
超音段语音象似性是否存在于拟声词之外?
——来自汉语方言和音义匹配实验的证据*
2022-09-14 10:37:20吴宇仑
太原师范学院学报(社会科学版) 2022年3期
吴宇仑
(清华大学 人文学院, 北京 100084)
一、引言
在过去的一百年间,已经成为语言学界共识的是,语言学理论中最重要的一个原则是任意性。语言的任意性最初被索绪尔明确提出,指的是组成语言符号的两部分——语音外壳(能指)和所指称的对象(所指)之间没有必然的联系。例如,英语中的“water”、汉语中的“水”和日语中的“mitsu”指的是同一个物体,但它们的语音形式各不相同。任意性是索绪尔语言学中最核心的概念,其他概念如约定俗成规约性、二层性、无限能产性都由任意性所决定或者受任意性影响。后来的结构主义语言学借鉴了这一概念,认为语言具有“非象似性(non-iconicity)”[1-2]。
与之相左的是,关于音义关系的另一种观点同样由来已久,那就是认为语言符号的声音形式在一定意义上模拟了它所表达的意义。这种观点可以上溯到古希腊哲学家的哲思之中,他们的证据主要来自于语言中的象声词(onomatopoeia,也称sound symbolism)。例如,“布谷”模拟了布谷鸟的叫声。在当代语言学研究中,象声词受到了认知语言学的广泛关注,已有的研究指出,象声词对外部世界的模拟存在于具体的某种语言的词汇[3]30-146、日常的言语行为[4]以及其他常见的言语活动中[5-6]。
但着眼于象声词的象似性研究也存在局限性。最为重要的一个问题是,象声词在一种语言的词汇总和中所占的比例实在太少,即使最终证明在象声词中存在任意性,也难以因此断定整个语言的词汇系统具有象似性。例如,Thompson[7]考察了现代汉语普通话中188个象声词的语音形式和意义的关系,并提出这些象声词显著地体现了象似性,但这188个象声词在汉语的整个词汇体系中所占的比例实在太小,难以因此就断定汉语整体上存在象似性。对于反对者来说事情则容易很多,他们可以简单地声称:“语言在绝大多数情况下具有任意性,除了语言中的象声词。”
正因为如此,将研究对象从象声词扩展到更多的词汇对象似性研究来说意义重大,然而目前这一方面的研究相对比较少见,只有几例对人称代词和指示代词的研究。Woodworth[8]对指示代词中存在的系统性的象似性进行了详细的考察,指出相对于表示远距离的指示代词,表示近距离的指示代词拥有更高的第二共振峰(F2)。已经有汉语语言学的研究验证了这一点[9-10],在汉语方言中,指示代词指代的距离与元音的前后、高低都有关系,具体而言,近距离指示代词多包含前高元音,例如粤语中表示“这”的“尼”,相对地,远距离指示代词多包含后低元音,例如华中地区官话中表示“那”的“兀”。人称代词方面,朱莉[11]通过对汉语方言的类型学考察,指出人称代词也具有语音象似性。
这些研究的确扩展了语音象似性的研究范围,然而美中不足的是,指示代词和人称代词仍然属于封闭词类,在一种语言的词汇总和中仍然占非常少的部分,一个呼之欲出的问题是,在开放词类(比如动词、名词等)中是否也存在语音象似性现象呢?如果这一问题的答案是肯定的,那么就更有理由说明语言系统作为一个整体,在某种程度上是具有语音象似性的。Bergen[12]指出了特定语音形式在英语名词、动词和形容词中可能具有一定的意义,例如“gl-”表示“眼界”和“光”;“sn-”表示“嘴”和“鼻子”等等。对于非印欧语系的语言,类似的研究还比较匮乏。
关于语音象似性的另一个研究“空白”是关于超音段特征的象似性研究非常罕见,目前可见的文献仅有前文提到的Thompson[7]的研究,这可能是因为研究者多出身于印欧语系语言背景,在印欧语系语言中超音段特征区别意义的作用没有那么大,因此可能受到研究者的忽视。但实际上,音调的调值和调型(在声学语音学中表现为音高的频率模式)在日常语言中经常能反映特定的认知和情感模式,例如,高调值经常与愤怒、兴奋或警惕联系起来,而低调值则经常表示伤心、恐惧或者缺乏自信。[13]
综合以上两种研究的局限性,可以得出目前语音象似性的研究情况,如表1所示:

表1 目前关于语音象似性研究的分布情况:基于词类和语音特征类型两维度
从表1中可以看出,目前针对开放词类进行的超音段语音象似性的研究非常罕见,本文力图在这一方面进行尝试性的探索,为以后更多的研究搭桥铺路。
汉语是一种典型的具有复杂声调系统的语言,不同于日语等“词调”语言,汉语的音调承载单位是“字”,即一个音节拥有一个声调。汉语的声调模式(即“调型”)简单来说有升调、降调、平调、降升调和升降调(在某些方言中),在每一种方言中又有不同的调值。汉语声调系统的复杂性实际上为调型、调值象似地模拟现实事物提供了可能。
李世中[14]创见性地将文言文中的“破音异读”现象与语音象似性联系了起来,“破音异读”指在文言文中可以通过改变声调的方式将一个音节由名词变成动词,例如平调的“衣”表示“衣服”,如果“衣”的声调变成降调,它就表示“穿衣服”的动作。这种改变一方面与屈折语中的屈折词缀有所类似,另一方面实际上反映了人类对表示事物的名词和表示动作的动词的情感态度。李世中[14]认为这种语音象似性持续到了现代汉语中,他指出带有[+质量大]的物体在生活中更易于出现跌落、下沉等向下的移动,因此多用降调编码,相反地,带有[+质量小]的物体因为在生活中更易于出现上浮、上升等向上的移动,或是维持原有的水平位置不变,因此多用升调或者平调来编码。其理论最直接的证据莫过于形容词反义词“轻”和“重”,表示质量大的“重”用降调编码,而表示质量小的“轻”用升调编码。这一研究最大的弱点是,普通话只是汉语各种方言中的一种,如何证明升调和平调对应[+质量小]而降调对应[+质量大]不仅仅只是一种偶然呢?这恐怕需要跨方言的调查来证明。另外,这种对应关系能否运用于汉语之外的语言呢?这也是一个有趣的问题。本文试图采用跨方言调查和音义匹配实验来解决这两个问题。
二、研究方法
(一)研究假设
本文的假设是声调类型和概念“轻”和“重”之间有包含理据性的必然联系。基于这一假设,本文预测:
第一,用升调或平调编码形容词“轻”,用降调编码形容词“重”在汉语所有方言中是一种非常常见的现象。
第二,在同一种汉语方言中,表示概念“轻”的语音形式在音调末尾的调值应当高于或者至少不低于表示概念“重”的语音形式。
第三,不仅仅止于汉语范围内,对任何语言而言,人类倾向于认为降调表示概念“重”而升调表示概念“轻”。
(二)跨方言调查
为了验证第一条和第二条预测,本研究采用了跨方言调查的方法。本文选取了66种能代表各个区域(北方方言、南方方言、西南方言等)以及语言谱系(官话、晋语、吴语、赣语等)的汉语方言进行调查。各个方言中“轻”和“重”的语音形式相对多样,但本研究只关注超音段特征即声调,不关注元音、辅音等音段特征。所有方言声调的数据均来自“汉字古今音资料库(xiaoxue.iis.sinica.edu.tw)”。为了便于归类比较,所有调型被归纳为两个大类:甲类,包括平调、升调、降升调;乙类,包括降调、升降调。
根据上文的预测,概念“轻”应当倾向于用甲类声调进行编码,而概念“重”应当倾向于用乙类声调进行编码。这里比较复杂的是音高两次变化的声调,即降升调和升降调,因为它们的音高变化了两次,因此很难说它们究竟模拟“向上运动”还是“向下运动”。为了便于对比,本文只考虑最后一次音高变化,因此降升调模拟“向上运动”归于甲类,升降调模拟“下降运动”归于乙类。
除了声调调型外,声调的调值同样是关注的对象,本文着重比较最后声调的调值,比如普通话阴平的调值是55,那么最后声调的调值就是5;普通话上声的调值是214,那么最后声调的调值就是4,经过比较,普通话阴平的最后声调调值高于上声,其他比较也以此类推。
(三)音义匹配实验
为了验证第三条预测,本研究同时采用了音义匹配实验的方法。实验过程与Sapir所进行的实验基本相似,在他的实验中,被试需要从一对语音的最小对立对中选择一个表示特定含义的语音形式,但在他的实验中对立的特征是音段特征,比如,在某一试次中,被试需要从“mik”和“mak”中选择表示“小”概念的语音形式,在本文所进行的试验中,最小对立对是由音段特征完全相同、超音段特征对立的两个语音形式组成的。
在本文所进行的试验中,所有出现的语音形式都是虚构的形式,只因为实验目的出现,不存在于任何的语言中。被试被告知他们进行的是一项对于巴布亚新几内亚土著语言的感知实验。在第一个试次中,被试需要从[Φiη51]和[Φiη15]中选出他们认为代表形容词“重”的形式;在第二个试次中,被试需要从[fi51]和[fi15]中选出他们认为代表形容词“轻”的形式。通过计算被试选择的比例是否具有倾向性,可以揭示声调调型与意义是否存在联系。
实验共涉及20名被试,其中8人为男性,12人为女性,母语全部为汉语普通话。他们均接受过相对良好的教育,拥有大学本科学历,但不具备语言学知识。
三、结果
(一)跨方言调查的结果
如表2所示,有一半的汉语方言中“轻”的语音形式为平调,说明平调在所调查的汉语方言中最广泛地被用于编码形容词“轻”,尽管调值在各个方言中有很大差异,从低平调11(如乐平赣语)到高平调55(如博白粤语)不等。总体来说,甲类调型比乙类调型分布更为广泛,甲类调型占所调查语言的68.1%,而乙类调型只占31.9%。表2同时说明了曲折调比较少见,降升调和升降调加起来只占12.1%。

表2 不同方言中形容词“轻”声调调型分布情况
如表3所示,有将近一半(48.5%)的汉语方言中“重”的语音形式为降调,说明降调在所调查的汉语方言中最广泛地被用于编码形容词“重”,尽管调值在各个方言中有所差异,从全降调51(如北京官话)到低降调21(如云和吴语)。表3中的数据没有表现出对甲类调型或乙类调型的倾向性,两者的频率基本持平(33:34)。如同表2一样,表3也说明曲折调比较罕见。

表3 不同方言中形容词“重”声调调型分布情况
表4将同种方言中的“轻”和“重”的调型种类结合起来进行分析,可以发现用甲类调型编码“轻”的同时用乙类调型编码“重”是在所有方言中最常见的“轻-重”调型分布模式。

表4 同一方言中“轻-重”的编码模式
甲类调型和乙类调型是本研究中为了便利而人为分类的结果,为了还原原本的同一方言中的“轻-重”声调调型编码模式,可以将甲、乙两类中的调型全部展示出来,得到的结果如表5所示。表5中纵向为“轻”的声调调型,横向为“重”的声调调型。非常直观地,在同一种方言中,用平调编码“轻”的同时用降调编码“重”是最为常见的“轻-重”编码模式,而与之相反的“重”用平调编码同时“轻”用降调编码的情况非常罕见。
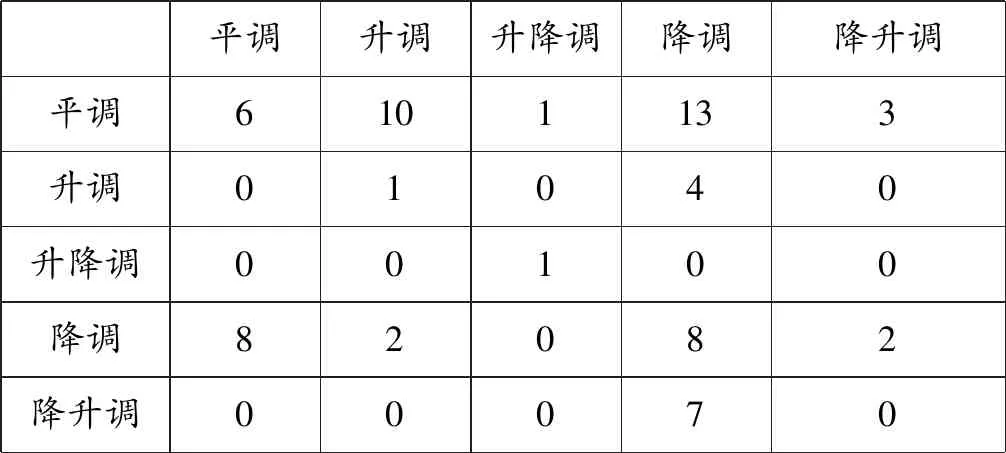
表5 同一方言中“轻-重”的编码模式(不采用甲类、乙类调型分类)
表6展示了同一方言中“轻”的声调末尾调值与“重”的声调末尾调值之间的关系。例如,在福州闽语中,“轻”的调值为44,“重”的调值为242,所以在福州闽语中“轻”的声调末尾调值大于“重”的声调末尾调值,属于表4中的“大于”。可以看到,在大多数的方言中,“轻”的声调末尾调值不低于“重”(即大于或者等于,占66个方言中的46个)。
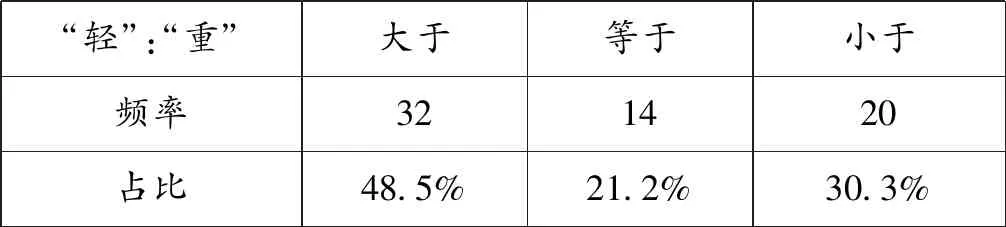
表6 不同方言中“轻”和“重”的末尾声调调值之间的关系
总结上述表2至表6,在不同的汉语方言中,说话人倾向于用升调和平调编码形容词“轻”,而倾向于用降调编码形容词“重”。一般来说,在同一种方言内部“轻”的声调末尾调值大于“重”。
(二)音义匹配实验的结果
音义匹配实验的结果如表7所示。16名被试从最小对立对中选择了声调为升调的形式与“轻”匹配,占80%,同时18名被试从最小对立对中选择了声调为降调的形式与“重”匹配,占比90%。卡方检验的结果显示,语义(“轻”或“重”)与声调调型(升调或降调)之间存在显著的相关性(p<0.001,df=1,χ2=19.798),说明被试强烈地倾向于将升调与“轻”匹配,而将“降调”与“重”匹配起来。
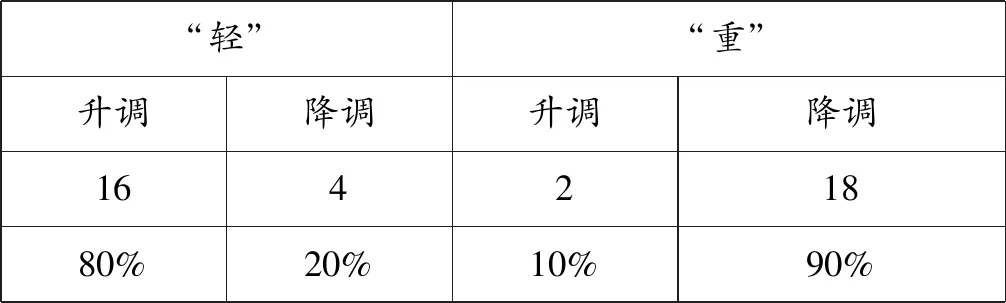
表7 音义匹配实验的结果
四、讨论
(一)“轻”和“重”的声调调型与调值有明显倾向性
根据反映中古音韵地位的重要文献《广韵》,在中古汉语中“重”用降调进行编码,而“轻”用平调进行编码,这一点与普通话所基于的北京方言非常接近。然而,并不能说因为中古音中如此编码“轻”和“重”,就能简单地预测在现代汉语各个方言中“轻”和“重”也是以相同的方式进行编码。因为,汉语中古音在各个方言中经过了不同的发展变化,不同的方言保留了不同的中古音特征,并在各自的基础上产生了不同的新变化。同一个字在当代不同方言中的发音可以说千差万别。以“是”字为例,在中古音韵中“是”的声调为上声,但在当代的不同汉语方言中“是”的声调调型千差万别,有升调(如太原晋语)、降调(如北京官话)、平调(广州粤语)等,它的调值也有不同的变化,比如温州吴语中的34、桂林平话中的23、香港客家话中的52等等。[15]4-20这个例子说明,从逻辑上来说,如果没有特殊的原因在背后推动,同一个字在不同的汉语方言中的声调调型和调值应当展现出极大的差异性。然而本文的调查结果却与这一结论有矛盾之处,根据本文所进行的跨方言调查,在同一种方言中,用降调编码“重”并用平调编码“轻”是非常普遍的现象,并且“重”的声调末尾调值不大于“轻”也是一种同样明显的倾向。这种倾向性需要一个合理的解释,而本文认为,这种倾向性的背后是人类认知活动产生的经验。
(二)对陌生语音进行的音义匹配中体现出的明显倾向性
上文所展示的实验结果用统计学的方法说明,在对一种陌生的虚构语言的音义匹配实验中,被试所作出的选择并非随机,而是有高度倾向性的。因为被试对这种陌生语言完全不可能了解,加之实验中的语音形式在音段特征上完全相同,可以得出的结论是,被试依赖于声调调型对陌生的语音形式进行意义解读,而根据被试最后作出的选择结果,可以断定被试倾向于将降调与概念“重”联系起来,同时倾向于将升调与概念“轻”联系起来。一些被试在实验后接受了访谈,以他们的话来说,他们依据一种“感觉”作出了判断,这种“感觉”是非常关键的,因为它可能代表了某种人类的认知共性。非常具有代表性的是一位被试在访谈中所说的(第6号被试,男性,22岁):
我不知道,我没有接触过类似的语言,我是说,除了中文外有声调的语言,但我觉得从声音中可以听出来哪一个是“轻”哪一个是“重”……当我听到第一组声音,我觉得第二个声音(降调的声音)听起来很重,听起来像是很重的东西掉下来,掉到地上,比如一个电视机、一个装满水的保温瓶,或者是一个大箱子掉在了地上。
该名被试在访谈中多次使用的一个词是“听起来”,这似乎能反映一种心理过程,这种过程可能是无意识的,因为该名被试仔细回忆但并不能明确指出降调和“重”的概念有象似性,但这种无意识的过程绝不是随机的,因为实验的结果有明显的倾向性,因此本文倾向于认为被试所依赖作出判断的是一种无意识的心理知识,具体来说,是一种基于认知活动的认知经验。
(三)认知语言学的观点
关于语言任意性和理据性(几乎可以等同于象似性,因为理据性认为语言符号的物质外壳是有理据的,这种理据来自于所指的物体本身,实际上这种理据就是一种“临摹”或者说“象征”的过程)的争论的起源实际上远远早于索绪尔时代,它可以上溯到古希腊时期的“克拉底鲁问题(problem of Cratylus)”,当时关于这个问题的两个回答实际上就是拥护任意性和拥护象似性,后来Simone[16]将前者总结为“亚里士多德范式(paradigm of Aristotle)”,将后者总结为“柏拉图范式(paradigm of Plato)”。回顾人类漫长的哲学史、符号学史和语言学史,亚里士多德范式毫无疑问处于主导地位[17]136,尤其是在后索绪尔时代的语言学中。
但需要明确的一点是,语言任意性并不是凭空而来的理论,它根植于西方哲学的一种思维范式中,Lakoff[18]和Johnson[19]称之为“客观主义范式(objectivist paradigm)”,这一范式有一整套的思维准则和预设,其中与任意性相关的就是“心智如同计算机的比喻(mind-as-computer metaphor)”。该范式认为,认知和心理过程运作的方式如同由抽象运算符号组成的计算机,心智通过数学运算的方式进行心理活动。这些抽象的运算符号(对应语言学来说即是词、句子以及它们的心理表征)原本是没有任何意义的,只是当这些运算符号与客观世界中的事物产生对应关系之后,它们才被赋予了意义,在这种情况下,这些抽象运算符号的意义的唯一来源就是它们与现实世界的关联,所以符号离开了物体没有意义,符号和物体之间的关系是任意的。
最近,认知语言学家提出了另一套迥然不同的思维范式,Lakoff[18]157-184和Johnson[19]56-60,226-228称之为“身体经验主义”,强调心智并非抽象的符号运算系统,而是一种基于身体经验的意象结构。在这一范式中,身体经验,即人类最初通过肉体感官感受到的经验在认知活动中起到非常重要的作用,这些身体经验被抽象为心智中的意象投射,而意象投射又通过隐喻、转喻、意象图式等方式将身体经验应用于新的认知活动之中。作为意象投射的一个重要组成,隐喻(metaphor)在认知活动中扮演着至关重要的角色。隐喻的本质是将两个具有相似性的事物联系起来,这实际上反映了人的认知过程,人对客观世界的认识就是将身体经验通过相似性与外部事物联系起来的过程。而在认知语言学中作为认知活动的一种的语言,也无时无刻不体现着隐喻关系,例如,在汉语中就存在着“意识等于距离”的隐喻,汉语中用“过来”表示意识的唤醒,比如“醒过来”,同时用“过去”表示意识的丧失,比如“昏过去”。这种在语言中存在的“隐喻性表达”不仅仅存在于词汇和语法的层面,同样也存在于语音层面,而就本文所关注的现象而言,概念“重”和“轻”的超音段特征毫无疑问也属于一种隐喻性表达,人类虽然有着不同的语言,但却享有共同的认知经验,并且有依赖认知经验对语言进行编码的倾向,在接下来的讨论中,本文将会详细说明,意象图式是如何影响到“轻”和“重”的超音段特征的。
(四)概念“轻”和“重”的意象图式
人类对于概念“轻”和“重”的经验可以由下面的意象图式来表达:
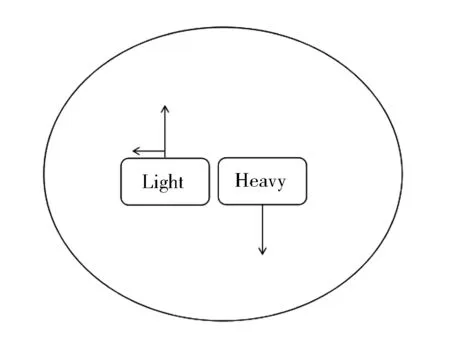
图1 概念“轻”和“重”的意象图式
图1反映了人类对轻的物体和重的物体的认知经验。假定有两个物体处于一种流体介质(比如水或者空气)中,两个物体的质量有差别,一个质量大即“重”,另一个质量小即“轻”。当这两个物体开始运动时,质量大的物体会沉下去(在水中)或者落下去(在空气中),总之会产生向下的移动,而质量小的物体会维持水平位置不变,悬浮在水或者空气中,甚至如果质量过于小的话,该物体会向上运动。两个物体经过运动之后产生的结果是,质量轻的物体的水平位置总是高于质量重的物体的水平位置。现在再回过头来看本文得出的关于“轻”和“重”声调调型和调值的分布规律:首先,“轻”倾向于用升调或者平调编码,“重”倾向于用降调编码;其次,“重”的声调末尾调值一半低于轻。非常明显,这两条规律可以与图1反映的认知经验很好地对应起来:声调的调型恰恰是对两个物体向上和向下的运动轨迹的模拟,而声调末尾调值的关系则是对运动结束后两个物体水平位置关系的模拟。
五、结论
通过对汉语方言的调查和虚拟语言的音义匹配实验可知,形容词“轻”和“重”的意义与其声调的调型和调值有明显的联系,具体而言,“轻”倾向于用升调和平调来标记,“重”倾向于用降调来标记。另外,在同一种方言中,“轻”的声调末尾调值大于“重”也是一个明显的趋势,这一结论证明了李世中[14]159-160的观点,并将他的观点从汉语普通话扩展到了汉语各种方言甚至是人类语言的共性。本文从认知语言学的角度出发,认为产生这一现象的原因在于人类的认知共性,即人类对于质量不同的物体运动产生的认知经验。
猜你喜欢
《学习方法报》语文七年级(2023年23期)2023-03-24 14:23:13
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
小学生学习指导(低年级)(2021年4期)2021-07-21 01:59:16
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
黄河之声(2019年5期)2019-12-18 12:47:03
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
儿童绘本(2017年6期)2017-04-21 23:20:41
设备管理与维修(2016年6期)2016-03-16 02:21:44
散文百家(2015年4期)2015-04-16 00:32:15
