
1978 年以来中国总体收入基尼系数的再估计
2022-09-16 01:30吴耀国沈晓静刘军荣
乐山师范学院学报 2022年8期
吴耀国,沈晓静,刘军荣
(1.乐山师范学院 跨喜马拉雅研究中心,四川 乐山 614000;2.四川大学 数学学院,四川 成都 610065)
0 引言
居民收入不平等,是经济学研究中的热点话题。最早采用统计方法研究不平等可以追溯到Pareto 于1895 年发表的开创性论文,其所构建的累积分布函数即帕累托(Pareto)分布不仅能很好地刻画财富分配情况,还能较好地刻画真实世界中广泛出现的幂律特征。Lorenz 于1905 年提出了洛伦兹(Lorenz)曲线,对从低到高排序后的收入数据,该曲线描绘累计人口比例与对应累计收入比例之间的关系。在一定意义上,帕累托分布和洛伦兹曲线都是对这两个比例之间关系的刻画[1],两者的本质区别在于,帕累托分布对收入分布通过给定的分布函数簇加以规范刻画,而洛伦兹曲线则可以看成是对收入分布的描述性刻画。
从信息论的角度来看,洛伦兹曲线是更为理想的描述收入不平等的工具,但人们更习惯使用指标而非曲线或函数对收入不平等程度进行刻画。学者们提出的多种指标中,最为知名的是意大利统计学家C.Gini 于1912年提出的基尼(Gini)系数,该系数基于洛伦兹曲线而设计。不同学者曾对基尼系数有诸多批评,并提出多种替代方案。在基尼系数提出之前,帕累托曾建议用帕累托分布中的参数α 来度量收入不平等[1]。Theil[2]利用信息理论熵提出计算收入不平等的泰尔指数,在此基础上进一步发展出了广义熵指数;Atkinson[3]在探讨基尼系数缺陷的基础上,依据社会福利函数构建Atkinson 指标;而Bhattacharyya[4]则批评基尼系数不能区分停滞不前的社会和不断向上和向下流动的社会,并提出R 指数作为刻画指标。虽然提出基尼系数的初衷是构建一种不受变量单位影响的度量随机变量分散程度的指标[5],并且不同研究者提出了各种刻画指标,但总体来说,基尼系数是刻画居民收入不平等应用最为广泛、接受度最高的指标。
对我国居民收入基尼系数的测算,不同学者结合收入数据调查情况进行了大量的计算方法与具体测算研究。陈希孺[5]对基尼系数及其估计进行了非常精炼的介绍;李实[6]与陈宗胜[7]曾就基尼系数的估算与分解进行了精彩的探讨。
国家统计局发布了自2003 年以来历年中国总体收入基尼系数,由于缺乏之前年份的城乡混合分组收入调查数据,2002 年及以前年份的基尼系数缺失。同时,国家统计局还公布了城、乡各自的分组收入调查数据,大部分学者在一定假设条件下基于该数据对我国总体收入基尼系数进行测算。除此之外,世界银行等机构和部分学者基于其他收入调查数据,或采用国家统计局数据同其他数据的混合数据,测算中国总体收入基尼系数。如,2012 年底,西南财经大学中国家庭金融调查与研究中心基于其住户调查数据测算了2010年基尼系数。罗楚亮[8]根据历年中国富豪榜数据,指出基于住户调查数据所测算的收入基尼系数存在一定程度的低估。由于不同机构和学者对中国总体收入基尼系数研究的测算数据基础、测算方法、涵盖年份不同,导致所给出的测算结果也存在差异。
显然,国家统计局公布的总体收入基尼系数作为官方数据具有权威性,更具有连续性保证。从可比性、连续性角度考虑,有必要对1978—2002 年度国家统计局基尼系数进行估计。此外,经济学研究中仍有其他类似的缺失数据的补充需要,如基于世界银行基尼系数进行国家间的比较研究,但数据是残缺不全的。本文在梳理已有测算研究的基础上,将已有不同版本的测算结果视为对理论基尼系数的观测样本,在合理假设下推论得到补充不同版本基尼系数的计算方法,并以国家统计局基尼系数为例,对1978—2020 年数据进行了填充估计。本文的边际贡献为:一是提供了统一可比、科学合理的中国总体收入基尼系数时间序列估计结果;二是为经济学研究中类似的数据缺失问题提供了解决方法的借鉴。
1 中国总体收入基尼系数测算综述
1.1 国家统计局发布的中国总体收入基尼系数
2013 年1 月18 日,在国务院新闻办公室举办的2012 年国民经济运行情况新闻发布会上,时任国家统计局局长在回答记者提问时,一次性公布了2003—2012 年共10 年的中国居民收入基尼系数,这是官方首次公布全国居民总体收入基尼系数。此后历年数据均在《中国统计年鉴》中公布。
1.2 基于国家统计局城乡分组调查数据的测算
由于城乡差异的显著存在,总体基尼系数的城乡分解是重要的研究问题。理论上,总体基尼系数可以分解为[9-10]:

如前所述,国家统计局公布了城镇、农村分开的收入分组数据,采用该数据的学者们则对基尼系数的城乡分解反其道而用之:分开测算(1)式中的各项指标再综合;而不同测算方法的主要差异在于对收入分布和(1)式中各项指标关系的假设。本文以不同文献发表时间为序,介绍不同学者的研究结果。
陈宗胜和周云波[11]对早期我国居民总体收入基尼系数的测算有较为系统的梳理,其中大部分研究仅对零星年份的基尼系数进行了测算;出于时序长度的考虑,本文仅给出其中向书坚[12]采用分组加权法的测算结果,见表2。
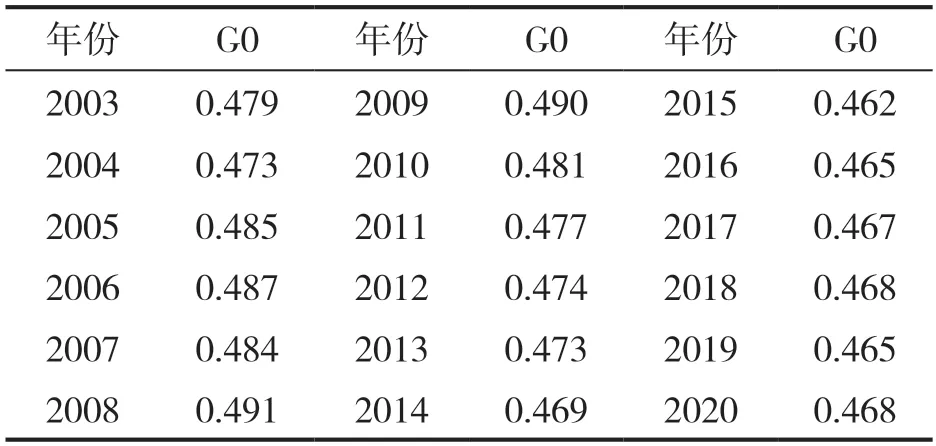
表1 国家统计局公布的中国总体收入基尼系数

表2 向书坚的中国总体收入基尼系数测算结果
董静和李子奈[13]假设城镇居民和农村居民的收入是服从正态分布的独立随机变量,运用修正城乡加权法推算1988—1999年全国基尼系数。结果见表3。

表3 董静和李子奈的中国总体收入基尼系数测算结果
学者程永宏[14-15]较为系统地讨论了基于城乡分离的收入调查数据测算城乡混合基尼系数的具体方法,并采用经过改造的Logistic 函数作为收入分布拟合函数,据此得到的全国总体基尼系数见表4。

表4 程永宏系列论文的中国总体收入基尼系数测算结果

续表4
徐映梅和张学新[16]考虑资料的可获得性和便利性,采用非等分法分别计算城镇和农村居民收入基尼系数(其中部分数据采自其他文献),并假设城乡收入分布不重叠,因而选择城乡加权法计算总体基尼系数。测算结果见表5。

表5 徐映梅和张学新的中国总体收入基尼系数测算结果
学者胡志军及其合作者[17-19]通过比较Weibull分布、广义BetaII 分布、对数正态分布对我国农村、城镇的收入分组数据的拟合效果,选择广义BetaII 分布作为收入的分布函数进行拟合,并基于此测算中国总体收入基尼系数。测算结果见表6。

表6 胡志军系列论文的中国总体收入基尼系数测算结果
胡志军等[17]给出1985 年、1990 年、1995 年、2000—2008 年基尼系数计算结果,但未经价格调整,本文将其记为G5;胡志军[18]给出了1985 年、1990 年、1995 年、2000—2009 年未经价格调整的、经过价格调整的两类测算结果,本文将其分别记为G6、G7,但2009 年度的两个结果较2008 年分别增加了5.58 和6.02 个百分点,增幅偏大,趋势与国家统计局、其他学者的结果相去较远,因此本文仅采用截至2008 年度的数据,此外,G5、G6 虽均为未经价格调整,但结果有细微差异,本文予以区别对待;胡志军和谭中[19]则给出了2005 年、2009—2012 年经过价格调整的测算结果,本文将这一结果接续于G7,其中2005 年数据取两个测算结果(分别为0.4570、0.4563)的均值。
Chen etc.[20]基于(1)式测算总体基尼系数,其中城乡组内基尼系数直接采用国家统计局城市社会经济调查总队和农村社会经济调查司的结果,在测算分解剩余项时,采用Dagum 分布作为收入的拟合分布。其测算结果见表7。
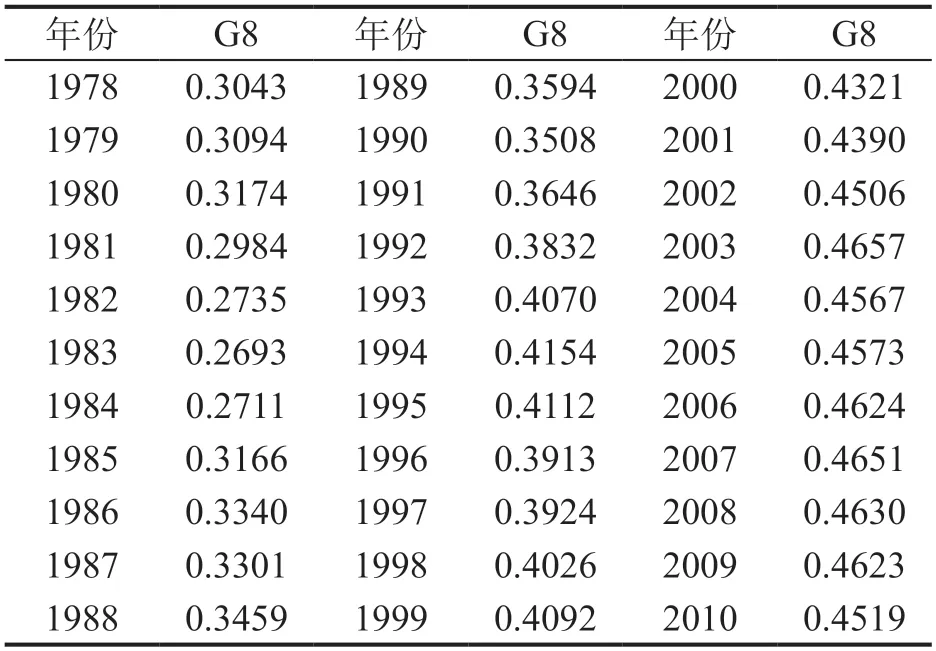
表7 Chen etc.的中国总体收入基尼系数测算结果
1.3 其他对中国总体收入基尼系数的测算结果
世界银行在其官方网站公布了不同国家的基尼系数,但未见其数据来源及测算方法说明;其中中国的基尼系数1990—2010 年为间断年份数据,且截至本文投稿时,2017 年以来数据缺失,其结果见表8。此外,赵人伟等[21]给出了世界银行测算的我国1979 年、1981 年、1992 年、1995年总体收入基尼系数,由于当前世界银行官网未给出该数据,本文不予摘录。

表8 世界银行的中国总体收入基尼系数测算结果
Ravallion and Chen[22]在探讨中国减贫工作的进展时,给出了对中国总体收入基尼系数的估计,但该文并未给出该基尼系数的计算方法或出处,其结果见表9;其中G11 为考虑城乡生活费差异而进行调整的结果。

表9 Ravallion and Chen 给出的中国总体收入基尼系数
此外,陈宗胜和张杰[23]综合整理了大量的统计资料,系统估算了新中国前30 年(1949—1978)的居民总体收入基尼系数,弥足珍贵,但该文所测算的年份不在本文探讨之列,故不予以赘述。
1.4 对中国总体收入基尼系数测算研究的简评
由于不同研究测算基尼系数所使用基础数据不同等原因,各版本基尼系数所涵盖的年份存在较大差异;不同测算的数据结果之间也存在显著差异。

表10 不同版本基尼系数所涵盖年份简表

续表10
对同一年份,不同测算结果之间存在显著差异。究其原因,本文分析有以下几个方面。其一,测算基尼系数的假设不同。如徐映梅和张学新[16]在具体测算基尼系数时,实际上假设了城镇居民和农村居民的收入不重叠,这与其余大部分研究者的假设相左。其二,对城乡居民收入所服从的分布,大部分研究所采用的并不一致。这些对收入的拟合分布包括正态分布、改造后的Logistic函数、广义BetaII 分布、Dagum 分布等多种形式,虽然部分研究者在选择拟合分布时从统计学层面的拟合效果角度进行了比较,但这种选择缺乏微观理论支撑,且存在过度拟合的倾向。其三,部分研究者基于城乡差别进行了调整。如胡志军[18]考虑城乡价格差异、Ravallion and Chen[22]考虑城乡生活费差异,分别给出了未经调整和经过调整的两个结果。
不可否认,不同的测算结果均有相应的价值和一定假设条件下的合理性。若研究者需要连续时间序列基尼系数,由于不同结果之间的系统性偏误可能不同,仅对已有不同年份测算结果简单拼接、对相同年份测算结果简单平均[11],本文认为略显简单,并不可取。其中,国家统计局公布的基尼系数作为官方数据具有权威性,更具有连续性保证。因此,从实际应用看,考虑可比性、连续性问题,有必要对1978—2002 年度国家统计局基尼系数进行估计,从而为其他相关研究提供统一可比的中国总体收入基尼系数时间序列。
2 中国总体收入基尼系数的再估计
2.1 基本假设与估计方法
假设国家统计局、世界银行及不同学者共12 个测算结果是对理论基尼系数(实际未知)的有偏观测:


据此,我们可以基于(5)式的回归系数估计结果,采用(6)式计算得到国家统计局总体居民收入基尼系数的无偏估计值。
2.2 估计结果
基于表1-表9 所给出的共12 个不同的基尼系数测算结果序列数据,采用OLS 对(5)式进行回归,系数估计结果见表11,所有系数估计数据保留小数点后4 位以上。

表11 回归方程系数估计结果
由表11 给出的参数估计结果,并应用(6)式容易得到1978—2020 年国家统计局总体居民收入基尼系数的估计值,结果见表12。

表12 基于文献结果的1978—2020 年总体收入基尼系数再估计

续表12
3 研究结论
3.1 再估计结果与文献结果的初步比较
图1 给出了关于中国总体收入基尼系数的3列估计结果的比较图,其中“再估计”指本文基于已有研究报告的测算结果对中国总体收入基尼系数的再估计,即表12 的结果,另外两个曲线图分别为国家统计局基尼系数、不含国家统计局结果的其他测算结果的简单平均,即表2-9 共11 列结果的简单平均。容易看出,相对于国家统计局结果,世界银行和其他学者测算的结果相对偏低,受制于不同年份“观测”数量的多寡,均值变化较大,与国家统计局基尼系数走势存在不一致的情形;而“再估计”结果与国家统计局结果重合度较高,走势基本一致。

图1 中国总体收入基尼系数的结果比较
3.2 对再估计结果的说明与建议
表12 所展现的估计结果是站在国家统计局基尼系数的角度进行估计的,图1 中,“再估计”及国家统计局结果与“均值”结果之间的差异,是由于国家统计局基尼系数在总体上,相较于其他基尼系数偏高的缘故。
由于2003—2020 年中国总体收入基尼系数国家统计局已经公布,建议研究者在使用1978年以来中国总体收入基尼系数时,1978—2002 年采用表12 报告的结果,2003 年以后年份采用国家统计局(即表1)的结果。当然,若所进行的研究需要进行国家间比较,则建议采用站在世界银行的角度对缺失数据进行“再估计”结果的补充。
3.3 对估计方法的进一步说明
实际上,使用本文所提供的方法,亦可以站在其他任何一个基尼系数估计序列的角度对缺失数据进行“再估计”。当然,应用上述的推导,我们无法估计任何一年的理论基尼系数,但我们关注的重点是基尼系数随时间的变化,在几乎所有与时间有关的因果关系研究(检验)中,数据的变化而非绝对值才是数据价值的关键。
类似的数据问题,都可以采用本方法进行缺失数据填充,如,基于世界银行基尼系数进行国家间的比较研究,则需要站在世界银行基尼系数角度对不同国家的缺失基尼系数进行填充估计。再如,基于观众打分的电影排名问题,也涉及到稀疏矩阵的填充处理。此外,使用该方法的前提是,不同版本的数据都是对理论数据的有偏观测,且该偏差与时间(个体)无关;当然,若随时间变化(个体不同),其偏差呈现规律性变化,可以对模型进行适当推广。
总之,为了弥补国家统计局仅公布2003 年以来总体收入基尼系数的遗憾,本文在对中国总体收入基尼系数相关测算研究进行综述的基础上,基于合理假设和科学的估计方法,再估计了1978—2002 年中国总体收入基尼系数时间序列,为后续相关研究提供了统一可比、科学合理的基尼系数结果,同时,也为不同国家基尼系数的再估计以及类似经济数据缺失问题提供了填充估计的思路方法。
猜你喜欢
小猕猴智力画刊(2021年11期)2021-11-28
机电信息(2020年13期)2020-06-30
中国证券期货(2017年3期)2017-03-30
中国证券期货(2017年3期)2017-03-30
统计与决策(2017年2期)2017-03-20
儿童故事画报·自然探秘(2016年4期)2016-06-24
科学启蒙(2016年5期)2016-05-10
管理现代化(2016年6期)2016-01-23
上海预防医学(2014年2期)2014-06-03
中共合肥市委党校学报(2013年2期)2013-08-15
