
彩色图像隐私部分自动标定及加密
2022-09-08 00:48:12张赛男李千目
南京理工大学学报 2022年4期
张赛男,李千目
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
互联网技术的快速发展和移动智能终端的普遍应用,使得用户在享受高效便捷的生活方式的同时,也潜在地承担着日趋严峻的个人隐私信息泄露风险[1-3],海量的图像数据蕴含着用户的隐私信息,如果不加以保护,将严重威胁到社会安全。
图像隐私保护技术,大致可以分为两大类,其一是图像处理技术占主导,如小波变换、边缘检测、高斯模糊、像素化、基于伪色等。李璐瑶等[4]应用GHM多小波变换对电子计算机断层扫描图像进行重要度分解,之后利用Canny边缘检测算法对分解图像进行信息提取。Li等[5]利用离散小波变换生成受隐私保护的低分辨率图像以及包含隐私信息的高分辨率数据。张志文等[6]、Frome等[7]、Yu等[8]、Yu等[9]利用高斯模糊或像素化等方式进行隐私保护。Ciftci等[10]、Jacob等[11]利用伪色保护图像隐私。Sengupta等[12]扭曲图像以掩盖隐私信息,Mahajan等[13]使用面部互换加以色彩平衡来保护人脸隐私信息。其二就是利用机器学习、深度学习等知识辅助实现图像隐私保护。张志文等[6]利用AdaBoost识别人脸、车牌等明显隐私信息。Kuang等[14]基于特征和对象学习自动预测隐私区域。Zhong等[15]提出随机空间归因模型进行隐私分类。Yu等[8]采用深度多任务学习识别敏感区域,并进行模糊。Peng等[16]基于卷积神经网络针对人脸关键区域进行编辑,在保护隐私同时保持较高图像质量。
不难发现,上述图像隐私保护方法大多是对图像隐私部分进行修改,比如模糊、马赛克、遮挡等。局部遮蔽方法存在的缺点是,攻击者可以根据其他未遮蔽区域的特征推测出遮蔽区域信息。在Ilia等[17]的试验中,仍有12.6%遮蔽脸部区域被用户的朋友识别出来。过滤器、泛化之类的保护方法,则很难抵挡McPherson等[18]描述的攻击方法,适用范围比较有限。孙江林[19]针对图像中的显著对象,保护的隐私范围过大,而且采用的加密算法的安全性不高。
基于上述分析,本文选择利用人脸检测,初步检测图像中的人脸重要隐私信息,并设计后处理算法更近一步确保有效覆盖隐私区域,之后采用图像加密这一手段来实现保护的目的。图像加密不同于修改图像的隐私保护手段,其一是可以还原出明文图像,其二图像加密之后的密文图像是人眼和深度学习都无法窥探隐私的。同时就本文提出的加密算法实施密钥安全分析、统计分析和扩散性分析,证明其安全性。
1 人脸检测改进的图像隐私部分自动标定
这部分介绍基于人脸检测改进的图像隐私部分自动标定算法,主要分为两步:第一步初步检测图像中的人脸重要隐私信息;第二步设计后处理算法合并隐私区域,获得最终隐私区域定位。
1.1 人脸检测Libfacedetection
Libfacedetection是一个开源的轻量级人脸检测库,由深圳大学的于仕琪老师发布在Github上,在目前开源的轻量级人脸检测库中,其在速度和精度上都具有很大的优势,因此选用其检测图像中人脸这一隐私信息。
1.2 图像隐私部分自动标定
首先,利用基于神经网络的人脸检测初步检测出图像中的人脸隐私信息。尽管人脸检测模型的精度优于同类检测模型,但是在实际应用中还是不能排除误检、漏检的情况,尤其是在图像隐私部分加密应用中,漏检情况更需重视。所以,一方面为了减少漏检的情况,覆盖到更多图像隐私区域,一方面也是为了后期进行部分加密时输入图像数据处理更加方便,设计一种合并检测区域的图像隐私部分自动标定算法。
输入:
人脸检测模型检测到的所有的矩形人脸区域的坐标为LOCfaces,LOCfaces中包含每个矩形人脸LOCface的左上坐标(fx1,fy1),右下坐标(fx2,fy2)信息,即LOCface[0]=fx1,LOCface[1]=fy1,LOCface[2]=fx2,LOCface[3]=fy2(下标从0开始)。
输出:
合并之后的所有矩形隐私区域LOCSprivacy及其总个数num,LOCSprivacy中包含每个最终矩形隐私区域LOCprivacy,每个矩形隐私区域包含左上坐标(x1,y1),右下坐标(x2,y2)信息。即LOCprivacy[0]=x1,LOCprivacy[1]=y1,LOCprivacy[2]=x2,LOCprivacy[3]=y2。合并算法如下:

合并检测区域的图像隐私部分自动标定算法
输入:LOCfaces
输出:LOCSprivacy,num
1.n=len(LOCfaces)//n为检测到的人脸总数
2.marked=
//marked为1*n的矩阵,元素初始值全为0,之后存储第i个检测区域所属连通区域标号
3.dict={}
//dict存储键值对元素,每一个键对应一个连通区域标号,键值存放该连通区域内人脸检测区域序号
4.num=0//计数连通区域个数
5.fori,LOCfaceinLOCfaces:
//遍历所有检测到的人脸区域
6.ifmarked[i]==0:
//若该人脸区域还未属于任何连通区域
7.num=num+1
8.marked[i]=num
9.dict[num]=
10.dict[num].append(i)
//从这个人脸区域开始新建一个连通区域,并将其加入进去
11.dfs(i,dict[num])
//深度搜索并连接相邻人脸检测区域进同一连通区域
12.LOCSprivacy=
//LOCSprivacy为num*4的矩阵,存储最终隐私区域坐标
13.foriin range(1,num+1):
14.a=dict[i]
15.x1=LOCfaces[a[0],0]
16.y1=LOCfaces[a[0],1]
17.x2=LOCfaces[a[0],2]
18.y2=LOCfaces[a[0],3]
19.forjina:
20.x1=min(x1,LOCfaces[j,0])
21.y1=min(y1,LOCfaces[j,1])
22.x2=max(x2,LOCfaces[j,2])
23.y2=max(y2,LOCfaces[j,3])
24.LOCSprivacy[i-1,0]=x1
25.LOCSprivacy[i-1,1]=y1
26.LOCSprivacy[i-1,2]=x2
27.LOCSprivacy[i-1,3]=y2
28.returnLOCSprivacy,num
29.//返回合并隐私区域及其个数
为了减少漏检情况,而非仅仅依赖检测模型的结果,基于局部性原理,如果此区域内检测出人脸,那么此区域周围存在人脸的可能性也较大,如果两个检测到的人脸区域距离相近,有理由相信这两个区域之间存在人脸的可能性较高,合并起来将覆盖到更多人脸。合并距离相近的人脸检测区域也可以减少最终矩形个数,方便之后加密输入处理。
本文选择将两个区域左上角的棋盘距离作为远近的度量,假设检测到的人脸区域A的左上坐标为(Ax1,Ay1),右下坐标为(Ax2,Ay2),检测到的人脸区域B的左上坐标为(Bx1,By1),右下坐标为(Bx2,By2),则他们之间的距离
D(A,B)=max(abs(Bx1-Ax1),abs(By1-Ay1)
(1)
合并(连通)条件:如果D(A,B)≤2max((Ax2-Ax1),(Ay2-Ay1),(Bx2-Bx1),(By2-By1)),就认为这两个人脸区域可以合并进同一个连通区域。
利用深度搜索的思想,遍历检测到的人脸区域,如果当前人脸区域未被合并,则
(1)新建一个连通区域,将其加入这个连通区域,标记它为已合并;
(2)遍历未标记的检测到的人脸区域:
①如果此区域与起点人脸区域距离满足合并条件,
②将其加入此连通区域,标记它为已合并,
③将此区域作为新起点,执行步骤(2)。
具体实现算法如下:
深度搜索并连接从第i个人脸检测区域出发的所有相邻人脸检测区域,将他们归属进同一连通区域
1. defdfs(i,dict[num]):
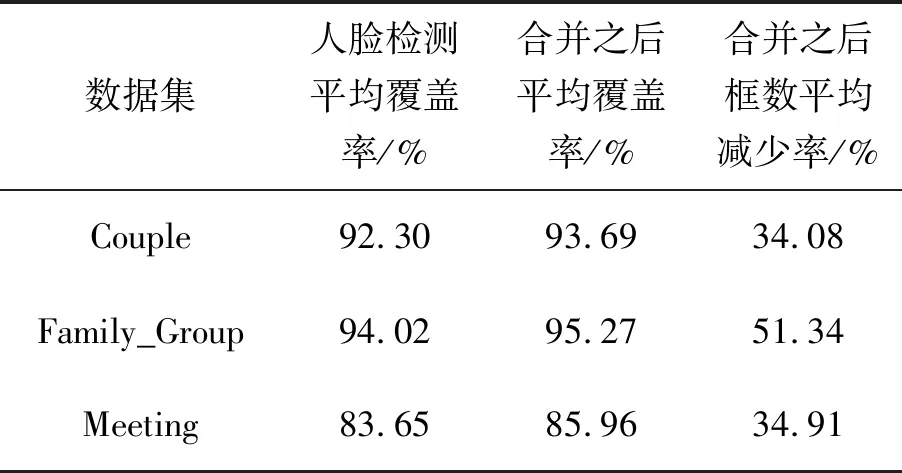
2.ifi 3.x=LOCfaces[i,0] 4.y=LOCfaces[i,1] 5.w=LOCfaces[i,2]-LOCfaces[i,0] 6.h=LOCfaces[i,3]-LOCfaces[i,1] 7.forkin range(0,n): 8.ifmarked[k]==0: 9.if max(abs(LOCfaces[k,0]-x),abs(LOCfaces[k,1]-y))<=2*max(w,h,LOCfaces[k,2]-LOCfaces[k,0],LOCfaces[k,3]-LOCfaces[k,1]): 10.dict[num].append(k) 11.marked[k]=num 12.dfs(k,dict[num]) 为了测试合并效果如何,本文选择Wider Face[20]验证集中的Couple、Family_Group和Meeting这3组数据进行试验,因为这3类数据一般较为需要进行隐私处理,且人脸尺寸由大变小,具有代表性。接着,分别进行初步人脸检测和合并人脸检测,计算初步检测出的人脸数除以需要保护的人脸数的平均值,计算合并之后覆盖需要保护的人脸数的平均值和矩形框数的平均减少率,结果如表1所示。 表1 人脸检测及合并结果 可见,优化合并之后,提升了人脸覆盖率,覆盖到更多人脸区域,同时大大减少了矩形框数,有利于之后的加密输入处理。 如图1所示,一副图像经过模型检测与优化合并,两个阶段的结果进行比照,可以看到,优化合并之后,减少了漏检的情况,覆盖到更多图像隐私区域,图像隐私区域分布较为集中,后期进行部分加密时输入图像数据处理更加方便。 图1 检测结果及合并结果 将logistic映射和sine 映射组合,级联上cosine映射,最终获得logistic-sine-cosine映射[21],如下所示 (2) 式中:r∈[0,1],x∈(0,1)。初始状态x0和控制参数r是图像加密算法的密钥,由此生成混沌序列。生成的混沌序列后续用以图像加密中的像素置乱和扩散。 logistic-sine-cosine映射的分叉图、Lyapunov指数和样本熵证明了其优良的混沌性能[21]。当r∈[0,1],x∈(0,1),logistic-sine-cosine映射的输出状态是随机分布的,其Lyapunov指数在1.374~1.386范围内。logistic-sine-cosine映射实现简单,并且能够生成具有良好随机性能的混沌序列。所以,选择其生成本文图像加密的混沌序列。 加密算法的密钥由随机生成的256位二进制数组成:4对32位的初始状态和控制参数。每32位都通过式(2)转化成小数x0、r (3) 显而易见,本文加密密钥的密钥空间是2256,足以对抗各式攻击[22]。由x0和r密钥,获得相应混沌序列,这4组混沌序列将一一作用于并影响着图像加密的4轮像素置乱、像素扩散,如图2所示。 图2 加密流程图 加密过程:在进行了隐私区域自动标定之后,针对图像隐私数据进行4轮像素置乱、像素扩散,如图2所示,得到加密数据。解密时,针对图像隐私部分进行4轮像素扩散还原、像素置乱还原,得到隐私部分解密后的图像。 整体的彩色图像隐私部分自动标定及加解密算法如图3所示。 图3 图像隐私部分标定及加解密流程图 接下来是详细的像素置乱、像素扩散算法介绍以及加密算法的安全性分析。设输入图像数组大小为(H,W,3)。 2.3.1 像素置乱 首先根据密钥初始状态x0和控制参数r生成长为H*W*3的混沌序列S,将S分成3个(H,W)的矩阵A,B,D。IA1是矩阵A每列按行排序的索引结果转置,大小为(W,H),矩阵元素∈[1,H]的整数。IA2是矩阵A每行排序的索引结果,大小为(H,W),矩阵元素∈[1,W]的整数。IB1是矩阵B每列按行排序的索引结果转置,大小为(W,H),矩阵元素∈[1,H]的整数。IB2是矩阵B每行排序的索引结果,大小为(H,W),矩阵元素∈[1,W] 的整数。ID1是矩阵D每列按行排序的索引结果转置,大小为(W,H),矩阵元素∈[1,H]的整数。ID2是矩阵D每行排序的索引结果,大小为(H,W),矩阵元素∈[1,W]的整数。将S转换为(H,W,3)的矩阵U,IU是矩阵U[i,j,:]中3个数排序的索引结果,大小为(H,W,3),矩阵元素∈[1,3]的整数(此节索引以1开始)。 置乱加密算法 输入:P(H,W,3),IA1,IA2,IB1,IB2,ID1,ID2,IS 输出:C(H,W,3) 1.fori=1:H://i从1取到H 2.forj=1:W: 3.C(i,j,1)=P(IA1(j,i),IA2(IA1(j,i),j),IU(IA1(j,i),IA2(IA1(j,i),j),1)) 4.C(i,j,2)=P(IB1(j,i),IB2(IB1(j,i),j),IU(IB1(j,i),IB2(IB1(j,i),j),2)) 5.C(i,j,3)=P(ID1(j,i),ID2(ID1(j,i),j),IU(ID1(j,i),ID2(ID1(j,i),j),3)) 6.returnC 接下来用一个实例进一步阐述置乱算法,假设这个例子是一个H=2,W=3的三通道输入数据,如图4所示。 图4 置乱前的数据 每个框内存放着一个数值(像素),数值的3位数字依次表示行、列和通道索引。这个数值作为每个框的标识数值,以此区分不同表格。在置乱过程中,只置乱框的位置,不改变框内的数值。通过这样的设计,置乱之后的数据可以显示出此置乱算法的置乱效果。此处索引从1开始。 按照上述置乱算法,推导出输出数据上位置为(1,1,:)的像素: (1,1,1)处,放入第IA1(1,1)=1行,第IA2(1,1)=3列,第IU(1,3,1)=3通道的像素。 (1,1,2)处,放入第IB1(1,1)=2行,第IB2(2,1)=2列,第IU(2,1,2)=3通道的像素。 (1,1,3)处,放入第ID1(1,1)=2行,第ID2(2,1)=1列,第IU(2,1,3)=1通道的像素。 处理完所有数据,得到图5所示置乱效果。 图5 置乱后的数据 如图4和图5所示,此像素置乱方法能够达到像素随机置乱到任意行、列、通道的效果,一一映射,置乱还原可逆。 还原算法 输入:C(H,W,3),IA1,IA2,IB1,IB2,ID1,ID2,IS 输出:P(H,W,3) 1.fori=1:H: 2.forj=1:W: 3.P(IA1(j,i),IA2(IA1(j,i),j),IU(IA1(j,i), IA2(IA1(j,i),j),1))=C(i,j,1) 4.P(IB1(j,i),IB2(IB1(j,i),j),IU(IB1(j,i), IB2(IB1(j,i),j),2))=C(i,j,2) 5.P(ID1(j,i),ID2(ID1(j,i),j),IU(ID1(j,i), ID2(ID1(j,i),j),3))=C(i,j,3) 6.returnP 2.3.2 像素扩散 在进行像素扩散时,遵循“Z”字型最大化传递像素,并将原本的扩散末尾点加至扩散起始点,使得在一轮扩散中,每个点至少影响其余一个像素点,至多扩散到所有像素点。通过4轮像素置乱、像素扩散,实现加密算法的混淆和扩散,保障图像数据安全。 先将x0和r生成的混沌序列S(总长为H*W*3)变换为大小(H,W,3)的矩阵,再把所有元素乘上232且向下取整,更新获得元素为正整数的矩阵S。 假设输入矩阵P,输出矩阵C,遵循以下规则实现像素扩散,规则中的i、j、u都是从1各自递增到H、W、3: i=1,j=1,u=1:C(i,j,u)=mod(P(i,j,u)+ P(H,W,3)+S(i,j,u),256) i=1,j=1,u>1:C(i,j,u)=mod(P(i,j,u)+ C(i,j,u-1)+S(i,j,u),256) i≠1,j=1,u=1:C(i,j,u)=mod(P(i,j,u)+ C(i-1,W,3)+S(i,j,u),256) i≠1,j=1,u>1:C(i,j,u)=mod(P(i,j,u)+ C(i,j,u-1)+S(i,j,u),256) j≠1,u=1:C(i,j,u)=mod(P(i,j,u)+ C(i,j-1,3)+S(i,j,u),256) j≠1,u>1:C(i,j,u)=mod(P(i,j,u)+ C(i,j,u-1)+S(i,j,u),256) 解密操作与加密操作逆序,i、j、u这时初始化为H、W、3,递减直至为1。解密规则和加密规则相同,区别仅在于操作符号,还原解密时需要将加号变为减号: i=1,j=1,u=1:P(i,j,u)=mod(C(i,j,u)- P(H,W,3)-S(i,j,u),256) i=1,j=1,u>1:P(i,j,u)=mod(C(i,j,u)- C(i,j,u-1)-S(i,j,u),256) i≠1,j=1,u=1:P(i,j,u)=mod(C(i,j,u)- C(i-1,W,3)-S(i,j,u),256) i≠1,j=1,u>1:P(i,j,u)=mod(C(i,j,u)- C(i,j,u-1)-S(i,j,u),256) j≠1,u=1:P(i,j,u)=mod(C(i,j,u)- C(i,j-1,3)-S(i,j,u),256) j≠1,u>1:P(i,j,u)=mod(C(i,j,u)- C(i,j,u-1)-S(i,j,u),256) 2.3.3 密钥安全性分析 本文加密算法的密钥空间为2256>2100足以对抗各式攻击[22]。更进一步地,利用比特变化率(Number of bit change rate,NBCR)检验密钥的灵敏度[23],确保密钥实际空间不低于理论密钥空间。 设彩色图像P1和P2大小一致,NBCR(P1,P2) (4) 即P1和P2所有像素的汉明距离除以图像总比特数,P1和P2的总比特数一样。 为了检验密钥灵敏度,进行256次试验。每次试验,都改变256位密钥中的一位,原密钥与改变后的密钥加密同一明文图像得密文图像C1和C2,计算NBCR(C1,C2),之后用原密钥与改变后密钥解密密文图像C1得D1和D2,计算NBCR(D1,D2)。根据256次试验得256对NBCR(C1,C2)和NBCR(D1,D2),所有的NBCR(C1,C2)和NBCR(D1,D2)都在0.5左右以不超过0.002 5的幅度振荡,说明当密钥发生极细微的改变时,加密所得的密文图像和解密所得的明文图像都大不相同,本文加密算法的密钥是很灵敏的。 2.3.4 算法统计分析和扩散性分析 最后,针对本文图像加密算法实施统计分析和扩散性分析。统计分析上主要采用直方图、相邻像素的相关性、信息熵,扩散性分析主要利用像素改变率(Number of pixels change rate,NPCR)和一致平均改变强度(Unified average changing intensity,UACI)[24]。 如图6所示,加密所得的密文图像的各通道直方图都接近完全一致分布,本文加密算法可以抵御直方图分析的攻击。 图6 明文、密文图像的三通道灰度直方图 随机选择明文、密文图像在水平(垂直、对角线)方向上相邻的2 000对像素,比较它们的相关性。结果如表2所示,Lena图三通道各方向上的相关性都接近1,而密文图像的相关性都接近0,可见加密算法可以抵抗相关性分析的攻击。 若各灰度值出现在密文图像中的概率一致,图像的信息熵等于8,这意味着此加密算法得到的密文图像是理想的随机加密图像。Lena图三通道信息熵依次为7.287 4、7.565 9、7.053 2,加密后依次为7.989 9、7.989 6、7.990 1,密文图像信息熵都在7.989之上,逼近目标值8。 选用USC-SIPI“Aerials”中的14张彩色图实施扩散性分析,其中前8张图像是256*256大小,剩余6张图像大小是512*512。对于每张图像,随机生成密钥、随机选择像素、修改像素值(加一或减一)、加密改变前后图像、计算NPCR和UACI,取10次随机测验的平均值作为最终结果填入表3。 表2 Lena原图与加密图三通道相关性对比 表3 14张彩色图的NPCR和UACI测试结果 测试图像大小是256*256时,测试通过的标准是NPCR>99.569 3%,UACI∈(33.282 4%,33.644 7%)。大小是512*512时,测试通过标准是NPCR>99.589 3%,UACI∈(33.373 0%,33.554 1%)[24]。如表2所示,所有图片所有通道的NPCR都不低于99.60%,而且UACI不低于33.43%,测验通过。可见本文加密算法扩散性良好,可以抵抗差分攻击。 表4是本文图像加密算法的平均NPCR和UACI与其他现有加密算法的比较。相比之下,本文的一致改变强度表现突出,像素改变率也不相上下。 表4 各加密算法的NPCR和UACI对比 根据上述图像隐私区域自动标定算法和图像部分加密算法处理输入图像,最终实现如图7所示的人脸检测、合并优化、加密图像。 图7 图像隐私部分自动标定及加密 将本文提出的图像隐私部分标定方法和保护手段与现有相关方案进行对比。 如表5所示,Yuan等[28]采用的加密手段:量化离散余弦变换系数符号修改,安全性不高[29],Wen等[30]将图像显著信息加密进参考图像,密文数据量大于明文。Yu等[8]、Liu等[31]的模糊手段难以抵挡McPherson等[18]描述的攻击方法。孙江林[19]采用的加密算法仅有置乱阶段,缺乏扩散阶段,安全性不高。Mahajan等[13]利用两张人脸图片,参考修改其中一个人脸的特征,修改后的人脸不仅不够自然,还保留了一些原本的面部特征,不利于隐私保护。本文的保护算法在前人研究基础之上,合并优化人脸检测区域,利用混淆和扩散性良好的加密算法,很好地保护了人脸隐私信息。 表5 本文所提算法与同类算法的对比 针对目前国内外研究的图像隐私保护存在的不足,即像素化、模糊、遮挡等保护方法的安全性随着深度学习的发展下降,而且无法实现图像的无损还原,本文提出了一种面向人脸隐私信息保护的图像部分加密算法: (1)人脸检测模型初步检测图像中的人脸信息。 (2)优化模型检测结果,减少漏检情况,合并距离相近的人脸检测区域。 (3)在进行像素置乱时,基于混沌序列设计实现了所有像素(行、列、通道)的一一映射,扩大了像素的位置置乱范围。 (4)针对加密算法的安全性进行了密钥安全性分析、统计分析和扩散性分析,充分证明了算法具有良好的混淆和扩散性。 本文提出的图像隐私区域自动标定及加密算法,针对的仅仅是人脸隐私信息,但在图像中也存在着其他类型的需要保护的隐私信息。由于是根据人脸检测深度学习模型进行初步检测,虽然已经增加了合并扩大隐私区域的后处理,但在实际应用中还是存在着一定的误检、漏检风险,有待改善。采用了人脸检测、加密等手段处理图像隐私信息,一定程度上保护了图像信息,但是面对庞大的数据量,处理速度和密钥存储机制还有待完善。1.3 合并结果分析

2 图像部分加密算法
2.1 logistic-sine-cosine映射
2.2 密钥组成

2.3 加解密算法








2.4 图像隐私部分加解密效果图

2.5 试验结果对比

3 结束语
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:17:56
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
北京电子科技学院学报(2020年2期)2020-11-20 01:44:06
动漫星空(2018年9期)2018-10-26 01:17:14
信息安全研究(2018年1期)2018-02-07 01:44:43
电信科学(2017年6期)2017-07-01 15:45:06
火控雷达技术(2016年1期)2016-02-06 02:18:04
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:20
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
