
面向神威高性能多核处理器的并行编译优化方法
2022-09-15 06:59周雍浩徐金龙
计算机工程 2022年9期
周雍浩,徐金龙,李 斌,钱 宏,聂 凯
(1.郑州大学 信息工程学院,郑州 450001;2.数学工程与先进计算国家重点实验室,郑州 450001;3.江南计算技术研究所,江苏 无锡 214083)
0 概述
编译器的设计与开发是一项复杂而又艰巨的任务,其中的编译优化至关重要。随着多核处理器设计领域技术的快速发展,CPU 的基础运算能力不断提高,但要提升信息系统的应用效能,必要的途径是通过编译优化技术来生成与多核处理器芯片相配套的高效率目标代码。在多核处理器上通过启动多个线程来并行执行程序,是充分发挥多核处理器性能优势的主要方法。目前,申威高性能多核服务器上的处理器采用对称式共享存储结构,实现多线程的主要方法是OpenMP 编程技术[1]。因此,对OpenMP程序的编译优化是申威高性能多核服务器配套的自动并行化编译系统的核心任务。OpenMP 程序编译优化的主要目标是尽量高效地表达出程序中的并行性,包括翻译时刻优化、运行时优化以及线程级优化等[2-4]。目前,OpenMP 程序编译优化的焦点主要集中在线程级优化[5-6]。
在OpenMP 编程技术中,实现线程级并行主要有两种模型:标准的fork-join(派生-合并)模型和较为复杂的单程序多数据(Single Program Multi-Data,SPMD)模型[7]。fork-join 模型使用灵活,易于处理程序中的并行域,在程序生成相对简单且支持增量式开发,但在运行过程中需要多次创建和汇合并行线程,开销大且运行效率低。SPMD 模型采用多线程协作的执行方式,在程序运行过程中整个线程组仅需一次创建与一次汇合,线程的控制开销较小且运行效率高,但该模型需要考虑线程之间的数据分配和工作负载,实现比较复杂。目前,神威平台自动并行编译系统采用的是fork-join 模型,在程序运行过程中线程的创建和汇合比较频繁,在并行性的表达上处于一种低效率的状态。并行域重构技术结合标量分析、依赖关系分析及数据和计算划分信息等自动并行化技术,尽量合并fork-join 模型中多个单独的并行域到一个大的并行域中,作为一个小的SPMD 区 域,能够得到混合fork-join 模型和SPMD 模型的OpenMP 程序。在不增加程序员工作量的前提下,降低线程的控制开销,提高线程级代码的并行执行效率。
OpenMP 程序的编程标准严格遵守fork-join 模型,每一个并行域在开始执行前必须去共享内存中读取数据,无论是中小型的SMP 架构还是目前广为流行的CMP 架构,都无法避免数据划分和分布的问题[8-9]。因此,fork-join 模型的OpenMP程序不是一个很好的并行编程模型。目前,已有研究人员在不同的平台上研究利用改进的编程模型优化OpenMP程序。ONODERA 等[10]在GPU 平台上通过对多重网格预条件共轭梯度(Multigrid Preconditioned Conjugate Gradient,MPCG)等OpenMP 程序的优化研究中指出,OpenMP 程序可以通过合并一些并行域实现更粗粒度的并行,从而提高程序的整体性能[11]。文献[12-14]在Intel Xeon 处理器上针对jacobi 程序给出了一些具体的OpenMP 程序优化方法,他们通过变量私有化、删除冗余同步等操作合并OpenMP 程序的并行域来提高程序的运行效率。文献[15-17]从OpenMP 编译器优化角度阐述了采用SPMD 模型消除冗余同步,扩大程序并行域,提高可执行程序的性能。ZHU 等[18]在C64 多核模拟器上的测试结果表明,随着线程数目增加,编译指示#pragma omp parallel for 和#pragma omp parallel 的代价相当,但是都远高于#pragma omp for 的代价,两者相差大约100 倍,证实了并行域合并之后的OpenMP 程序并行代价远低于未进行合并与扩展的OpenMP 程序。扩大OpenMP 程序中的并行域是一种比较有效的优化方法,但是并没有给出一种通用的扩大OpenMP 程序并行域的方法。
本文针对申威高性能处理器上的线程级并行执行模型,提出一种面向神威高性能多核处理器的并行编译优化方法。该方法结合了fork-join 模型与SPMD 模型的优点,OpenMP 程序的串行部分被单线程执行,并行部分被合并到一个大的并行域中从而形成一个小的SPMD 区域。在每个SPMD 区域中,编译器可以通过数据依赖分析消除冗余同步,或使用代价较低的同步来提高程序的整体性能,以避免fork-join 模型并行效率低及SPMD 模型程序编写复杂等缺点。
1 OpenMP 程序执行模型及问题分析
fork-join 模型是OpenMP 编程技术的标准执行模型,也是目前神威平台线程级并行采用的执行模型。在起始时只有一个主线程执行程序语句,当遇到OpenMP 编译制导标识的并行域开始时,主线程派生(fork)出一组子线程共同完成并行域中的计算任务,当遇到OpenMP 编译制导标识的并行域结束时,所有子线程挂起或者退出执行,主线程则继续执行。与此不同的是,在单程序多数据(SPMD)模型中,所有线程执行整个程序,且一直处于活动状态,串行部分约束为单个线程执行或者多个线程重复执行。在执行程序中并行循环时,根据线程编号执行对应部分的循环迭代,循环迭代之间的依赖关系通过插入栅障同步语句来维持。图1 和图2 所示为两种OpenMP 模型的并行执行模型。
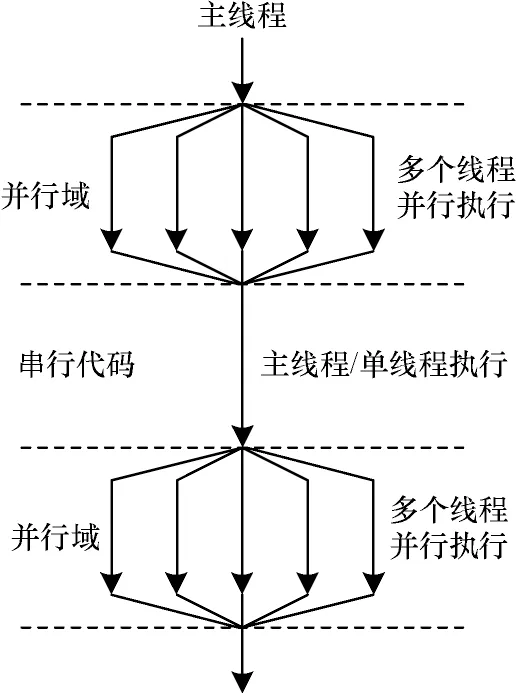
图1 fork-join 模型Fig.1 fork-join model

图2 SPMD 模型Fig.2 SPMD model
fork-join 编程模型的OpenMP 程序是对相应的循环进行并行化,实现简单且易于增量式开发,缺点是多个线程组的启动和同步代价很高,尤其在嵌套循环中容易出现嵌套并行的情况,在嵌套并行时线程组频繁地创建和注销,极大地增加了操作系统对线程组管理和控制的开销,严重影响程序的整体运行效率。程序中跨循环的优化无法实施,Cache 利用率低,并行性能受串行部分占比限制,因此,程序的整体运行效率不高。与此相比,SPMD 模型的OpenMP 程序将并行循环合并到一个大的并行域中,减少了多个线程组创建和汇合的开销,同时编译器可以通过分析消除冗余同步,进行更充分的数据划分,高效提升Cache 利用率。但是,SPMD 模型的OpenMP 程序并行域更大,程序中变量数据属性的分析变得非常复杂,在循环优化时数据的依赖分析和并行线程之间的同步优化具有较大的难度,因此,SPMD 模型的OpenMP 程序不容易实现。本文提出的并行域重构技术将OpenMP 程序中运行效率低的fork-join 执行模型转换成运行效率高的SPMD 执行模型来提高程序的整体性能。
图3 所示为并行域重构技术后OpenMP 程序的执行模型。
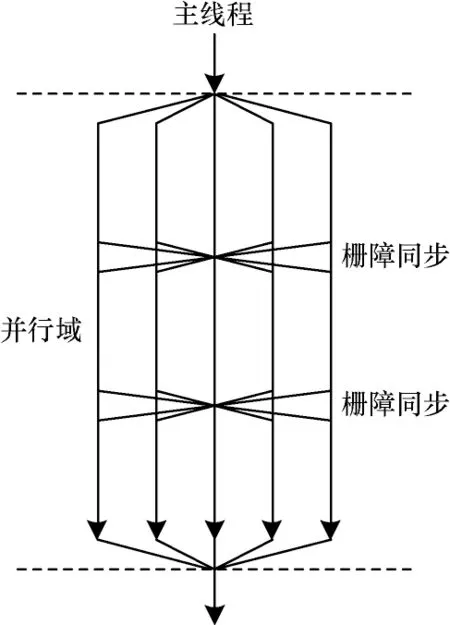
图3 并行域重构模型Fig.3 Parallel region reconstruction model
2 并行域重构技术
并行域重构技术包括并行域合并和并行域扩展,下面分别使用程序实例对这两种技术进行说明,并给出并行域重构技术的实现方法。
2.1 并行域合并
并行域的合并是指在两个相邻的单独并行域之间插入一个栅障同步(如果两个并行域存在数据依赖性),然后把这两个并行域直接合并为一个大的并行域,作为一个小的SPMD 区域。代码清单1 和代码清单2 展示了一个相邻并行域合并的代码示例。需要说明的是,在神威平台的自动并行化编译器中,parallel、for、sections 和single 构造的最后都有一个隐式的栅障同步。
代码清单1相邻并行域代码合并前的形式

代码清单2相邻并行域代码合并后的形式

为了确保并行域合并不修改原程序语义,这里需要保证各个子线程获取数据的更新顺序和执行顺序拥有相同的一致性。后者能通过OpenMP 中的栅障同步操作来实现,前者可以通过OpenMP 的制导指令flush 操作来保证可见数据的一致性。此外,相邻并行域的合并还需要解决2 个问题:合并过程中遇到的变量数据属性冲突和合并过程中程序串行语句的处理。
1)变量数据属性冲突处理。在多线程程序中,变量属性包括共享和私有两种。共享变量在并行域中只有一个副本,并行域中的所有线程均可对其进行读、写等修改操作,且这种修改对并行域中的所有线程都是可见的。与此不同的是,并行域中的所有线程都拥有私有变量的一个副本,线程内部私有变量的修改并不影响其他线程内部私有变量的值。实际的并行域合并操作经常遇到变量的数据属性冲突问题,因此,对变量数据属性的冲突是需要解决的重要问题之一。
代码清单3 展示了一个并行区域合并遇到的数据属性的冲突示例。并行域1 中声明k为共享变量,并行域2 中声明k为私有变量。并行域1 和并行域2无法进行合并,因为变量k在并行域合并时存在数据属性冲突问题。针对该问题,本文采用标准OpenMP 编译制导语句 private、firstprivate 和lastprivate 修改共享变量的数据属性,然后再次尝试合并。例如,在编译代码清单3 示例程序过程中通过对变量k的定值-引用链分析发现,共享变量k在并行域1 中引用,而定值却在并行域1 先前的程序段中。因此,在并行域1 对变量k进行私有化处理,则需要使k先前的定值在并行域1 内部可见,需要在引用前将这个定值引入到并行域1 中,这可以通过OpenMP 提供的firstprivate 子句实现,如代码清单4所示。
代码清单3变量数据属性冲突示例

代码清单4变量数据属性修改示例

修改变量k的数据属性后,进一步可实现并行域1和并行域2 的合并。代码清单5 展示了修改变量k的数据属性后并行域1 和并行域2 的合并。
代码清单5数据属性修改后的并行域合并


对变量进行私有化处理会屏蔽掉变量原来的定值,无论是并行域内部的定值-引用关系,还是并行域结构上下程序之间的定值-引用关系都有可能被修改,已经有学者对这一问题进行了深入的研究[19-21]。为满足共享变量私有化之前所有的定值-引用关系,本文设进行私有化处理的共享变量在并行域中没有定值。本文在这一前提下确定能否对一个并行域中的变量实行私有化处理,只有满足共享变量在并行域中没有被定值,才能确定并行域合并过程中不存在变量属性冲突,然后尝试私有化处理,进一步实现并行域合并。
2)串行语句处理。如果两个相邻的并行域之间存在若干条串行语句,那么并行域合并操作无法直接实施。此时,可以通过约束执行来使得串行语句包含在并行域中,再实施并行域的合并,这可以通过OpenMP 制导语句master 或者single 来实现。
代码清单6 和代码清单7 展示了一个合并过程中串行语句处理的程序示例。串行语句通过OpenMP 制导子句single 和master 约束执行,实现与并行域的合并,进一步合并更多的并行域。但是,这样的做法也增加了同步操作,带来新的额外开销,但优点是串行域的代码可以用来作为并行域中新的工作负载,还可以根据串行域代码的特点进一步转化为section 类型的并行任务,从而提供更多的负载均衡选择方案。
代码清单6并行域合并过程中串行语句处理前的形式

代码清单7并行域合并过程中串行语句处理后的形式


2.2 并行域扩张
并行域扩张主要有循环并行域扩张、控制流并行域扩张和跨越函数边界的并行域扩张3 种情况。
1)循环并行域扩张。如果一个循环中的所有语句都被包含在一个并行域中,则该并行域可以被扩张到该循环之外。这是一种较为高效的并行域优化模型,如果一个并行域扩张到N次迭代的循环之外,则并行域的创建和汇合次数将减少N-1 次。例如,代码清单8 和代码清单9 展示了一个简单的循环结构并行区域扩展,j 循环对应的并行域可以扩展到i循环之外。在并行域扩展之前,并行域创建和汇合100 次,而扩展之后并行域创建和汇合仅1 次,减少了99 次。
代码清单8循环结构并行域扩张前的代码形式

代码清单9循环结构并行域扩张后的代码形式

2)控制流并行域扩展。当并行域出现在选择结构的分支中时,可以将整个选择结构包含在一个大的并行域中。例如,代码清单10 中的if-then-else 结构,采用并行域扩张的方法能将它变为一个大的并行域,扩张后的并行结构如代码清单11 所示。这里需要注意的是,如果选择结构中含有串行分支,则必须对串行的分支进行保护或者进行计算私有化处理。
代码清单10控制流并行域扩张前的代码形式


代码清单11控制流并行域扩张后的代码形式

3)跨越函数边界的并行域扩展。并行域扩展仅能在函数内部进行通常是不够的。函数体通过并行域合并,能够将函数体内部的全部语句包含在并行域中。跨越函数体边界的并行域扩展是指将特定函数体内部的并行域扩展到整个函数的外部(即调用点处),进一步获得更多的并行域合并机会。
代码清单12 和代码清单13 展示了一个跨越函数边界的并行域扩张示例。跨越函数边界的并行域扩张扩大了并行域的范围,从而有可能进一步改善程序的结构,增加并行计算的粒度。但是,跨越函数边界的并行域扩展会彻底改变线程的堆栈结构,而且这种做法隐含着对函数体内局部变量的数据属性私有化处理。为了保证并行域扩展不修改原程序语义,必须经过定义使用链保证函数体内局部变量私有化处理的合法性,此外,还需要对数据属性的制导进行优化以消除不必要的重复私有化。
代码清单12跨越函数体边界并行域扩张前的代码形式

代码清单13跨越函数体边界并行域扩张后的代码形式


跨越函数边界的扩展是基于编译器过程间分析的结果,前提是至少能访问被调用函数的调用点和函数体。其原因是并行域扩张预示着对被调函数体的修改,被调函数体的修改对所有调用者都是可见的,因此,能够通过找到这个函数在整个程序中的所有调用点插入制导子句来完成这一扩展。如果被调函数为外部函数,过程间分析无法明确被调函数的全部调用点,又或者不能确保对被调函数进行跨函数边界的扩展使所有的调用点都受益,本文的做法是对被调函数同时生成两个版本,即复制被调函数的函数体,对复制的函数体进行跨越函数边界的并行域扩展,或保存被调函数的原函数体,因此可以不必修改被调函数的全部调用点,也不必依赖整体过程间分析结果。
2.3 并行域重构技术的算法实现
在并行域合并和并行域扩展的基础上,本文选择自底向上的递归调用算法构造SPMD 并行域。在开始时把OpenMP 程序中的每个并行循环视为小的SPMD 并行域,然后从循环的最内层开始,对相同循环层的并行循环尝试进行并行域合并,如果相同循环层的全部程序语句都包含在同一个并行域内,则向外循环层进行并行域扩展,直至遭遇不能合并的程序语句。并行域重构把多个并行域以及并行域之间的串行代码合并到一个SPMD 区域中,同时将循环体、控制流以及函数体中的并行域进行扩展,整个OpenMP 程序被包含在一个大的SPMD 并行域中,整个程序结构如代码清单14 所示。
代码清单14并行域重构后的代码框架


3 实验评估
本文的工作来源于神威平台自动并行化编译系统优化项目,并行域重构技术已集成在该系统的原型中。
3.1 实验环境、测试集及测试内容
实验环境、测试集及测试内容如下:
1)实验环境。实验环境为新一代神威高性能多核服务器SW1621。SW1621 服务器的处理器为共享内存架构的申威1621 处理器,搭载神威自动并行化编译系统、中标麒麟操作系统以及神威计算机存储管理系统等。详细的配置信息如表1 所示。

表1 实验环境Table1 Experimental environment
2)测试集。选择面向高端服务器上OpenMP 程序性能测试的NPB3.3-OMP Benchmarks 和SPEC OMP2012 Benchmarks。
NAS 并行基准测试集(NAS Parallel Benchmark,NPB)是由美国航空航天局开发的一套计算流体力学应用程序的集合,已经成为公认的测试大规模并行机和超级计算机性能的标准程序集。NPB3.x-OMP 为NPB 测试集中程序的OpenMP 并行版本,被广泛认为是检测并行计算机上的OpenMP 程序的性能标准。表2 所示为NPB3.3 测试集中每个应用程序的规模与功能。NPB 测试集中每个基准测试程序有7 类计算规模,分别为S、W、A、B、C、D、E。其中A 类规模最小,S 类是样例程序,B 类规模通常用于测试高性能服务器。因此,本文选择B 类规模进行测试。

表2 NPB3.3 Benchmarks 应用程序规模和功能Table 2 Application size and functionality in NPB3.3 Benchmarks
标准性能评估组织(Standard Performance Evaluation Corporation,SPEC)是一个全球性的第三方非营利性组织,致力于建立、维护和认证一套应用于评测计算机系统性能的标准化基准套件。SPEC 历经多年的开发积累和沉淀,已经成为全球众多用户广泛认可的标准测试程序。SPEC OMP2012 专注于测试计算机系统中OpenMP 程序性能,强调OpenMP 并行编译器支持和库支持。表3 所示为SPEC OMP 测试集中每个应用程序描述。数据输入规模从小到大分别test、train 和ref,本文选择ref 规模进行测试来验证本文方法的准确性。

表3 SPEC OMP2012 Benchmarks 应用程序规模和功能Table 3 Application size and functionality in SPEC OMP2012 Benchmarks
3)测试内容为并行域重构技术对自动并行化编译系统的性能提升效果。在神威1621 服务器上,分别使用原自动并行化编译系统和集成了并行域重构技术的自动并行化编译系统,编译运行NPB3.3-OMP Benchmarks 和SPEC OMP2012 Benchmarks 中的应用程序,检查编译和运行结果,对比运行时间,计算运行效率提升。运行效率提升的计算公式为:

其中:T1为原自动并行化编译系统生成的目标码运行时间;T2为集成了并行域重构技术的自动并行化编译系统生成的目标码运行时间;E为运行效率提升,当E>0 时,说明本文方法对自动并行化编译系统的运行效率有提升,当E≤0 时,说明本文方法对自动并行化编译系统的运行效率没有提升或者降低。
3.2 实验结果与分析
神威1621 高性能服务CPU 集成了16 颗Core3A处理器,为了检测并行域重构技术在充分发挥多核处理器体系结构优势下的运行效率提升效果,本文选择了16 线程的运行时间作为参考依据。NPB3.3-OMP Benchmarks 的测试结果静态统计和运行效率提升如表4 和图4 所示,SPEC OMP2012 Benchmarks的测试结果静态统计和运行效率提升如表5 和图5所示,其中,√表示编译通过且运行结果正确。

图5 SPEC OMP2012 Benchmarks 运行效率Fig.5 Running efficiency of SPEC OMP2012 Benchmarks

表4 NPB3.3-OMP Benchmarks 测试结果Table 4 Test results for NPB3.3-OMP Benchmarks

表5 SPEC OMP2012 Benchmarks 测试结果Table 5 Test results for SPEC OMP2012 Benchmarks

图4 NPB3.3-OMP Benchmarks 运行效率Fig.4 Running efficiency of NPB3.3-OMP Benchmarks
由表4 和表5 可知,集成了并行域重构技术的自动并行化编译系统编译通过了全部NPB3.3-OMP Benchmarks 和SPEC OMP2012 Benchmarks 中的基准程序,且运行结果全部正确。分析其原因是由于并行域重构技术主要集中在中间优化过程,采用的是保守型的做法,对后端机器描述文件和系统的基础库影响比较少,因此不影响整个编译系统的正确性。
图4 结果显示,在NPB3.3-OMP Benchmarks 中运行效率提升比较明显的是BT、FT、SP、UA、IS、MG、LU,整体运行效率提升10.77%。BT、SP 和UA这3 个基准程序的核心循环段都存在函数调用,尤其是BT 和SP 核心段非常相似,都是分别对块三对角系统的X、Y和Z方向求解,核心循环段中函数调用为3 个求解器(xsolve,ysolve,zsolve)。原自动并行化编译器分别对3 个求解器(xsolve,ysolve,zsolve)的循环添加“!$OMP PARALLEL DO”制导语句,并行域重构技术通过函数体扩展将“!$OMP PARALLEL DO”制导语句扩展到整个循环体之外,扩大了整个并行区域,减少了线程组频繁创建的开销,取得了10%以上的运行效率提升。在IS、MG 和LU 核心循环段相对集中,并行的循环段之间存在一条或多条串行语句,原自动并行化系统分别针对这些循环段并行处理,添加并行编译指示,没有将相邻的并行循环段做合并处理,并行域重构技术通过修改部分属性冲突的变量(例如,LU 中的i、j+e、k等)合并了部分相邻的循环段,因此也取得了一定的加速比提升。
图5 结果显示,在SPEC OMP2012 Benchmarks中性能提升较明显的是367、370、376、360、372,整体运行效率提升7.94%。367 的核心为拉普拉斯卷积函数中的计算循环段,这些计算循环段之间存在部分赋值语句,或存在加、乘赋的串行执行语句,并行域重构技术先将这些语句限制为单线程执行,然后再与其他相邻的并行域进行合并。该课题成功合并的并行域比较多,数据连续性得到改善,因此运行效率提升明显。370、376、360、372 这4 道课题热点函数本身含有的循环段并不多,这些课题的共同特点是核心循环段中存在较多的嵌套并行循环层,并行域重构技术通过循环并行域扩展将并行域外提,减少了嵌套循环内部并行域频繁创建和合并的开销,提高了运行效率。虽然362 课题成功合并了较多的并行循环,但是核心循环段中始终存在两个无法合并的规约变量冲突,因此取得运行效率提升并不明显。
实验结果显示,NPB3.3-OMP 的整体运行效率提升效果优于SPEC OMP2012,其原因是SPEC OMP2012 的程序规模较大,复杂程度相对较高,包含了更多难以分析的函数调用,数据变量的属性存在较多复杂的读写操作,编译器层面无法进行有效的并行域合并。例如350 和362 虽然合并了大量的并行域,但是在几个热点函数核心循环段中的函数调用关系比较复杂,或者私有变量存在太多比较复杂的操作导致无法进行合并,因此没有取得明显的运行效率提升。
4 结束语
为提升神威高性能多核服务器自动并行化编译系统生成的OpenMP 程序的执行效率,本文提出一种并行域重构技术。该技术通过并行域合并和并行域扩展来扩大OpenMP 程序中的并行域范围,减少OpenMP 程序的并行域数目,降低线程组频繁创建和合并等控制开销,并将标准的fork-join 执行模型转换成高效的SPMD 执行模型。为测试并行域重构技术性能的提升效果,本文通过NPB3.3-OMP 和SPEC OMP2012 测试集在新一代神威高性能多核服务器SW1621 上进行实验,结果表明,并行域重构技术不影响自动并行化编译系统的正确性,且运行效率明显提升。后续将在并行域重构技术的基础上结合数据依赖分析及数据划分等技术,消除并行域中的冗余同步操作,进一步提升神威平台OpenMP 程序的并行执行效率。
猜你喜欢
现代电子技术(2022年8期)2022-04-13
山西电子技术(2021年3期)2021-06-28
新世纪智能(语文备考)(2020年4期)2020-07-25
网络安全技术与应用(2020年1期)2020-01-07
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
