
王者荣耀游戏实时胜率预测*
2022-09-05 12:24蓝雯飞
网络安全与数据管理 2022年8期
田 鹏,蓝雯飞,张 潇
(中南民族大学 计算机科学学院,湖北 武汉 430074)
0 引言
王者荣耀游戏是一款当前广受欢迎的手机游戏之一,作为一款可玩性很强的竞技类游戏,游戏的胜负成为了玩家和观众最关心的问题。由于游戏的复杂性、部分可观察性和对局动态实时变化等特点,仅仅依靠人工来解说比赛已经不能满足需求,还需要实时的胜率预测为其提供话题引导和需求。胜率预测能够为解说提供有力依据,增强观众的参与感,还可以用于赛后复盘,提升竞技实力。
人工智能(AI)解说员越来越多地出现在比赛直播中,AI会根据双方所获得的资源预测出整场比赛的胜率趋势,如肯德基KI上校、DOTA PLUS胜率预测面板,已经在LOL和DOTA玩家中取得了良好的反馈。
实时战略游戏(RTS)在过去十年中一直是人工智能研究领域的一个热点,游戏AI是其中的重要研究方向。文献[1]-[3]提出了一种多人在线战术竞技游戏(Multiplayer Online Battle Arena,MOBA)AI学习范式,让其能够自主地训练和扮演大量英雄,并且构建能够击败顶级电子竞技玩家的超人AI代理。胜率预测也取得了大量研究成果,如文献[4]、[5]使用神经网络以及Naivebayes分类器,通过分析阵容来预测胜率,但准确率都不是很高,而且只能在赛前进行预测,具有比较大的缺陷。此外,通过分析比赛数据来进行胜率预测也是一种可行方法,如文献[6]-[8]参考了玩家和角色的历史表现,使用了更丰富的数据特征来进行预测,但运用的模型较少参考性不强。文献[9]中增加实时输入特征和高质量的训练集,提出了一种两阶段时空网络(TSSTN),不仅可以提供准确的实时胜方预测,而且可以将最终的预测结果归因于不同特征。文献[10]提出了用赛后数据和阵容两种方法对整局游戏胜负作出预测,但不是实时胜率;文献[11]将阵容和比赛时的特征相结合,运用逻辑回归模型进行胜率预测,得到的准确率为71%,效果比较一般。
关于实时预测的现有研究仍然存在局限性,现有工作很大程度上忽视了可解释性,预测的准确性很难令人满意。为了解决上述问题,本文考虑同时使用阵容数据和对局数据来进行胜率预测。为了使阵容数据具有实时性,本文采用关系模型提取不同时间节点时英雄之间的克制协同关系,并采用序列LSTM模型来进行胜率预测。为了缓解黑盒模型的不可解释性,本文决定对于实时数据解耦,分离特征值和重要性的影响。提出了时空网络概念,在空间阶段将最重要的三个特征分开进行单特征预测,并在时间阶段为空间阶段产生的结果向量添加时间权重向量,最终通过加权组合得到预测结果。最后,本文将两个模型进行联合,提出了一种高准确率且具有可解释性的角色-实时联合网络。
本文利用收集的真实对战数据集,使用角色-实时联合网络进行预测,并对预测结果进行解释,具体预测流程如图1所示。实验结果表明,AI解说员可以在解说词中给出较为准确的胜率预测与分析,大大增强游戏观看者的体验。同时,本方法对于其他类似的电子竞技游戏具有相同的实用价值。
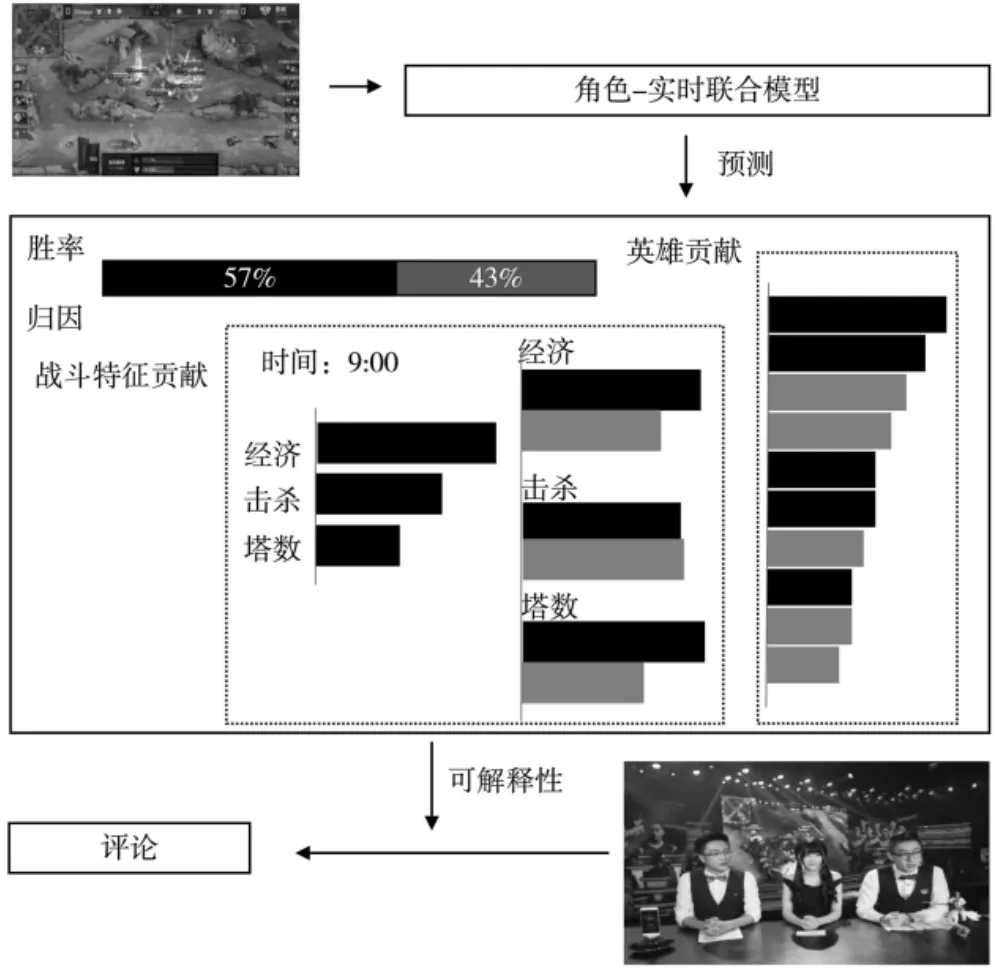
图1 王者荣耀可解释性胜率预测流程图
1 王者荣耀游戏数据集
在王者荣耀中,两支由五名英雄组成的队伍互相战斗,直至推掉对方主水晶才算获得胜利。通过与王者荣耀发行商进行合作,从2019年11月随机选择一天,提取游戏数据库中当天所有对局的核心数据。核心数据是重构游戏和提取游戏特征的原始数据形式。为了减少数据冗余,每隔半分钟提取一次特征,10 min得到20个数据帧,总共得到了496 342个数据帧。在每个数据帧中,包括了一些明显对胜率预测有帮助的信息,如经济、击杀数和团队的塔数等,如图2所示。

图2 王者荣耀数据集示例图
1.1 基础特征提取
根据获得的数据集,可以直接提取出基本特征。这些基本特征的主要构成如表1所示,基本特征的具体形式如表2所示。
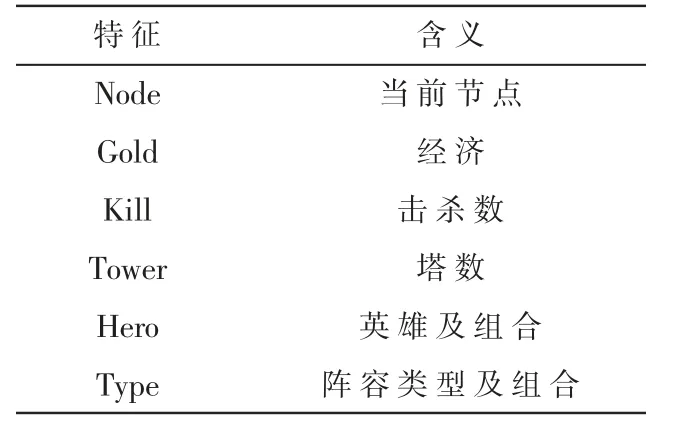
表1 基础特征

表2 基础特征每个字段含义
1.2 时序统计特征提取
本文还提取与游戏时间相关的统计信息,描述特征在不同时间节点的表现,主要包括两类:一类是战斗数据在不同时间点的作用;另一类是角色在不同时间节点的作用。战斗数据类型能够反映出两队通过战斗所获得的所有资源差异,主要包括在不同时间节点下的经济、击杀和塔数上的差异。例如,需要统计整局游戏中两队经济的最大值、最小值、均值以及当前节点与相邻节点间经济的差值等。
统计特征包括战斗统计特征和角色统计特征,其中战斗统计特征的具体形式如表3所示,角色统计特征的具体形式如表4所示。

表3 战斗统计特征的形式
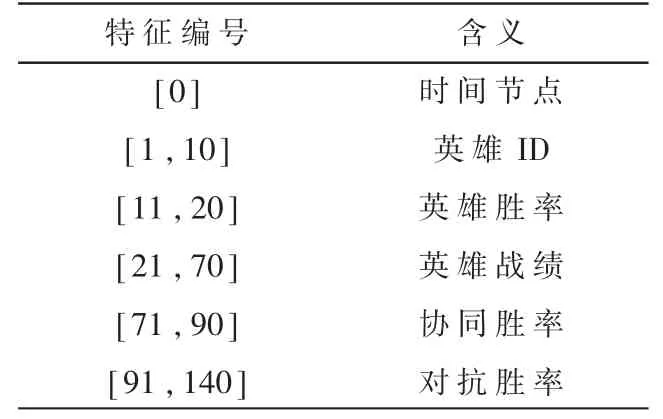
表4 英雄统计特征的形式
2 角色-实时联合预测网络
2.1 整体框架
为了建立准确且可解释的预测模型,需要同时考虑角色信息和实时信息。将角色模型和实时模型结合起来预测胜率,其中角色模型主要由双线性模型捕获角色的时序特性,通过序列LSTM模型来进行赛时胜率预测;实时模型主要由LSTM搭建的可解释性时空网络模型来进行可解释的赛时胜率预测。为了捕获时间序列特征,搭建了序列建模网络LSTM来进行任务预测,选择连续的l个节点数据作为输入,游戏时间t的输入数据为X=[xt-l+1,…,xt]T。 对于游戏开始4 min前的输入,同样输入四个数据,如t=2时,X=[x0,x1,x2,x2]T。最后,将两个模型的预测输出进行融合,提高预测的准确性。图3展示了提出的联合模型的流程图。

图3 模型整体框架图
2.2 角色模型
为了解角色在比赛中的作用,对角色的时序属性进行提取。角色数据类型能够反映在不同时间阶段角色以及角色组合的影响力差异。王者荣耀中的角色都有不同的定位,不同定位的角色在不同游戏阶段的作用不同,全面了解不同阶段内游戏角色之间的协同和对立关系是十分重要的。提取角色时序属性首先提高了胜率预测的准确性;其次,可以帮助玩家发现比赛中每个角色的影响力,提高了对预测结果的可解释性。为了更好地模拟角色的协同和对立关系,提出了一个潜在变量模型,将游戏角色建模为学习的低维空间中的向量。嵌入方法通过学习低维向量来捕获实体的丰富属性。
给定英雄的编号N,英雄集合表示为H={H1,H2,…,HN}。将每场比赛中红蓝两队的英雄表示为对于英雄Hi,其特征向量表示为hi∈RV,则H∈RN×V表示英雄的特征矩阵。
选择使用双线性模型来模拟协同和对立关系。首先对两名英雄之间的关系进行提取。引入协同评分函数计算Hi和Hj的协同得分。

其中CH∈RV×V是Hi和Hj的协同矩阵。引入了对抗评分函数来计算Hi和Hj的对抗得分。
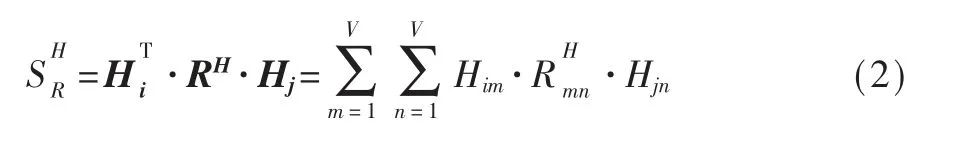
其中RH∈RV×V是Hi和Hj的对抗矩阵。图4展示了角色关系嵌入并进行赛时预测的流程。

图4 角色模型框架图
2.3 实时模型
模型的框架如图5所示,在空间阶段,所有特征被分为三个不同的特征组(金币、击杀和塔数),并投影到3个独立的表示空间上,也是资深专业评论员关注的3个最重要的特征。构建3个LSTM序列网络模型,仅将单个特征组和游戏时间t作为输入并作出各自的获胜预测,通过将游戏时间添加为模型输入特征的一部分,模型的准确性得到了提高,整个预测模型的准确性也得到了提高。模型的输出为Si∈[0,1.0],表示基于单个特征组值差的胜负可能性预测。同一特征的重要性在整个游戏中并不是一成不变的,为了更好地模拟这种“时间”特征,在第二阶段(时间阶段)中,为3个空间模型分配了3个时变权重,并通过空间模型输出的加权组合来进行最终的胜率预测。给定作战空间中作战模型提供的时间点t的得分向量c(x,t)(其中x代表特征组),在时间阶段通过重要性权重wt和得分向量c(x,t)的线性组合获得Ct:

图5 实时模型框架图
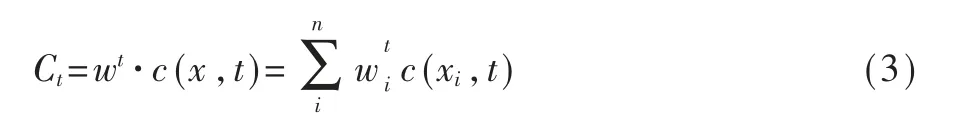
2.4 角色-实时联合模型
根据对MOBA游戏的深入调查发现,角色数据和战斗数据在整个游戏中也并非始终重要和同等重要。为了更好地模拟战斗和角色相对时间的重要性变化,在联合模型的第二阶段,为每个模型分配了时间变量和可学习权重。经过空间阶段,会得到得分向量FP=[Ct,Rt],然后将重要权重向量分配给得分向量以获得最终预测分数Pt。

2.5 可解释性
可解释性是联合模型的重要优势,主要集中于实时模型中。在实时模型的第二阶段会产生特征贡献向量,能够更直观地解释特征对胜率的影响。作出重大贡献的特征不一定是最重要的特征,例如,在大多数时间点,双方的经济都是非常重要的特征,但如果双方的经济差异接近于0,则经济对胜率贡献不大。这也意味着,如果第一阶段的预测输出足够高,那么重要性相对较低的特征仍然可以作出不可忽略的贡献。更重要的是,对每个贡献向量求和会得到实时模型的最终得分。如实时模型中三个特征组在10 min时的预测得分为[0.82,0.76,0.75],它们的重要性权重为[0.56,0.3,0.14],则三个特征组的贡献为[0.46,0.23,0.11]。通过贡献值排序,对局层的得分为0.8,功能组1(gold)是对局层中最为重要的特征。同时角色模型的最终得分为0.7。此时,对局层和英雄层的重要性权重为[0.85:0.15],因此最终胜率为0.785。评论员可结合信息作出比赛评论和精准预测。此信息也可用于在游戏结束后恢复游戏,并通过信息确定游戏的阶段性目标。
3 实验
3.1 实验设置
本实验基于Windows平台通过Python语言实现,采用Windows 11 21H2的操作系统,硬件配置为Intel®CoreTMi5-8300H CPU@2.30 GHz,显卡为NVIDIA GeForce GTX 1050 Ti,内存为16 GB,硬盘为512 GB。实验选择了496 342个数据帧中的10%作为测试集,10%作为验证集,剩下的80%作为训练集。对于联合模型的参数设置,使用带有两个循环层的双向LSTM,dropout的概率是0.2,隐藏状态的大小为128。在LSTM之后,使用一个256维全连通层和一个tanh函数来计算类分数P(y|X)。
3.2 对比模型
(1)逻辑回归(LR):逻辑回归将所有特征作为其输入。
(2)SVM:SVM将所有特征作为其输入。输入与LSTM格式相同,参数C=0.01,参数Gamma=10 000。
(3)LSTM:使用双向LSTM和两个循环层,辍学概率为0.1,隐藏状态的大小为32。在LSTM之后,使用64维完全连接层和tanh函数来计算预测结果。
3.3 结果与分析
为了验证提取的角色关系对模型性能提升的有效性,使用了LR与GBDT来进行实验。结果如表5所示。
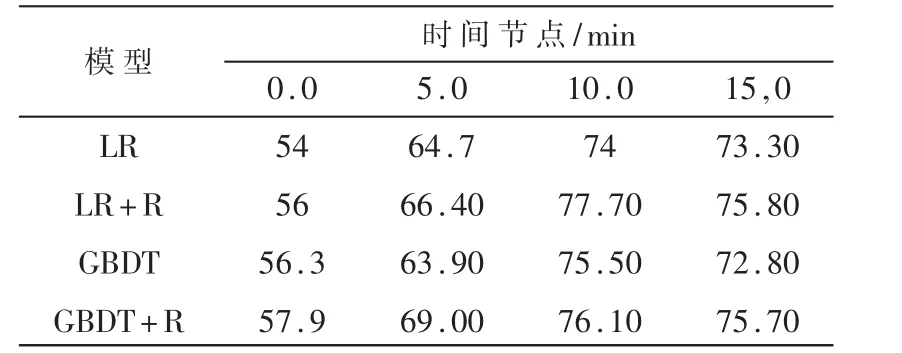
表5 角色关系提取算法在不同模型上的效果(%)
当使用由算法提取出的角色关系作为特征输入时,不仅能够依靠角色进行赛时胜率预测,而且在不同算法的效果都有提升,其中LR的效果最好,最高达到了77.7%。在图6中,通过每2 min进行一次预测,比较了所有提出的方法的准确性。从这些实验中可以得出三个观察结果。
(1)实时信息大大提高了基线的预测准确性,当输入超过6 min的实时信息时,所有四个实时模型都能获得更好的准确性。
(2)中后期实时特征比角色特征提供的信息更多。随着模型间差距的缩小,表明队伍的实时表现决定了获胜的一方。
(3)在使用少于10 min的实时特征时,联合模型的性能优于LR。在比赛初期阶段,更重要的是对性能趋势进行建模,而不是对当前值进行建模。联合模型明确地建模了4个时间序列数据,编码了每个团队的表现趋势,因此它在这个时期的表现优于LR。
所有模型在5个等距时间节点的平均预测精度如表6所示。联合模型在早期阶段显示出优势,而其他模型在节点0处的精度稍低。原因是节点0时的战斗数据相同,阵容是唯一决定胜率的因素,而联合模型可以结合战斗数据和阵容预测比赛,并对角色关系进行优化。由于联合模型在不同阶段增加了英雄对获胜率的贡献,因此结果略高于其他模型。另外,如图6所示,节点10后准确率下降的原因有两个:

表6 5个预测模型在5个等距时间点的准确度(%)
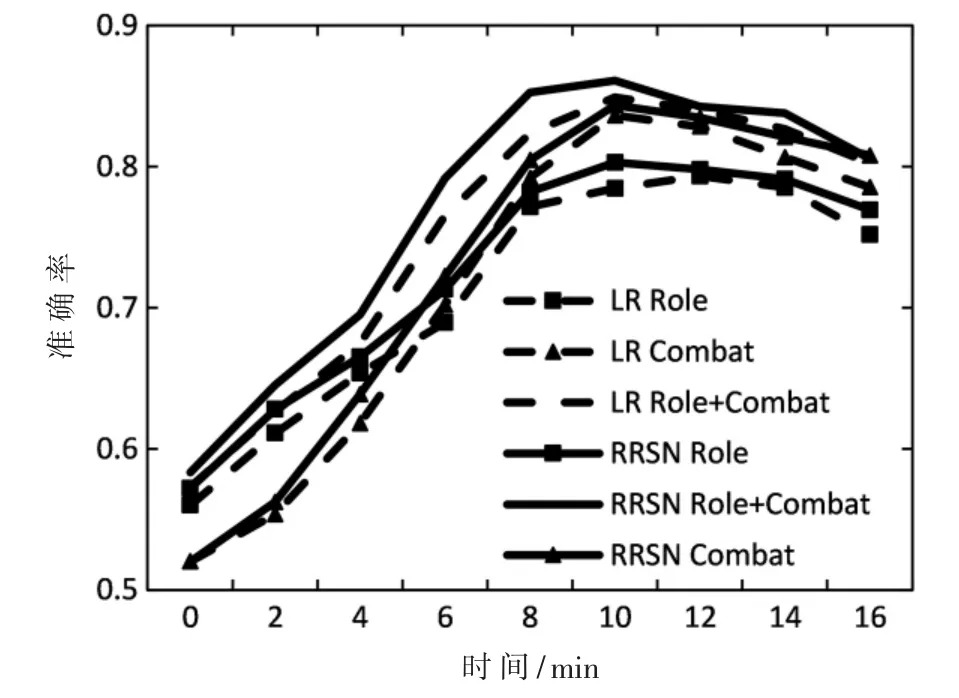
图6 模型在不同时间节点的准确率图
(1)游戏进入后期,双方设备达到最大值,游戏结果越来越受到玩家意外失误等随机因素的影响。
(2)由于大部分游戏还未进入后期阶段便结束了,游戏后期的数据远少于游戏中期阶段的数据,导致预测精度显著下降。
此外,本文将所有的特征分成最主要的4个特征,通过实验得到了所有特征在每个时间节点的特征重要性,如图7所示,在游戏前期,与角色相关的特征是最为重要的特征;随着游戏的进行,与经济相关的特征变得越来越重要;当游戏进行到中期,与经济相关的特征和与击杀相关的特征变得重要;到了游戏后期,与塔数相关的特征成为了最关键的特征。
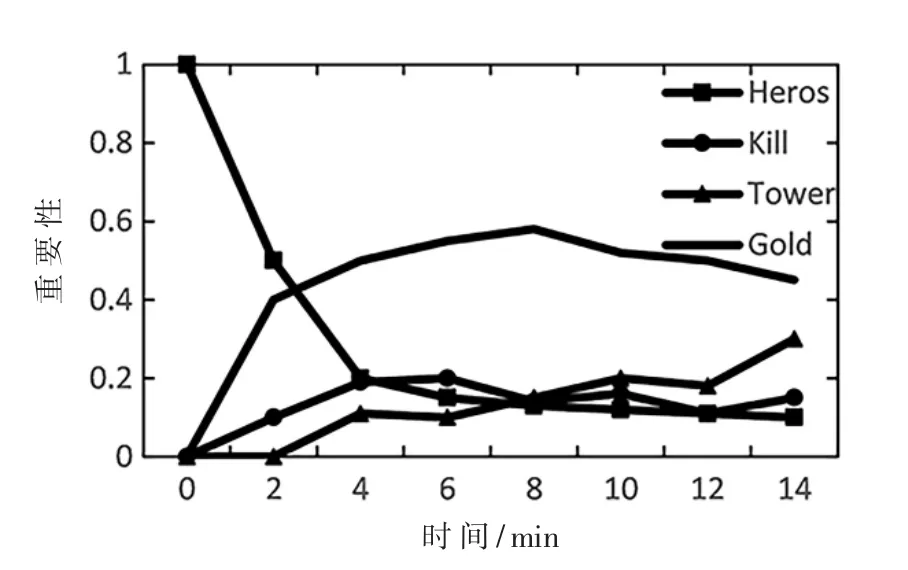
图7 特征重要性图
4 结论
本文利用收集到的王者荣耀游戏的真实对战数据,提出了一种角色-实时联合预测模型,以提供高准确率的可解释性预测。该模型结构的核心思想是在赛时胜率预测中引入角色交互,以提高准确率;同时分离战斗数据和英雄数据价值差异的影响以及每个特征的相对重要性,以解耦不同特征的贡献,从而得到更全面的解释。结果表明,随着游戏时间的变长,角色的预测能力会下降,通过对实时时间序列进行建模来提高预测准确率。模型在预测精度和可解释性方面比其他的模型效果更佳,模型的可解释结果可用于各种类似的场景,以促进相关行业的发展。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
机械工业标准化与质量(2022年6期)2022-08-12
法律方法(2021年4期)2021-03-16
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
文教资料(2018年30期)2018-01-15
体育时空(2017年7期)2017-08-03
首都体育学院学报(2016年2期)2016-04-08
无线互联科技(2015年23期)2016-03-05
中国体育科技(2010年6期)2010-03-03
