
基于集成深度学习模型的耕地地块提取*
2022-09-14 09:14魏妍冰吴文斌
中国农业资源与区划 2022年7期
程 锐,魏妍冰,陆 苗,吴文斌
(中国农业科学院农业资源与农业区划研究所,北京 100081)
0 引言
耕地地块是农业经营管理的基本单元,具有面积大小、空间分布、物理边界和几何形态等多维特征,是衡量和表征耕地利用规模的重要指标,为农作物监测、农业生产管理和农业政策制定提供了重要的基础信息[1]。目前全世界已有多种耕地地块数据,比如美国国家农业统计局(National Agricultural Statistics Service)基于监督分类的决策树方法使用30米分辨率的Landsat影像,提供了1997—2019年覆盖全美的耕地地块数据(Cropland Data Layer)[2]。白俄罗斯的OneSoil公司基于机器学习算法使用10m分辨率的Senti‐nel2影像,提供2016—2020年覆盖全欧洲与美国的耕地地块数据One Soil Map(https://onesoil.ai/en/)。然而我国农业以小农经济为主体,耕地细碎化显著,约95%的农户耕地面积低于2 hm2,户均经营规模0.59hm2(8.8亩)[3],基于Landsat影像或Sentinel影像很难提取耕地地块。因此亟需探索基于高空间分辨率数据的耕地地块提取方法。
深度学习(Deep Learning)近年来发展迅速,卷积神经网络(Convolutional Neural Network,CNN)作为一种应用广泛的深度学习模型,能通过组合低层次特征形成更加抽象的高层次特征,从而具有强大的特征提取能力[4]。CNN利用大数据来学习特征,能够刻画数据丰富的内在信息[4]。C.Persello等利用SegNet网络、FCN(Fully Convolutional Networks)网络分别获得耕地边界的概率结果图,并将该图利用传统边缘方法(分水岭分割、全局化边界概率算子等)进行二次处理得到耕地地块[5]。Sun等利用3个具有层次性的神经网路分层次获得大地块、耕地地块与作物类别[6]。这些研究仅应用单个CNN分类器提取地块,而单个分类器各有优缺点,如表1所示。CNN的网络结构丰富且各具特点,如何选择合适的网络结构是使用者首要解决的问题;同时,由于训练样本的局限性、网络参数设计等问题,CNN易出现过拟合[4]。

表1 单个CNN方法信息
集成学习(Ensemble learning)将多个弱监督分类模型进行集成,结合各个模型的优势,得到一个强监督分类模型,其核心思想是如果某一个分类器得到了错误的预测,通过集成学习,其他分类器可以将错误纠正回来,减小偏差,提升预测效果[7]。集成学习方法比单一分类器拥有更好的预测性能,常见集成模型有Adaboost模型、随机森林模型等[8]。
针对上述深度学习的网络选择和过拟合问题,文章将深度学习和集成学习相结合,基于FCN、Seg‐Net、PspNet和Unet卷积神经网络,构建集成深度学习模型(Ensemble Deep Learning,EDL),进行耕地地块的提取。首先通过随机可放回的Bagging抽样方法在整体训练样本集中得到不同的训练样本子集,然后分别利用上述深度学习网络进行训练,预测耕地地块后验概率,最后根据预测后验概率的算术平均值获得提取结果,确定耕地地块。
1 研究区与数据概况
研究区位于黑龙江省富锦市前进镇(图1a、b),富锦市是三江平原腹地的中心城市,2018年该市的耕地总面积为61.33万hm2(920万亩),大部分耕地种植水稻,粮食总产达到21亿kg,是国家重要的商品粮生产基地[9]。选择的研究数据为Maxar Technologies公司免费提供的WorldView卫星影像,该影像的空间分辨率为0.3m,共有RGB 3波段,成像时间为2012年6月29日(图1c)。研究区的训练数据与验证数据都位于富锦市前进镇的创业农场,该地属于国营农场,耕地比较集中,以种植一年一熟的水稻为主。该文采用目视解译方法,选择深度学习所需要的训练和检验区域,其中TR1、TR2与TR3是各个CNN网络进行训练的区域,TS1、TS2与TS3是各个CNN网络进行验证的区域(图1c)。

图1 研究区域
2 研究方法
集成深度学习模型包括3个主要部分:Bagging抽样、CNN多模型训练和预测结果集成,如图2所示。实验使用了二分类的方式,即地块边界和非耕地边界。在训练时,使用Bagging筛选样本的方法随机获取数据,将总体精度作为训练的控制函数,使其各模型具有独立性,同时在更新权重时考虑了地块边界编码值的区间大小变化。该文首先建立整体样本集,在整体训练样本集中,通过Bagging随机可放回抽样得到相同数量的训练样本子集;然后使用不同的训练数据子集分别对FCN、Unet、SegNet和PspNet网络进行训练,得到各CNN的预测模型;最后基于4个预测模型得到地块边界的概率值,按取平均值的集成方式获得基于集成深度学习模型的耕地地块提取结果。

图2 集成深度学习模型流程
2.1 基于Bagging样本子集构建
首先,由于训练数据TR1、TR2、TR3像素数过大,超过了各个CNN模型所能加载的数量阈值,故将训练数据全部裁剪为270像素×270像素×3波段,一共获得300张的训练样本影像。因为卷积神经网络的训练需要大量训练样本,为提高分类准确率,防止模型过拟合,研究采用旋转、轴对称、添加噪声点等图像增强技术[10],扩大训练数据样本,共计获得了2 000张影像的样本数据库。
然后,基于2 000张影像的训练样本集,利用Bagging随机可放回抽样方法得到1 000张影像的训练样本子集。Bagging方法,又叫袋装法,具有训练样本可放回抽样的特性,是一种在机器学习中常用的数据处理算法。假设从总体样本量N中有放回的随机选取M个样本作为子样本集,每个子样本集的M个样本是有放回随机选取的,因此每个样本不被选中的概率为:

因此所有子样本集约包含原样本集总数的60.65%,其余39.35%的样本未被选中。在总体上,不同训练样本子集是相互独立的,样本子集的多样性保证了各个模型不会因为训练数据而产生偏倚[10]。
Bagging在不稳定模型集合中表现较好,能在训练数据发生微小变化时产生不同泛化行为的模型,即增加了样本的多样性,又能有效解决CNN模型训练时的过拟合问题。
2.2 参与集成的CNN模型
集成深度学习使用4个不同的CNN模型,即FCN、SegNet、PspNet和Unet,分别提取耕地地块边界的概率值图,最后进行集成。经典的CNN通常在卷积层使用全连接层得到固定长度的特征向量进行分类,Long等在2015年提出的全卷积神经网络FCN(Fully Convolutional Networks)可以接受任意尺寸的输入图像,第一次实现了基于端到端的卷积神经网络的图像语义分割[11]。FCN采用反卷积层对最后一个卷基层的特征图进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,保留了原始输入图像中的空间信息。然而FCN的最大值池化层增大感受野的同时,使得图像损失了边缘位置信息[11]。SegNet与FCN不同的地方是,SegNet采用的是vgg16全连接层前面的网络结构,并引入了更多的编码信息,使用的是池化索引(Pooling Indices),将下采样过程中池化的位置记录,在上采样中是使用该信息进行逆池化,使得每个filter都具有几个权重,可以得到在Pooling中相对Pooling filter的位置。这也使得SegNet具有更好的边缘检测的网络结构基础[12]。PspNet网络(Pyramid Scene Parsing Network)则使用了两个Loss值来评价训练精度,上采样过程采用双线性内插算法,加快了训练数据的收敛速度,保留了更多的非最大值池化的图像信息[13]。Unet分为两个部分,前半部分作用是特征提取,后半部分是进行上采样。Unet采用了完全不同的特征集成方式:拼接,即Unet采用将特征在channel维度拼接在一起,形成更厚的特征。因此Unet具有多尺度识别的特点并且非常适合于小样本的训练,但易出现过拟合[14]。
基于Bagging随机可放回抽样构建的训练样本子集,分别训练4个网络模型,得到相应的预测模型,然后进行地块概率预测。在训练CNN模型过程中,为控制实验变量,4个CNN训练参数设置为相同值,比如共同使用梯度下降法进行优化、交叉熵作为损失函数、相同的学习率与dropout等。
2.3 预测结果集成
基于4个CNN分类器的训练,得到其耕地边界相应的概率值(0~100%)。然后将4个CNN网络得到的概率值设置相同权重,并按式(2)方法获取平均值得到最后的概率结果,获得基于集成深度学习的预测影像,这部分流程如图2c。该实验数据经过集成深度学习模型,可以兼顾各个CNN模型的优势,大概率保证了即使某一个分类器出现错误,最后集成结果也是正确的,从而使得耕地地块更接近于真实的耕地空间分布情况。

式(2)中,P是指在集成深度学习模型中每个像素被分类为地块边界的概率,Pi是指在第i个CNN模型中像素为边界的概率,n为分类器的总数量。
2.4 精度评价
该文将得到的地块边界预测结果与验证区域的标签图进行对比,计算用户精度(UA,User′s Accura‐cy)、生产者精度(PA,Producer′s Accuracy)、总体精度(ACC,Overall Accuracy)、KAPPA系数以及P-R曲线。用户精度是指从分类结果中任取一个随机样本,其所具有的类型与地面实际类型相同的条件概率。生产者精度是指耕地边界类别的地面真实参考数据被正确分类的概率。

式(3)中,M是所有样本的个数,mi为在第i类中被正确分类的个数,n为总样本个数,Ρ0为总体分类精度,表示每一类正确分类的样本数量之和除以总样本数,表示对每一个随机样本,所分类的结果与检验数据类型相一致的概率。

式(4)(5)为KAPPA系数的计算过程,ai分别是每一类的真实样本个数,bi分别是每一类的预测样本个数,n代表地物类别数量,Κ就是KAPPA系数,值越高,则分类效果越好。
P-R曲线是显著性检测评价曲线,以召回率(Recall)作为横坐标轴,精确率(Precision)作为纵坐标轴,这是在机器学习中常用的二分类问题精度评价方法。当分类算对样本进行分类时,置信度表示该样本是某种类别的概率。通过置信度就可以对所有样本进行排序,再逐个阈值地选择样本,比阈值大的都属于耕地地块边界,比阈值小的都属于非耕地地块边界,形成不同阈值条件下的混淆矩阵。精确率Pre‐cision和召回率Recall从混淆矩阵中计算而来。精确率Precision能够体现地块边界分类正确的比例,即分类为地块边界的样本,分正确的概率的公式为:

式(6)中,TP(True Positive)为将地块边界预测为地块边界的数量,FP(False Positive)将非地块边界预测为地块边界的数量。召回率Recall又称查全率为:

式(7)中,FN(False Negative)表示把非地块边界正确地分类为非地块边界的数量。通过设置不同的正类概率阈值,就可得到一系列的Precision与Recall值,从而形成显著性检测评价P-R曲线。
3 结果与分析
3.1 地块边界提取
使用训练好的FCN、SegNet、PspNet、Unet和EDL从测试影像中提取耕地地块边界概率图,各个方法提取的结果如图3所示。4个CNN网络都能有效提取耕地地块,但是不同CNN具有各自的局限性。FCN能满足提取地块边界的信息特征维度要求,提取的地块边界清晰,拼接痕迹不明显,但碎斑在地块内部分布较多,预测效率也较低。SegNet的地块边界较清晰,但在预测过程中保留了多余的边缘信息,导致拼接痕迹较明显、碎斑分布较多。PspNet的地块边界清晰,虽然碎斑较少,但是碎斑的概率值较高,拼接痕迹较明显,预测效率也较低。Unet的地块边界不明显,碎斑的概率云图分布较少,拼接痕迹较轻,但由于自身的网络特性,损失较多的耕地地块的边缘信息,因此地块边界存在较多不连通的情况。EDL则综合了各个CNN的优势,能保证获取到合适、足量的特征信息,在一定程度上可以纠正分类错误的类别、降低碎斑的概率值和淡化影像切片的边缘。因此EDL提取的地块边界清晰、碎斑的概率云图分布较少、拼接痕迹较淡,总体来说EDL的提取效果最好。

图3 FCN、SegNet、Psp Net、Unet和EDL在验证区域的提取结果
使用EDL提取整个研究区的地块边界,经过拓扑错误检查以及去除碎斑后,使其与真实耕地数据进行叠加分析,获得基于EDL的耕地地块数据,如图4所示。再将其与耕地数据面积验证,耕地重叠率为96.93%,如表3所示。

图4 EDL提取研究区耕地地块流程

表3 耕地面积对比
3.2 精度评价
将验证区的地块边界概率图转为二值图之后,各方法的精度评价如表4所示。从用户精度来看,FCN的用户精度最高,PspNet用户精度最低,也侧面反映了提取FCN非地块边界的能力最好。从生产者精度来看,PspNet用户精度最低,FCN、Seg‐Net、Unet精度依次升高,EDL的生产者精度最高,这说明EDL提取地块边界的能力最好。从总体精度来看,EDL的效果最好,FCN、Unet、PsPNet的效果次之。从KAPPA系数来看,EDL的值最高,也说明了EDL的综合分类性能最好。需要注意的是PspNet的4个指标都较低,这可能是两个原因:(1)地块边界是一个二分类问题,PspNet采用了非最大值池化的方式,提取不出地块边界与地块的差异;(2)PspNet碎斑的概率云图概率值较大,这些碎斑易被归纳为地块边界。总的来说,EDL的精度存在显著提升,具有最高的生产者精度、总体精度以及KAPPA系数。精度评价结果表明集成深度学习EDL确实可以改善分类结果,提高耕地地块边界提取的准确率。
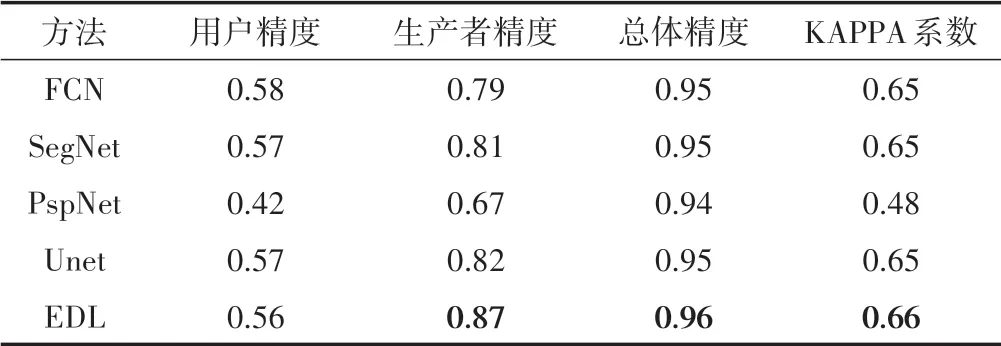
表4 各方法的精度对比
图5为各个CNN模型与集成深度学习模型的P-R曲线对比,其中X轴是代表Recall,Y轴表示Preci‐sion。平衡点(BEP)是指在P-R曲线中,“Precision=Recall”时的各个方法的取值,值越大,学习器的性能越好。EDL预测结果位于P-R曲线的最右上角,同时其BEP为最大值。集成深度学习方法的提取效果最好,Unet与SegNet表现效果几乎一致,而FCN表现更次一等,PSP网络表现最差。

图5 多方法的P-R曲线对比
4 讨论与结论
4.1 讨论
单个CNN网络各有特点,对于地块边界的分类具有偏向性。虽然从分类精度来看,各个CNN提取结果相似,但是在每个CNN模型中,对于同一地物其所得到的置信度是不同的。集成学习可以将多个CNN模型进行集成,使得集成结果兼顾各个CNN的结果特征,去除掉一部分被错分的地物。在4个CNN训练过程中,需要从同一训练库中选取样本,使用Bagging法可放回抽样的特性,保证各个训练样本子集相互独立。
该文使用集成深度学习的方法进行地块提取,从提取结果图5看,EDL的耕地边界清晰、碎斑较少。从分类精度来看,EDL的生产者精度为97%,总体精度为96%,kappa系数为0.66,均高于其余4个CNN网络。从P-R曲线看,EDL的平衡点均大于其余4个CNN网络,具有更好的提取性能。相较于单个CNN网络,利用集成深度学习在高分辨率影像中提取耕地地块,可以有效提高提取精度。
但是该文所使用的CNN为基于像素的分割网络模型,因此提取的地块边界结果存在碎片、边界不连续的情况,下一步工作将放在地块边界连通性上。此外,该文仅在东北的三江平原提取地块,但我国幅员辽阔,如何将该方法应用于我国其他地理条件不同的区域,值得进一步的探索。
4.2 结论
针对目前深度学习中存在的CNN网络选择困难以及过拟合问题,该文提出基于集成深度学习模型的耕地地块提取方法,该方法首先使用Bagging法实现样本随机抽样,然后使用4个CNN网络进行训练,得到各自的预测模型,最后通过集成学习提取到耕地地块。结果表明了集成深度学习模型相较于单个CNN网络具有更高的提取精度,实现了基于高分辨率遥感影像的地块提取,这为我国地块提取研究提供了新的方法与思路。
猜你喜欢
中国化肥信息(2022年8期)2022-12-05
今日农业(2022年13期)2022-11-10
中学生数理化·中考版(2022年6期)2022-06-05
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
今日农业(2021年14期)2021-11-25
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
小学科学(学生版)(2021年4期)2021-07-23
