
医院新生儿患者主索引模型的优化与探索
2022-08-29 02:21:08陈韵王洁琳
现代信息科技 2022年12期
陈韵,王洁琳
(四川大学华西第二医院,四川 成都 610066)
0 引 言
一个患者对应一份真实可靠又完整全面的医疗记录,是医疗信息管理的一种理想状态。这份医疗记录在主数据管理(Master Data Management ,简称MDM)中被称为单一最佳记录(Single Best Record,简称SBR)或者金质记录(Golden Record)。新生儿患者的SBR 不仅应该包含新生儿科、儿科,以及将来成年后的相关医疗数据,而且应该包含其在产科出生时的记录,甚至应该包含母亲整个妊娠过程的数据的关联。
但现实中,新生儿患者存在多次建卡并在HIS 中拥有多个患者标识号,每个患者标识号对应的医疗记录都不是SBR。首先新生儿在产科出生时医院会自动新建一个患者标识号,这个标识号与母亲生产就诊时相关联。新生儿患者从产科出院再就诊时,尤其是急诊就诊或急诊入院,可能会再办理一张新的就诊卡,生成新的患者标识号,这个标识号与其在产科时的标识号无法直接关联匹配。新生儿办理出生证后,可能会以出生证号又再办理一个患者标识号来就诊;新生儿办理户口后,还可能会以身份证号再办理一个患者标识号来就诊。主动找医院合并标识号的患儿数量占比非常小,大多数患儿直接使用新的标识号就诊,旧的标识号可能不会再被使用。新生儿患者每次就诊的医疗记录被不同的患者标识号分割成多组档案,给临床查阅带来困难,还可能造成数据统计分析失实。新生儿在儿科的就诊数据也失去了与母亲整个孕期数据的珍贵联系,导致研究母亲怀孕生产情况和新生儿病情、生长发育的多个科研项目因为提取不到关联数据而难以进行。综上所述,医院迫切需要一个可以自动或者半自动合并新生儿患者标识号的平台或模块来解决上述问题。
1 传统患者主索引(EMPI)的匹配规则和弊端
企业级患者主索引(Enterprise Master Patient Index,EMPI),将来自多个系统或多个业务版本的患者标识进行关联,实现同一患者医疗信息的统一,最终保证一位患者只有一个全局唯一标识号(Global Patient Identifier,GUID)。每个患者GUID 对应唯一份最真实最可靠最全面的患者信息记录,既SBR。EMPI 不仅可以解决患者在同个系统中存在多个标识号的关联问题,而且可以整合同一患者在不同的院内系统中的不同体系的患者标识号。根据中国医院协会信息专业委员会在2019—2020年度对1 017 家医院的EMPI 的建立和使用情况的调查与分析,建立了EMPI 和GUID 的医院比例达到75.81%。传统的EMPI 虽然能较好地处理成人患者和年龄较大的患儿的身份信息匹配,但是在新生儿患者身上却无法使用。
传统EMPI 一般使用证件号、姓名、性别、出生日期、电话号码等,交叉匹配计算每两个标识号的信息相似度值,再同阈值比较判断两个及两个以上的患者标识是否属于同一患者。两个患者标识对应两组信息x,x的加权相似度的计算公式如下:
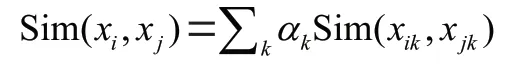
指第个信息项,α指第个信息项对应的权重,Sim(x,x)指x,x中的第个信息项的相似度,相等时相似度为1,不等或者其一为空时相似度为0,对相似度加权求和就是x,x的整体相似度。
以国内某著名医疗信息系统厂商提供的EMPI 为例,所用到的信息项权重如表1所示。

表1 传统EMPI 所用关键信息项
当任意两组患者信息相似度的达到相似推荐阈值(大于30%)时,说明对应的两个患者标识可能属于同一患者,推荐进行人工合并。
但是新生儿作为全新生命个体,短短几个月时间从无身份编号到拥有出生证号、身份证号,其就诊名字也可能从某某之婴变成正式姓名。此外,婚姻对于新生儿来说是无效信息项,而证件号和姓名分别属于静态业务标识和静态人口学特征,在相似度算法中的权重非常大。同一新生儿不同患者标识对应的信息相似度很难达到合理的阈值,往往无法匹配出完整的结果;降低阈值又会匹配出过多不准确的结果,给信息合并带来干扰。因此,传统的交叉匹配计算加权相似度的策略不适用于新生儿患者,EMPI 信息项需要针对新生儿重新设计和优化。
2 新生儿患者主索引的优化与探索
综合考虑了信息项的类型划分、易获取性和历史数据的完整度,本文整理出新生儿EMPI 可以用到的信息项如表2所示。
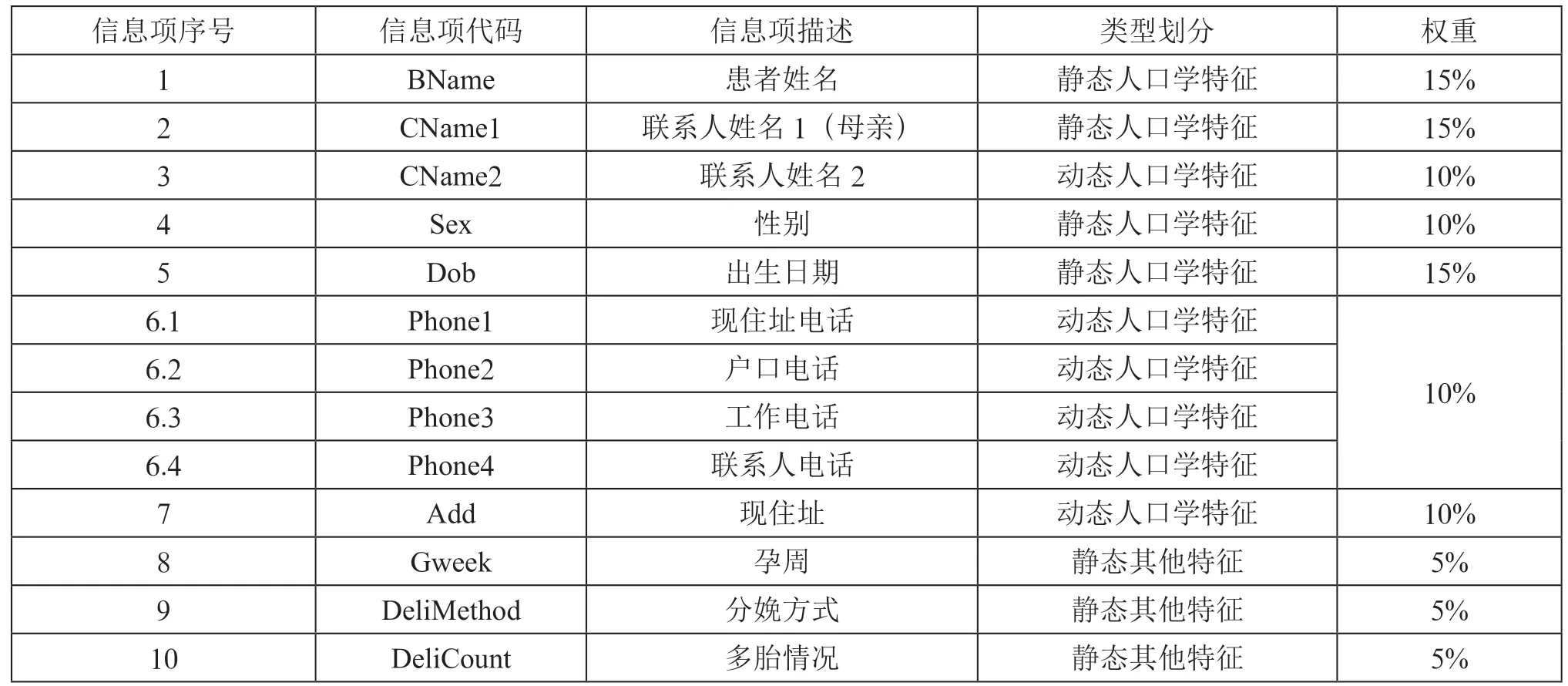
表2 新生儿EMPI 所用关键信息项
表2中13 个信息项包含静态人口学特征4 个,动态人口学特征5 个,以及静态其他特征3 个。权重大小分配大致符合静态人口学特征>=动态人口学特征>=静态其他特征规律。其中,联系人姓名1 是患儿母亲(生母)的姓名,联系人姓名2 是联系人中不确定是否为母亲的联系人姓名,将它们区分开是为了给母亲姓名更高的权重。此外,4 个电话综合看作同一个信息项,两组患者信息中所有电话交叉比较,两组中任有一对电话相同这个信息项的相似度就是1,占整体相似度的10%;若完全没有电话相同,这个信息项的相似度就是0。
这些信息项都非常容易获得,不论是将来患儿再次就诊时由家属提供,还是从历史数据中提取都可行。患者姓名、性别、出生日期、联系人姓名、电话、现住址作为患者注册时必填的基本项目,其历史数据和未来录入的数据都有一定的数据质量保证。产科新生儿可以通过分娩登记表关联到母亲作为联系人姓名1。从2019年开始,我院逐步提升未成年患者信息表中保存母亲的患者标识号的比例,通过母亲的患者标识号也可以准确地获得母亲姓名。此外,孕周、分娩方式和多胎情况作为婴儿出生时产生的关键信息,大多数患儿家属能够快速提供,可以考虑纳入注册基本信息由家属填写或选择。历史数据中的孕周、分娩方式和多胎情况可以从分娩登记表和电子病历个人史、现病史中进行提取和整理。
2.1 数据准备与采集
本文选取了2019年至2021年在我院产科出生的所有婴儿患者的信息63 043 条设为集合、我院产科出生后去了新生儿科但是患者标识改变了的患者的信息11 891 条设为集合(新生儿科电子病历上个人史中包含患者出生医院,以此筛选我院产科出生的患者),使用Kettle 工具从电子病历和病案系统中提取这些患者标识对应的含上述13 个信息项的原始内容,导入中间库Oracle 进行后续处理。采用电子病历和病案系统为数据源的原因是:病案系统会在患者出院后对电子病历进行迁出和归档,归档后电子病历中的数据不再发生变化,相当于关键信息项的一个信息快照。电子病历数据示例如表3、表4所示。

表3 产科电子病历数据示例
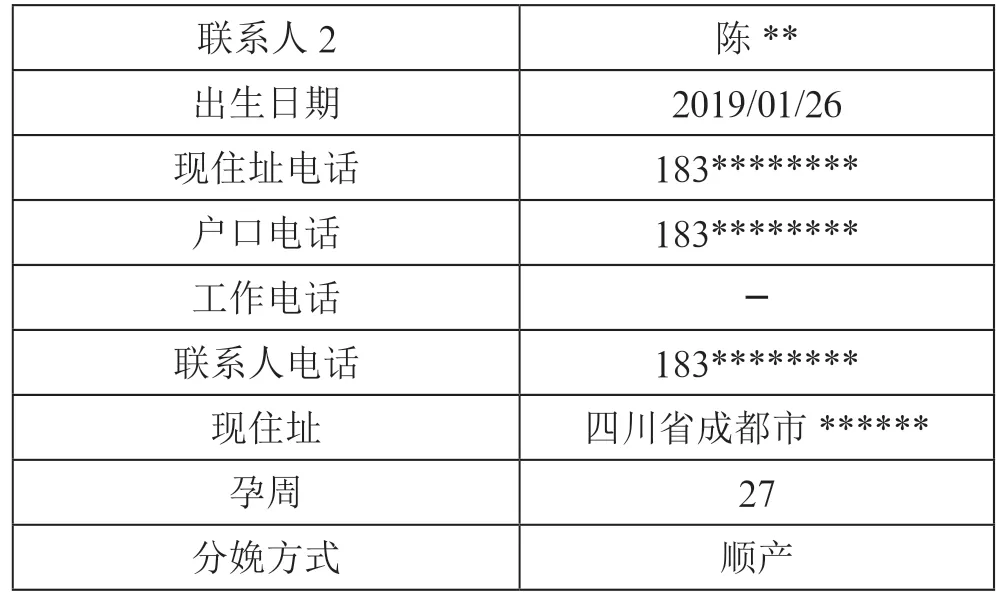
联系人2陈**出生日期2019/01/26现住址电话183********户口电话183********工作电话-联系人电话183********现住址四川省成都市******孕周27分娩方式顺产
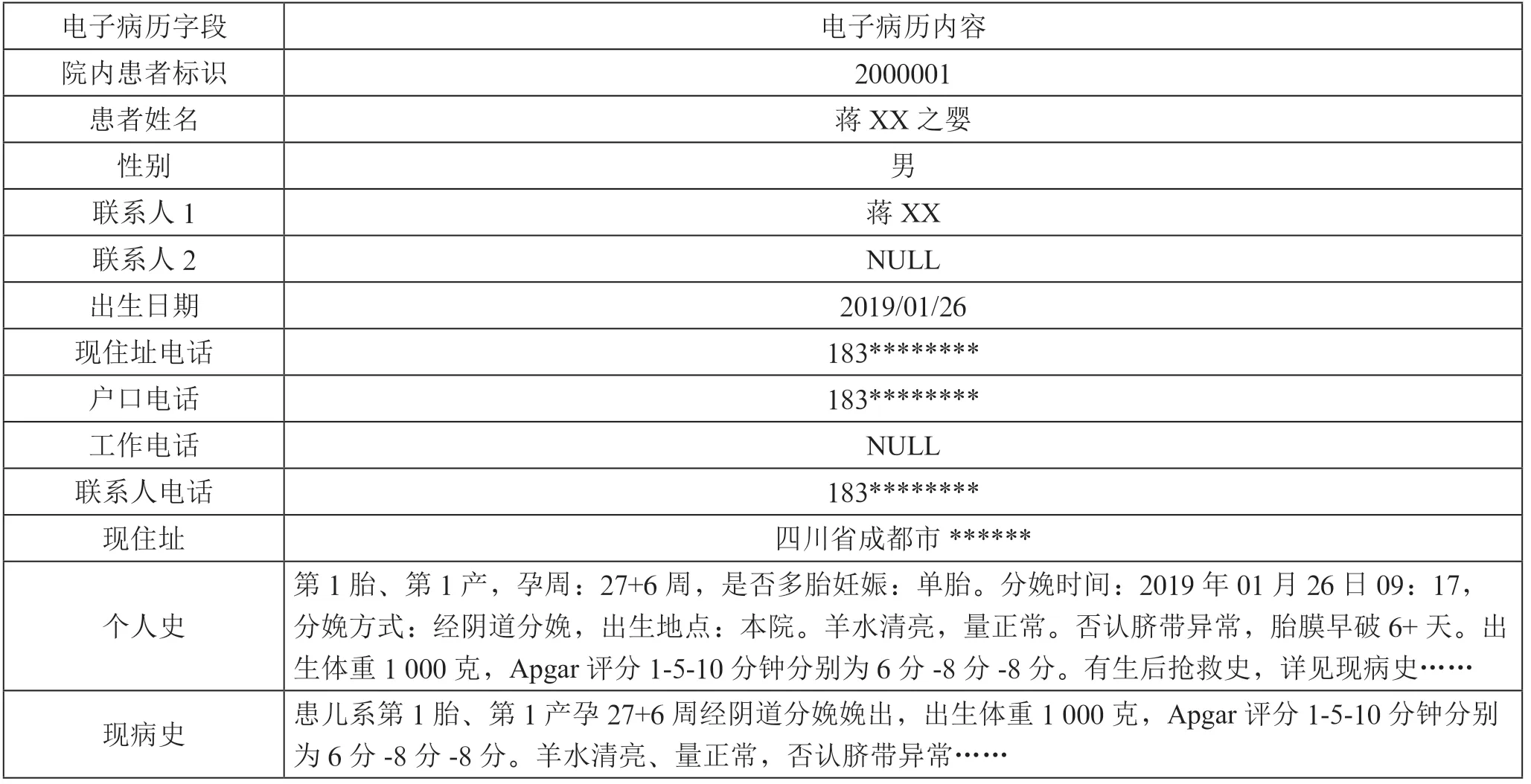
表4 新生儿科电子病历数据示例
2.2 数据处理
观察表3表4,会发现产科、新生儿科电子病历的原始内容无法直接进行匹配,需要先进行处理才能成标准的13个信息项才可以使用。处理的过程包括数据解析、数据清洗、整合与去重、统一值域等。
数据解析:产科电子病历数据与目标数据结构基本一样,但是新生儿科电子病历数据需要从个人史和现病史中拆分出孕周和分娩方式。本文用到的文字解析方法是关键词划分,比如再个人史中通过截取“孕周”和第N 个“周”之间的字符,然后通过正则表达式判断需要的部分,删除不需要的部分,来得出最终的孕周数字“27”。对于更复杂的情况,可以借助NLP 工具来进行处理。
数据清洗:数据清洗的过程可能不止一次,依据数据的情况而定。比如人名、电话、地址中也存在无效字符、多余空格等问题,这些可以使用SQL 查询脚本进行去除与置空。
整合与去重:每个新生儿的产科出生病历只有一份,但是一些新生儿可能会有多次新生儿科的就诊。对于同个院内患者标识的新生儿病历数据只需要整理出一份最全的目标信息项即可。
统一值域:已表3表4为例,新生儿科记录分娩方式为经阴道分娩,但是在产科记录的是顺产,其实是同种分娩方式的不同表达。两组数据的分娩方式需要先转换成同一个标准值域才能进行匹配。
2.3 相似度计算与模型评价
数据处理完毕后,本实验使用上文提到的相似度计算公式计算每一条记录的相似度值Sim(,),其中∈,∈。接下来设置阈值,在不同阈值下匹配出结果,结果会存在下述两类错误。
第一类错误概率:在集合中没有匹配到对应的,即我院产科出生的新生儿科患者匹配不到其在产科创建的患者信息的概率。
第二类错误概率:在集合中匹配到的实际上不是同一人的概率,即匹配结果错误的概率。
实验采用5%的间隔逐步升高阈值,匹配出结果,计算出第一类错误,然后按照1%的比例随机抽取匹配结果,通过人工核对婴儿电子病历信息、婴儿脚掌印等方式去判断匹配结果是否正确,计算出第二类错误的概率。然后根据不同阈值所对应的第一类错误概率和第二类错误概率绘出模型效果评价图如图1所示。

图1 模型效果评价
观察图片得知第一类错误与第二类错误此消彼长,当阈值在45%时,两者相较达到平衡,此时第一类错误和第二类错误分别为4.07%和3.03%,满足大多数统计分析的显著性要求。此结果可以运用在科研分析平台中,对历史数据进行有效整合,提高医疗健康档案的连续性和完整性。
2.4 补充:非单胎新生儿的区分

表5 非单胎新生儿的区分信息项
对于双胞胎,三胞胎和高序多胎的同性别新生儿患者而言,只依据1 至10 的信息项无法区分出生顺序,而出生序号在新生儿科的记录中缺失较为严重或者难以提取。出生体重和出生体长可以较为容易地从产科分娩登记表、新生儿科电子病历中获取,完整度优于只有产科才会详细记录的出身序号,所以可以利用这两项静态数值信息项用于非单胎新生儿的二次匹配,以此区分患儿个体。对于无法判断出生序号的多胎新生儿科患者,可以先完成第一步匹配,标准化出生体重和出生体长后再计算欧式距离,欧式距离越小说明更有可能是同一个人。
3 结 论
本文针对新生儿患者身份信息在传统EMPI 平台中无法有效整合的弊端,给出了新生儿患者主索引的构建方案。通过重构新生儿EMPI 平台用于计算相似度的信息项和权重值来计算新生儿患者之间的相似度,对于达到相似度阈值的患儿进行合并。利用出生体重和身长,进行二次相似度匹配,区分出非单胎患儿的不同个体。让新生儿患者在不同科室、不同阶段、不同业务中的临床数据构成一份连续完整的医疗健康档案,为母婴临床数据的区域共享与医学研究打下坚实的数据基础。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18 05:52:42
艺术品鉴(2020年11期)2020-12-28 01:36:56
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
家庭医学(下半月)(2019年8期)2019-09-25 09:02:00
下一代英才(酷炫少年)(2018年4期)2018-04-28 08:29:31
妈妈宝宝(2017年4期)2017-02-25 07:01:36
妈妈宝宝(2017年3期)2017-02-21 01:22:34
妈妈宝宝(2017年2期)2017-02-21 01:21:28
中国卫生(2016年10期)2016-11-13 01:07:44
中国卫生(2015年10期)2015-11-10 03:14:32
