
基于视觉注意力和FCA的古建筑图像语义完备
2022-09-16 06:50牛少刚张素兰张继福
计算机技术与发展 2022年9期
牛少刚,张素兰,张继福
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
中国古建筑作为中国的艺术文化瑰宝,蕴含着强烈的人文气息和文化气息[1-3]。随着互联网古建筑图像资源的快速增长,用户可以通过网络便捷地查找古建筑信息。但在检索古建筑图像时,由于古建筑图像缺乏相应语义标签或存在错误标签,检索到的图像往往难以满足用户需求。因此,对古建筑图像进行准确完备的标注,不仅能提高古建筑图像的检索效率,而且可提高人们对古建筑鉴赏的文化修养。
图像特征的有效提取是提高完备标注精度的关键,而传统的基于颜色、形状、纹理等图像特征提取[4-5]方法无法提取图像的一些深层特征,且不能有效地对古建筑轮廓边界等重要特征进行语义分析。近年来,深度学习中基于卷积神经网络(Convolutional Neural Networks,CNN)提取图像特征的方法,因容易建立图像显著特征与语义之间的映射关系,得到了研究者的关注[6-8]。但由于古建筑图像结构复杂、特征分布不均匀,影响古建筑图像CNN模型分类效果,而视觉注意力机制是深度学习中的一种资源分配方式,可将学习到的权重分配到提取的特征上面,权重的大小表示了特征的显著性程度。该方法因能在提取重要特征时,抑制一些非重要的信息,在各种视觉识别任务中得到很好的应用[9-15]。其中,林泓等人[13]在无监督图像翻译中融合注意力机制,加强图像生成过程中像素间远近距离的关联关系,解决了图像无关区域导致图像翻译细节模糊以及真实性低等问题。Leng等人[14]根据视觉注意力的思想,提出了上下文感知的注意力网络用于图像识别,通过注意力模块进行注意转移,定位注意区域来完成精确的图像识别。汤文兵等人[15]通过视觉注意力机制实现用户多重交互,再结合卷积网络获取更高级别的特征交互,有效提升了物品识别效率。因此,为有效提取古建筑图像轮廓边界等重要特征,该文通过CNN结合视觉注意力机制,建立古建筑图像轮廓特征与语义信息之间的映射关系并获取古建筑图像初始语义。
古建筑图像的完备标注,主要通过计算图像视觉特征与语义标签,以及语义标签之间的关联度,来选择适合的标签作为标注结果,而完备标注效果的好坏关键在于古建筑图像视觉内容与语义标签,语义标签之间关联关系的有效建立。概念格又称形式概念分析(Formal Concept Analysis,FCA)[16],是一种数据分析和知识提取的有力工具,因其能有效地描述对象与属性之间的关系,反映概念之间泛化与特化的关系,已在知识表示、数据挖掘、图像标注等众多领域得到了广泛的应用[17-20]。其中,Hao等人[17]构造了能够动态处理上下文的三支概念格,提升了构造效率并缩短了构造时间,能够更有效地进行知识规则提取。Zou等人[19]提出一种模糊分层概念格的规则提取方法,通过设置不同的置信度构造概念算子来获取规则之间的关联性。顾广华等人[20]通过构造基于图像簇的概念格,去除噪声图像块并获取目标语义簇,大大提升了图像标注的准确率。由于古建筑结构复杂、形式多变,其结构语义之间又存在一定联系,为进一步完备古建筑图像语义,该文利用FCA具有上下文语义分析的特点,建立了一种基于FCA的古建筑图像标签完备方法。该方法利用概念格分析古建筑构件之间隐含的关联关系,通过概念相关度计算,有效提取出古建筑图像的潜在语义,完备了古建筑图像语义。
1 文中方法
在利用CNN提取图像特征时,卷积层深度的增加使CNN所提取的深层特征更具有语义判别性。但在用CNN对古建筑图像进行特征提取时,图像特征与语义标签之间的映射较为单一,无法得到全面的图像语义信息,而概念格有层次化分析语义的特点,可以有效对古建筑图像进行语义补充。为尽可能地描述古建筑的屋顶风格、屋顶类型等深层语义,该文利用视觉注意力机制和卷积神经网络结合的方法得到初始的代表性标签,然后通过概念格节点相关度计算,获取更深层的古建筑语义标签(例如屋顶风格重檐、建筑结构木结构等),进而丰富古建筑图像的语义信息,该方法框架如图1所示。
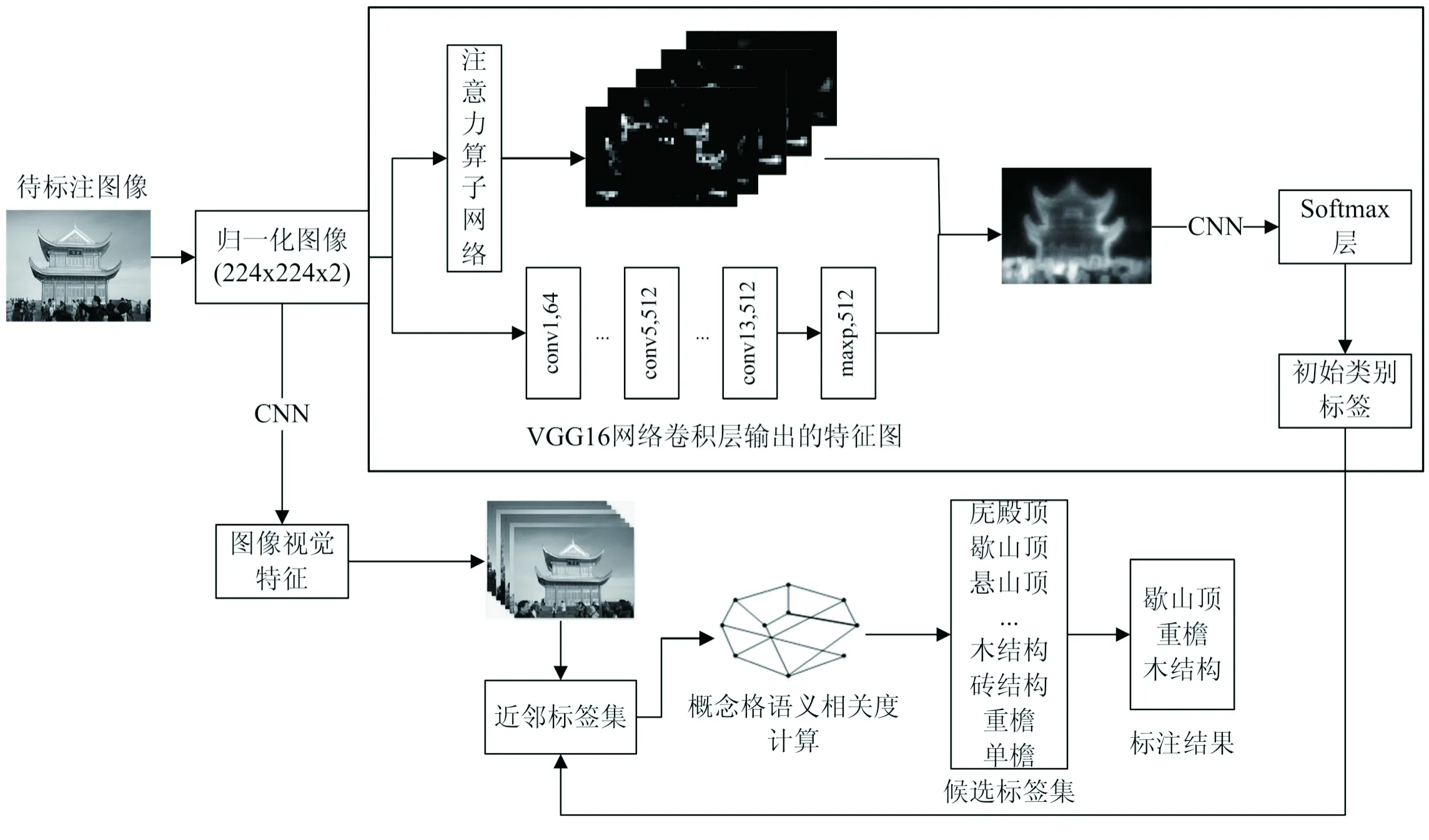
图1 基于注意力机制和概念格语义扩展的古建筑图像语义完备标注模型
1.1 基于CNN的古建筑注意力图的获取及初始类别标签生成
通过注意力算子网络和VGG16网络模型卷积层提取待标注古建筑图像的特征,得到尺寸和通道数不变的权重图和特征图,然后将权重图与特征图进行融合获取能够表述古建筑图像特征的注意力图,最后,通过CNN结构中的softmax层获取古建筑类别标签。其中注意力机制可以表示为:
fatt=N(I)
(1)
(2)
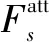
1.2 近邻图像的生成及近邻标签生成
为得到待标注图像I0的初始近邻集及其近邻标签,首先利用1.1节中已训练好的VGG16模型提取图像4 096维特征向量,计算待标注图像I0与训练图像的视觉相似性得分并选取相似性得分高的图像集作为近邻集。该文使用欧氏距离计算图像的视觉相似性,距离越小说明二者越相似。计算公式如下:
(3)
其中,dist(Ii,Ij)为图像Ii和Ij的视觉特征向量的欧氏距离,δ是一个标量,根据经验,将图像距离矩阵的中位数设置为其值。通过图像相似性得分的降序排序,获取了待标注图像的图像近邻集标签,并将其与1.1节中的初始类别标签进行融合作为最终的近邻标签。
1.3 基于概念格的语义扩展
1.3.1 形式背景的构造
概念格是一种有效的语义层次分析工具。为利用概念格进行图像标签语义相关性分析,该文将待标注图像与其近邻图像集作为对象集U,将待标注图像的初始标签和近邻标签合并形成新的标签集作为属性集M,并将近邻图像与标签映射关系进行归一化处理,即存在映射关系记为1,反之记为0,从而构造出基于待标注图像及近邻图像集标签相关的形式背景。
假设待标注图像为I0,其经过softmax分类器获得的典型的初始预测标签为t1,由1.2节中搜索近邻图像得到m幅(假设m=3)与I0最相似的近邻图像I1-I3,获取图像I0近邻图像的所有标签并入集合T中,则Im={I1,I2,I3},T={“WuDianDing”,“XieShanDing”,“XuanShanDing”,“YingShanDing”,“CuanJianDing”,“DoubleEaves”,“SingleEaves”,“WoodStructure”,“BrickStructure”}。参照文献[18],根据近邻图像与标签之间映射关系构造形式背景K=(U,M,R),如表1所示。

表1 形式背景K
根据形式背景K生成概念格结构Hasse图,如图2所示。

图2 形式背景K的Hasse图
1.3.2 基于概念格的古建筑语义扩展
古建筑图像往往包含多种语义信息,各语义信息之间又具有一定关联。为利用概念格进行图像标签语义相关性分析,该文采用粗糙概念格(Rough Concept Lattice,RCL)[22-23]相似性模型来度量两个概念节点之间的相似性。与其他相似性算法相比,RCL相似性算法结构性更加清晰,能有效地挖掘出标签之间的相似性,可以更方便地度量形式背景中上下文概念的相似性[23]。因此,利用RCL来处理古建筑语义之间的关联问题。概念格中任意两个节点a和b的相似性度量方法如下:
sim(a,b)=
(4)
其中,sim(a,b)的值介于0和1之间,1表示完全映射,0表示错误映射;a∨b表示a和b的交集;||表示集合的基数;aLA为下近似属性集,即包含概念a最大可定义集;aLA-bLA表示属性集属于aLA,不属于bLA;α为相似性度量阈值,其值设置为0.5,当相似性度量值大于等于0.5时,可以认为两个概念节点之间存在映射关系,当α小于阈值0.5时,则节点之间不存在关联。在图2中,对节点#5,#6进行相似性度量,节点#3是其连接节点且与#5,#6存在上下位关系。
5LA={{1,2},{1,3}} 6LA={{1,3},{1,4}}
3LA={{1,3}} 5LA-6LA={{1,2}}
6LA-5LA={{1,4}}
通过计算概念之间的相似性度量可以得到,节点5和6之间的相似性度量阈值为0.5,说明#5和#6可以相互映射。由式(3)计算得到待标注图像与近邻图像的相似度,将其作为近邻图像Im对待标注图像的支持度指标之一,根据概念格获得的概念之间的相似度,计算候选标签集中每个标签对待标注图像的支持度:

Im)γ(Im,ti)
(5)
其中,β为相似性权重系数,γ(Im,ti)为近邻图像Im与标签ti之间的所属关系,即若Im存在标签ti,γ(Im,ti)的值为1,反之为0。为减少不相关的语义标签,在计算得到的概念之间的支持度后,选择支持度高于0.1的标签词,作为待标注图像的最终标签词。
例如,待标注图像I0的初始标签为t1,结合1.2节中计算图像之间的相似度,可得I0与近邻图像之间的相似性得分,选取得分较高的前三张图像I1-I3,将其标签{t2,t3,t4,t6,t7,t8,t9}赋予待标注图像。然后通过式(5)得到各个标签对待标注古建筑图像I0的支持度,去掉了近邻标签中与待标注图像无关的标签{t2,t3,t4,t7}后,得到待标注图像的最终标签{t1,t6,t8,t9}。与传统的完备标注方法相比,基于概念格的语义扩展通过挖掘图像上下文潜在的语义关系,不仅扩展了图像标签,而且也去掉了近邻图像中出现次数多的冗余标签,使标注效果得到显著提升。
1.4 算法描述
文中方法的主要步骤如下:
输入:待标注的古建筑图像I0,待完备标签集L={L1,L2,…,Ln}。
输出:待标注图像完善后的标签集L'。
Step1:预处理。对古建筑数据进行归一化处理。
Setp2:图像特征提取。利用注意力机制和卷积神经网络获取古建筑数据集的抽象特征图。
Setp3:初始标签获取。将上一步得到的古建筑注意力特征图做softmax线性分类,得到古建筑图像的初始标签集L'。
Setp4:获取近邻图像及近邻标签。通过式(3)得到的待标注图像I0的近邻图像和近邻标签,并入并更新标签集L'。
Step5:概念格的构造以及标签完善。利用近邻图像和标签集抽象形式背景并构造概念格,利用概念格中节点之间的映射关系,由式(5)得到标签对图像的支持度sup(a,b),选取对待标注图像支持度高的标签进行标注并更新标签集L'。
Step6:标签输出。输出待标注图像的最终标签集L'。
语义完备算法流程主要包括图像归一化、提取图像特征、获取初始标签、获取近邻图像集近邻标签以及概念格构造和概念格语义相似度计算等。流程如图3所示。
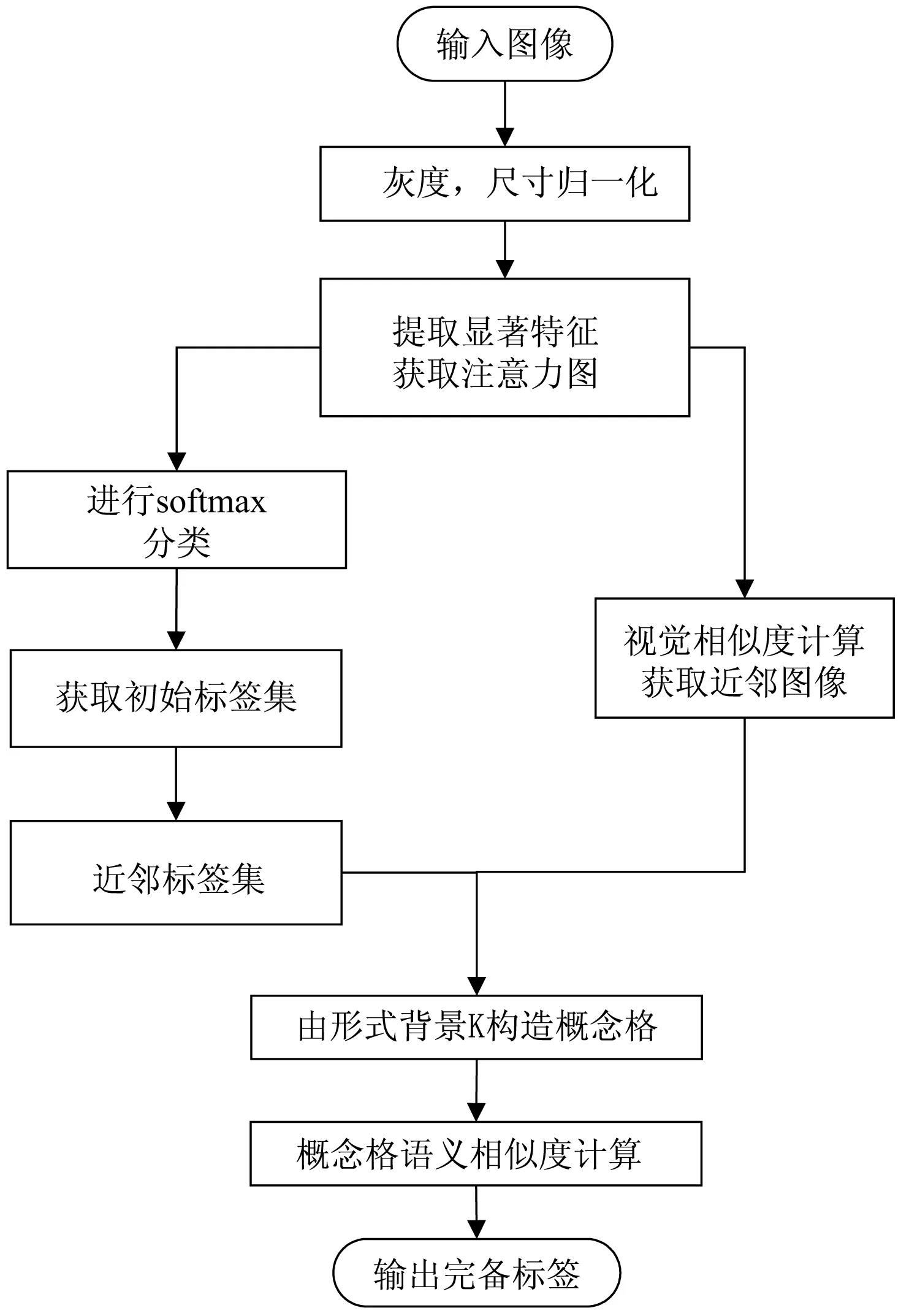
图3 语义完备算法流程框图
2 实验结果及分析
2.1 古建筑数据集及语义标签设计
通过网络收集了唐宋时期古建筑图像,构建了唐宋时期古建筑图像数据集。为验证文中方法的有效性,在唐宋时期古建筑数据集和中国科学院自动化研究所模式识别国家重点实验室提供的传统古建筑数据集(http://vision.ia.ac.cn/data)进行了实验。唐宋时期数据集和传统古建筑数据集的属性如表2所示。

表2 古建筑图像数据集属性
综合中国古建筑的特点,从建筑屋顶风格、建筑构件以及屋顶类型等方面设置语义标签。古建筑的屋顶主要有五种风格,分别为:庑殿顶(WuDianDing)、歇山顶(XieShanDing)、悬山顶(XuanShanDing)、硬山顶(YingShanDing)、攒尖顶(CuanJianDing);建筑构件主要有木结构(WoodStructure)和砖结构(BrickStructure);屋檐形式分为单檐(SingleEaves)和重檐(DoubleEaves)两种形式。
2.2 评价标准
采用的评价标准[20]有:准确率P、召回率R以及F值,分别定义为:
(6)
(7)
(8)
其中,M为待标注图像的总数目,wj为第j张待标注图像的生成的语义标签,Correct(wj)为生成语义标签wj中正确标签的数目,Prerdicted(wj)为生成语义标签wj的总标签数,Truth(wj)为第j张待标注图像真值标签的数目。
2.3 注意力图对标注效果的影响及训练模型损失对比
为了确定生成的注意力特征图对古建筑图像的特征表示能力,将经过注意力机制处理的古建筑数据集与原古建筑数据集进行了标注准确率实验对比。在训练网络时,将训练集图像大小进行归一化,输入尺寸为224×224,使用动量为0.9的异步随机梯度下降,网络初始的学习率设为0.01,每10步下降到当前学习率的十分之一,epoch为200,损失函数为交叉熵损失函数,为克服过拟合,对全连接层中前两层丢失率为50%的进行删除操作。采用二分类模型常用指标ROC-AUC曲线图来评价所训练的网络模型。ROC为受试者操作特征曲线,AUC指曲线下方的面积,其值大小范围在0.5~1之间,AUC值越大,说明训练模型性能越好。图4(a)和图4(b)分别给出了训练模型VGG16在使用了注意力机制和未使用注意力机制的唐宋古建筑数据集和传统古建筑数据集上的ROC-AUC曲线图。

(a)唐宋古建筑数据集 (b)传统古建筑数据集
由图4可以看到,VGG16在传统古建筑数据集上模型的训练精度不如唐宋古建筑数据集,这是因为在唐宋古建筑数据集构建过程中,人工过滤掉了一些噪声严重的数据。而传统古建筑数据集中存在与建筑无关的物体以及建筑物被遮挡等情况,影响了模型的训练精度。从图4中可以观察到,融合视觉注意力机制之后的古建筑数据在VGG16网络模型上有着更高的识别精度,且在训练模型的ROC曲线上的AUC值分别达到了85.12%和80.18%。说明该文的古建筑注意力特征图能够有效地增强古建筑的边界、轮廓等特征,进而表述了古建筑的局部特征以及整体特征。图5为VGG16网络模型在两类数据集上的损失收敛曲线,可以看到两类数据集的损失率都在epoch为160之后达到了最低。

图5 VGG16训练网络在两类数据集上的损失曲线
2.4 参数分析
本节在唐宋古建筑数据集和传统古建筑数据集上通过实验进行了参数分析。参数β是图像相似度权重系数,β值越小,图像视觉相似度对标注的结果影响越小。通过寻找其最佳值,获取图像标注的最佳结果,用F值作为评价该参数的指标。图6是对参数β进行分析的结果,从图中可以看出,随着β的变化,评估指标曲线波动程度较小,总体呈先升后降的趋势,并在β=0.2时达到最佳,说明概念格语义相关度对标注的结果影响较大,因此设置参数β的值为0.2。
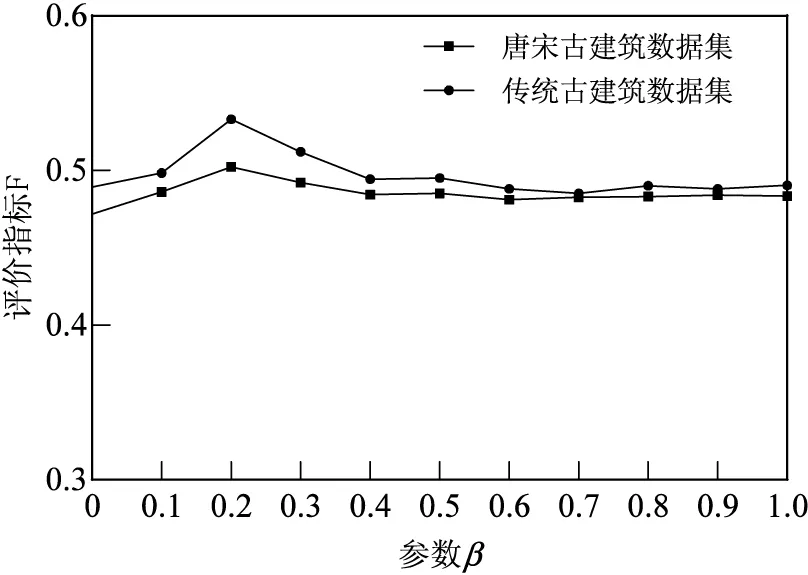
图6 评估指标F随参数β的变化
2.5 标签完备
本节验证概念格语义丰富的有效性,在文中两类数据集上分别随机选取一定数量的图像进行实验,N为概念格节点数,选取准确率P为评价指标,计算方法见公式(6),准确率P的大小与标注图像获取的标签数目以及正确标注图像的标签数目有关。实验中,通过计算每幅图像所产生语义标签的数目,将图像所生成的正确标签在候选标签集中进行标记,来获取每幅图像语义扩展之后的准确率,实验三次,取平均值,实验结果如表3所示。

表3 概念格语义扩展实验
由表3可以看出,在两类数据集上,图像初始标签数目基本为1,完善后的标签数目为3,这是因为古建筑语义标签设置为三大类(屋顶形式、屋檐以及建筑构件),文中方法通过概念格上下文语义相关度计算,有效地避免了类间语义的错误传播,比如屋顶形式庑殿顶和歇山顶两个标签之间并没有关联,概念格通过计算语义类间的关联,补充了与待标注图像初始标签关联度高的标签,对古建筑图像进行了有效标注。
2.6 实验对比
为了验证文中方法的有效性,在两类数据集上进行了标注实验对比,实验三次,对P、R、F三个指标取平均值,实验结果如表4所示。
在表4中,VAM表示文中所用到的视觉注意力机制。从表4中可以看出,文中方法在两类数据集上均取得了较高的准确率和召回率,特别是通过概念格完备语义标签之后,标签的召回率得到了较大提升。这是因为在特征提取阶段利用了视觉注意力机制加强了古建筑图像的边界、轮廓等重要特征,提高了图像的初始标注效果,然后计算了图像之间的相似度,根据相似度系数越高得到图像特异性越强的特点,得到具有高准确度的候选图像,提高了标注的准确率P。在语义学习阶段利用概念格挖掘出了标签之间的相关性,扩展了图像标签,提高了标注的召回率R,与当下多数研究者使用VGG16网络相比,文中方法的准确率和召回率都有所提升,在标签召回率上提升较大,证明了文中方法能够有效扩展图像标签,从而丰富了古建筑图像的语义信息。在文中方法中,加入概念格之后图像标注准确率比视觉注意力机制方法稍有降低,这是由于在概念格进行语义扩展时,候选标签集中标签的数量会不断增多,错误地标记了部分噪声标签,导致准确率降低。
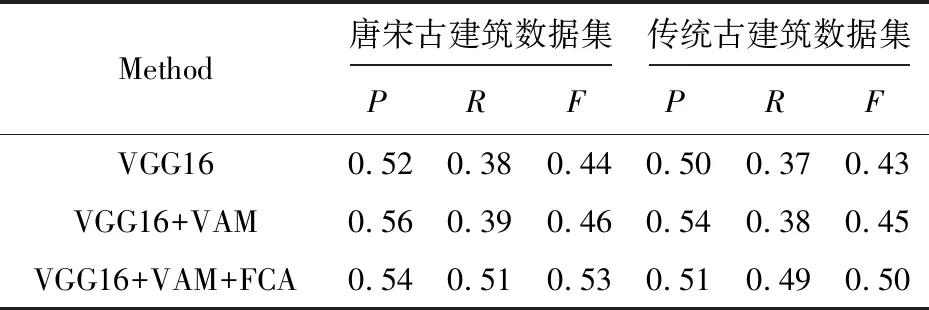
表4 文中方法对比
2.7 标注实例
表5给出了部分图像的标注实例,其中第一列是文中使用的数据集,第二列为待标注的图像,第三列为图像的初始标签,即图像的待完备标签词,第四列为利用文中方法得到的标注结果。

表5 标注实例
其中加粗字体为正确标注的标注词,非加粗字体为图像中不应该存在但被文中方法标注的标签词。在初始标签预测阶段,文中方法可以利用卷积神经网络和视觉注意力识别古建筑图像中的具体信息,并产生能够反映古建筑图像内容的标签,但仅使用深度模型进行古建筑图像标签完备,会带来许多噪声标签。由于古建筑图像本身含有多层语义,各语义之间又存在关联,而深度学习并不能很好地学习关联语义的特征,造成语义信息的缺失。比如在第二张图中,标注结果标注了图像的深层语义标签“砖结构”,该标签词无法从图像的视觉特征得到,但是经过概念格的提取标签的相关性,挖掘了古建筑图像更深层的语义内容。由此可以证明概念格可以有效地改善标注结果,丰富古建筑图像的语义信息。但在第三行第一张图的标注结果中,产生了错误的标签“单檐”,这是因为“单檐”和“歇山顶”相关性较高,而图像中的初始标签为“歇山顶”,所以导致了错误的标注。这也说明标签之间的相似性会影响最终的标注结果,若能进一步细化古建筑图像与标签的相关性,去除噪声标签,将会极大地提升古建筑图像标注性能。
3 结束语
提出一种基于视觉注意力和FCA的古建筑图像标注方法。该方法利用视觉注意力提取了古建筑图像的边界轮廓等重要特征,通过卷积神经网络得到了视觉特征和语义标签之间的映射关系,在此基础上利用概念格对语义标签进行扩展,通过在古建筑数据集上进行标注实验,证明了该方法可以有效地提升古建筑图像标注性能。下一步工作是进一步探索古建筑语义标签之间的关联性以及细化古建筑语义标签,以提高古建筑图像标注精度,丰富古建筑图像语义。
猜你喜欢
建材发展导向(2022年20期)2022-11-03
文物鉴定与鉴赏(2022年6期)2022-05-27
视野(2018年18期)2018-09-26
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
长江学术(2015年1期)2015-02-27
读者(乡土人文版)(2013年10期)2013-04-12
数理化学习·高一二版(2009年2期)2009-03-30
