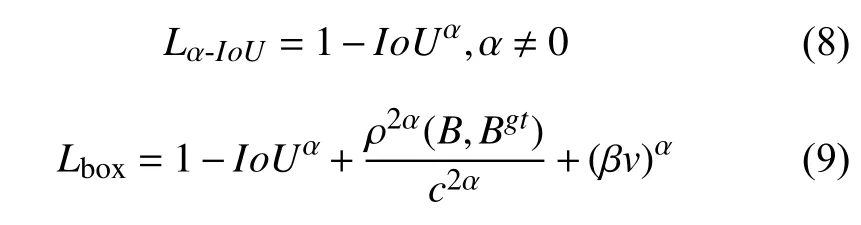
通过调节α, 可以使检测器在不同水平的边界框回归方面具有更大的灵活性, α大于1时有助于提高IoU较大的目标回归精度.
车道线检测损失 Lll和可行驶区域分割损失 Lda都包含交叉熵损失, 借鉴YOLOP的损失计算方法, 本文在车道线检测任务中也加入了IoU损失, 以提高车道线的检测精度, 最后总体的损失由3个任务加权后的损失组成, 计算如下所示:
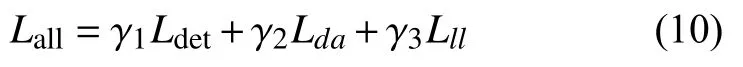
3 实验分析
3.1 数据集
本文测试数据集是BDD100K, 该数据集是目前最大规模, 内容最具有多样性的公开自动驾驶数据集, 共有100k张图片, 其中训练集70k张, 验证集10k张, 测试集20k张, 包含晴天、阴天、雪天、雨天、多云、有雾6种不同天气, 以及城市道路、隧道、高速公路、住宅、停车场、加油站6种不同场景.
3.2 实现细节
本文实验中训练时的warmup设置为3个epoch,初始的学习率设置为0.001, 优化器使用ADAM,β=(0.9,0.999), IoU阈值为0.2, anchor阈值设置为4.0,损失函数计算时, α设置为3, α1-α3, γ1-γ3设置为1. 因为BDD100K的测试集并未完全公开3类任务的标签,因此本文在70k张训练集图片上训练, 并在验证集上验证模型效果. 数据增强方面, 本文主要考虑到光照畸变和几何畸变, 光照畸变本文通过随机改变图片的色调、饱和度和亮度进行增强, 几何畸变本文通过随机旋转、缩放、平移和左右翻转等几何操作进行增强数据集, 以提高模型在不同环境中的鲁棒性. 本实验过程中测试FPS时使用的硬件配置如表2所示.

表2 实验所用硬件配置
3.3 实验结果
为了验证本算法的有效性, 本文分别从3个任务的检测结果与其他多种多任务环境感知算法对比, 本文和当前最好的多任务自动驾驶环境感知算法YOLOP的结果对比图如图3所示.

图3 实验结果对比图
从图3中我们可以看到, 在白天, 夜晚以及雨天的情景下, 我们的算法处理结果均优于当前最好的多任务网络YOLOP. 在第1张图片中, 本文的目标检测边界框回归更精准, 而YOLOP还出现了误检的情况; 第2张图片中, YOLOP的车道线检测出现了缺失, 过长等情况, 本文结果车道线拟合更准确; 第3张图片在雨天的情况下, 本文的结果仍比YOLOP的处理结果精度更高.
目标检测方面如表3所示, 本文对比了当前流行的多任务深度学习网络MultiNet[17], DLT-Net[18], 以及目前表现SOTA的YOLOP, 除此之外笔者还对比了单任务目标检测网络Faster R-CNN[6]和YOLOv5s[2], 关于速度的测试都是基于显卡NVIDIA GeForce 1080Ti进行的, 表中对比3个目标检测评价标准召回率、平均精度和帧率, 可以看出本文工作结果在多任务中取得了SOTA效果, 检测准确率比当前最好的多任务网络提高了0.9%, 速度也提高了0.9 , YOLOv5s的速度虽然比本文快, 但是该网络没有处理分割任务的能力.
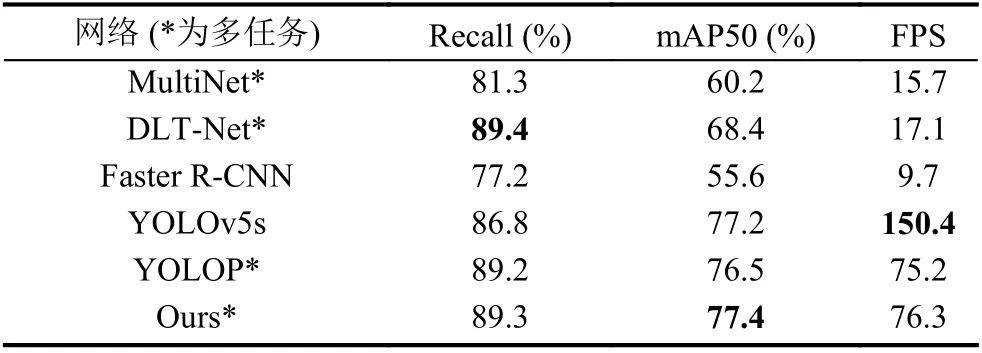
表3 目标检测结果对比
可行驶区域分割的结果如表4所示, 在对比时除了3个多任务网络还对比了单任务分割网络PSPNet[13],使用平均交并比(mIoU)来评价网络, 从结果可以看出本文结果在BDD100K和其他网络相比表现最佳.

表4 可行驶区域分割结果对比
车道线检测的结果如表5所示, 实验对比了多任务网络YOLOP以及一些传统的单任务车道线检测网络ENet[3], SCNN[14], ENet-SAD[15], 使用准确率和IoU评价网络的效果, 准确率的定义如下:
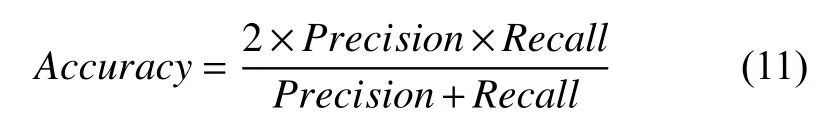

表5 车道线结果对比 (%)
为验证本文算法对于复杂场景的有效性, 本文对BDD100K数据集中的不同场景、不同时段的图片分别计算3个任务的检测性能, 结果如表6所示, 从表中可以看出本算法在各个场景下均优于YOLOP.
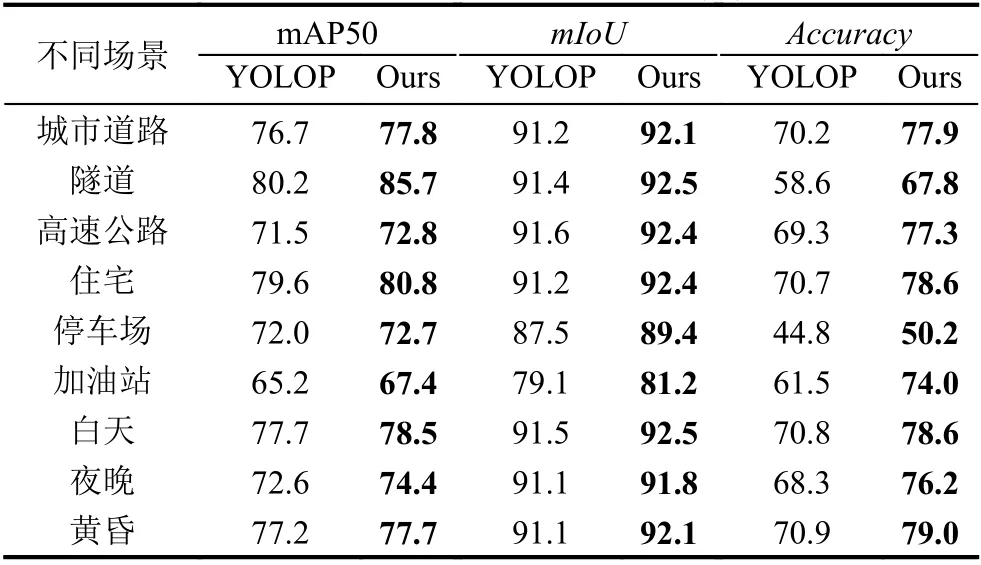
表6 不同场景下结果对比 (%)
3.4 消融实验
为了验证本文所提网络中用到的模块的有效性,本文做了如下消融实验, 采用普通的IoU计算方式和去除分割分支的独立FPN结构进行实验, 实验结果如表7所示.

表7 消融实验结果对比 (%)
表7中网络baseline在损失函数计算时使用一般的CIoU计算方式, 分割分支和目标检测分支共用一个特征金字塔结构, 目标检测使用mAP评价, 可行驶区域分割使用mIoU评价, 车道线检测使用准确率进行评价. 从表7中结果我们可以看到, α-IoU提升了目标检测准确率, 而独立FPN结构则有效提升了分割分支的检测效果.
4 结论与展望
本文基于YOLOv5设计了一个多任务自动驾驶环境感知算法, 可以同时处理目标检测, 可行驶区域分割,车道线检测3个任务, 并且在1080Ti显卡上达到了76.3 fps, 在BDD100K数据集上与其他多任务网络相比取得了最佳的效果. 下一步的研究工作将在本文的基础上结合车道线检测的特点, 增加一些后处理操作,进一步提高车道线检测的准确率, 构建一个工业级的多任务自动驾驶环境感知算法.
猜你喜欢
卫星应用(2021年11期)2022-01-19 05:13:02
波谱学杂志(2021年3期)2021-09-07 10:10:06
科学大众(2021年9期)2021-07-16 07:02:50
中国交通信息化(2020年11期)2021-01-14 03:30:34
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
产业与科技论坛(2019年13期)2019-03-20 13:46:15
经济研究导刊(2016年32期)2017-04-06 17:10:42
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
天津大学学报(自然科学与工程技术版)(2015年10期)2015-12-29 12:53:22
