
基于微博数据的云南省地理情感及主题特征研究
2022-09-02 02:20:46李梁森杨德宏翟文龙李刘飞高励
城市勘测 2022年4期
李梁森,杨德宏,翟文龙,李刘飞,高励
(1.昆明理工大学,云南 昆明 650093; 2.南方海洋科学与工程广东省实验室(广州),广东 广州 511458; 3.中国科学院软件研究所天基综合信息系统重点实验室,北京 100190; 4.山东正元数字城市建设有限公司,山东 烟台 264000)
1 引 言
随着互联网和定位技术的快速发展,发布在社交媒体平台中的信息越来越多带有位置标签。这些信息不仅是人们真实生活在网络世界中的展示,也包含着人们的观点、兴趣和需求等。通过社交媒体信息了解人群活动,进而发掘区域的地理情感和主题特征,对推动区域协调发展具有重要意义。
在国外,社交媒体数据主要来源于Twitter。Mitchell等利用Twitter地理标记数据集进行了美国州和城市的分类及居民幸福感的评估[1];Dyer等研究了美国新冠肺炎大流行期间美国人的关注点及情绪变化[2];于亚新等利用Twitter数据集研究了MFCD算法在用户行为理解方面的优越性[3];Suparna等研究了组织推文中的情绪与公司股价的关系[4]。在国内,社交媒体数据主要来源于微博及携程网等。刘逸等通过与联合国UNWTO数据进行校验,验证了微博旅游大数据在情感分析中的可行性[5];李萍等利用百度旅游和携程网点评数据揭示了北京市5个社区的旅游形象[6];刘萌通过黄山景区微博数据探究了景区不同旅游路径上的游客情感[7];费涛研究了日常与假期期间微博主题时空分布特征的差异性[8]。
根据《第47次中国互联网络发展现状统计报告》显示,微博作为全球最大的中文社交媒体平台,在网络新闻、政策发布、疫情防控等方面发挥着巨大的作用,已经成为人们获取信息、抒发情感和表达意见的重要渠道[9]。本文选取新浪微博数据,利用基于情感词典的情感分析方法和基于主题模型的主题建模方法,获取每一条微博的量化情感分值及主题类别,探究云南省129个区县的地理情感及主题分布特征,为云南省的区域协调发展提供有意义的参考。
2 数据采集及预处理
原始数据是通过网络爬虫获取2021年3月~5月期间定位在云南省范围内的新浪微博数据,并且不包含微博大V、机构团体等数据,仅采集个人用户的数据,包括用户名、发布日期、发布位置及发布内容。
由于本文的情感计算需要细化到区县粒度,因此首先去除没有定位信息和定位信息大于区县粒度的数据。其次,微博数据的文本信息不仅包含文字、表情、符号等表现形式,还含有转发、艾特等互动信息。因此在微博文本中充斥大量的对情感计算无用的标记信息,主要有@用户、#话题#、网页链接等。为了保证情感计算的准确度,利用正则表达式提取微博的正文内容,并剔除@用户、#话题#、网页链接等无用信息。最终得到的有效微博数据为26万余条。
3 研究方法
3.1 情感计算
受理性原则的支配,地理学对情感的研究时间虽然不长,但情感分析作为自然语言处理的一个重要分支,经过多年的发展,技术已经比较成熟[10]。情感计算的方法主要有两种:非监督的分类方法和监督的分类方法[11~13]。本文采用非监督的分类方法,即利用情感词典进行微博数据的情感定量化计算。为了尽可能匹配较多的情感词汇,保证情感计算的准确度,在采用大连理工大学情感词汇本体库的7大类21小类情感分类的基础上,融合其他情感词典构建通用情感分析词典,根据情感倾向(正向、中性、负向)和情感强度(1~9、0和-1~-9),计算每条微博的量化情感分值[14,15]。
利用Python结巴分词进行中文分词,并在分词中添加上述的情感词典作为用户自定义词典,从而保证尽可能获取到较多的情感词汇[16]。对分词后得到的词汇与情感词典进行匹配,根据情感词典对其进行赋值,未匹配到的词则赋值为0;选用中科院中文情感词典之程度词典来匹配程度副词。匹配到的程度副词根据词典对其进行赋值,未匹配的词赋值为1,从而使得其与情感词相乘不会产生变化;采用四川大学机器学习实验室的停用词词表来去除停用词对微博情感计算的影响。微博数据中,除了文本数据具有情感倾向以外,还有多种多样的表情符号。本文参考庞磊和陈冉对微博表情的情感分类及赋值方法对微博数据中的表情符号进行匹配赋值[11,17]。最终,得到每一条微博的平均情感得分,其计算公式为:
(1)
式中,S为该条微博的情感得分;qi为与情感词典匹配后的得分;di为与程度副词词典匹配后的得分;ej为与表情词典匹配后的得分;m为分词后的词语个数;n为匹配到的表情的数量。
3.2 主题建模
文本建模的目的在于发现语料库中的词序列如何生成,并构建数学化的描述方法使文本信息可以参与计算。基于概率的潜在语义分析模型(Probabilistic Latent Semantic Indexing,PLSI)和潜在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)是传统的用于长文本建模的主题模型[18,19]。微博文本由于短文本特有的短小、特征信息少和语义稀疏等原因,使用传统方法进行主题建模,会产生特征矩阵稀疏的问题,建模效果不理想[20]。Yan等学者2013年5月在万维网大会上提出的双语词话模型(Biterm Topic Model,BTM),在LDA模型基础上,采用用一元混合模型中所有文档共享一个主题分布的方法,克服了传统主题模型的数据稀疏问题,是首个针对短文本的主题模型[21]。
为了提高主题建模的精度,对微博数据进行分词及词性标注后,仅保留名词、动词和形容词,并去除少于4个词的微博数据。采用主题一致性指标(Topic Coherence)确定主题数目并采用BTM模型对微博数据进行主题建模,最终确定微博数据的文档-主题概率分布和主题-词概率分布。
3.3 空间分布模式
空间现象受到距离和方向的作用,使得传统的统计分析方法无法准确描述地理现象。20世纪60年代,法国统计学家Matheron G开创了空间统计[22]。空间统计学的主要思想在于空间中邻近的现象或数据比远处的现象或数据具有更高的相似性。采用全局Moran’s I指数的方法对微博情感进行空间自相关分析,根据计算判断微博情感的空间相关性及置信度[23]。Getis-OrdGi*方法可以获取高值或低值要素在空间上聚类,用于获取微博情感及主题模型在空间上高值(热点)和低值(冷点)的空间聚类特征[24]。
4 结果与分析
4.1 微博情感分值的空间分布特征
计算出260 878条微博数据的情感分值以后,根据计算结果,将微博情感分为三类:即情感分值大于0的正向情感,共有 173 973条,占总微博数量的66.69%;情感分值等于0的中性情感,共 39 419条,占总微博数量的15.11%;情感分值小于0的负向情感,共47 486条,占总微博数量的18.20%。个体微博的情感得分在空间上分布如图1所示:
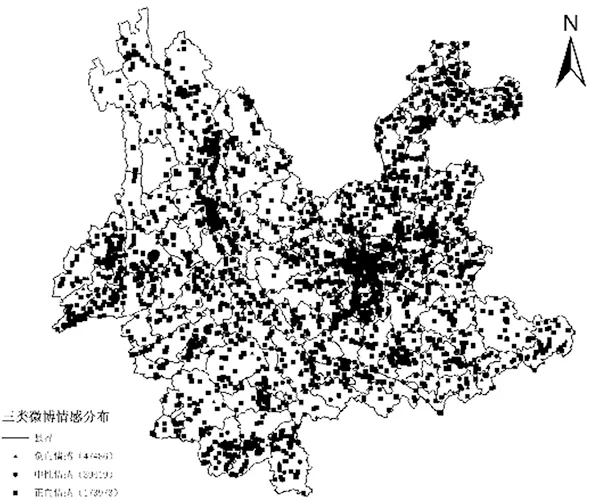
图1 三类微博情感分布图
总体上看,微博情感以正向情感为主,但个体微博的情感分值在空间上的分布是随机的,各类情感互相交错,在空间上没有明显的聚类或分离现象。因此,本文计算了云南省129个区县的微博情感均值,如图2所示:
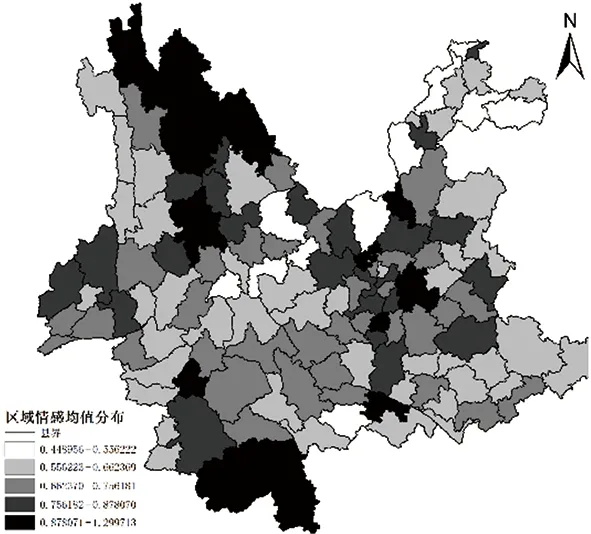
图2 云南省微博情感均值分布
4.2 微博情感空间分布模式
为了判断微博情感在云南省范围内的空间自相关性,根据云南省微博情感均值分布采用全局Moran’s I指数进行空间自相关性的计算,最终结果如图3所示:
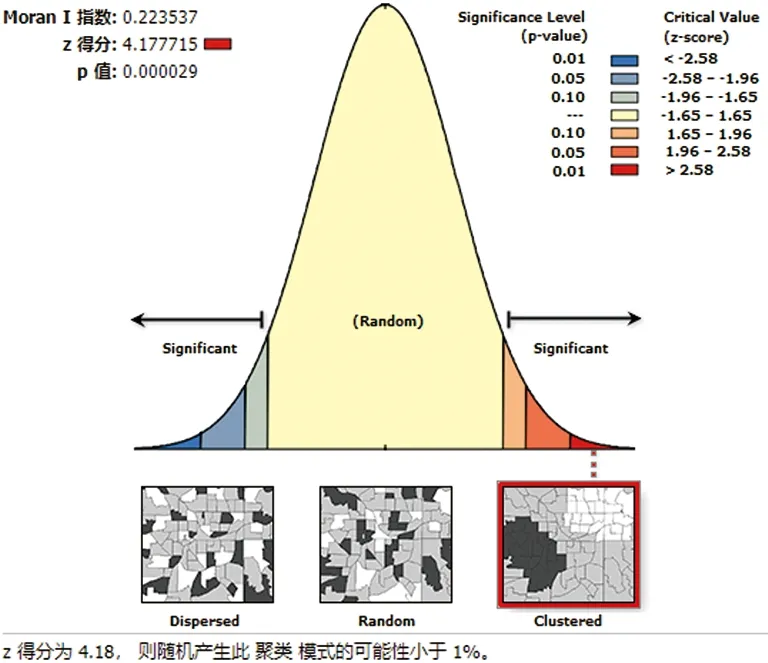
图3 全局Moran’s I指数计算结果
从图3来看,最终计算结果:z得分为 4.177 75,p得分为0.000 029,且Moran’s I指数为 0.223 537,则有99%的可能认为微博情感在云南省范围内具有聚类模式特征。由于Moran’s I指数为正,说明微博情感在云南省范围内具有正的相关性,即相邻的区县具有相同或相似的微博情感。为了进一步探究微博情感在空间上的聚类分布特征,通过Getis-OrdGi*方法计算了云南省微博情感的冷热点模式,如图4所示:
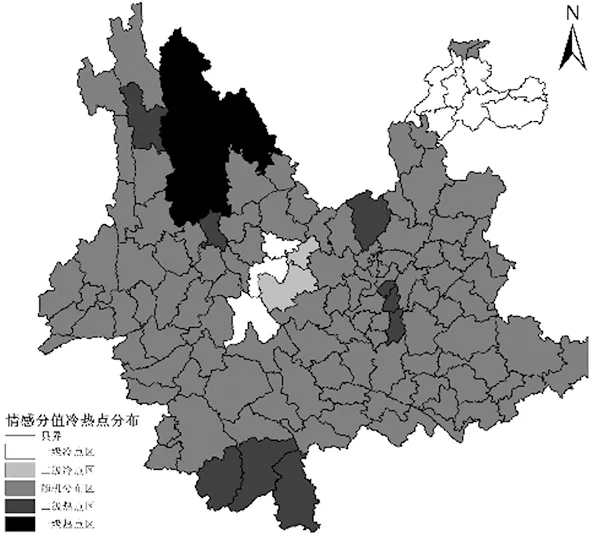
图4 云南省微博情感冷/热点分布
根据Getis-OrdGi*值的高低及显著性水平,采用自然断点分级法将微博情感在空间上的分布分为5类区域:一级冷点区(冷点高聚集区)、二级冷点区(冷点低聚集区)、随机分布区、二级热点区(热点低聚集区)和一级热点区(热点高聚集区)。由图6所示,云南省的微博情感在空间上具有明显的冷/热点(低/高值聚类)特征。热点区一主要分布在云南省的西北(丽江市的古城区、玉龙纳西族自治县、宁蒗彝族自治县,大理白族自治州的大理市、洱源县、鹤庆县、剑川县,迪庆藏族自治州的香格里拉市、维西傈僳族自治县),热点区二主要分布在云南省的南部(西双版纳傣族自治州的勐海县、景洪市、勐腊县);冷点区一主要分布在云南省的东北侧(昭通市的昭阳区、永善县、大关县、盐津县、彝良县、镇雄县、威信县),冷点区二主要分布在云南省的中部(楚雄彝族自治州的楚雄市、南华县、姚安县、牟定县,普洱市的景东彝族自治县)。
4.3 主题模型空间分布模式
通过BTM模型对微博文本进行主题建模后,获取36个主题。选取每个主题下概率最大的前20个词,采用词云图的形式对主题1~主题37进行展示,如图5所示:

图5 主题1~主题36词云图展示
利用Getis-OrdGi*对36个主题的冷/热点分布模式进行探究,如图6所示:

图6 主题1~主题36冷/热点分布
如图6所示,微博情感热点区一是主题16宗教、主题19人文旅游、主题20风景旅游、主题24正面情绪、主题31天气分布的热点区,主题9疾病分布的冷点区;微博情感热点区二是主题1茶、主题20风景旅游、主题31天气分布的热点地区,主题23负面情绪分布的冷点地区。上述主题中,主题19和主题20均为旅游主题,同时旅游主题在微博情感热点区二是二级热点区,在微博情感热点区一是一级热点区,说明由于疫情影响,处于边境的旅游城市的旅游业仍然受到较大的影响。出门旅行会对天气有更多的关注,因此主题31在两个微博情感热点区域也属于热点分布。而主题23负面情绪的冷点分布与主题24正面情绪的热点分布,可以近似的看作是同一类分布,说明两个微博情感热点区域的人们生活较为轻松愉悦。除此之外,两个情感热点区域的热点分布主题还有其地域分布有关,微博情感热点区一中的大理白族自治州和迪庆藏族自治州信仰佛教的人较多,因此是主题16宗教的热点分布区,微博情感热点区二的西双版纳傣族自治州是云南产茶区之一,因此是主题1茶的热点分布区。综上,云南省微博情感热点分布的共性为关注旅游,并且有较多的正面情绪或较少的负面情绪。
微博情感冷点区一是主题9疾病、主题17离乡、主题22负面情绪、主题23拼搏、主题33遗憾、主题35音乐分布的热点区域,微博情感冷点区二是主题2出行、主题17离乡分布的热点区域。两个微博情感冷点区均包含主题17离乡,主题2出行和主题23拼搏也均与主题17有关。因此,两个微博情感冷点区的共性为对离乡有更多的关注。不同的是,微博冷点区域一全部分布在昭通市内,而昭通市作为云南人口第三的城市,仅有两家三甲医院,医疗资源短缺,且存在地方病氟骨病,因此对主题9疾病有更多的关注,且存在较多的负面情绪。
5 结 语
基于2021年3月~5月定位在云南省范围内的26万余条新浪微博数据,采用基于情感词典的情感计算方法和基于BTM模型的主题建模方法,度量了微博数据在云南省的情感分布及主题聚类特征,揭示了影响云南省地理情感分布的主要因素。
研究表明,云南省基于微博数据的地理情感在空间上具有明显的聚类特征,存在大范围的热点分布区和冷点分布区各两个;旅游城市的微博情感较高,且具有更多的正面情绪或较少的负面情绪;微博情感较低的区域更多的关注离乡拼搏,且微博情感冷点区一由于医疗资源不丰富和地方病的原因,对疾病有更多的关注,且有更多的负面情绪。
本文利用微博大数据,通过将情感分析与主题建模相结合的方式,衡量了云南省的区域地理情感特征及其影响因素,为推动区域的协调发展提供了一种新的思路。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28 06:07:02
压力容器(2022年11期)2022-02-17 06:34:58
文苑(2019年24期)2020-01-06 12:06:50
车迷(2019年10期)2019-06-24 05:43:28
教学考试(高考语文)(2018年2期)2018-07-21 01:53:26
快乐语文(2018年7期)2018-05-25 02:32:00
——居住在“冷点社区”与健康欠佳、享有卫生服务质量欠佳间的关系
中国全科医学(2018年19期)2018-01-27 21:01:14
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
中国记者(2014年6期)2014-03-01 01:39:53
