
基于层次频繁模式树的数据自动挖掘算法
2022-08-29 10:59:00王景兰
上海电机学院学报 2022年4期
王景兰, 方 晓
(亳州职业技术学院 信息工程系, 安徽 亳州 236800)
近些年,随着信息网络的迅速发展,数据挖掘技术得到了广泛关注[1-2],主要是由于大量的数据被转换为有用的信息和知识,能够在获取过程中应用于多种类型的产业结构[3-4]。随着数据库的成熟发展,人类日积月累产生的数据信息越来越复杂,在不同产业内部形成了超过数百万条的信息记录[5-6],需要对其进行更深层次的分析才能被有效利用。但由于数据库系统只能完成录入和查询功能,在数据存在的相关联系中,无法根据现有数据进行未来预测,不能实现现有数据的隐藏功效,导致数据繁多且知识贫乏的局面[7]。如何在海量数据中有效提出对应知识点,成为目前最需要解决的问题之一。数据挖掘的任务主要是从信息中发现关联模式,以此判断选项集合中的规则,为不同产业提供预知行为可能性[8-9]。
其中频繁模式树能从数据的底部进行挖掘,从下至上依次对关联节点进行支持度分类,根据数据的首尾相接模式,减少不必要的数据搜索,可在有限时间内提高挖掘效率[10]。本文以此为基础,研究层次频繁模式树的数据自动挖掘算法,为最大限度地保留信息完整度,提高算法运行效率提供理论支持。
1 基于层次频繁模式树定义挖掘任务
频繁模式树是指在数据库的信息集合中,将原来庞大的事务数据压缩储存为“一棵树”,在其内部可以包含多个类型的数据挖掘信息,根据不同密度将数据分为几个小的事务数据集合,通过其相似度定义挖掘任务。在每个小事务数据集合中,包含有相邻选项相似度最高的数据,根据层次分析方法将相邻的数据依次划分,直到小事务数据集合之间的频繁项相似度降为零[11-12]。
由于算法实现以层次分类频繁模式树为依据,故在算法进行之前需要生成层次频繁模式树,生成过程如下:
(1) 对模式树T进行一次扫描,将支持度满足最小支持度阈值的频繁1项集按降序生成头表H—List。
(2) 将分类标签按字母顺序排序在特征属性的后面,形成三元组顺序表TS—List,表中的每个元素由特征项或类别项、层次号两部分组成。
(3) 对事务数据库进行一次投影操作,将原始项集中不在H—List的项删除。
(4) 对于每一个事务Ti,根据处理后的项集,结合项在TS—List的层次关系生成层次频繁模式树(HCFP—Tree)。HCFP—Tree生成时,相同层次的特征节点可以共享路径、类别节点。
(5) 生成标头Header表,表中指针指向对应的类标签节点。
当数据集合不存在相似度后可以对任意集合进行关联,首先根据每个事务集合中,最高支持度的数据选项进行初次归类,以具有相同数据最多的集合作为第1个事务集合的合并,利用支持度对余下的非最高相同事务进行筛选查询,其他数据选项是否都属于此类事务集合的任务目标,这样这些事务任务就构成了一个新的集合[13-14],以此类推直到所有事物集合重新完成任务分类。为减少集合的分类负荷,在每个频繁出入的集合中进行原生数据的任务处理,保证在同一个任务集合分块中的频繁项相似度较高,不同集合分块中的相似度要接近于零[15]。在定义完成数据挖掘任务后,根据关联规则对应建立数据矩阵,以保证自动挖掘算法的顺利完成。
2 建立数据自动连接矩阵
根据层次频繁模式树给出的挖掘任务,对需要整合的数据进行权重分析,以此建立相对应的连接矩阵,根据层次分析法的权重生成模式,对变量数据进行离散。以每组连续数据的取值范围[0,1]作为单次节点出入项,确定不同任务层级的连接权重,每个层级的数据个数设置为g,数据向量的输入矩阵表示为
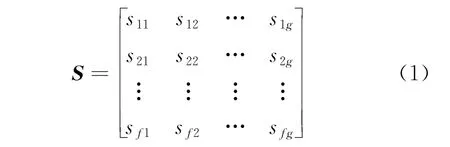
式中:S为输入向量的连接权重,在输入样本向量中设置f×g的矩阵类型,f为输入数据的记录数值。
根据连接权重的数据分别设置相邻数据向量的期望值,利用隐藏函数作为反复迭代的补充,计算其输出向量,表达式为
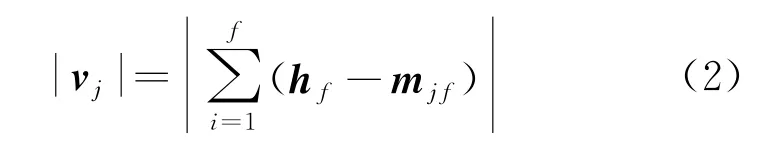
式中:v j为相邻数据向量期望值的输出向量;j为某个数据向量期望值;h f为输出相对误差;f为输出相对误差数量;m jf为上一层级相邻数据向量期望值的输出向量。
当期望输出的权重包含相对误差h f时,假定两个层级v j和m jf之间的函数包含第i个可能性。在误差大于0时可以设置为迭代完成,将所得结果作为输出数据的期望值,用于后期队列的排序,根据最小支持度进行裁剪即可。
3 最小支持度裁剪队列完成数据挖掘
在建立连接矩阵后可对潜在的数据进行关联,有效收集海量数据中较为频繁的模式关系,根据其特性分析存在的同一事物,选择影响度最小的数据值进行数据挖掘即可。以候选集合裁剪枝的思想理念,设定数据向量集合的规则定义,在集合Q中会有相对项的执行集合,每个集合中包含对应项,其中项所在的集合必须满足定义集合,表达式为
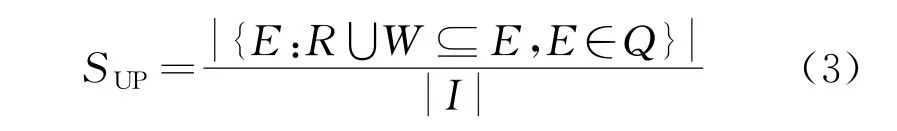
式中:E为相对项的执行集合;W为其中包含的对应项;R为能够被执行的对应项数据,用单一集合标识;I为给定集合中能够被执行的数据可信比。
此时产生的集合T可作为定义项中的执行选项,当其属于执行对象集合时,在两者之间能够生成可信比,可以作为等待执行的选项进行最小度计算,表达式为
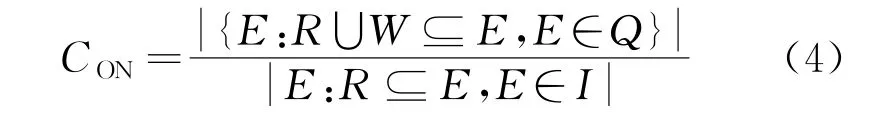
在其中能够对用户的最小支持度和最小可信度进行关联,通过扫描数据集合的矩阵队列对重复数据进行裁剪,即可完成频繁模式树下的候选集数据挖掘。
至此本文通过理清层次频繁模式树的基本概念,结合候选集剪枝思想的基础上,提出优先定义数据挖掘任务选项,在建立数据自动连接矩阵选集中,利用最小支持度裁剪队列自动挖掘数据,完成基于层次频繁模式树的数据自动挖掘算法设计。
4 实验结果分析
为验证设计的数据自动挖掘算法的实际意义,选择某动车组的运维数据作为样本,在调取近3个月的数据信息中利用分布式集群实验环境进行模拟,将多个路由器和动车组计算机端口完成连接,导入历史数据。该实验的主要目的是对本文设计的方法进行全部数据筛选,在有效时间内完成关联对象的挖掘任务,具体测试环境的连接节点性能和参数如表1所示。
表1 数据节点名称和性能参数
由表1可见,在实验中共包含4组数据节点,每个节点的内存大小和主机连接形式相一致,能够减少数据采集和储存过程中的误差。将动车运维计算机和建立的数据节点依次连接,其中每组数据节点为自动信息获取模式。为能够更加直观地验证新算法的优越性,选择两组传统算法进行对照,分别为单机前向传播算法和并行前向传播算法,与本文算法进行性能对比。利用VC++6.0在内存为128 GB、CPU 为Pentium Ⅲ-733 MHz、操作系统为Windows 10的电脑中实现3种算法。设置每组数据节点的接收总量分别为200万条、300万条,其各自的挖掘时间测试结果,如图1所示。
根据图1每组数据节点,数据接收的时间间隔均设置为10 s,对不同接收数据总量的挖掘结果来看,本文方法在数据处理时间上对比两组传统算法,用时较少。其中在200万条数据中3种方法的处理时间相持平,但当数据总量增加至300万条时,所用时间的差值拉大,两组传统方法所用时间均高于400 s,而本文方法仍然能保持在150 s之内。综上所述,本文方法能够在较短的时间内完成大量繁杂数据的挖掘,具有实际应用意义。
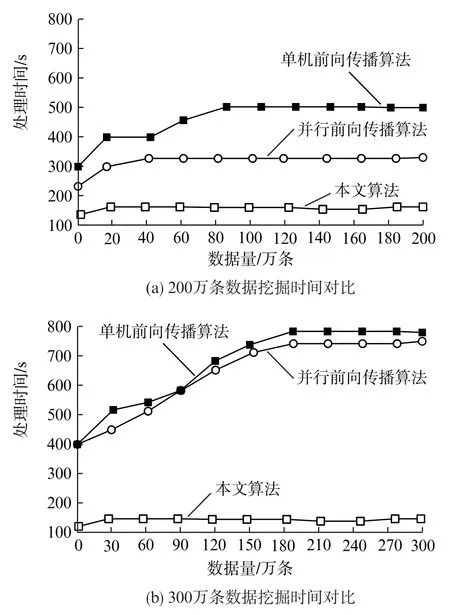
图1 不同算法下对数据总量的挖掘时间结果
为进一步证明本文方法能提高数据挖掘的完整性,在对比3种方法的处理时间上,以150 s为样本数据的挖掘时间,选择200万条数据总量进行多轮测试,具体结果如表2所示。
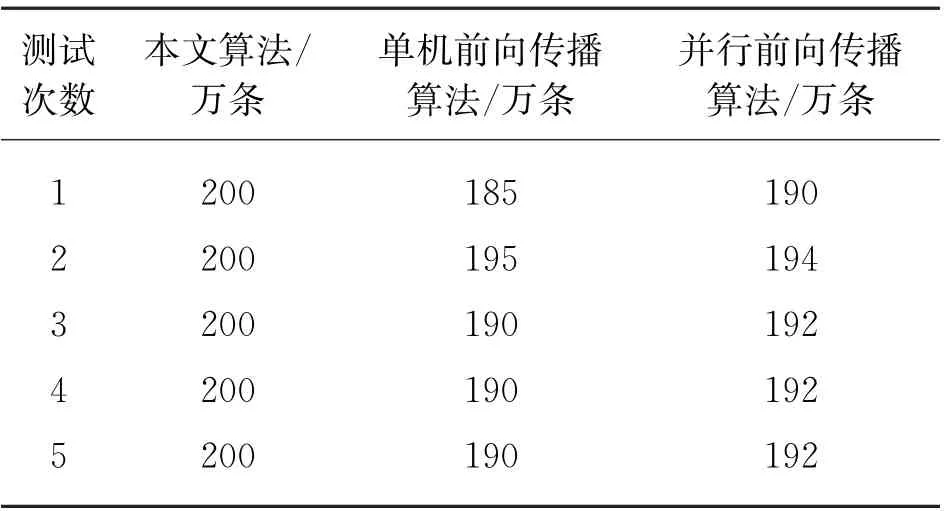
表2 不同算法下数据内容保留总数
由表2可见,本文算法在多轮测试中挖掘的数据总量,与节点接收的数据相一致,基本上没有任何出入。两组传统算法虽然能够在规定时间内完成数据挖掘,但数据总量保留的平均值分别为190万条和192万条,比本文算法分别少了10万条和8万条。综上所述,在对复杂的数据挖掘中,本文算法能够在有效时间内执行任务,且所得数据可以完整保存,不会产生丢失现象,具有实际操作意义。
5 结 语
本文在层次频繁模式树的理论基础上,结合候选集剪枝思想重新定义挖掘任务,以建立数据自动连接矩阵为基础,利用最小支持度裁剪队列自动挖掘数据,完成新的数据自动挖掘算法设计。实验结果表明:在本文算法的应用下,能够对选择的数据总量进行有效执行,且挖掘后的数据与原有节点接收总量相一致,最大限度地保存信息的完整度,能够被广泛应用。后续研究中将针对挖掘后的数据进行测试,检验是否存在重复数据拟补丢失数据的现象,为更高效能的数据挖掘提供理论支持。
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
大众投资指南(2021年35期)2021-02-16 01:06:26
河南水利年鉴(2020年0期)2020-06-09 05:43:44
电力与能源(2017年6期)2017-05-14 06:19:37
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
信息通信技术(2015年6期)2015-12-26 01:16:46
新高考·高二数学(2015年11期)2015-12-23 18:17:44
