
时空特征金字塔模块下的视频行为识别
2022-09-15 10:27:42龚苏明
计算机与生活 2022年9期
龚苏明,陈 莹
江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122
在计算机视觉领域,对人类行为识别的研究既能发展相关理论基础,又能扩大其工程应用范围。对于理论基础,行为识别领域融合了图像处理、计算机视觉、人工智能、人体运动学和生物科学等多个学科的知识,对人类行为识别的研究可以促进这些学科的共同进步。对于工程应用,视频中的人类行为识别系统有着丰富的应用领域和巨大的市场价值。其应用领域包括自动驾驶、人机交互、智能安防监控等。
早期的行为识别方法主要依赖较优异的人工设计特征,如密集轨迹特征、视觉增强单词包法等。得益于神经网络的发展,目前基于深度学习的行为识别方法已经领先于传统的手工设计特征的方法。Karpathy 等率先将神经网络运用于行为识别,其将单张RGB图作为网络的输入,这只考虑了视频的空间表观特征而忽略了时域上的运动信息。对此,Simonyan 等提出了双流网络。该方法使用基于RGB 图片的空间流卷积神经网络(spatial stream ConvNet)和基于光流图的时间神经网络(temporal stream ConvNet)分别提取人类行为的静态特征和动态特征,最后将双流信息融合进行识别。Wang 等提出了时间片段网络(temporal segment network,TSN)结构来处理持续时间较长的视频,其将一个输入视频分成段(segment),然后每个段中随机采样得到一个片段(snippet)。不同片段的类别得分采用段共识函数进行融合来产生段共识,最后对所有模型的预测融合产生最终的预测结果。为了解决背景信息干扰,周波等结合目标检测使神经网络有侧重地学习人体的动作信息。刘天亮等提出融合卷积网络(convolutional neural network,CNN)与长短期记忆网络(long short-term memory,LSTM)的行为识别方法来指导网络学习更有效的特征。借鉴2D 卷积神经网络在静态图像的成功,Ji等将2D 卷积拓展为3D 卷积,从而提出了3D-CNN 方法来提取视频中的运动信息。Qiu 等将3D 卷积解耦为2D 空间卷积和1D 时间卷积,在一定程度上减少了网络参数,缓解了网络难以优化的问题。Zhou 等提出了结合3D 和2D 的想法,其核心思想是在空间2D 卷积网络中,加入3D卷积核(×1×1)来获取视频序列中多帧之间的相关信息,以此来补充时间维度上的特征。
上述方法中,普通的2D 卷积网络无法学习输入帧间时空特征信息,从而导致整体结果不佳;3D 卷积方法虽然能同时提取表观信息和时空特征信息,但网络参数过多致使网络难以优化。基于此,本文提出全新的时空特征金字塔模块,该模块对输入特征构建特征金字塔模型并使用空洞卷积金字塔提取输入帧间时空特征信息,同时只引入较少的额外参数和计算量。该模块是一种即插即用模块,能嵌入主流2D 卷积网络中提升识别精度。
1 时空特征金字塔网络
本章首先介绍残差网络ResNet50的构成模块Bottleneck;接着介绍将特征金字塔模块引入Bottleneck 后的网络构成模块;最后给出本文网络的整体架构。特征金字塔模块将在2.1 节详细介绍。
1.1 ResNet50 基础模块问题分析
ResNet50 由4 个网络层(Stage1~4)构成,每层构成模块是Bottleneck,其结构过程如图1(a)所示。该模块首先对输入特征图使用1×1 卷积(Conv1)进行卷积操作,主要目的是为了减少参数的数量,从而减少计算量,且在降维之后可以更加有效、直观地进行数据的训练和特征提取。接着使用感受野较大的3×3 卷积(Conv2)来提取更细化特征。最后使用1×1卷积(Conv3)进行升维操作,使输出能与原始输入维度相匹配,从而进行特征相加。

图1 ResNet50 构成模块及改进模块Fig.1 Composition module of ResNet50 and corresponding improvement module
从图中可以看到,模块输入尺寸为[,,,],表示批大小(batch_size),表示输入帧数,表示通道数,、则是特征图尺寸大小。尽管网络输入帧数为,但维度一直与维度在一起,因此网络依旧是对每帧输入进行单独操作,并未提取帧间信息。
为了解决Bottleneck 存在的问题,本文提出了时空特征金字塔模块并将其插入Bottleneck构建STFPB(spatio-temporal feature pyramid block),该模块流程如图1(b)所示。
输入特征[,,,]首先经过1 次卷积操作变成[,,,],记为;然后将送入STFPM(spatio-temporal feature pyramid module)提取时空特征信息,在此部分特征尺寸将变为[,1,,],得到时空特征后将特征尺寸转化为原始尺寸;然后将、、等加权融合,其中权值固定为1,、等权值由网络学习得到;最后将融合特征送入后续的两个卷积层并与原始输入特征相加。
1.2 网络整体架构
以STFPB 为基础,本文构建了全新的行为识别网络STFP-Net。网络整体结构如图2 所示。图中,黑色虚线框表示网络层(stage),紫红色立方体表示输入,黄色矩形表示卷积核为7×7 的卷积操作,蓝色立方体表示ResNet50 原本的Bottleneck(①~⑬),红色立方体表示STFPB(⑭~⑯),绿色框表示全连接层(Fc),橙色椭圆表示交叉熵损失函数,紫色圆圈则是每类结果的预测得分。输入首先经过7×7 卷积操作进行特征图尺寸缩减,然后将输出送入Bottleneck 与STFPB 进行特征提取,最后的高层特征经过全连接层拉平后得到每类结果的预测得分,完成行为识别任务。
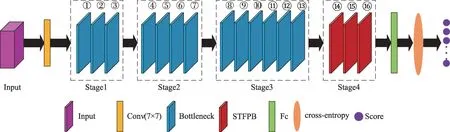
图2 网络整体架构Fig.2 Overall structure of network
2 时空特征金字塔模块
本章首先介绍特征金字塔,其作用是说明需要对哪些输入帧进行操作;接着介绍空洞卷积和由它构成的空洞卷积金字塔,其作用是提取时空特征信息;最后介绍时空特征的融合方式。
2.1 特征金字塔
给定一个输入∈R,首先通过网络提取特征,然后如图3 所示构建特征金字塔。图3 中,蓝色立方体表示某一帧图像的全部特征信息,紫色虚线立方体表示该帧被跳过,不参与特征金字塔的构建。为了画图简便,省略了维度,同时T表示第帧的全部特征信息。
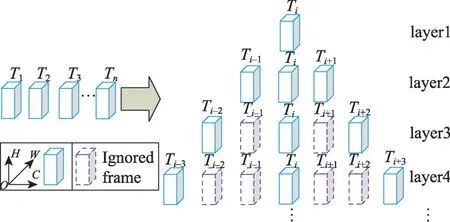
图3 特征金字塔示意图Fig.3 Schematic diagram of feature pyramid
以T为例,在特征金字塔中,T作为金字塔的第一层;然后(T,T,T)三帧图像特征信息作为金字塔第二层;接着将采样步长设为2,则金字塔第三层便是(T,T,T),此时跳过了(T,T)。以此类推,便能构建多层特征金字塔。值得注意的是,金字塔第一层只包含T,后续的每一层都包含3帧图像特征信息。
此外,和其他特征金字塔方法不同的是,本文的特征金字塔并不减小特征图的尺寸,这避免了原始信息的丢失。与此同时,本文也不引入额外的损失函数来指导网络学习,这从网络的训练和复杂性角度来说是有益的。
2.2 空洞卷积金字塔和时空特征提取
与普通卷积相比,空洞卷积多了一个超参数dilation factor。图4 给出了空洞卷积的示意图。当dilation factor 等于1 时,此时的卷积核便是普通的卷积核,随着dilation factor 的增大,卷积核的尺寸也在变大。图中红点表示卷积核需要学习的参数,其余的空白部分用0 进行填充。
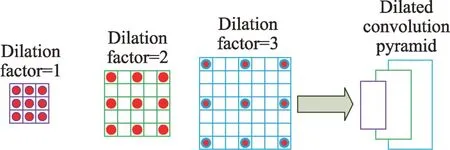
图4 空洞卷积和卷积金字塔Fig.4 Dilated convolution and convolution pyramid
空洞卷积的主要优势是在特征图不做池化操作损失信息的前提下,加大了感受野,让每个卷积输出都包含较大范围的信息。此外,空洞卷积的另一个优势便是0 值填充带来的“跳跃”特性。很多文章都没有考虑过此特性,本文将不同dilation factor的空洞卷积组合在一起,构建了空洞卷积金字塔,并将它应用到特征金字塔中提取帧间时空特征信息。

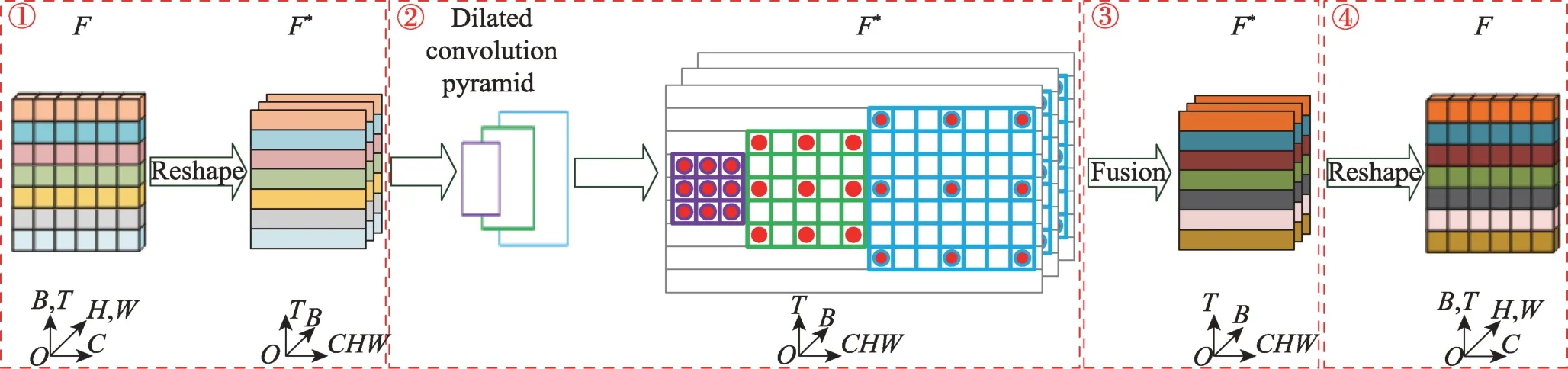
图5 时空特征金字塔详细过程Fig.5 Detailed process of spatio-temporal feature pyramid
2.3 时空特征的融合策略
对得到的时空特征,本文考虑了两种特征融合策略:特征级联和加权相加。
假设有两路通道数相同的输入(,,…,Y) 和(,,…,Z),特征级联和加权相加分别为:

式(1)、式(2)中,表示原始特征,表示提取后的特征,表示通道数,表示卷积操作,和表示权重系数。
可以这么理解上述公式,特征级联是通道数的合并,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息没有增加。加权相加则是每一维下的特征信息量在增加,特征数(通道数)没有改变。特征级联操作中每个通道对应着相应的卷积核,而加权相加操作则将对应的特征图相加,再进行下一步卷积操作,相当于加了一个先验:对应通道的特征图语义类似,从而对应的特征图共享一个卷积核。本文的核心思想是对空域特征进行时域信息的增加,这更符合特征加权相加的思想,因此,本文选用加权相加的方式进行特征融合,后续对比实验也佐证了这一想法。
本文中,第一层金字塔特征的权重固定为1,其余各层金字塔特征的权重系数由网络学习得到。
2.4 时空特征金字塔模块具体流程
完整的时空特征金字塔流程如图5 所示。给定一个输入∈R,首先通过矩阵维度变换操作,将变为∈R(图5①)。图5①中,矩形的每一行表示某一帧的全部特征。然后对使用空洞卷积金字塔进行时空特征提取(图5②),接着对得到的时空特征使用加权相加策略进行特征融合操作(图5③),此时融合后的特征的尺寸和原始输入不相符,因此需要再次使用矩阵维度转换操作将特征维度进行转换(图5④)。相比原始输入,经过时空特征金字塔模块后的特征具有时空特征信息,因此更有利于视频行为识别任务。
3 实验验证和分析
3.1 数据集介绍
本文在最常见的行为识别数据集UCF101和HMDB51上对本文网络结构进行评估实验,以便将其性能与目前主流的方法进行比较。
UCF101 数据集是从YouTube 收集的具有101 个动作类别的逼真动作视频的动作识别数据集。101个动作类别中的视频分为25 组,每组可包含4~7 个动作视频。来自同一组的视频可能共享一些共同的功能,例如类似的背景、类似的观点等。
HMDB51 数据集内容主要来自电影,一小部分来自公共数据库,如YouTube 视频。该数据集包含6 849 个剪辑,分为51 个动作类别,每个动作类别至少包含101 个剪辑。
3.2 实验设置
本文Baseline 采用ResNet50 作为主干网络。针对每个视频输入,首先将其分为8个片段,然后在每个片段随机采样1 帧,共计8 帧作为输入。网络对每帧作出预测,然后将8个预测值取平均作为最终预测值。
本文实验中,卷积神经网络基于PyTorch平台设计实现。网络采用ResNet50 作为主干网络,训练采用小批量随机梯度下降法,动量为0.9,权值在第15、35、55个epoch时衰减一次,衰减率为0.1,总训练数设置为70。初始学习率设为0.001。Dropout 设置为0.8。实验采用两张TITAN 1080Ti GPU进行,batch_size设置为24。
3.3 实验结果与分析
本文主要考虑两种特征融合策略:特征级联和加权融合。表1 给出了两种融合策略在UCF101 上的结果。从结果来看,加权融合比特征级联高了3.331个百分点,故本文后续实验均采用加权融合方式。在2.3 节中已经说明,金字塔第一层特征权值固定为1,后续层的特征权值由网络自主学习得到。

表1 特征融合策略的影响Table 1 Influence of feature fusion strategy
从2.1 节和2.2 节描述可以知道,特征金字塔的层数和空洞卷积金字塔的层数是相同的。理论上,当输入帧是无限数量时,可以构建无限多层金字塔。因此采用ResNet50 作为主干网络,然后用实验来说明金字塔层数最合理的值。实验结果如表2 所示。从结果来看,金字塔层数为3 时结果最高。主要原因如下:2 层金字塔只包含两个相邻帧的信息,这限制了它提取时间信息的能力;当层数大于等于4时,空洞卷积本身的“网格”效应造成严重的信息不连续,影响最终的识别结果。因此,在后续实验中,金字塔等级的数量固定为3。

表2 金字塔层数的影响Table 2 Influence of pyramid layers
金字塔模块可以直接嵌入到现有网络中使用,选择合适的嵌入位置对网络来说至关重要。对于深度神经网络,低层网络会提取一些边缘特征,然后高层网络进行形状或目标的认知,更高的语义层会分析一些运动和行为。
基于此共识,本文首先在ResNet50 的Stage4 中添加金字塔模块,然后逐步往低层网络添加金字塔模块。表3 给出了不同位置嵌入金字塔后的结果。从结果来看,在语义层(Stage4)嵌入金字塔模块后表现最好。当Stage3 和Stage4 同时嵌入金字塔模块后,识别结果下降了0.106 个百分点,这是因为行为识别任务更依赖语义信息。因此,本文最终只在Stage4 中嵌入金字塔模块。

表3 嵌入位置的影响Table 3 Influence of embedding position
通过前3 个小实验,本文网络最终配置为3 层金字塔,Stage4 添加和加权融合,并记为STFP-Net。一个优秀的嵌入性模块不仅能给网络带来结果正确率的提升,同时引入的额外计算量也应该很少。基于此,对本文最终网络的模型大小与计算量进行定量分析,如表4 所示。采用每秒浮点运算次数(FLOPs)作为计算量的评价指标,该指标值越大则意味着网络需要更多的计算资源。
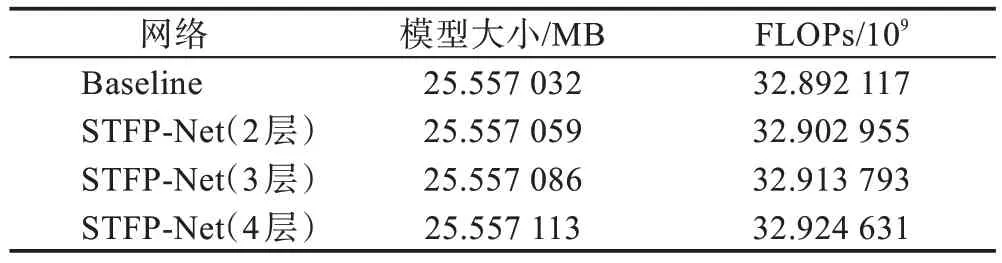
表4 模型参数和计算量Table 4 Model parameters and calculation amount
从表4 结果来看,相比于Baseline,3 层金字塔只增加了54 Byte 的模型参数,计算量只增加了0.06%,约为2×10次浮点运算数量。综上所述,本文的金字塔模块是高效的嵌入性模块。
在本小节中,将通过具体实验进一步展示所提出的STFP-Net 与最先进的动作识别方法的比较结果。关于UCF101 和HMDB51 的相关结果详见表5。

表5 与主流方法正确率的比较Table 5 Comparison of accuracy with mainstream methods 单位:%
在当下主流方法中,有的采用了先进的时空融合方法来获得高效的网络特征,如TLE;有的则利用CNN 和LSTM 网络的结合体来获得输入帧之间的序列信息以此来获得比单纯RGB 表观信息更丰富的时空信息;I3D直接将最先进的2D CNN 架构膨胀成3D CNN 网络,以利用训练好的2D 模型;为了减少参数量,P3D通过将3D 卷积分解为沿空间维度的2D 卷积和沿时间维度的1D 卷积来建模时空信息,从而学习非常深的时空特征;MiCT则提出混合2D/3D卷积模块,利用2D 卷积提取RGB 图像的表观信息,利用3D 卷积提取序列间的相关信息。ISTPA-Net通过对不同网络层的特征进行下采样从而构建注意力金字塔,旨在突出特征图中某些重要的特征,同时引入两个额外的损失函数来约束网络学习。
从表5 结果来看,在UCF101 数据集上,本文的STFP-Net以96.4%的正确率排在所有方法中第一位;同样的,在HMDB51 数据集上,本文的STFP-Net 以75.5%的正确率排在第一名。
综上所述,由本文提出的特征金字塔模块所构建的STFP-Net确实具有明显的效果提升。
4 结束语
本文提出了时空特征金字塔模块下的人体行为识别方法。通过分析现有基础网络的局限性,提出了时空特征金字塔模块。为了验证模块的有效性,分别从特征融合方式、金字塔层数、嵌入位置、额外计算量等方面进行实验验证。最后在通用数据集上与其他主流方法进行比较,实验结果再次证明了时空特征金字塔模块的高效性。
猜你喜欢
环球时报(2022-09-19)2022-09-19 17:19:22
四川党的建设(2022年8期)2022-04-28 21:29:35
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
作文大王·低年级(2018年10期)2018-12-06 06:22:44
童话世界(2017年11期)2017-05-17 05:28:25
故事作文·高年级(2017年2期)2017-03-01 13:03:27
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
新闻传播(2015年20期)2015-07-18 11:06:46
