
基于记忆网络的视频着色方法
2022-09-05 13:30李赟红孙泽龙邵峰晶孙仁诚
青岛大学学报(自然科学版) 2022年3期
李赟红孙泽龙邵峰晶孙仁诚
(青岛大学计算机科学技术学院,青岛 266071)
利用黑白视频上色处理技术,可以对早期的黑白影像色彩化处理,使人们更好的了解当年的真实情况,黑白影像的彩色化也能为视觉理解和对象跟踪等计算机视觉应用提供辅助支撑。随着卷积神经网络(CNN)在计算机视觉领域的发展,出现许多图像、视频处理技术,如,图像超分辨率[1],图像修复[2],图像着色[3-4],视频着色等。视频上色时,可以通过图像增强算法处理生成的视频帧而实现,但该方法并没有解决相邻帧的颜色传播问题,帧与帧之间颜色跳变明显[5]。此后出现一种多样性的视频上色方法,可生成多个不同颜色的视频,并人工挑选出最终结果,但训练过程中,模型往往只学习主流颜色,当待上色视频与训练集中的主流颜色差异很大时,导致上色后视频严重失真[6]。基于传播的视频上色方法通过深度神经网络学习从给定的参考帧中复制颜色,用参考帧来指导灰度视频着色,这些方法对于和参考帧场景相同的上色质量较好,若后续帧与参考帧颜色差异很大,视频上色质量会迅速下降,并且如果颜色在特定帧上传播失败,后续传播都会出现问题[7-8]。随着记忆模块[9]的提出,人们将其与深度学习模型相结合来解决实际应用问题。Yoo等[10]首次将记忆模块应用于图像着色任务中,实现罕见动画的彩色化,但该方法无法解决相邻帧的颜色传播问题以及多场景转换问题。
1 视频着色方法
视频着色时首先分解输入的视频,然后对分解后的帧着色处理,最后合成视频。如果视频中有语音,则再合入语音信息。本文的着色网络采用生成对抗网络[11-12],该网络着色成功的关键在于其对抗性损失,即判别器区分真实图像和假图像,而生成器生成更逼真的假图像来欺骗判别器。但若将其单独应用到视频着色任务中,则无法解决相邻帧的颜色跳变问题。因此,本文借鉴了文献[10]的图像着色思想,将记忆模块与生成对抗网络相结合,提出了基于记忆网络的视频着色方法。一方面利用记忆网络的存储以及可提取优势,针对视频中不同的场景,提取不同参考特征指导上色,鉴于同一场景参考特征的唯一性,保证了相邻帧的色彩连续性,解决了相邻帧的颜色跳变问题。另一方面利用生成对抗网络的对抗性损失优势,生成与真实图像难以区分的彩色图像。
如图1所示,该方法由两个网络组成:记忆网络和着色网络。在训练过程中,记忆网络学习存储训练集中彩色图像的颜色特征、空间特征等,着色网络学习如何有效地将颜色特征注入灰度视频帧中。在测试过程中,从记忆网络中检索与输入视频帧最接近的颜色特征,将其作为参考特征注入到着色网络中,以确保相邻视频帧的颜色一致性。为了应对多变的场景,本文增加了场景检测功能,当检测到场景变化时切换参考特征。着色过程如图2所示。

图1 视频着色方法训练过程
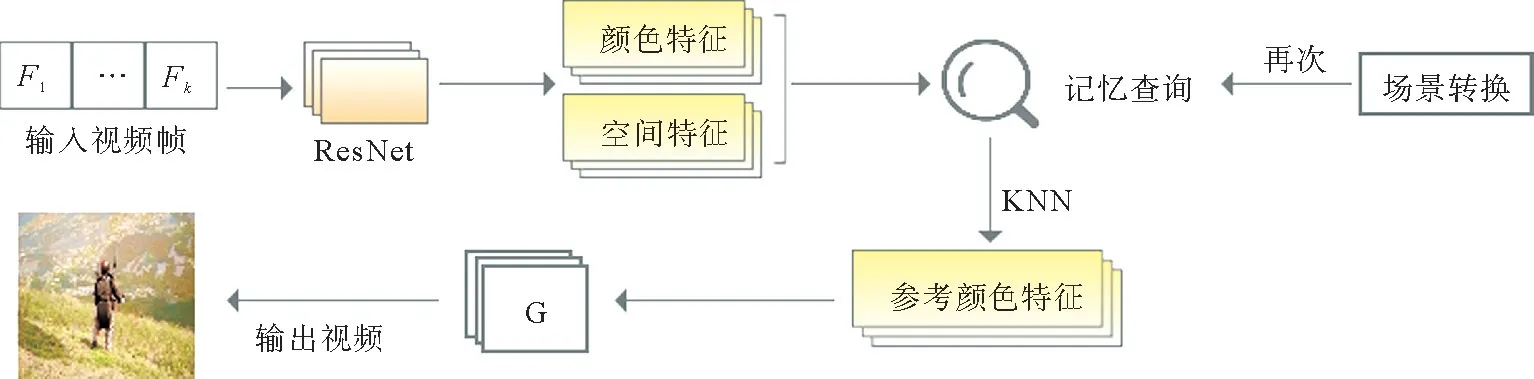
图2 视频着色过程
1.1 记忆网络
本文的记忆网络借鉴了记忆模块[9]的一些机制,结构用二元组表示

其中,K∈Rn×m表示键矩阵,n是记忆模块大小,m是维数。K提取于训练集中,训练过程中用于存储输入图像的空间信息,着色过程中用于计算参考样本与输入视频帧的相似性。V表示值向量,提取于训练集中,用于存储训练图像的参考特征,这是后期视频着色的必备条件。实验中,将输入视频帧统一转化成Lab颜色空间的值信息,然后存储,这种转化使模型更适用于具有不同颜色和复杂绘图的图像。
1.1.1 参考特征提取 参考特征,即训练集中彩色图像的颜色信息。在训练过程中,参考特征主要通过记忆网络的V向量进行存储,在着色过程中通过记忆网络的记忆查询功能查找与输入视频帧最匹配的参考特征,利用该参考特征指导灰度视频帧的着色。
记忆网络中的记忆查询用向量q表示,查询时,首先将视频帧X i输入预训练好的残差网络Res-Net101,以总结视频帧的空间信息。鉴于ResNet本身参数少、训练效率高以及在特征提取方面应用广泛等优势,选择在查询q之前先通过其池化层提取一个特征,将提取到的特征通过全连接层的线性函数进行处理,最后,进行正则化处理以构建查询向量q,q的大小同键矩阵K维度相同


并返回最近的值,即参考颜色,该值是着色网络着色的必备条件。
1.1.2 记忆损失 记忆网络的损失函数是决定记忆网络好坏的关键因素。2015年,Schroff等[13]首次提出三重损失函数,并应用在人脸识别系统中,通过嵌入该损失函数,系统人脸识别的准确率显著提高。三重损失函数对处理一些差异性较小的样本效果显著,前提是需要引入类标签,是有监督的训练。
记忆网络的损失函数借鉴了三重损失的方法,不同的是视频上色任务是无监督性质的,无标签的,因此,引入了超参数β作为阈值,只需要阈值化输入帧与查询q之间的距离即可。假设两个图像具有极大的空间相似性,那么图像的颜色特征之间的距离一定在β内,相反则距离大于β。计算k个最近邻(n1,n2,n3,…,n k-1,n k),假设图像i与输入帧是同一类别,n i为正邻居,则输入帧与查询q的颜色特征之间的距离,即KL差异在阈值β内

其中,V ni为查询图像的颜色特征,v为预期值。同理,假设图像j与输入帧非同一类别,即n j为负邻居,则输入帧与查询q的颜色特征之间的距离,即KL差异大于颜色阈值β

最终,记忆损失定义为

即最大化查询q与正样本的相似性,同时最小化查询q与负样本的相似性,α为常数。
1.2 着色子网
相比于基于CNN 的图像上色,GAN 的对抗性损失是可以自动学习的损失函数,从而减轻了人为设计损失函数的负担,有条件的生成对抗网络可以生成更为多样化的着色效果,因此本文利用其在图像生成方面的优势,将其作为着色子网。若将色彩视为一种风格,那么对于图像着色,亦可以看作是一种样式的迁移,即将彩色颜色特征转移到灰度图像中。因此,在本文着色网络中,使用了AdaIN 来实现将参考图像的特征转移到到灰度视频帧中,强化了视频帧的着色效果。
1.2.1 目标函数 训练期间生成器G 主要负责捕获图像的数据分布,判别器D 主要负责判断输入的图像是生成的还是真实的。训练过程中,模型不断优化,即生成器生成图像来欺骗判别器,然后判别器检测这张图片的真实性,整个网络不断进行生成器和判别器的对抗训练和迭代过程。随着迭代次数的增加,生成器和判别器各自的能力不断增强,模型最终达到稳态。测试期间,将视频帧和记忆查询的颜色特征C输入给生成器,以生成更为逼真的彩色视频帧G(F x,C)来欺骗判别器,判别器则试图通过输入的视频帧和F x记忆查询的颜色特征C来区分真实的图像。判别器的目标函数

即判别器尽可能的区分出生成的视频帧和参考帧。
生成器目标函数
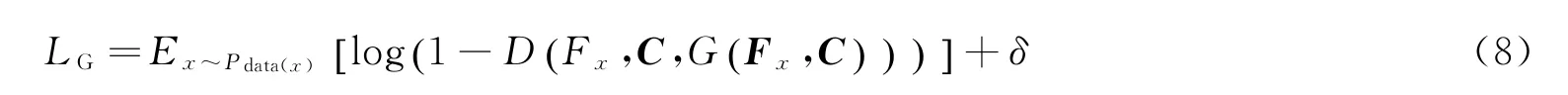
即生成器生成的样本被判别器尽可能的判别为真。
1.2.2 场景检测 针对长视频,当前后帧为不同场景时,若还采用同一参考特征,则生成的结果会脱离实际。因此,为了应对多变的场景,增加了对前后帧F1,F2的处理。引入阈值超参数a,模型在上色过程会检测相邻帧的颜色分布,若在该阈值内,则该相邻帧为同一场景,否则切换场景

当检测到切换场景以后,重新从记忆网中检索与视频帧最接近的颜色特征,指导后续帧上色,以解决多场景的视频上色问题。
2 实验
2.1 数据处理
训练过程中,记忆网络存储训练集中图像的颜色特征和空间特征等信息,着色网络从记忆网中寻找参考特征来指导整个视频上色,因此应尽可能保证训练集中图像场景的多样化。实验中并没有采用视频集作为训练集,因为视频集相对较大,与同规模图片集相比,视频集涵盖的场景更少。实验数据集来源于ImageNet数据集,测试集从Videvo视频集以及DAVIS数据集中挑选不同场景以及清晰度较高的部分视频,实验中包含100多个视频,每个视频帧数不等。
2.2 消融实验
为了测试记忆模块在整个上色过程中的重要作用,本文对比了全模型与消融模型视频上色的效果,如图3。虽然两种方式都具有较为优秀的着色效果,但是从连续帧数来看,有记忆网的效果明显比无记忆网的更稳定,无记忆网的生成的视频帧存在某几帧同其他帧颜色差别显著的现象。而全模型的方法可以缓解相邻帧之间的颜色跳变问题,有效的保证了视频的帧与帧之间的时间一致性。

图3 消融实验
为验证实验结果的可靠性,本文进行了用户感知评价。取20个视频对,每个视频对包含有记忆网和无记忆网各自生成的视频,视频顺序随机,让10位参与者分别观看这20组视频,并挑选出各组内质量最好的视频,统计结果见表1。其中的16组视频,用户一致认为全模型生成的视频无论是在流畅性还是颜色上效果更好,但是其中4组存在争议,用户认为无记忆网生成的视频色彩更鲜亮。

表1 消融实验用户感知评价结果(%)
2.3 实验对比
为使实验结果更具说服力,在上色质量方面,将本文方法与最近较为流行的全自动图像着色方法进行比较。实验中,首先采用文献[3]、文献[4]的方法对视频帧上色,然后再应用文献[5]的盲视频时间一致性方法来提升着色视频的颜色一致性。如图4,对比了本文方法和文献[3]、文献[4]方法生成的彩色视频中的几个彩色帧。

图4 与全自图像着色方法对比
对比本文方法与文献[6]的全自动视频着色方法,文献[6]的方法虽然可以生成多个不同颜色的视频,但是容易受训练集中主流色彩的影响,导致某些视频上色后跟原视频风格差异很大。如图5,本文生成的视频色彩更加真实,文献[6]生成的视频颜色由黄色主导。

图5 与全自动视频着色方法对比
为了更好评价生成视频颜色的真实感,将本文的方法与基线方法进行对比,结果见表2。实验中随机选取Videvo视频集生成的20个视频。每组包含各个方法生成的视频,顺序随机,参与者可反复观看,并在评价表中填写闪烁较少、色彩更真实、总体效果更优的视频的编号。共有10位用户参与评价,可知,本文的方法无论是在总体效果上还是其他评价方面都优于基线方法。

表2 对比实验用户评价结果(%)
3 结论
本文结合深度学习和视频处理技术实现了自动视频上色。拥有记忆网络的着色方法在视频着色任务中效果较好,缓解了视频上色存在的闪烁问题,使生成的视频色彩更真实,并且支持多场景检测。但是该方法也存在局限性,针对场景多变的视频,检测方式比较单一,对于一些微弱场景变化可能识别为切换场景,所以下一步研究重点是优化场景检测功能。
猜你喜欢
今日农业(2021年9期)2021-11-26
今日农业(2020年16期)2020-12-14
电影(2018年10期)2018-10-26
新湘评论·下半月(2016年4期)2016-05-05
新湘评论·下半月(2016年4期)2016-05-05
海外文摘(2016年4期)2016-04-15
少儿科学周刊·儿童版(2015年11期)2015-12-17
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
