
使用Sqoop进行数据迁移
2022-09-07 12:00:38黄明辉
科教导刊·电子版 2022年20期
黄明辉
(湖北三峡职业技术学院电子信息学院,湖北 宜昌 443000)
1 概述
Sqoop是一种旨在有效地在ApacheHadoop和关系数据库等结构化数据存储之间传输大量数据的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce良好的特性保证了并行化和高容错率,而且相比 Kettle等传统ETL工具,任务运行在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景上,抽取过程会有很大的性能提升。
可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中数据转换导出(export)关系数据库管理系统,其功能如图1所示。
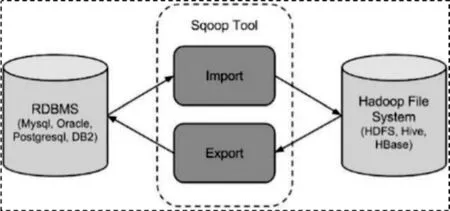
图1 Sqoop功能
(1)导入原理。
在导入数据之前,Sqoop使用JDBC检查导入的数据表,检索出表的所有列以及列的SQL数据类型,并将这些SQL类型映射为Jave数据类型,在转换后的MapReduce应用中使用这些对应的Jave类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
(2)导出原理。
在导出数据之前,Sqoop会根据数据库连接字符串来选择一个导出方法,对于大部分系统来说,Sqoop会选择JDBC。Sqoop会根据目标表的定义生成一个Jave类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
2 Sqoop安装配置
Sqoop的安装配置非常简单,前提是部署Sqoop工具的机器需要具备Jave和Hadoop的运行环境。本文是以稳定版本Sqoop-1.4.6为例。
(1)Sqoop安装。
将安装包上传至Hadoop01主点的/export/software目录中,并解压至/export/serers路径下,然后对解压包进行重命名,具体指令如下:
$tar–zxvf sqoop-1.4.6.bin_hadoop-2.0.4-alpha.tar.gz–C/export/servers/
$mv sqoop-1.4.6.bin_hadoop-2.0.4-alpha/dqoop-1.4.6
执行完上述Sqoop的下载解压后,就完成了Sqoop的安装。
(2)Sqoop配置。
先进入Sqoop解压包目录中的conf文件夹目录下,将 sqoop-env-template.sh文件复制并重命名为 sqoopenv.sh,对该文件中的如下内容进行修改。
exportHDAOOOP_COMMON_HOME=/export/servers/hadoop-2.7.4
export HDAOOOP_MAPRED_HOME=/export/servers/hadoop-2.7.4
export HIVE_HOME=/export/servers/hadoop-1.2.1-bin
在sqooop-evn.sh配置文件中,需要配置的是Sqoop运行时必环境的安装目录,Sqoop运行在Hadoop之上,因此必须指定Hadoop环境。另外在配置文件中还要根据需要自定义配置HBase、Hive和Zookeeper等环境变量。
为了后续方便Sqoop的使用和管理,可以配置Sqoop系统环境变量。使用“vi/etc/profile”指令进入profile文件,在文件底部进一步添加如下内容类配置Sqoop系统环境变量。
export SQOOP_HOME=/export/servers/sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
配置完成后直接保存退出,接着执行“source/etc/profile”指令刷新配置文件即可。
当完成前面Sqoop的相关配置后,还需要根据所操作的关系数据库添加对应的JDBC驱动包,用于数据库连接。本文将针对MySQL数据库进行迁移操作,所以需要将mysql-connector-java-5.1.23.jar包上传至 Sqoop解压包目录的lib文件夹下。
(3)Sqoop效果测试。
执行完上述 Sqoop的安装配置操作后,就可以执行Sqoop相关指令来验证Sqoop的执行效果了,具体指令如下。
$sqoop list-databases
-connect jdbc:mysql://localhost:3306
--username root–password 123456
上述指令中,sqooplist-databases用于输出连接本地的MySQL数据库中的所有数据库名,如果正确返回指定地址的MySQL数据库信息,那么说明Sqoop配置完成。
3 使用Sqoop将数据从MySQL导入HDFS
(1)数据准备。
在MySQL中有一个表student,表的数据如下表:

表1 student数据表
确定HDFS、MySQL已启动。
cd/usr/local/hadoop
./sbin/start-dfs.sh
Service mysql restart
mysql-u roop-p
(2)在MySQL中新建一张表并插入一些数据。
use mysql;
create table student(
sid char(10)primary key,
sname char(10)not null,
sex varchar(10)null,
birthday date null,
class char(16)null,
dep varchar(20)null
);
insert into student values(10001,'gopal','male','2002-06-02','1','computer');
insertintostudentvalues(10002,'andy','male','2002-01-05','2','electromechanical');
insert into student values(10003,'lily','female','2001-05-06','3','computer');
导入表的所有数据至HDFS
./bin/sqoop import
--connect jdbc:mysql://localhost:3306/mysql
--username root
--password'hadoop'
--table student
-m l
--fields-terminated-by' '
检查导入结果
通过hdfs命令检查导入结果:
hdfs dfs-cat/user/hadoop/student/part-m-00000
10001,gopal,male
10002,andy,male
10003,lily,female
4 作用Sqoop将数据从HDFS导出MySQL
在导出前需要先创建待导出的表的结构,如果导出的表在数据库中不存在会报错;如果重复导出表,表中的数据也会重复出现。
(1)在MySQL下创建表。
create table student_demo(
sid char(10)primary key,
sname char(10)not null,
sex varchar(10)null,
birthday date null,
class char(16)null,
dep varchar(20)null
);
(2)指定分隔符导出表的所有列。
./bin/sqoop export
--connect jdbc:mysql://localhost:3306/mysql
--username root
--password'hadoop'
--table student_demo
--fields-terminated-by' '
--lines-terminated-by' '
--export-dir path/user/hadoop/student
-m l
在MySQL Shell界面输入select*from student_demo查看导出表的数据,如图1所示。
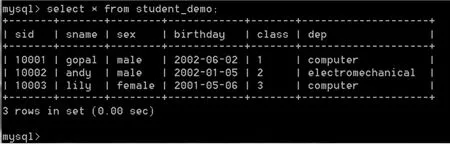
图1
说明:每执行一次,数据都会插入MySQL中,所以在执行之前根据需要将表中的数据删除后再导入。
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:51:30
电脑爱好者(2022年12期)2022-05-30 10:48:04
电脑爱好者(2020年10期)2020-07-28 17:10:30
网络安全和信息化(2019年4期)2019-12-23 09:39:34
电脑爱好者(2019年20期)2019-12-10 06:30:31
电脑爱好者(2019年16期)2019-10-30 03:35:12
网络安全和信息化(2018年5期)2018-11-09 02:02:26
青岛科技大学学报(社会科学版)(2015年4期)2016-01-25 09:57:38
青岛科技大学学报(社会科学版)(2015年4期)2016-01-25 09:57:38
河北大学学报(自然科学版)(2015年1期)2015-02-27 13:06:13
