
基于Python的古诗文数据爬取与可视化分析
2022-09-09 03:16任夏荔
电子技术与软件工程 2022年13期
任夏荔
(山西职业技术学院 山西省太原市 030006)
1 引言
众所周知,中国传统文化博大精深,源远流长, 古诗词是中华民族传统文化重要的文化载体,并且以其独特的形态,传递给人们不同的人文内涵,从而形成了我国文化史上一道靓丽的风景线。
随着大数据技术的发展,大数据分析技术也已开始运用于行业中。那么,传统文化中的古诗词与新兴的大数据分析技术发生碰撞,会擦出怎样的火花呢?
本文利用爬虫技术和可视化技术,使用Python 语言,借助其丰富的第三方库,实现了古诗文数据的爬取和可视化,并对可视化结果进行了简要的分析。
2 关键技术
2.1 Python语言
Python 是数据科学与数据分析领域的优先选择,丰富的第三方库、开源社区、及不断优化的使用文档,为许多非计算机领域的学习者提供了广阔的入门与精通渠道。
2.2 网络爬虫
网络爬虫也被形象地称为网络蜘蛛、网络机器人,是一个可以自动下载网易的计算机程序或自动化脚本。网络爬虫就像一只蜘蛛一样在互联网上爬行,它以一个被称为种子集的URL 集合为起点,沿着URL 的丝线爬行,下载每一个URL 所指向的网页,分析页面内容,提取每个URL 并记录下每个已经爬行过的URL,如此往复,直到URL 队列为空或满足设定的终止条件为止,最终达到遍历Web 的目的。
关于网络爬虫的实现,通常有两种方式,一种是使用专门的爬虫软件,另一种则是使用编程语言。就第二种方式而言,有很多语言可以用于实现爬虫,如Python、Java、PHP、C++等。Python 中有许多可用于爬虫开发的库,包括urlib、urlib3、Requests、Scrapy、Beautiful Soup、Selenium 等。本文采用Python 语言结合Selenium 库来完成数据的爬取。
Selenium 是一个Web 应用程序的自动测试工具,支持多种浏览器,模拟人工使用浏览器的操作。
2.3 数据可视化
数据可视化分析是大数据时代的重要研究方向,“一图胜千言”,当数据以生动的可视化图表的形式展示出来时,分析人员往往能够便捷地洞察隐藏在数据背后的有效信息,并据此作出相应决策。
用于实现数据可视化的工具有很多,诸如Tableau、PowerBI、Zeppelin、Python 等。就Python 可视化而言,有许多可用于可视化的库,包括Matplotlib、PyEcharts、Plotly等。本文采用Python 语言结合PyEcharts 库来完成数据的可视化。
PyEcharts 是一个用于生成Echarts 图表的JS 类库,Echarts 是百度开源的一个数据可视化工具包。利用PyEcharts,通过编写少量代码就可方便快捷地生成Echarts风格的各种图表,是大数据时代进行数据可视化的常用方案。
3 总体设计
本文的数据来自于古诗文网(https://www.gushiwen.cn/),本文沿着爬取数据、清洗数据、存储数据、可视化数据的技术路线,技术路线图如图1 所示,着重从以下几个角度对关于思乡类的古诗文展开分析:

图1 :技术路线
(1)古诗文作者更青睐于用哪些词抒发思乡之情?
(2)关于思乡的古诗文中出现频率最高的前10 个词分别是什么?
(3)哪个朝代(或时代)的思乡类古诗文最多?
(4)各个朝代(或时代)的思乡类古诗文数量占比情况如何?
4 具体实现
4.1 爬取数据
古诗文网收录了很多诗词曲赋、经典古文,资源全面,分类详细,方便获取古诗文相关资料。通过对古诗文网的分析,发现首页的右侧设有分类栏,“思乡”也在其中,点击“思乡”会跳转到新的页面,其中以链接的形式罗列了关于思乡的古诗名,点击各古诗名即可查看到相应的诗文内容、译文、注释、创作背景、赏析等。本文使用Python 语言结合Selenium 库爬取古诗文网中收录的关于“思乡”的古诗文。具体步骤如下:
(1)使用 web=webdriver.Chrome()打开古诗文网首页,调用web.get()方法传入网址获取页面内容。
(2)调用 web.find_element().click()方法,通过XPATH定位到首页右侧的“思乡”类别,并模拟点击操作,跳转页面。
(3)利用web.switch_to.window(web.window_handles[1])方法,定位到新的窗口,即“关于思乡的古诗”页面。
(4)调用 web.find_elements()[0],通过CLASS_NAME找到所有“思乡”类古诗文链接的
标签。再调用web.find_elements(),通过TAG_NAME 获取到每个链接的标签,并将其保存在列表中。
利用网络爬虫技术验证房地产灰犀牛之说 基于Python的网络爬虫和反爬虫技术研究 基于Unity3D 的冒泡排序算法动态可视化设计及实现 猜朝代 利用爬虫技术的Geo-Gnutel la VANET流量采集 朝代谁也不服谁 朝代谁也不服谁 大数据环境下基于python的网络爬虫技术 基于Android平台的柱状图组件的设计实现 基于Excel-VBA的深水井柱状图绘制程序的设计和实现
(5)通过for 循环,依次打开每首古诗文的详细页面,在每个页面中通过4 次调用find_element()方法逐个找到古诗文的诗名、作者、朝代、古诗内容,将其存放在字典类型的变量中,即每首古诗一个存储为一个字典。
(6)将代表古诗的所有字典存放到一个列表类型的变量中,最终形成列表中嵌套字典的数据结构。
具体代码如图2 所示。

图2 :爬虫代码
4.2 清洗数据
从古诗文网中爬取的古诗文都保留了网页上呈现的格式,且包含标点符号,这对于后续的数据可视化会产生干扰,因此需要先将数据进行清洗,确保数据的纯净。如:“唐代”表示为“(唐代)”;每首诗的每行之间有换行符“ ”;古诗内容中含有“,”“。”“、”“?”等标点符号。针对以上情况,本文去除了朝代中的“()”,去掉了古诗文内容中“ ”、“,”“。”“、”“?”等符号。
4.3 存储数据
清洗后的数据,需存储下来以供后续使用。本文利用csv 库,调用csv 中的DictWriter 类,实例化一个csv 文件对象,然后用该对象调用writeheader()方法写入表头,再调用writerows()方法写入具体的数据,从而将清洗后的数据全部存储到csv 文件中。
4.4 可视化数据
经过前面的步骤,我们获取到了397 首关于思乡的古诗文,那么,古诗文作者更青睐于用哪些词抒发思乡之情?关于思乡的古诗文中出现频率最高的前10 个词是什么?哪个朝代(或时代)的思乡类古诗文最多,各个朝代(或时代)的思乡类古诗文数量占比情况又如何?
以上一连串的问题,我们很难直接从csv 文件中寻找到答案,在此,借助可视化工具,帮助我们更直观、清晰地呈现数据中隐藏的信息。本文针对上述3 个问题,分别选用词云图、柱状图、饼图进行数据的可视化。
4.4.1 词云图
词云图可以对文本中出现频率较高的“关键词”予以视觉化的展现,过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨。
本文采用词云图突出展示“古诗内容”中出现频率较高的词汇,以此回答“古诗文作者更青睐于用哪些词抒发思乡之情?”的问题。实现方法是,借助jieba 中文词库对古诗文内容进行分词处理,并使用Counter()方法统计每个词出现的次数,按次数从高到低将结果存放在一个列表里面。取出词频排名前150 的词汇及其出现的次数,使用Python 语言PyEcharts 库的WordCloud 类实例化词云图图表对象,调用add()方法填充数据并设置字号和字体,以此绘制词云图。具体代码如图3 所示。

图3 :词云图代码
运行结果如图4 所示。

图4 :词云图
4.4.2 柱状图
柱状图由一系列宽度相等、长度不一的矩形条组成,利用矩形条的高度表示数值,以此反映不同分类数据之间的差异。
本文采用柱状图呈现词频靠前的词汇出现的次数,以此回答“关于思乡的古诗文中出现频率最高的前10 个词是什么?”的问题。实现方法是,取出词频排名前10 的词汇及其出现的次数,使用Python 语言 PyEcharts 库的Bar 类实例化柱状图图表对象并依次调用add_xaxis()、add_yaxis()方法填充数据。柱状图默认垂直显示,为了使其水平显示,此处调用reversal_axis()方法,使坐标轴翻转。再调用set_series_opts()方法进行系列项的配置,通过设置label_opts 参数的值,将标签显示在柱形的右侧。从而绘制词频排名前10 的词汇的柱状图。具体代码如图5 所示。

图5 :柱状图代码
运行结果如图6 所示。

图6 :柱状图
4.4.3 饼图
饼图由若干个面积大小不一、以条形或颜色填充的扇形或圆环组成,用于表示不同分类的占比情况,主要用于表现比例、份额之类的数据。饼图通过将一个圆饼按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块表示该分类占总体的比例大小,所有区块相加的和等于100%。
本文采用饼图呈现各个朝代(或时代)诗文所占的百分比,以此回答“哪个朝代(或时代)的思乡类古诗文最多,各个朝代(或时代)的思乡类古诗文数量占比情况又如何?”的问题。实现方法是,利用jieba 库的Counter()方法统计csv 文件中“朝代”列每个词出现的次数,按次数从高到低将结果存放在一个列表里面。使用Python 语言PyEcharts 库的Pie 类实例化饼图图表对象,调用add()方法填充数据并设置饼图的内外半径以及饼图中心的坐标。接着链式调用set_global_opts()方法进行全局配置项的设置,此处设置图例的类型、位置以及布局朝向。再调用set_series_opts()方法进行系列项的配置,通过设置label_opts 参数的值,设置标签显示的样式。具体代码如图7 所示。

图7 :饼图代码
运行结果如图8 所示。
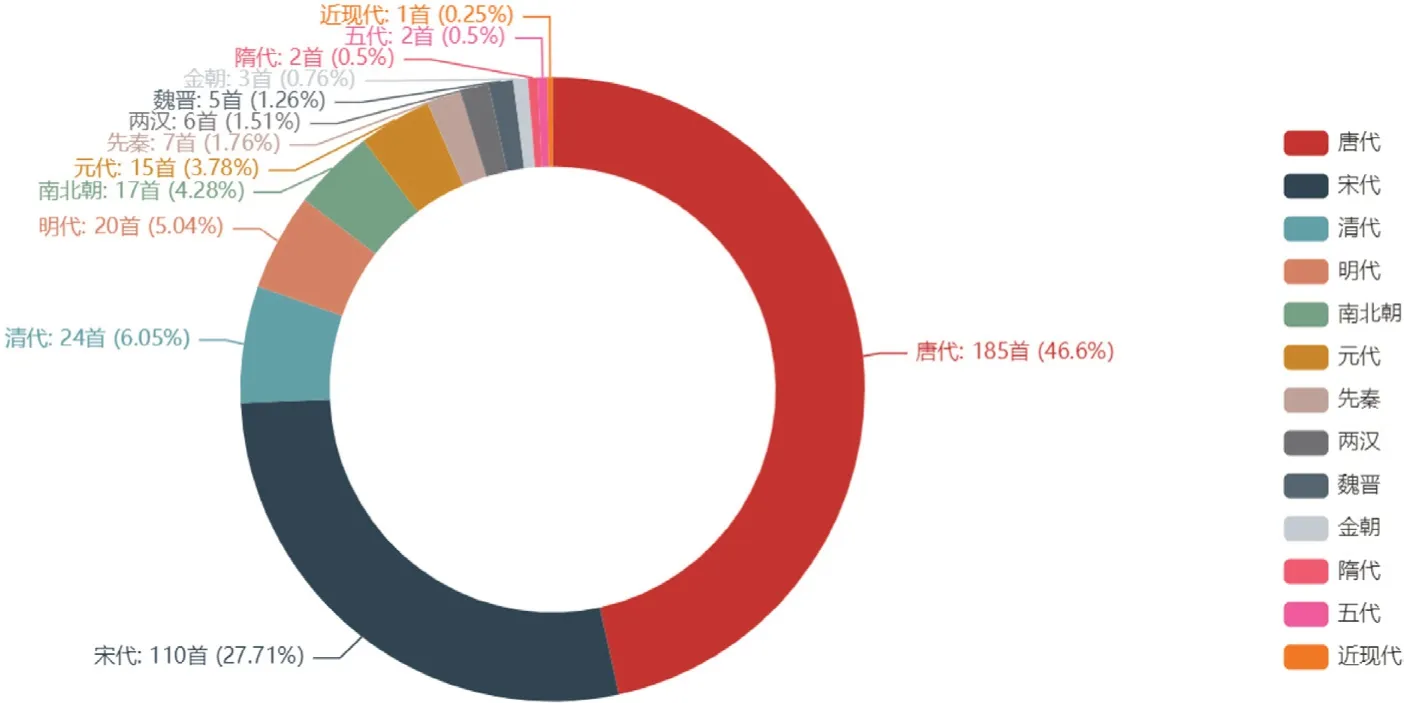
图8 :饼图
4.5 可视化结果分析
一眼扫过图4 的词云图,首先被注意到是字号相对较大的“月”、“故乡”、“归”、“万里”等,说明在所有词汇中,这些词汇出现的频率较高,也验证了古人确实更喜欢用月亮来寄托“思乡之情”。除此之外,“何处”、“梦”、“天涯”、“故园”、“望”等词汇也常在思乡类的古诗文中出现。
从图6 的柱状图可以看出,“月”这个词在获取到的397 首古诗中出现了54 次,高居榜首。其它出现频率较高的词汇还有“归”、“不”、“万里”、“故乡”等。
由图8 的饼图可知,唐代、宋代关于思乡的古诗文最多,分别达到了46.6%和27.71%,两个朝代之和超过了总数的70%,不知是唐、宋两个朝代盛产古诗呢?还是唐、宋诗人更思乡呢?
5 结束语
本文沿着“爬取数据-清洗数据-存储数据-可视化数据”的技术路线,对古诗文网中收录的关于思乡的古诗文资源进行了爬取、清洗、存储、可视化及分析。首先对古诗文网页面进行分析,采用Python 结合Selenium 库的方案爬取了古诗文网收录的关于思乡的古诗文397 首,然后使用python 语言中字符串的相关函数做了数据清洗,接着用Python 结合csv 库将清洗后的数据存储在csv 文件中,最后通过Python 的Jieba 库进行中文分词处理,用PyEcharts 库对数据可视化,绘制了词云图、柱状图、饼图,并进行了简要分析。除了本文的视角之外,对古诗文的数据分析角度还有很多,还需要进一步的探索和研究。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
喀什大学学报(2021年6期)2021-03-12
读者(2018年23期)2018-11-20
电子测试(2018年1期)2018-04-18
百家讲坛(2017年14期)2017-11-08
百家讲坛(蓝版)(2017年7期)2017-09-15
电子制作(2017年9期)2017-04-17
现代计算机(2016年16期)2016-10-18
河南水利与南水北调(2015年22期)2015-08-19
