
基于粒子群优化的支持向量机停电预测研究
2022-09-08 00:38李淑锋张玉峰王大鹏袁培森
南京理工大学学报 2022年4期
李淑锋,李 加,张玉峰,王大鹏,袁培森
(1.国网内蒙古东部电力有限公司,内蒙古 呼和浩特 010010;2.国网蒙东电力供电服务监管与支持中心,内蒙古 通辽 028000;3.南京农业大学 人工智能学院,江苏 南京 210095)
停电现象在日常生活中发生的可能性较小,但在广泛分布时会造成严重影响。它的影响几乎渗透到社会的各个方面,包括经济、社会、公共卫生和其他重要方面[1]。停电通常会造成巨大的经济损失,影响其他关键基础设施系统并严重破坏日常生活[2]。因此对停电数据进行分析很有必要。其次,由于智慧电网的建设,电网公司收集了大量的电力历史数据,给停电情况分析提供了数据条件[3,4]。预测是数据挖掘中较为常见的技术之一,停电预测可以为电网公司、政府等提前做好停电的响应规划和决策[5]。从短期看,停电预测可以帮助公共事业更好地计划其响应,从而更好地平衡成本和恢复速度。对于大规模停电事件,电网企业提前准备相应的修复材料,以便更快地恢复电力节约成本[6]。
目前,专家学者们对停电预测做了一定的研究,并且取得了一些成果。赵建军等[7]用导纳模型来描述电网的拓扑结构,然后基于导纳模型对停电的概率做出估计,并发现电网系统中的故障组件。陈颖等[8]针对极端天气下的停电问题,利用贝叶斯网络模型对历史数据分析并预测停电的概率和停电范围。于群等[9]针对停电风险的重要衡量指标损失负荷进行预测,首先用相对值方法对数据进行预处理,然后集成自回归滑动平均和反向传播神经网络对停电数据进行分析和预测。
为了提高停电预测的精度,本文采用基于线性递减权重的粒子群优化(Particle swarm optimization,PSO)[10]的支持向量机方法对停电数据进行预测。首先,为了拥有更多的有效特征,在已有的天气特征基础上通过对最大温度和最小温度作差来增加温差特征;其次,为了提取出有效的特征降低数据处理的复杂度,通过随机森林对停电数据进行特征选择;接着,使用支持向量机(Support vector machine,SVM)模型对停电数据进行预测,并且使用线性递减权重的PSO优化SVM的参数,提高预测的准确性,为电网公司的决策提供参考。方法过程如图1所示。
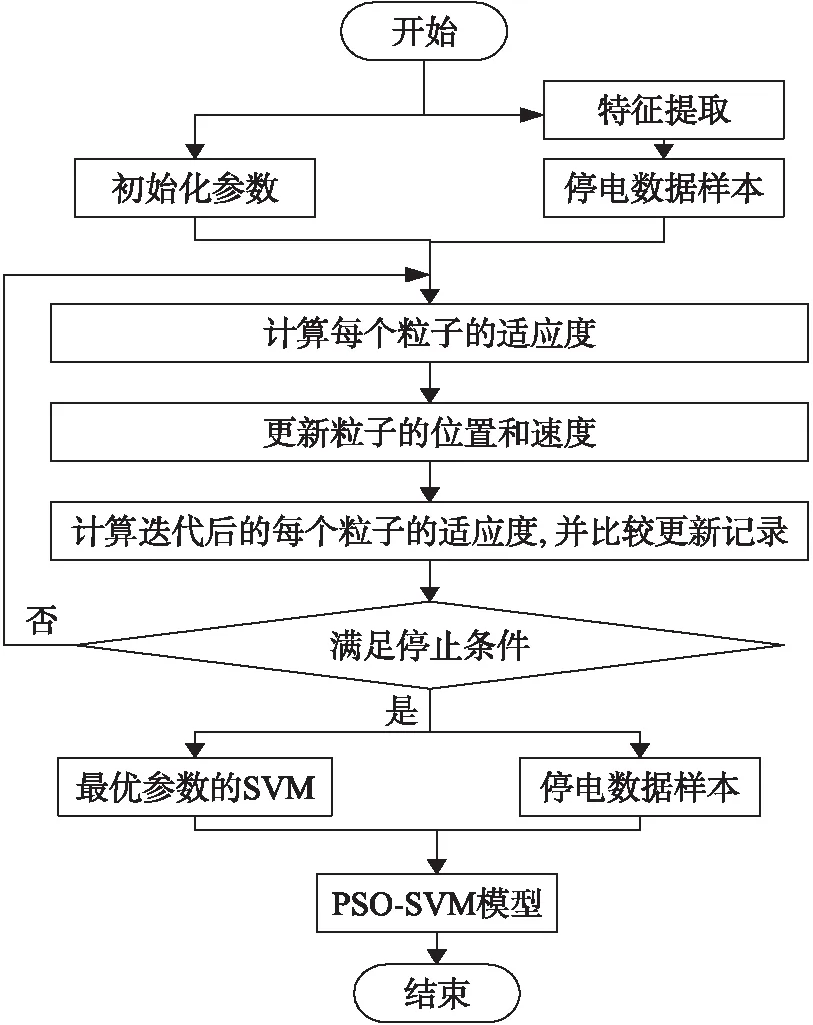
图1 方法过程图
1 特征选择
本文通过随机森林(Random forest,RF)[11]做特征选择,通过RF可以得到不同特征在多个决策树上作的贡献,通过贡献度的大小选择特征。基尼(Gini)系数或袋外数据的错误率通常用于衡量评估功能的重要性。
(1)
式中:k从1到K,共K个类别;pmk表示在节点m中类别k所占的比例。
接下来,介绍基尼指数的变化量计算。特征Xj在节点m分支前后的基尼指数的改变值如式(2)所示
(2)
式中:GIm表示特征Xj的基尼指数分数,GIl和GIr均表示分支后两个新节点的基尼指数分数值。
假如Xj出现在决策树i中的节点隶属于集合M,那么特征Xj在决策树i中的重要性的计算如式(3)所示
(3)
归一化计算的重要分数如下所示
(4)
上述公式中,C表示所有特征数。接着,对计算出的不同特征的重要性进行排序,选择对停电预测较为重要的特征去训练模型。
2 停电预测方法
2.1 SVM
SVM是Vapnik提出的一种分类技术,这一技术具有坚实的统计理论基础[12]。SVM可以将原始的数据映射到高维且线性可分的空间,扩展了线性不可分的样本数据,它是使用核函数将线性不可分转换为线性可分[13,14]。
如果问题为线性不可分割,则需要引入非线性变换。在变换后的坐标空间中,划分超平面的模型方程如下
f(x)=ωTφ(x)+b
(5)
式中:ω和b为SVM模型中的参数,φ(x)表示x的映射变换。为了使得找到的超平面到不同类别之间的距离和最大,则有
(6)
根据二次规划技术结合核函数进行求解得到超平面的方程
(7)
式中:κ(·)为核函数,κ(x,xi)表示φ(x)·φ(xi),φ(x)表示关于x的映射变换,αi表示权重系数,yi表示真实值。核函数技术是使用原来的样本数据计算变换后的空间中相似度的一种方法,可以用来帮助处理SVM中的非线性问题。常用的核函数有径向基函数、线性核函数、多项式核函数等。本文采用径向基核函数。
SVM分类模型中存在两个非常重要的参数C和γ。参数C代表惩罚因子,C的取值会影响分类器的分类精度,也可以理解为对误差的容忍限度。如果C太大,则训练阶段的分类准确率很高,而测试阶段的分类准确率很低,对于模型产生的误差具有较低的容忍程度。如果C太小,则分类准确率较差,不能令人满意,对于模型产生的误差具有较高的容忍程度,从而使得训练出来的分类模型变得无用。不恰当的C值会导致模型具有较差的泛化能力。参数γ对结果的影响相较于惩罚因子更大,γ的取值会对特征空间中的划分产生影响。如果γ的值过大会导致拟合过度,而γ的值过小会导致拟合不足,并且γ的大小会影响支持向量的多少,从而影响模型的训练速度。因此C和γ的取值对于SVM的影响很大,不同的取值会导致不同的分类性能,为了选择合适的C和γ的值,通过PSO优化SVM模型。
2.2 PSO算法
PSO算法[14]是基于种群的搜索算法。在群体中粒子的经验知识会影响相邻粒子的运动趋势。PSO算法中的任意一个粒子均为潜在的优化解,通过不断地调整自身位置找到设置条件下的相对更优解。
粒子群优化算法由改变每个粒子向其pbest和gbest位置移动的速度组成。加速度由随机项加权得到,在这些随机项中,为向pbest和gbest位置的加速度生成单独的随机数。PSO更新每个粒子的位置、速度的方式见式(8)
(8)
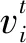
(9)
式中:w1表示初始的设置值,we表示迭代到最大的进化代时的设置值,Ik表示设置的最大的迭代次数,g表示当前迭代次数。通过LDW方法可以提高PSO的寻优性能。
2.3 粒子群优化的支持向量机
在本节中,阐述了用于停电预测的PSO-SVM算法模型。利用LDW优化的粒子群算法寻找参数的最佳值,自动求解支持向量机的模型选择问题,从而优化SVM分类器的精度。在PSO算法中,粒子在搜索空间中位置的变化是基于个体追随他人成功的社会心理倾向[15]。群中一个粒子的变化受其邻居的经验或知识的影响。因此,搜索过程使得粒子随机返回到搜索空间中先前成功的区域[16]。
为了实现本文提出的方法,将径向基核函数(Radial basis kernel function,RBF)用于支持向量机分类器。将粒子群中每个粒子的位置视为一个矢量,这个矢量编码SVM分类器的两个参数的值,分别是核参数C和γ。分类精度是设计适应度函数的一个标准。因此,对于分类精度高的粒子产生较高的适应值。同时为了更好地利用粒子群算法寻优,采用线性递减权重动态更新w的值。最终将粒子群优化的SVM模型应用于停电情况的预测。粒子群优化的SVM算法的算法描述如下:

算法1粒子群优化的SVM算法
输入:粒子的总数N,学习因子c1和c2,惯性因子w1和we,迭代次数m
输出:相对更优的SVM参数C,γ
1.j←1
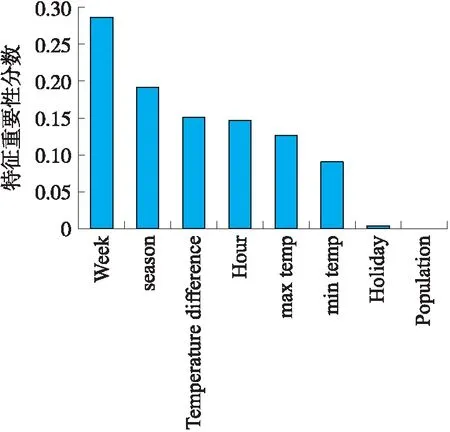
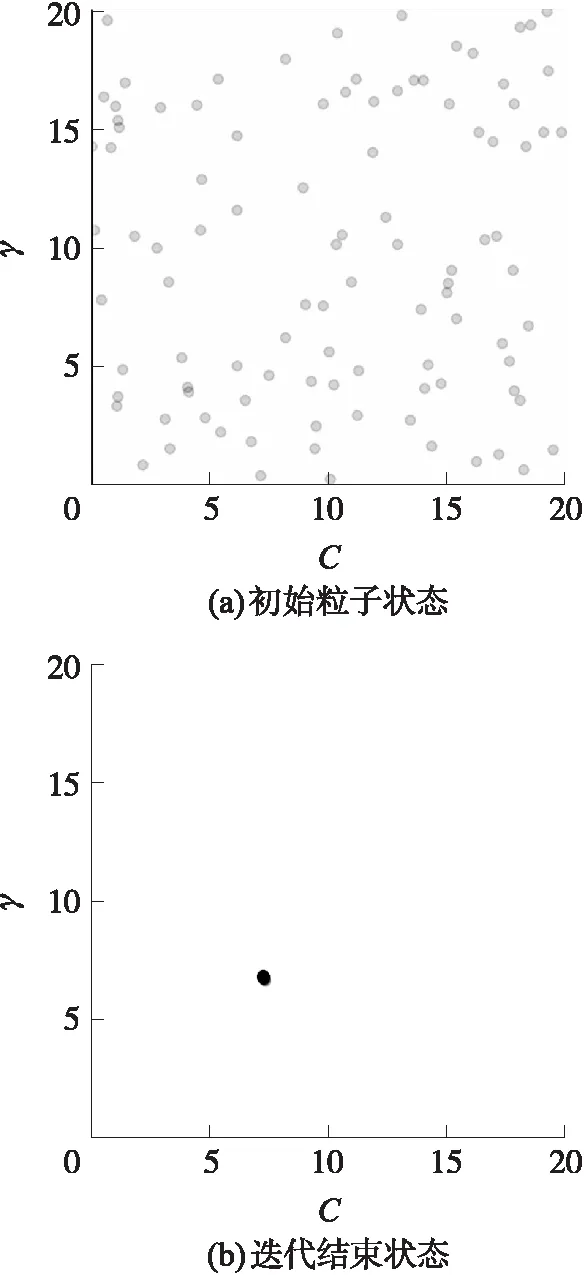
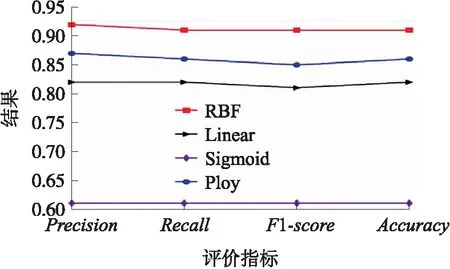
2. WHILEj 3.Intialization(vi,xi) 4.Evaluation(particlei) 5.pbesti←xi 6. END WHILE 7.gbest←max{pbesti} 8.j←1 9. FORi=1 tomDO 10. WHILEj 11.wt=Updation(w1,we,m,g) 12.vi=Updation(wi,c1,c2,pbesti,gbest,xi) 13.xi=Updation(xi,vi) 14.Evaluation(particlei) 15. IFPrediction.SVM(xi)>Prediction.SVM(pbesti) THEN 16.pbesti←xi 17. END IF 18. IFPrediction.SVM(pbesti)>Prediction.SVM(gbest) THEN 19.gbest←pbesti 20. END IF 21. END WHILE 22. END FOR 23. (C,γ)←gbest 24. RETURNC,γ 算法1是通过粒子群优化算法优化支持向量机中的参数,提高支持向量机模型的性能。首先初始化,随机生成初始的粒子,并对生成的粒子进行评估,给局部最优和全局最优的位置赋值(第1~7行)。接着,通过线性递减权重更新粒子的惯性因子值,接着更新粒子的速度和位置值,并对粒子进行评估,将不同粒子的位置对应的参数代入SVM模型中得到分类精度,根据不同参数下的分类精度更新局部最优和全局最优的位置,然后不断迭代直到满足结束条件。最后,返回搜索到的适合停电数据预测的SVM模型下的相对更优参数(第8~24行)。 本文采用的试验数据集是Bangalore的停电数据集[17],数据记录一共包括16 445条,记录了Bangalore城市的停电情况。为了更好地训练预测模型,针对已有的特征又构造出温差特征。停电数据的参数包括id、week、min temp、max temp、season、holiday、population、hour、temperature difference、outage,共计10个参数,outage为预测的目标,第2~9的参数用于特征选择。 文中采用精度,召回率,正确率,F1-score值来评估停电预测的结果[18,19]。精度(Precision)、召回率(Recall)和F1值(F1-score)的计算公式如式(10)~(13) (10) (11) (12) (13) 式中:分类正确的正例True positive表示为TP,分类错误的正例False positive表示为FP,分类错误的负例False Negative表示为FN,分类正确的负例True Negative表示为TN,如表1所示。 表1 TP,FP,FN,FP 首先利用RF算法对停电数据不同特征的重要性进行计算,然后根据计算出的不同特征的重要性进行排序,选择对停电预测较为重要的特征去训练模型,可以提高SVM模型的性能。通过图2可以看出不同特征对于停电预测的重要性,根据计算出的重要性分数,本文选取了重要性排在前6位的特征进行训练,这些特征为:week、season、temperature difference、hour、max temp、min temp。 图2 不同特征的特征分数 接着利用支持向量机去训练停电数据,并且为了提高支持向量机模型的性能利用LDW优化的粒子群算法去搜索试验数据集下支持向量机模型的相对更优参数。粒子群优化算法搜索相对更优的C和γ。C和γ的范围均设置为0~10,惯性因子w的值设置为0.5,学习因子c1和c2的值均设置为1.49,粒子总数设置为100,迭代次数设置为200。粒子群优化算法搜索过程的初始状态和迭代结束状态如图3所示。通过图3可以看出,初始状态下,PSO随机生成若干个粒子,每一个粒子代表一组C和γ值,通过不断地迭代更新最终确定相对更优的参数。在设定条件下进行10次试验,然后取平均值作为最终结果。在设定条件下的相对更优参数值C为7.20,γ为6.75,在此参数下的支持向量机模型性能相对更优。 图3 粒子群优化算法的参数搜索过程 接下来,把不同核函数下的SVM模型的精度、召回率、F1分数和正确率进行比较。对比的核函数分别为RBF、线性核函数(Linear kernel function,Linear)、多项式核函数(Poly kernel function,Poly)、Sigmoid核函数(Sigmoid kernel function,Sigmoid)。SVM模型的参数C设置为7.20,γ设置为6.75。不同核函数下的SVM的评价指标结果如图4所示。 图4 不同核函数下的SVM的评价指标的结果 从图4可以看出在4种不同核函数下,使用径向基核函数的SVM模型性能最好。此时的精度为0.92,精度表示对SVM的精确性的衡量指标,值越大,说明模型识别出正例中的真实正例的比率越高。召回率为0.91,召回率是模型识别出正例的能力评价指标,值越大,正例识别越准确。F1值为0.91,其为模型的召回率和精度的综合指标,值越大,模型效果越好。模型的正确率为0.91,正确率是对正负例子被正确分类的能力的衡量指标,值越大,模型的性能越好。 接下来,将粒子群优化的SVM模型PSO-SVM和线性回归模型、朴素贝叶斯模型、XGBoost模型[20]进行模型性能的4种评价指标的比较。PSO-SVM模型的C设置为7.20,γ设置为6.75,核函数采用RBF。不同算法模型的比较结果如图5所示。 图5 不同算法的评价指标的结果对比 从图5可以看出,文中使用的PSO-SVM模型预测性能最佳,模型的精度、召回率、F1分数和正确率均优于另外3种算法,相比较于线性回归模型、朴素贝叶斯模型、XGBoost模型,文中的停电预测模型精度分别提高了13.58%、6.98%和4.55%,召回率分别提高13.75%、4.60%和3.41%,F1值提高15.19%、5.81%和3.41%,正确率分别提高13.75%、4.60%和3.41%。因此,本文使用的算法模型对于停电数据的预测具有较好的效果。 文中针对停电预测存在的问题,提出了一种基于粒子群优化的SVM预测模型。通过LDW-PSO优化SVM模型中的参数,可以提高支持向量机模型的性能。在真实数据集上进行试验,证明了径向基核函数作为SVM的核函数性能最好,并且和其他算法比较,文中的算法模型对于停电数据的预测具有较好的效果。利用本文提出的算法处理停电数据,可以为企业的停电响应规划和决策提供参考。未来,可以根据季节、月份等因素或者利用聚类方法将停电数据分成不同类别数据集,然后针对不同类别的数据进行预测。3 试验分析
3.1 试验数据集
3.2 试验评估标准

3.3 试验细节

4 结束语
猜你喜欢
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化·高二版(2022年4期)2022-05-09中学生数理化·高二版(2022年4期)2022-05-09新高考·高一数学(2022年3期)2022-04-28电子技术与软件工程(2018年12期)2018-02-25分析化学(2018年12期)2018-01-22软件(2016年3期)2016-05-16高中生学习·高三版(2016年9期)2016-05-14新高考·高二数学(2015年11期)2015-12-23
