
基于图神经网络的异构信任推荐算法
2022-09-15 06:59徐上上孙福振王绍卿董家玮吴田慧
计算机工程 2022年9期
徐上上,孙福振,王绍卿,董家玮,吴田慧
(山东理工大学计算机科学与技术学院,山东淄博 255049)
0 概述
随着互联网技术的发展及社交媒体的普及,网络社交逐渐成为人们拓展社交关系的重要途径。传统社交推荐算法通过矩阵分解[1-3]获得用户特征和项目特征表示,在一定程度上解决了数据稀疏问题,但通过矩阵分解方式获得的用户和项目特征的表示准确度较低。为解决这一问题,学者们将用户间的社交关系对用户和项目的影响加入推荐算法[4-5],之后还将地理位置[6]、群组信息[7]、连接关系[8]等其他附加信息与社交关系相融合,然而随着信息产业的发展,互联网上的个人隐私保护[9-10]受到了广泛关注,可获取的用户和项目的显式信息非常有限,因此挖掘用户和项目的潜在关联关系具有重要意义[11-13]。
为准确描述用户和项目特征,并进一步说明某一用户对其他用户和评分项目的影响力传播过程,马帅等[14-15]使用图神经网络来增强社交推荐,何昊晨等[16-18]利用节点表示用户和项目特征,通过图结构对影响力扩散过程进行建模,更好地模拟现实生活中用户复杂的社交关系。然而,多数社交推荐算法将社交关系看作是静态的。WU 等[19]提出DiffNet模型,将用户之间的社交信任关系在图结构中进行迭代计算,最终形成用户之间的动态影响力进行传播。另外,多数算法将社交影响力假设为恒定权重,为缓解这一问题使算法更贴合现实情况,张浩博等[20-21]将注意力机制融入算法,WU 等[22-23]在社交关系动态建模的基础上加入注意力机制,对用户特定的注意力权重进行分配计算。
上述社交推荐算法在一定程度上捕获了社交影响力的传播特征,加强了对用户和项目特征的学习,提升了算法预测精度,但用户和项目缺乏对高阶相关特征的学习,并且只是简单地将图结构中与当前节点存在关联的所有邻居节点进行聚合,未区分节点和边的类型,同时仅对用户间的社交影响力进行分析,忽略了项目间的相互影响,其中注意力机制在一定程度上提升了算法预测精度,但对邻居节点的权重分配可解释性较差。为充分挖掘存在高阶相关性特征的用户或项目间的关系,增强推荐模型的可解释性,本文将用户和项目的初始特征与潜在特征进行融合,利用融合后的特征进行影响力迭代获得更新后的特征,最终将用户和项目特征聚合进行评分预测。
1 相关工作
1.1 传统评分预测模型
传统评分预测模型将评分矩阵进行矩阵分解,得到用户和项目的低维潜在特征,对应的用户和项目特征进行内积运算,获得预测评分,如式(1)所示:

SVD++在此基础上将每个用户交互过的项目特征作为辅助信息融入用户特征,如式(2)所示:
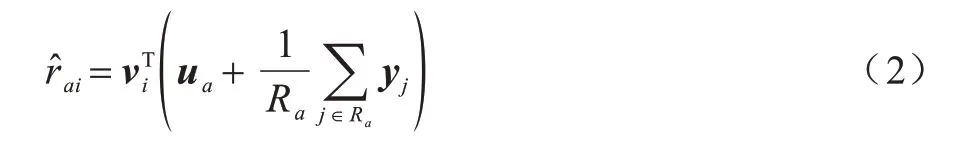
其中:Ra表示用户a交互过的项目集合;yj表示用户a交互过的项目特征。
1.2 基于动态社交影响力传播的DiffNet 模型
DiffNet 模型[19]将用户-项目对作为输入,预测用户是否对该项目感兴趣,主要分为嵌入层、融合层、影响力扩散层和预测层四部分。
1)嵌入层使用PD×M表示用户潜在特征矩阵,QD×N表示项目潜在特征矩阵,赋予随机值作为初始值,其中,D为特征维度,M为用户数,N为项目数。
2)融合层将嵌入层的用户特征矩阵与提取的用户初始特征矩阵XD×M相结合送入全连接层,得到的最终用户特征作为模型的用户输入,如式(3)所示:

其中:W0为转换矩阵;g(·)为非线性激活函数。
同理,提取的项目初始特征矩阵为YD×N,作为模型输入的项目特征,如式(4)所示:

其中:σ为Sigmoid 函数;F为转换矩阵。
3)影响力扩散层模拟用户社交影响力的动态传播过程,将融合后的用户特征作为该层的初始输入。社交影响力在本层进行迭代计算,k-1 层输出的用户特征输入到第k层,在k层影响力扩散完成后,输出更新后的用户特征,再将其作为k+1 层的输入,直至模型达到平衡状态,如式(5)、式(6)所示:
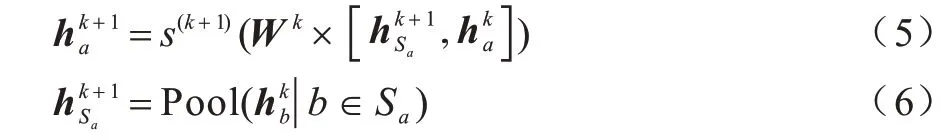
其中:Sa表示用户a信任的用户集合,若用户a信任用户b则sab=sba=1,否则sab=sba=0。由两部分组成,具体为通过聚合用户a信任的邻居用户b得到与第k层用户a的特征。
4)预测层用户a的最终特征由影响力扩散层迭代k次得到的用户特征与用户a交互过的项目i的特征vi两部分聚合而成,预测评分由最终的用户和项目特征内积运算获得,如式(7)所示:

1.3 影响力传播方式
在图神经网络中,多数算法不区分节点类型,例如,假设用户a、b交互过项目i,那么存在a↔i↔b相互联系,当用户a对用户b进行影响力传递时,会先通过项目i影响用户a的特征,再由用户b影响项目i的特征,最终用户a的影响力传递到用户b,如式(8)、式(9)所示:


其中:Ri为交互过的项目i的用户集合;δ函数根据特定情景进行指定。
HIN 模型[24]提出将同类型节点进行聚合的思想。假设以用户为起点,找到a↔i↔b这条通路,保留同类型节点即保留用户节点而忽略项目节点,那么存在a↔b相互联系,用户间和项目间影响力传播的过程如式(10)、式(11)所示:

2 基于图神经网络的异构信任推荐
2.1 同类型节点和边的影响力传播
不同于异构影响力传播方式,本文将节点类型和边类型进行分类,见图1,节点类型包含用户和项目两类。从聚合同类型节点特征的角度估计节点间的影响力,因此在仅考虑用户集合时,图结构中包含3 种用户间关系,如图1(a)~图1(c)所示,其中关系1 为显式信任关系,关系2 和关系3 为隐式信任关系。在仅考虑项目集合时,图结构存在如图1(d)所示的项目关联关系4。隐式关系可以缓解显式信息稀疏导致推荐性能不佳的问题,因此边类型分为直接好友、基于用户的潜在好友、基于项目的潜在好友和关联项目4类。
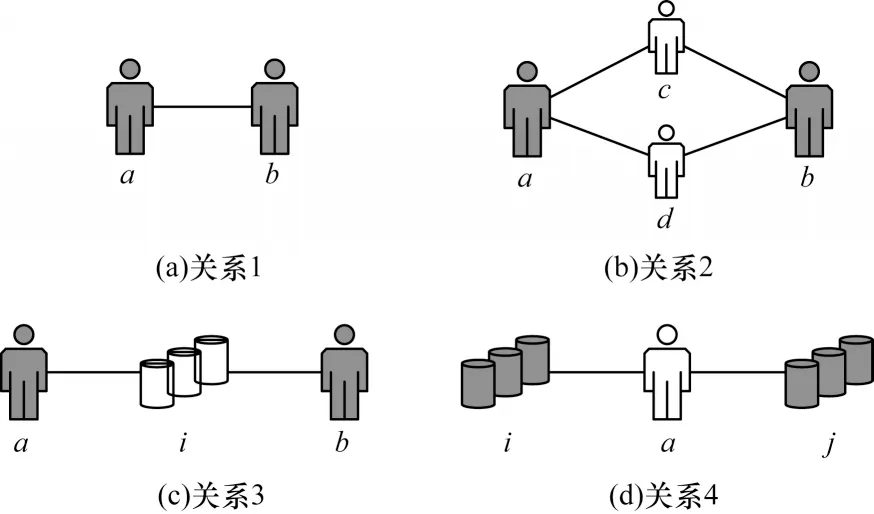
图1 边的分类Fig.1 Classification of edges
2.1.1 用户间的影响力
直接好友通过用户-用户社交图直接获得,基于项目的潜在好友根据用户-项目评分图获得,对相同的项目感兴趣的两个用户有相似的偏好,可能成为好友,因此笔者认为交互过同一个项目的用户即为潜在好友。基于用户的潜在好友可以通俗地理解为“朋友的朋友是朋友”,但并不是所有“朋友的朋友”都可称为用户的潜在好友。
以图2 为例,用户的社交关系非常复杂,“朋友的朋友”可能是用户自身,也可能是他的直接好友,如用户a与b、c的关系,因此在基于用户的潜在好友中,首先将用户a的直接好友与其自身排除。用户与“朋友的朋友”关系强度也不同,如用户a与e有一个共同好友b,用户a与g有两个共同好友c和d,那么用户g比用户e更可能是a的潜在好友,a对g的影响可能更大。在影响力传播时,笔者认为邻居好友对用户的影响是相同的且和为1,那么用户e受到a的影响程度实际比用户g要大,与实际情况不符。针对该情况,假设用户与“朋友的朋友”的共同好友数大于等于t时,认为其是基于用户的潜在好友。实验结果证明,当t=2 时效果最佳。在实验中,t的初始值为1,通过不断增大t值来观察其对实验结果的影响。当t<2 时,用户与“朋友的朋友”的潜在信任关系数较多,如两个用户的共同好友仅为中介服务人员、老师、医生等社交圈复杂的用户时,容易存在较大偶然性,不足以区分是否为真正偏好相似的潜在好友关系。当t逐渐增大时,由于数据集中的显式数据稀疏,符合条件的基于用户的潜在好友越来越少,推荐性能降低。

图2 基于用户的潜在好友Fig.2 Potential friends based on users
在用户特征聚合时,通过直接好友、用户的潜在好友和项目的潜在好友这3 条路径均使用平均池化操作进行特征聚合,如式(12)~式(14)所示:
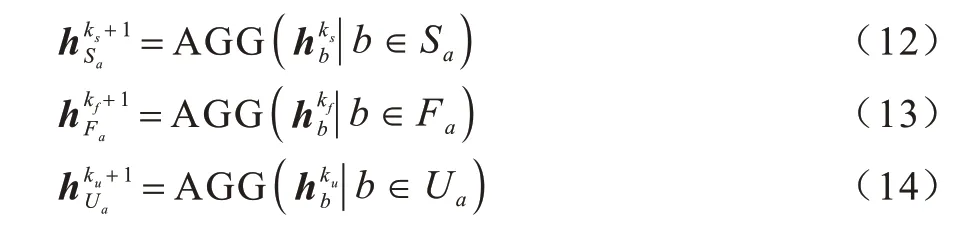
其中:Fa表示用户a符合条件的基于用户的潜在好友集合,若用户a信任用户b,则fab=fba=1,否则fab=fba=0;Ua表示用户a基于项目的潜在好友集合,用户a信任用户b,则有uab=uba=1,否则uab=uba=0。
2.1.2 项目间的影响力
传统社交推荐算法在挖掘用户潜在好友时,通常基于协同过滤方法并以用户为关注重点,将项目看作用户建立关系时的辅助信息,认为交互过同一个项目的用户即为潜在好友。然而,项目不是一个独立不变的个体,受到用户的影响,项目之间也是相互联系相互影响的。两个关联性不强的项目通常通过用户的交互行为产生关联。为挖掘项目间的隐式关系提升推荐精度,本文提出以下假设:在评分图中以项目为中心,同一个用户交互过的项目也被认为存在关联,称为项目关联,如图1 中关系4 所示,存在关联的项目可能相互影响,使各自的特征发生改变。使用Li表示与项目i关联的项目集合,若项目i与j存在关联,则lij=lji=1,否则lij=lji=0。项目通过平均池化操作进行聚合,如式(15)所示:

2.2 模型融合
社交影响力在社交网络中不断传播扩散,潜在特征受好友、潜在好友和交互项目的影响不断变化。为了更好地捕捉高阶相关特征,使用动态影响力传播模型模拟该过程对潜在特征造成的影响。假设表示用户潜在特征矩阵,QD×N表示项目潜在特征矩阵,赋予随机初始值,通过边的类型分别进行训练。
1)使用式(3)的融合方式,将用户潜在特征与用户初始特征XD×M在融合层进行融合,如式(16)~式(18)所示。为了区分用户和项目两种节点类型,使用式(4)中σ(·)函数对项目潜在特征与项目初始特征YD×N进行融合,如式(19)所示。
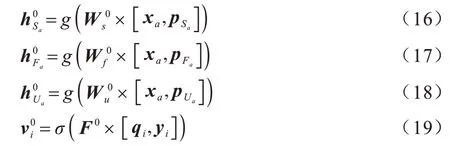
2)用户与直接好友、基于用户的潜在好友、基于项目的潜在好友和项目之间的影响在影响力扩散层进行传播并更新用户与项目特征,如式(20)~式(23)所示:
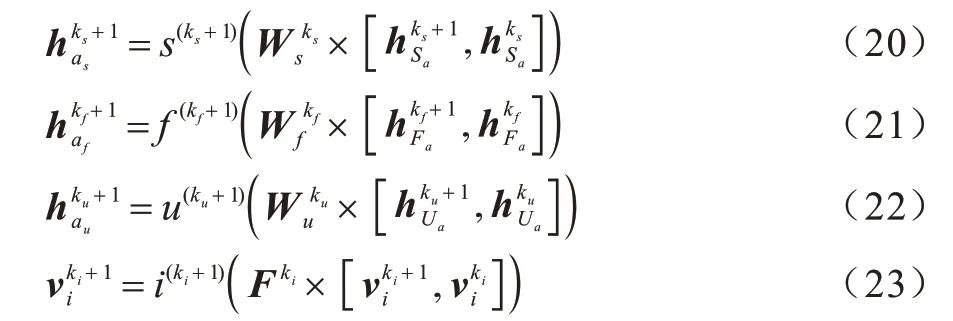
其中:函数s、f、u和i为非线性变换函数;对于层数k,将k-1 层的输出作为输入,完成当前层的影响力扩散后输出更新后的用户特征,作为k+1 层的输入,循环传播达到最大深度k后结束传播。当ks=2、kf=ku=ki=1 时算法性能为最佳。
3)用户a和项目i的最终特征如式(24)所示:
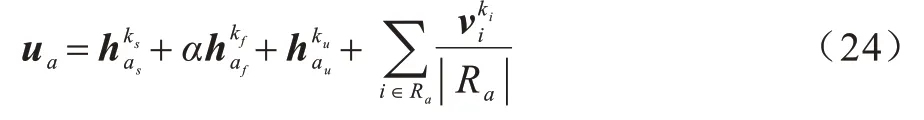
其中:α为超参数,基于用户的潜在好友的聚合是为了弥补在高阶传播时影响力没有被深入传达的部分,使模型能够更好地捕捉高阶相关特征,用户的影响力在高阶传播时显然小于低阶传播,因此的权重要小于其他用户特征,通过实验证明了当α=0.1 时效果最好;用户的历史偏好作为辅助信息加入到用户特征中。
4)使用基于成对排序损失函数进行模型训练,如式(25)所示:
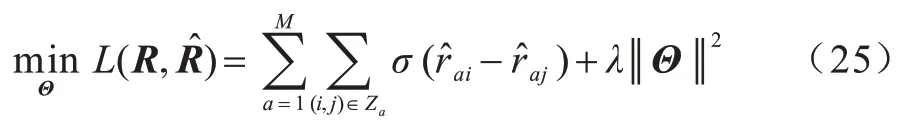
其中:L表示损失函数;R为原数据集的评分矩阵;为模型给出的预测评分矩阵;σ为Sigmoid 函数;λ是一个正则化参数,用于控制用户和项目潜在特征矩阵的复杂性;Θ=[Θ1,Θ2]、Θ1=[PS,PF,PU,Q]、Θ2=;Za表示用户a喜欢和不喜欢的项目对集合。
2.3 算法框架
本文异构信任推荐算法(GraphTrust)的整体框架如图3 所示。首先将用户和项目的初始特征与潜在特征进行融合,然后将融合后的特征通过不同的影响力迭代获得更新后的特征,最后将用户和项目特征进行内积预测用户是否对项目感兴趣。
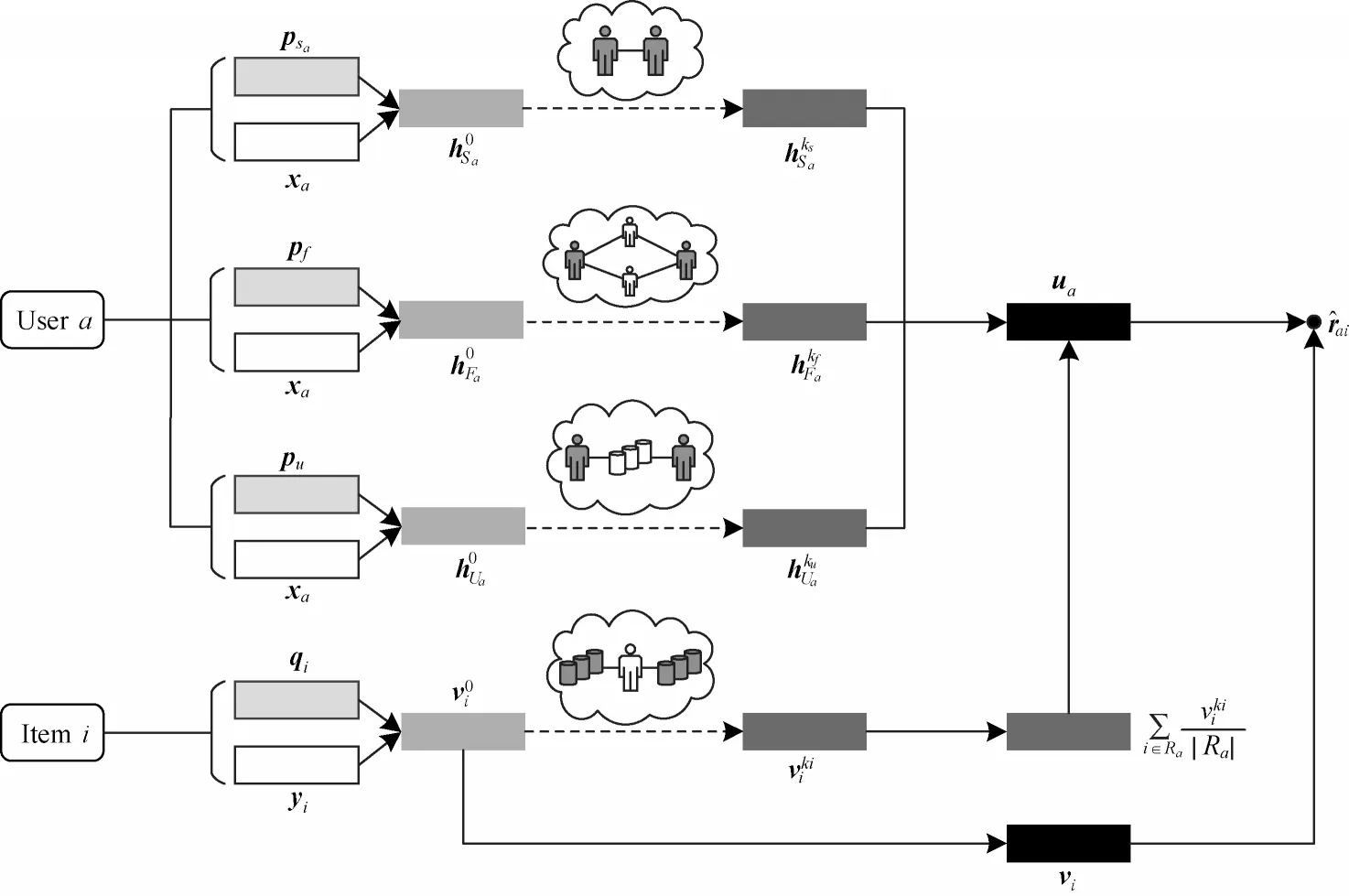
图3 GraphTrust 算法整体框架Fig.3 Overall frame of GraphTrust algorithm
算法1GraphTrust 算法
输入融合后的用户特征和项目特征
输出用户的Top-K 推荐
1)通过式(20)~式(23)对用户和项目特征进行更新:
(1)根据式(20)对用户与直接好友的影响力进行传播并更新用户特征;
(2)根据式(21)对基于用户的潜在好友的影响力进行传播并更新用户特征;
(3)根据式(22)对基于项目的潜在好友的影响力进行传播并更新用户特征;
(4)根据式(23)对项目之间的影响力进行传播并更新项目特征。
2)生成最终用户特征和项目特征:
(1)根据更新后的用户特征和用户的历史交互项目特征作为辅助信息生成最终用户特征;
(2)融合后的项目特征作为最终项目特征。
3)将最终用户特征和最终项目特征做内积运算,预测用户对项目的评分。
3 实验设计与结果分析
3.1 数据集选取
选取Yelp 和Flickr 两个公开数据集[18]来评估GraphTrust算法。Yelp 是一个在线点评网站数据集,在网站中用户可以给商家打分、发表评论、与朋友交流互动等,用户根据自己的体验在0~5分内给出评分。Flickr是一个社交分享平台数据集,用户在平台上分享照片,其他好友通过点赞的形式表示自己的喜好。Yelp 和Flickr 两个数据集过滤了低于2 分评分的记录和低于2个社交好友的用户,以及用户交互次数低于2的项目,处理后的数据集统计信息如表1 所示。数据集随机选取每个用户5%的评分记录作为测试集,10%的评分记录作为验证集,其余数据作为训练集。
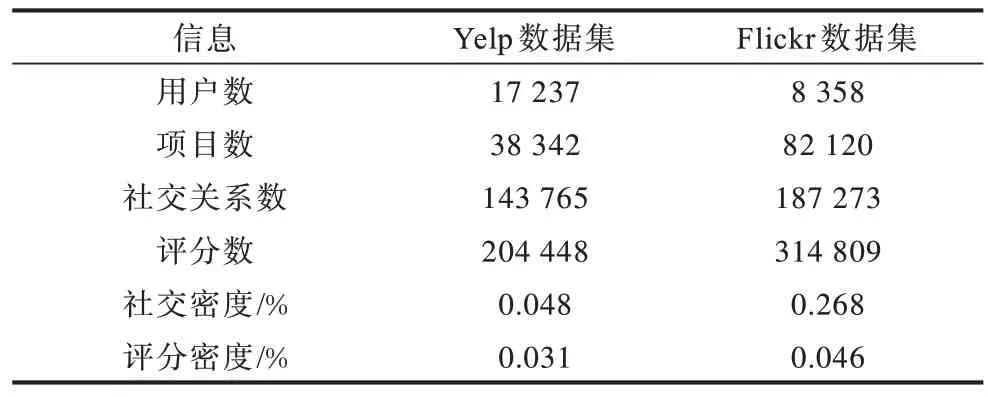
表1 数据集统计信息Table 1 Dataset statistics
3.2 评价标准设置
选取Top-K 推荐中常用的两个评价指标:命中率(Hits Ratio,HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)。两个指标的值越大,算法性能越好。由于数据集中用户未交互的项目较多,为了提高效率,每次为用户随机选取1 000 个未交互项目进行评价,并将这些项目与用户排名过程中喜欢的项目结合,重复10 次该过程,取平均排名结果。
3.3 对比实验分析
为验证GraphTrust 算法的有效性,选取如下算法作为对比:基于矩阵表示社交信息的SocialMF[4]和TrustSVD[5]算法,基于图神经网络的NGCF[17]和GraphRec[18]社交推荐算法,社交影响力动态扩散建模的DiffNet[19]和DiffNet++[23]算法。GraphTrust-F 表示在GraphTrust算法中仅保留图1 中的关系1和关系2,GraphTrust-FU 表示在GraphTrust 算法中仅保留图1 中的关系1、关系2和关系3,GraphTrust-I 表示在GraphTrust 算法中仅保留图1 中的关系1 和关系4。
使用TensorFlow 进行实验,设置潜在特征维度D为16、32 和64,根据文献[4-5,17-19,23]中推荐的参数加以调试选取最优参数,在初始化潜在特征时选取较小的随机值,正则化参数为0.001,学习率为0.001。Batch-size 大小设置为512,使用Adam 优化器对模型进行优化。表2 为算法在不同潜在特征维度参数下HR@10 和NDCG@10 的结果,其中最优指标值用加粗字体标示。
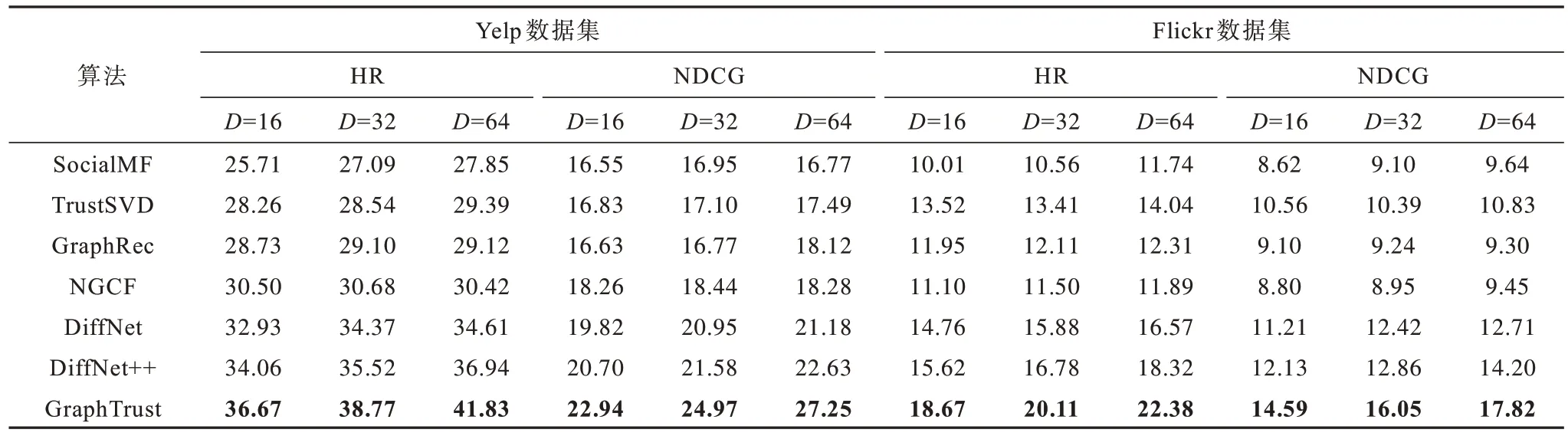
表2 社交推荐算法在不同潜在特征维度下的HR@10 和NDCG@10 结果Table 2 Results of HR@10 and NDCG@10 of social recommendation algorithms under different potential feature dimensions %
由表2 可以看出,GraphTrust 推荐精度高于对比算法,当特征维度D=16、D=32 和D=64 时,在Yelp 数据集上,HR 比最优对比算法分别提升了7.7%、9.1%和13.2%,NDCG 分别提升了10.8%、15.7%和20.4%,在Flickr 数据集中,HR 比最优对比算法分别提升了19.5%、19.8% 和22.2%,NDCG分别提升了20.3%、24.8%和25.5%。随着数据集评分和社交密度的增大,算法整体性能进一步提升,验证了GraphTrust 的有效性。基于图神经网络的GraphRec 和NGCF 社交推荐算法在HR 和NDCG 上多数优于基于矩阵表示社交信息的SocialMF 和TrustSVD 算法,这说明图神经网络可以根据特定的数据和场景,将图设定为同构图或异构图、静态图或动态图,利于学习复杂的社交关系和高阶相关特征来提升推荐精度。每个节点不仅受到显式关系所表示的一阶节点的影响,还受到高阶结构的影响,因此考虑社交影响力动态扩散的DiffNet 和DiffNet++能更好地模拟现实生活中的影响力流动,使推荐结果更优。GraphTrust 在动态建模基础上,将图神经网络中的节点和边进行分类,通过不同类型的边在不同节点间进行影响力传播扩散,捕捉隐藏在高阶网络结构中的影响力扩散特征,使得用户和项目的潜在特征随着影响力传播过程最终达到平衡状态。实验结果表明,GraphTrust 算法性能优于最优对比算法。异构网络中不同类型的节点和边通常带有不同的语义信息,对用户偏好的影响也不同,本文通过区分节点和边类型的重要程度并分别考虑不同节点和边类型的影响,得到最终预测评分,使得推荐过程具有较好的可解释性。
3.4 消融实验分析
用户间的影响力可以缓解社交影响力在高阶传播时被分散导致影响力不足的问题。通过增加基于用户的潜在好友来调整高阶传播时边的权重,由图4可以看出,相比于每次传播使用相同权重的DiffNet,GraphTrust-F 能更好地捕捉高阶传播时的社交影响力,赋予新的权重分配弥补影响力传播不足的问题,使得推荐效果有所提升。但是,GraphTrust-F 仅通过一种潜在好友关系对用户节点进行特征学习,相对于更新用户和节点特征的DiffNet++仍有一定差距。
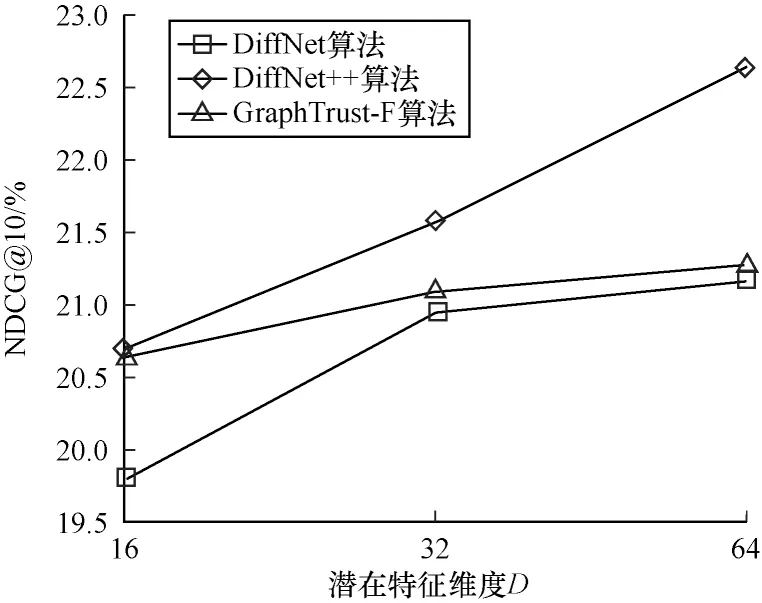
图4 Yelp 数据集上DiffNet 与GraphTrust-F 的NDCG@10 结果对比Fig.4 Comparison of NDCG@10 results between DiffNet and GraphTrust-F on Yelp dataset
由图5 可看出,GraphTrust-FU 通过潜在好友调整高阶传播的权重,同时将社交影响力通过不同类型的边进行扩散传播,相比于加入注意力机制的DiffNet+型效果更优。

图5 Yelp 数据集上DiffNet 与GraphTrust-FU 的NDCG@10 结果对比Fig.5 Comparison of NDCG@10 results between DiffNet and GraphTrust-FU on Yelp dataset
根据项目间影响力的假设进行实验,在GraphTrust 算法中仅保留对项目改进的部分,即GraphTrust-I。由图6 可以看出,相对于项目是独立个体的观点,由用户交互而产生影响使得项目间相互联系这一假设是成立的,GraphTrust-I 在D取16、32 和64 时的NDCG@10 比DiffNet++分别提升了3.3%、4.2%和8.5%,比DiffNet 模型分别提升了7.9%、7.3%和15.9%,提升效果显著。GraphTrust 利用项目节点更新项目特征的分类,这种更新方式相对于不区分节点类型更新项目节点的DiffNet++有小幅提升,相对于不更新项目节点,仅把项目节点作为辅助信息加入到用户特征的DiffNet 提升较多。因为将更新后的项目特征进行聚合,可以缓解用户的社交关系稀疏导致推荐精度降低这一问题,进而提升了推荐性能。

图6 Yelp 数据集上DiffNet 与GraphTrust-I 的NDCG@10 结果对比Fig.6 Comparison of NDCG@10 results between DiffNet and GraphTrust-I on Yelp dataset
3.5 特征维度对GraphTrust 算法性能的影响
在不同潜在特征维度D下对GraphTrust 算法性能进行实验验证。由图7 可以看出,当潜在特征维度过小时,用户和项目的特征无法被充分表示,随着潜在特征维度的增大,算法效果不断提升。在16≤D≤64 时增长较快,在超过64 时推荐精度增长缓慢,逐渐趋于平缓。这说明虽然潜在特征维度增大可以表示更多的特征,但增大到一定维度时,无关特征也会被考虑在内,导致实验结果差异较小但计算复杂度相对增加,且容易出现过拟合的风险,因此本文选取潜在特征维度D为16、32 和64 进行实验验证。

图7 潜在特征维度对GraphTrust 性能的影响Fig.7 Impact of potential feature dimensions on GraphTrust performance
4 结束语
传统基于图神经网络的社交推荐算法通常忽略了用户间的多种社交关系,且对于项目节点关注较少。本文提出一种基于图神经网络的异构信任推荐算法GraphTrust,通过挖掘用户的多种潜在好友和不同的社交关系实现影响力动态传播,同时模拟项目间的影响力传播过程更新项目特征,并将其作为用户特征的辅助特征进行评分预测。对比实验结果表明,GraphTrust 算法在Yelp 和Flickr 数据集上相较于其他算法具有明显的性能提升。消融实验结果验证了在用户交互行为的作用下项目之间存在相互影响。目前多数研究仅将社交和评分关系加入到推荐算法中,而现实生活中还存在许多交互信息,因此后续将考虑用户与用户、用户与项目以及项目与项目之间的多种交互行为,并对用户和项目冷启动问题进行相关研究,进一步提升算法推荐精度。
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
小雪花·初中高分作文(2019年10期)2019-02-12
文苑(2018年17期)2018-11-09
NBA特刊(2018年14期)2018-08-13
杂文月刊(2017年20期)2017-11-13
人大建设(2017年11期)2017-04-20
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
