
基于弱学习回归树的电网基建投资模型研究
2022-09-19 01:27张乃夫郭忠涛
机械设计与制造工程 2022年8期
张乃夫,郭忠涛
(国网冀北电力有限公司唐山供电公司,河北 唐山 063000)
电网基建投资属于国家公共资源建设性投资,其不但需要考虑经济效益,还需要考虑社会效益[1]。对具体的社会效益进行评价,通过量化形式予以体现难度较大,为此可通过构建一定的电网基建投资模型进行分析[2]。在分析中,基于用电负荷数据分布情况矢量回归分析的投资模型、基于节点重要性评价的联动分析投资模型、基于弱机器学习的弱学习(AdaBoost)回归树投资模型等均有应用。其中,矢量回归分析侧重实现电网的功能,联动分析侧重满足用户侧的需求,回归树分析侧重数据本身的统计学表达。
弱学习回归树虽然其机器学习部分在整体算法中的占比并不大,但通过机器学习的反复迭代,可获得更精确的输出反馈值[3-4]。在实际电网基建投资效益预估过程中,基于弱学习回归树的原理,可以进行统计学层面的投资问题的分析研究,并通过与常用模型的比较,验证所提出的投资模型的实用性,是本文研究的核心创新点。
1 弱学习回归树的基本原理
与传统机器学习过程不同,弱学习回归树算法中机器学习的神经网络部分承担的计算任务较少,主要是计算数据列前一周期的数值,并根据效果评价阵列对该数据值的实际表现进行评价,若数值的偏差率过大,会在次轮迭代中进行修正,降低其偏差率,直至效果评价模块认为该数据满足回归目标[5]。弱学习回归树迭代阵列示意图如图1所示。
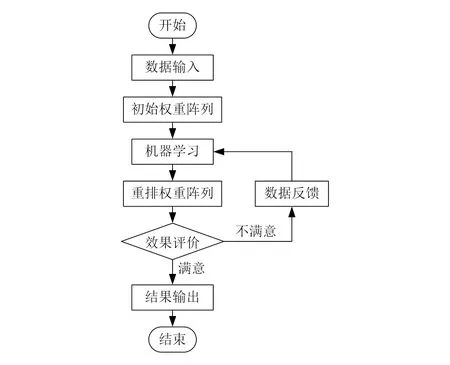
图1 弱学习回归树迭代阵列示意图
图1中,如果机器学习部分不采用神经网络结构,而是使用基于刚性数学函数传导的方式进行计算,则电网运行数据相关的二次矢量矩阵函数表达式为:
(1)
式中:ui,j为电网运行数据相关的二次矢量矩阵,该矩阵的作用是补全任意缺失项;xi,j为二次矢量矩阵中第i行第j列的矢量值;a为聚类中心,其计算结果与采取的聚类模式有关;r为计算阶数;c为矩阵维度;m为检测变量。
公式(1)应满足以下两个条件:其一是ui,j≥0,即所有矢量值的范数均为正值;其二是∑ui,j=1,即代入该函数的所有值需要在二次矩阵范畴内进行统一的离差标准化(min max)治理,并根据治理结果进行基于空间分布的加权重构。重构方式如式(2):
(2)

公式(1)中a为聚类中心,其计算可应用聚类中心管控函数,以实现对回归值的补充,具体计算方式如式(3):
(3)
在逐次迭代中,补全的输出数据数值逐渐贴近最终收敛值,其收敛结果的倾向性与效果评价模块的算法有关[6]。本文拟采用的效果评价方法为标准偏差率(6σ)方法,即当最终的数据补全结果满足6σ≤0.001 0时,认定该分析结果有效。其评价函数如式(4):
(4)

(5)
2 神经网络在弱学习回归树中的应用
在基于神经网络的机器学习技术得到充分推广应用的今天,使用神经网络实现对其机器学习部分升级成为重要的技术路径[7-8]。基于神经网络的回归值确认架构如图2所示。

图2 基于神经网络的回归值确认架构
此处,输入矩阵同样需要使用公式(2),计算中同样需要满足以下两个条件:一是ui,j≥0,即所有矢量值的范数均为正值;二是∑ui,j=1,即代入该函数的所有值需要在二次矩阵范畴内进行统一的离差标准化治理,并根据治理结果进行基于空间分布的加权重构。
在归一化计算中,采用基于Z-Score累加值的归一化算法,如式(6):
(6)
式中:q为归一数列长度,在行归一算法中,q=m,在列归一算法中,q=n;σ为对应行、列数据的一维标准偏差率;xi是第i行输出的数据。一维算术平均值的计算与一维标准偏差率对应的二维计算基本一致,仅在维数控制上有所简化,受限于篇幅,本文在此不做分解论述。
行输入模块与列输入模块的统计学意义是将输入的(c+d)个数据进行降维处理,形成2个Double格式的输出数据,在构建节点函数的时候同样采用多项式函数进行设计[9]。3个模块的神经网络设计参数见表1。

表1 神经网络模块设计参数汇总表
表1中,行输入模块和列输入模块的隐藏层结构为降维压缩型神经网络结构,采用逐层降维压缩的思路将c、d个输入节点的数据逐步压缩到2个Double型变量中。而中央模块的神经网络结构属于数据整理型结构,在2个输入数据的基础上形成1个输出数据。3个模块均采用多项式回归函数进行节点函数设计,其节点函数基函数为:
(7)
式中:Y为节点的输出量;Xi为节点的第i个输入量;p为多项式阶数;Ap为第p阶多项式的待回归系数。
公式(2)的反算算法详见公式(8):
X0={[x′-min(qi,j)][max(Xi,j)-min(Xi,j)]}/[max(qi,j)-min(qi,j)]+min(Xi,j)
(8)
式中:Xi,j为原始数据集合;qi,j为重投影数据集合;x′为经机器学习后的输出值,为解模糊前的计算结果;X0为机器学习输出值与原始数据集合对应的输出值。
3 数据仿真与算法效能评价
3.1 数据迭代过程与收敛效能评价
在某变电站近3年实际运行数据中选择300个实际发生序列组,对其进行数据前置训练,比较其实际运算过程中数据迭代过程和效果评价结果。选择其中300组真实数据进行测试,剔除前端数据后进行比较分析,比较两种弱学习回归树算法——聚类重构算法和神经网络算法之间的差异,具体结果见表2。
表2中,传统的基于聚类重构算法的弱学习回归树平均需要进行39.2次迭代后才可以通过效果评价模块实现数据输出,而基于神经网络算法的弱学习回归树平均仅需要进行6.9次迭代即可得到数据输出结果,前者是后者的5.68倍,表明神经网络算法的效能更高。

表2 两种弱学习回归树算法效能评价
3.2 曲线估计需求下的计算效能
在本文算法中,输出数据的6σ评价结果均达到0.001 0以下再输出运算结果。基于R2评价算法,比较聚类重构算法和神经网络算法的曲线估计结果,以评价这两种算法的实际计算能力。所有测试数据均采集不同前推周期的真实数据,测试300组数据,得到表3。

表3 两种弱学习回归树算法曲线估计能力评价
表3中的数据显示,聚类重构算法在30周期的原始数据驱动下,前推10个周期后可以保持0.900以上R2值的数据回归效果;神经网络算法在30周期的原始数据驱动下,前推60个周期时,仍能保持0.900以上的R2值数据回归效果。对弱学习回归树算法与传统回归算法在回归效果方面的差异进行比较,具体结果如图3所示。

图3 弱学习回归树算法的实际回归能力图
图3中,在30个周期的驱动数据支持下,传统回归算法在第3个前推周期后其精度就显著下降,而两种弱学习回归树算法中,聚类重构算法在第10个周期后才显著下降,神经网络算法在第60个周期后才显著下降。
3.3 弱学习回归树对投资模型的支持效果
比较不同算法下的投资模型支持效能,可以从最终投资评价结果与项目实测结果之间的差异,比较不同投资模型效能的差异[10]。详见表4。

表4 不同算法下的投资模型评价误差比较 %
结合表4中的数据进行分析可以发现,神经网络算法驱动下的弱学习回归树投资评价结果误差率优于聚类重构算法。
4 结束语
弱学习回归树应用于电网基建投资模型中可以对所有相关数据进行充分且长周期的高精度回归分析,并实现基于指标曲线估计的评价。本文比较分析了聚类重构算法和神经网络算法驱动下的弱学习回归树算法,结果显示,在迭代次数、曲线估计前推周期数、分析精度等方面神经网络算法均优于聚类重构算法。因此,基于神经网络算法支持下的弱学习回归树算法对电网基建投资分析模型有积极意义。
猜你喜欢
现代电力(2022年2期)2022-05-23
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
中国生殖健康(2020年7期)2020-12-10
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
商周刊(2017年6期)2017-08-22
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
