
基于YOLOv5的安全帽智能检测
2022-09-09 01:41王智远赵理山朱世松芦碧波
东北电力技术 2022年8期
张 跃, 王智远,赵理山,朱世松,芦碧波
(1.华能沁北电厂,河南 济源 454650;2.河南理工大学计算机科学与技术学院,河南 焦作 454003)
电厂、建筑工地等行业从业人员众多,且危险性高,极易发生事故。工人在现场进行作业时,身边存在很多安全隐患,容易造成事故。事故发生时,头部伤害造成死亡和重伤的可能性最大,应随时对头部做好防护措施。安全帽可以承受和分散坠落物体的撞击,更能减轻人员从高处坠落头部先着地时的撞击程度,有效保护头部。因此佩戴安全帽是有效降低事故危害、保护员工生命安全的防护措施。在实际工作中,对于不按规定佩戴安全帽的行为,通常采用人工监管的方式进行管理。人工监管缺点明显:一是消耗人力;二是人工监管缺乏客观性。利用智能方法来代替传统的人工监管, 实现安全帽佩戴的自动化检测, 既节省人力成本, 又提高了现场安全性。
近年来,随着深度学习的快速发展,目标检测技术掀起新的研究热潮,为安全帽的智能化检测提供了新的研究方向。目前主流的深度学习目标检测算法主要分为双阶段检测算法和单阶段检测算法。双阶段检测算法是以R-CNN[1]系列为代表的基于候选区域的目标检测算法;单阶段检测算法是以YOLO[2]、SSD[3-7]为代表的基于回归分析的目标检测算法。前者检测精度高但速度慢,后者检测速度快但精度较低,更加适用于需要实时检测的目标识别问题。徐守坤[8]等提出了基于改进Faster R-CNN的安全帽佩戴检测研究。施辉等[9]提出了基于YOLOv3的安全帽佩戴检测方法。上述方法都是基于深度学习的目标检测算法,但Faster R-CNN存在速度慢,不能满足实时检测需求的问题。YOLOv3存在检测精度较低,对小目标识别效果较差的问题。YOLO系列最新发布的YOLOv5具有速度快、精度高、体积小等优点,采用Mosaic数据增强方式有效解决了数据集少、小目标检测精度低等问题。
本文以佩戴安全帽的人员和未佩戴安全帽的人员2类目标为检测任务,对视频数据进行预处理,构建安全帽检测数据集。使用YOLOv5算法进行数据集的训练,以获取能够满足需求的安全帽检测模型;通过试验结果表明,本文所使用的算法满足相应场景下的检测需求。
1 YOLOv5目标检测算法原理
YOLOv5是YOLO系列新一代目标检测网络,该算法在YOLOv4基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。YOLOv5算法具有4个版本,包括YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,YOLOv5s网络模型是YOLOv5这一系列中深度最小、特征图宽度最小的网络,其他3个版本均是在该版本的基础上对网络进行加深与加宽。从使网络更加轻量级的角度出发,本文选择网络深度和宽度最小的YOLOv5s模型进行训练。YOLOv5共划分为4个通用的模块,具体包括输入端、基准网络、Neck网络与Head输出端。
a.输入端主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放3部分。YOLOv5使用Mosaic数据增强操作,同时用4张图片通过随机裁剪、缩放和排布进行拼接。这种方式在小目标检测效果上更为理想,适合本文数据集中安全帽的小目标检测;在网络训练阶段,针对不同的数据集,都需要设定特定长宽的初始锚点框,YOLOv5中加入了自适应锚框计算方法,可根据数据集自适应计算出最佳的锚点框;自适应图片缩放功能自适应添加最少黑边到缩放的图像中,进一步提升了算法的推理速度。
b.基准网络采用Focus[10]结构和CSP[11]结构。Focus结构如图1所示,主要思想是通过slice操作来对输入图片进行裁剪。在YOLOv5s中,输入大小为608×608×3的图像,通过4次切片操作和1次32个卷积核的卷积操作,将原始图像变成304×304×32的特征图。YOLOv5中设计了2种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck网络中。
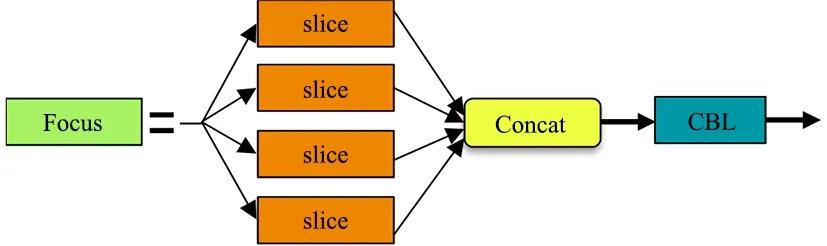
图1 Focus结构
c.Neck网络使用FPN+PAN结构,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图,FPN自顶向下将高层的特征信息通过上采样的方式进行传递融合,传达强语义特征,PAN为自底向上的特征金字塔,传达强定位特征。YOLOv4的Neck结构中,采用的都是普通的卷积操作,YOLOv5借鉴了CSPnet设计的CSP2结构,加强网络特征融合的能力。
d.输出端采用GIOU_Loss作为损失函数。在目标检测后处理过程中,针对多目标框筛选,YOLOv5采用加权NMS操作。YOLOv5s网络结构如图2所示。
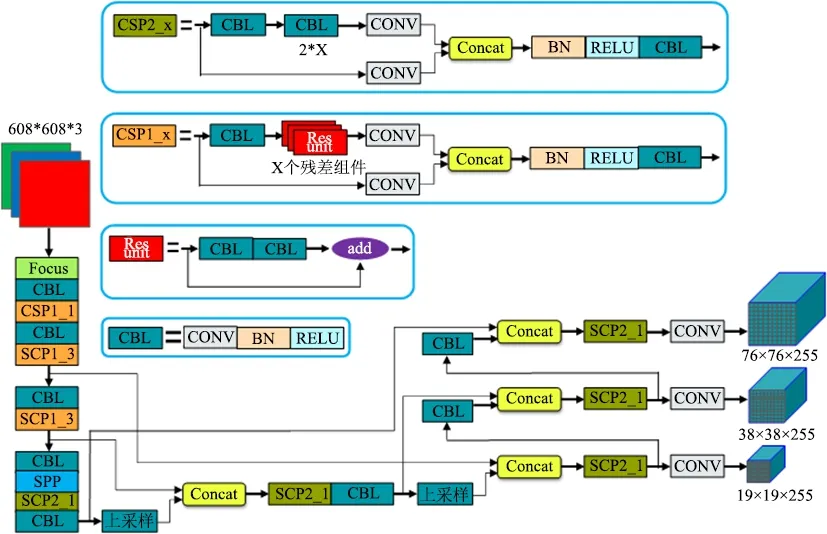
图2 YOLOv5s网络结构
2 试验结果分析
2.1 试验环境及数据集
本文试验使用Windows操作系统,在pytorch环境下运行,使用GPU硬件加速运算。试验环境配置如表1所示。
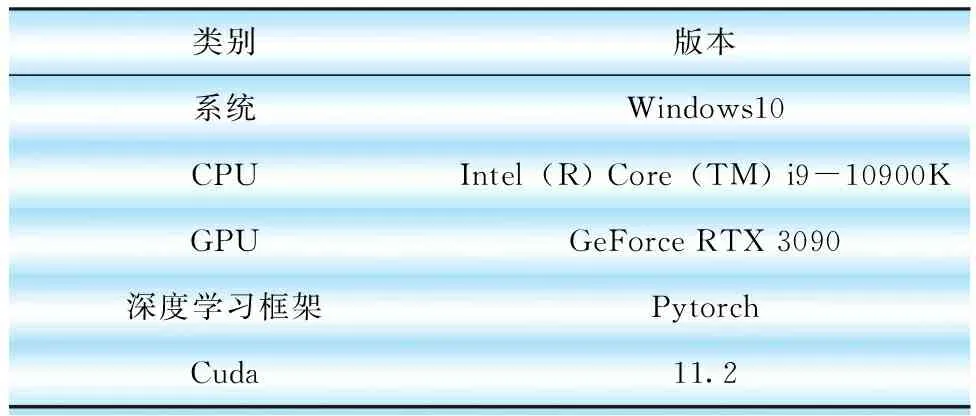
表1 试验运行环境
本文数据集所需图像均来源于自主采集,通过对监控视频进行分帧,共获得原始数据集260张。将数据集按8∶2的比例随机进行划分。由于采集数据集有限,文本对训练集进行数据增强增加训练的数据量,提高模型的泛化能力。数据增强实例如图3所示。

(a)原图;(b)裁剪+噪声+镜像+旋转;(c)裁剪+噪声+旋转;(d)裁剪+旋转图3 数据增强实例
最终得到1160张训练集,52张测试集。数据集类别为佩戴安全帽与未佩戴安全帽2种,使用labellmg工具对图像进行标注。
2.2 试验参数
本试验利用YOLOv5s模型进行网络训练,根据试验数据及运行环境,调整了相应参数。具体参数设置如表2所示。

表2 试验参数设置
2.3 试验结果
本文使用精度(Precision)、召回率(Recall)和平均精度均值(mean average precision,MAP)等常用指标来评估模型性能的优良。Recall 定义为所有目标都被模型检测到的比例,用于衡量模型的查全率。MAP为平均精度均值,是模型在多个检测类别上平均精度AP的均值,MAP的计算需要用到精度 (Precision)和召回率(Recall)2个指标。
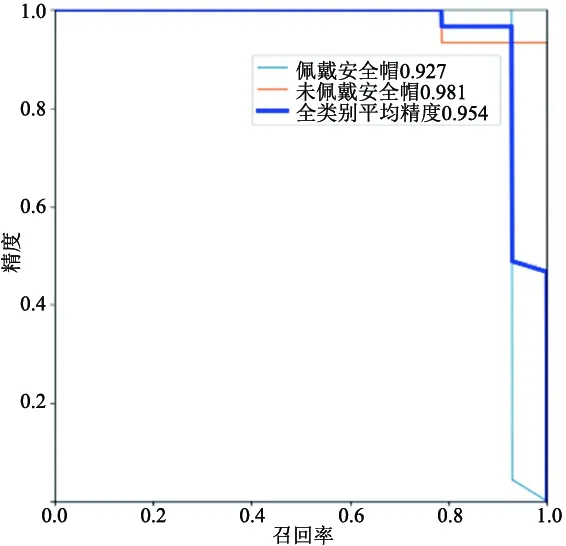
图4 阈值为0.5时的PR曲线
图4为阈值取0.5时,以recall为横坐标,precision为纵坐标制作的PR曲线,PR曲线下围成的面积即平均精度AP,所有类别AP平均值即MAP。其公式分别为

(1)
式中:P为Precision;r为Recall。
(2)
式中:C为目标检测的总类别数。
试验结果表明,佩戴安全帽人员检测平均精度为92.7%,未佩戴安全帽人员检测平均精度为98.1%,所有类别平均精度为95.4%,权重大小为13.7 Mb,检测视频fps为25,结合模型大小、平均精度和检测视频fps来看,该算法可以满足嵌入式设备或移动端对人员佩戴安全帽检测的准确性和速度要求。图5为YOLOv5s检测结果。

图5 YOLOv5s检测结果
3 结语
针对不佩戴安全帽进入施工现场的危险行为,本文提出了一种安全帽智能检测方法。以YOLOv5网络为模型,自主采集数据集并进行数据增强,以提高模型鲁棒性。试验结果表明,数据集在YOLOv5网络模型中表现出色,网络模型的平均精度达到了95.4%,检测视频fps为25,实现了在保证检测精确度的同时,对人员不佩戴安全帽的实时检测。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
课外生活·趣知识(2019年4期)2019-09-10
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
今古传奇·故事版(2017年5期)2017-04-08
职业·中旬(2009年12期)2009-06-01
阅读(中年级)(2009年11期)2009-04-14
