
基于强化学习补偿的地面无人战车行进间跟瞄自适应控制
2022-08-27 09:39魏连震龚建伟陈慧岩李子睿龚乘
兵工学报 2022年8期
魏连震, 龚建伟, 陈慧岩, 李子睿,3, 龚乘
(1.北京理工大学 机械与车辆学院, 北京 100081; 2.北京理工大学 长三角研究院, 浙江 嘉兴 314019;3.代尔夫特理工大学 交通与规划系, 荷兰 代尔夫特 2628 CN)
0 引言
现代局部战争的实践反复证明,高新技术已经成为现代战争的制胜因素。随着自主智能、网络协同、云处理等高新技术的发展,作战模式正在发生重要转变,以地面无人战车为代表的无人作战系统能够执行多种特殊任务,是应对未来不确定形势的重要突破口,具有广泛的应用前景。
在执行打击任务时,地面无人战车通常可采取静态射击与行进间射击两种作战方式。相比静态射击的作战方式,行进间射击能够缩短任务完成时间以提升作战效率,降低被反装甲武器命中的概率从而提升战场生存能力,是地面无人战车未来发展的重要方向。行进间射击的关键技术之一是跟瞄镜对目标准确、稳定地跟瞄。现代坦克主流采用稳像式火控系统:火炮与瞄准镜分别稳定,瞄准镜对目标实时跟瞄并调动火炮,火控计算机根据跟瞄角速度、目标距离、炮弹弹种、风速等值计算射击诸元以实现射击。然而,无论跟瞄系统处于稳像状态还是自动跟踪状态,底盘运动和路面起伏都会对瞄准带来平移误差,这给跟瞄控制系统带来了挑战。
为提升战车行进间跟瞄的准确性与稳定性,不同研究人员提出了各自的技术方案。如钟洲等建立了车载防空导弹的行进和发射一体化多柔性体动力学模型,并分析了路面和车速对防空导弹行进间发射精度的影响,但仅重点关注动力学模型的创建与分析,并未给出合适的控制方法。慕巍等利用光电跟踪仪、火炮、载体惯导系统、视频跟踪器和激光测距机输出的相关参数,完成瞄准线坐标系下方位速度环和俯仰速度环跟踪前馈补偿参数的计算,以提升对高速目标跟瞄控制的准确性。熊珍凯等针对机动快速目标的跟踪问题,采用基于当前统计模型的改进卡尔曼滤波算法预测出目标运动状态参数,并采用自适应滑模的解算控制方法,实现伺服系统的位置控制,提升跟瞄精度。这些方法没有涉及本车运动状态的分析,在动对静、动对动场景受限。郝强等采集目标距离、火炮相对车体角度和车体速度等信息,循环解算瞄准线的补偿角速度,减小了跟瞄误差。但是,该方法仅考虑底盘速度影响,忽略了路面起伏影响,在地形复杂的越野场景中跟瞄补偿的效果不佳。张卫民等以自行火炮与敌遭遇时紧急直瞄场景为研究对象,提出一种自行火炮自动直瞄控制方法,以提高火炮直瞄时快速反应能力和射击精度。然而,该方法侧重于瞄准的快速性,没有充分考虑各种非线性干扰对瞄准稳定性的影响。朱斌等考虑系统内部扰动和外部扰动对稳瞄系统速度跟踪精度的影响,提出了采用自抗扰的控制方案。不过,该方法侧重于稳定性,仍然没有有效消除底盘运动与路面起伏因素带来的瞄准线平移误差。
针对跟瞄控制存在的上述问题,本文从整车角度进行研究,提出一种基于强化学习补偿的地面无人战车行进间跟瞄自适应控制方法。将感知模块感知得到的地形信息与规划模块规划得到的未来轨迹传输至上装跟瞄控制模块,上装跟瞄控制模块利用Dueling 深度Q网络(DQN)强化学习算法对这些信息处理后得到补偿控制量,以削弱底盘运动与路面起伏对跟瞄的影响,提升战车跟瞄的准确性与稳定性。首先建立地面无人战车一体化运动学模型,之后对补偿控制方法进行细节性描述,最后利用仿真实验证明方法的有效性。
1 系统模型
针对地面无人战车行进间跟瞄自适应控制问题,提出问题场景模型、地面无人战车一体化运动学模型以及强化学习模型。
1.1 问题场景描述
地面无人战车行进间跟瞄平面示意如图1所示。无人战车接收上级指挥端下发的打击任务,从起点位置规划战车的运动轨迹,而后自主跟踪运动轨迹并且实时搜索打击目标,跟瞄系统对可疑目标识别并在自动跟踪状态对其瞄准。跟瞄控制的目标是迅速、准确、稳定地减小跟瞄镜与打击目标随动角度误差。
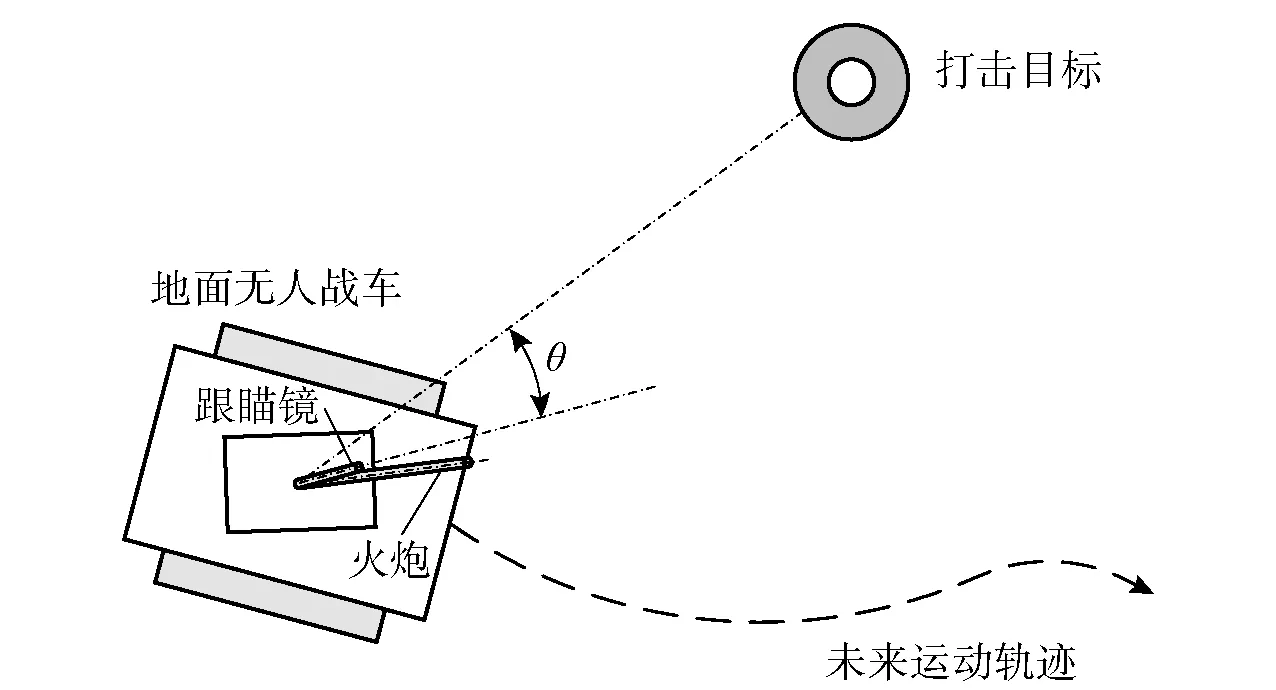
图1 问题场景描述Fig.1 Problem scenario description
1.2 地面无人战车一体化运动学模型
地面无人战车采用履带式移动底盘,可通过调节左、右两侧主动轮的转速或转矩控制整车航向和速度。战车配备无人炮塔,其中升降式搜索镜用于识别周围可疑目标,跟瞄镜对搜索到的敌方目标实时跟瞄,火炮随动,而后火控计算机计算射击诸元,控制火炮在阈值内完成射击。考虑战车底盘的平移、俯仰、横摆、侧倾等会对上装跟瞄与打击模块产生影响,基于履带式无人车运动学模型, 推导出右手坐标系的地面无人战车底盘与上装一体化运动学模型,如图2所示。
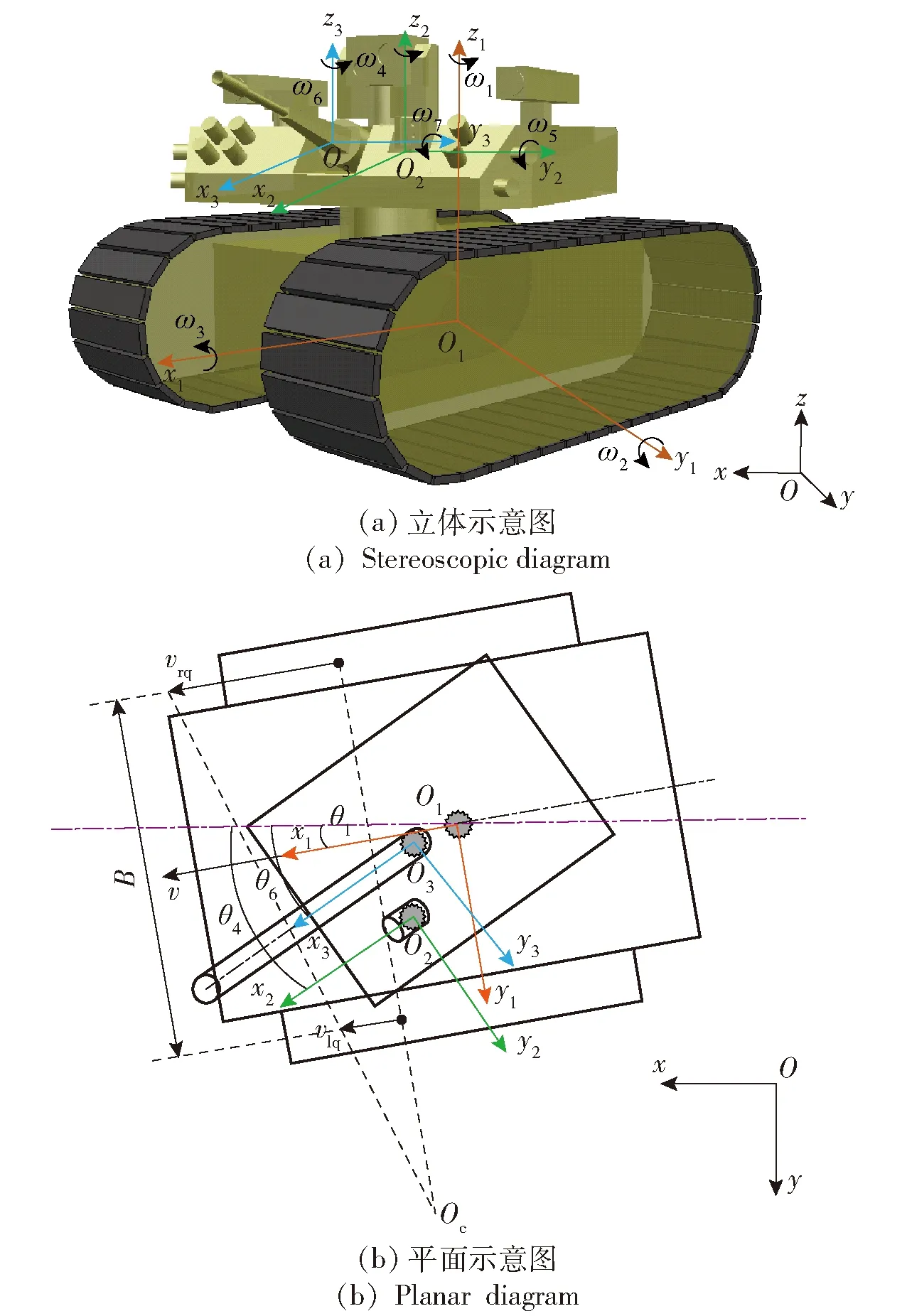
图2 地面无人战车一体化运动学模型Fig.2 Integrated kinematics model of unmanned combat ground vehicle
图2中,为世界坐标系,为底盘坐标系,为跟瞄坐标系,为火炮坐标系。如2(a)中同时给出了可旋转方向,记代表底盘在世界坐标系中的横摆角速度,代表底盘在世界坐标系中的俯仰角速度,代表底盘在世界坐标系中的侧倾角速度,代表跟瞄镜在底盘坐标系中的方位角速度,代表跟瞄镜在底盘坐标系中的高低角速度,代表火炮在底盘坐标系中的方位角速度,代表火炮在底盘坐标系中的高低角速度。图2(b)中、分别为左、右两侧履带或驱动轮的牵连速度,为底盘在世界坐标系中的横摆角,为跟瞄镜在世界坐标系中的方位角,为火炮在世界坐标系中的方位角,为战车底盘履带中心距,为底盘瞬时转向中心,为底盘运动速度。
由于差速转向战车在转向时,两侧履带或驱动轮不可避免地会发生滑移滑转,定义左右两侧的滑移滑转系数分别为

(1)
式中:、分别为左、右两侧履带或驱动轮相对于车体的卷绕纵向线速度。考虑到滑转滑移,底盘的运动速度、横摆角速度分别为
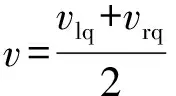
(2)
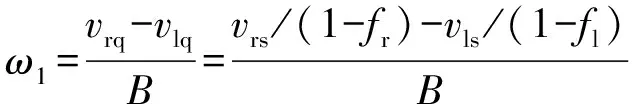
(3)
由上述定义与推导,可得地面无人战车的数学模型为

(4)
式中:、、、分别为底盘在世界坐标系中的俯仰角、侧倾角、跟瞄镜在世界坐标系中的高低角以及火炮在世界坐标系中的高低角。
1.3 强化学习模型
强化学习是机器学习的一个重要分支,它模拟的是生物学中的行为主义,即自然界中的生物体在一定的正向或负向刺激下,通过不断学习形成一套应对刺激的策略,从而实现自身利益最大化。强化学习任务通常利用马尔可夫决策过程(MDP)进行描述,它满足马尔可夫性质:系统下一时刻状态只与当前时刻状态有关,与过往时刻状态无关。MDP的基本组成是五元组(,,,,),其中为智能体在交互环境中的状态集,为智能体在交互环境中对应的动作集,为智能体的状态转移概率,为奖励的折现因子,为智能体在交互环境中采取特定动作的回报奖励。强化学习过程是智能体从初始状态开始,不断从动作集中选取动作进行状态的转移,之后利用奖赏函数对选取的动作进行评价从而更新参数直到累计奖励最大化的过程,核心思想是试错与学习,具体如图3所示。
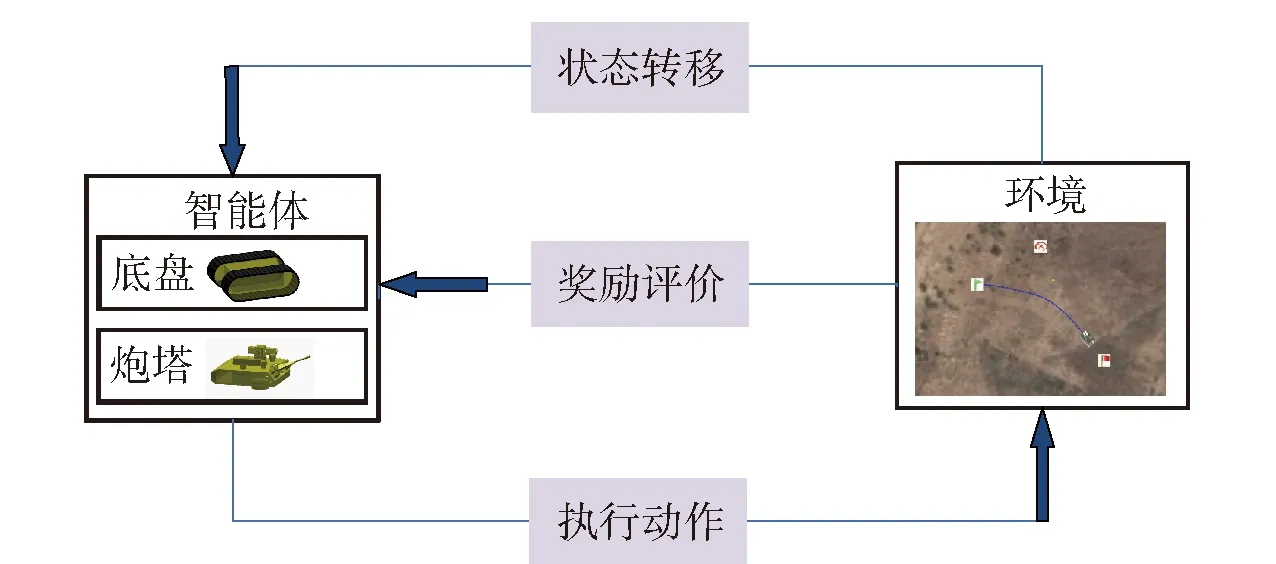
图3 强化学习过程Fig.3 Process of reinforcement learning
强化学习主体框架包括智能体、环境、动作、奖励4个内容。本文主要涉及地面无人战车跟瞄控制方法:由强化学习控制的智能体为地面无人战车的炮塔;环境指代的是战车周围态势;动作指代的是炮塔方位角控制量、炮塔高低角控制量;奖励指代的是人为设定的奖赏函数。通过奖赏函数的奖赏值引导智能体进行学习,下面阐述了强化学习模型的基本要素:
1)累积奖励。智能体每次执行动作后系统都会对该步操作进行评价,该评价值是单步奖励,累积奖励是智能体在一个回合之后所有动作单步奖励的折扣加权和,如(5)式所示:
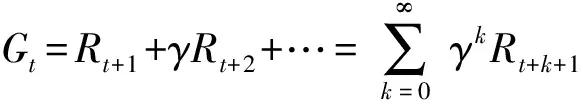
(5)
式中:代表时刻后开始的累积奖励;+1代表+1时刻的单步奖励。需要注意的是:累积奖赏实际上是一个随机变量,对它求期望可以得到价值函数。
2)策略。策略代表智能体在每种状态下执行某种动作的概率,是状态空间到动作空间的映射,如(6)式所示:
(|)=[=|=]
(6)
式中:(|)为状态时执行动作的概率;为时刻可选动作集;为时刻状态集。
3)状态价值函数。为评价智能体所在状态的优劣,需获得智能体从当前状态转移到结束状态的累积奖励,在当前状态下按照一个固定策略求得的累积奖励期望是状态价值函数,如(7)式所示:
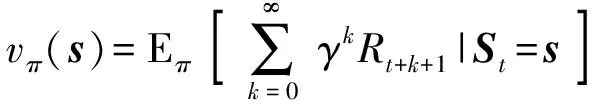
(7)
4)动作价值函数。在当前状态下执行某个动作后按照某固定策略求得的累积奖励期望即是动作价值函数,如(8)式所示:

(8)
5)贝尔曼方程。贝尔曼方程是将多层决策转化为多个决策的动态规划过程,根据迭代公式求解状态价值函数与动作价值函数,状态价值函数与动作价值函数对应的贝尔曼方程分别为

(9)
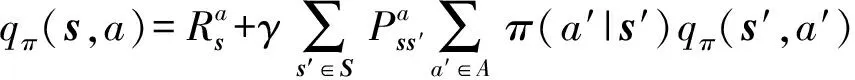
(10)

2 控制方法
跟瞄控制问题的核心在于跟瞄系统能够快速、准确、稳定地对目标实时瞄准,其难点在于目标点运动、己方战车运动、路面起伏等因素带来的非线性干扰。针对此,本文提出一种基于强化学习补偿的地面无人战车跟瞄控制方法,以减小跟瞄误差,提升跟瞄性能。
控制方法架构如图4所示。PID控制器根据当前跟瞄偏差得到主控制量;Dueling DQN控制器将底盘局部规划路径点与目标的相对位置、局部规划路径点附近的起伏梯度、车辆运动速度、当前跟瞄误差等信息作为输入,利用神经网络处理得到补偿控制量;主控制量与补偿控制量加权之和为最终控制量,共包括方位控制量与高低控制量两个输出。主控制量保证跟瞄的大致方向性,补偿控制量用于对主控制量进行修正,从而提升地面无人战车行进间跟瞄对底盘速度变化以及路面起伏的自适应能力。需要说明的是:该控制方法得到的控制量是跟瞄系统下一时刻相对转动的角度增量,并非底层的转矩控制量。本文中强化学习算法的学习机制与网络结构能够针对复杂动态信息分析和处理,并且具备持续学习效果,随着训练次数的增多,跟瞄效果的准确性与稳定性可逐步提升。图4中,、分别为方位角度偏差值与高低角度偏差值,、、、、、分别为方位角和高低角对应的比例、积分、微分权重系数,是方位角增量,是高低角增量。

图4 基于强化学习的补偿控制方法架构图Fig.4 Framework of compensation control method based on reinforcement Learning
战车对目标的实时跟瞄偏差角度值可以由目标在跟瞄坐标系中位置求解得到,角度计算如(11)式所示:

(11)
式中:、、代表跟瞄目标在世界坐标系中坐标;、、代表车辆跟瞄镜在世界坐标系中坐标。
最终的控制量(当前控制时刻相对于上一控制时刻,其跟瞄方位角度增量与跟瞄高低角度增量)的数学表达如(12)式所示:
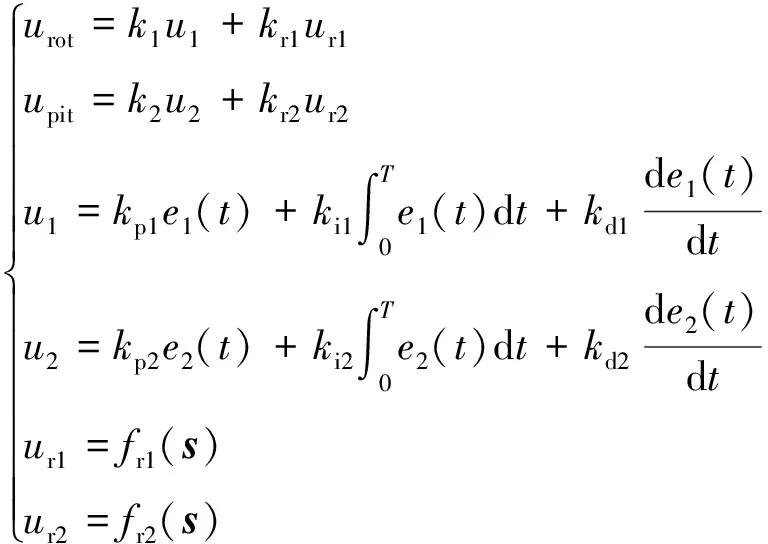
(12)
式中:、分别为方位角和高低角主控制量权重系数;、分别为方位角和高低角主控制量;、分别为方位角和高低角补偿控制量权重系数;、分别为方位角和高低角补偿控制量;代表积分时间;r()、()分别为强化学习神经网络拟合的方位角和高低角非线性函数。
本文采用的强化学习算法参考了Dueling DQN算法思路,它属于值迭代算法的一种,是基于传统DQN算法的一种改进算法,如图5所示。图5中,()代表第条数据对应的误差值,代表一次性处理的数据条数。

图5 强化学习算法思路图Fig.5 Algorithm diagram of reinforcement learning
图5中,估计网络与目标网络在网络结构上一致,区别在于估计网络实时更新参数,目标网络非实时更新,算法值计算如(13)式所示:

(13)
式中:(|,) 为状态值函数,用于衡量状态价值,仅与状态有关,为公有网络参数,为状态值函数特有网络参数;(,|,)是动作优势函数,用于衡量不同动作相对于所处状态的价值,同时与状态以及动作有关,是动作优势函数特有网络参数;为离散动作空间元素个数。
本文中使用的神经网络结构如图6所示,其中方位角度补偿控制网络与高低角度补偿控制网络类似,区别在于神经网络的输入信息、输出信息以及神经元个数。方位角度补偿控制网络的输入为底盘局部规划路径点与目标的相对位置、左右履带速度、方位跟瞄误差;高低角度补偿控制网络的输入为局部规划路径点附近的起伏梯度、左右履带速度、高低跟瞄误差。其中,路径附近起伏梯度指的是“一定数目的未来路径点以及对应的左右偏移路径点集合”前后相邻点之间高度差值构成的矩阵。输入信息先经过若干层全连接层,之后分为状态值网络以及动作值网络,最后得到每种动作对应的值。此外,本文对部分全连接层进行了处理,即在训练阶段随机将部分神经元丢弃从而削弱训练中的发生过拟合现象。

图6 Dueing DQN神经网络结构图Fig.6 Structure of Dueing DQN neural network
程序训练过程:先随机探索一定步数以获得多组数据并将其存储在经验池中,每一次从经验池中抽出若干条数据并不断更新网络参数值,直至模型满足要求或训练次数达到阈值。Dueling DQN算法是通过最小化时序差分误差实现网络更新,其数学表达如(14)式所示:
=(+max′′(′,′|′,′,′)-
(,|,,))
(14)
式中:′代表下一状态的目标值。因实际进行参数更新是同时对若干条数据进行处理,平均后的误差值如(15)式所示:

(15)
利用TD误差对网络参数的更新原理是借助梯度下降算法,本文在实验时采用了Adam优化器实现参数梯度下降,相比传统的随机梯度下降算法能够更快地实现参数收敛。
3 仿真实验与结果分析
3.1 V-REP三维仿真实验设置
底盘运动是影响地面无人战车行进间跟瞄误差的一个重要非线性干扰,当速度大小或者速度方向发生变化时会对跟瞄的稳定性产生影响,即使战车保持匀速直线运动,也会对战车跟瞄带来瞄准线的平移。路面起伏是影响地面无人战车行进间跟瞄误差的另一个重要非线性干扰因素。基于单独PID控制的跟瞄算法不能对战车未来阶段的起伏信息进行预判,这种被动跟随控制策略在起伏路面时跟瞄效果不佳;并且,由于路面起伏的复杂性,传统的前馈补偿方法难以针对性开展设计。本章基于V-REP动力学仿真软件进行强化学习网络参数训练与测试,通过观察训练过程中奖赏值的上升和对比单独PID控制方法与补偿控制方法跟瞄误差角数值来验证本文提出的补偿控制方法有效性,仿真实验流程如图7所示,仿真软硬件环境如表1所示。
图7 仿真实验流程图Fig.7 Flow chart of simulation

表1 仿真软硬件环境
为在V-REP动力学软件中搭建路面起伏环境,采用Perlin噪声算法构建近似于自然环境的起伏路面,并将地形文件、车辆模型、打击目标导入V-REP仿真软件,再利用ROS接口实现与程序端的通信,最终完成起伏路面仿真环境搭建,如图8所示。仿真中设定车辆运动速度为15 km/h,方位角速度阈值为40°/s,高低角速度阈值为40°/s。设计两个强化学习神经网络分别对方位角与高低角进行补偿控制,强化学习的基本信息如表2所示。

图8 三维仿真环境搭建过程Fig.8 Construction process of 3D simulation environment

表2 强化学习基本设置
3.2 实验结果分析
由表2可以看出,奖赏函数是关于目标跟瞄角误差值的二次函数,当误差角越小时对应的奖赏值越大,因此可通过观察训练过程中奖赏值变化分析跟瞄效果。图9绘制出了无人战车从起始位置自主运动到目标位置的前500次训练过程中高低角网络平均奖赏值的变化情况,为便于观察进行了均值滤波。由图9看出:随着训练次数地增多,平均奖赏值呈现整体上升的趋势,这代表Dueling DQN控制器对于跟瞄误差补偿效果随着训练增多而提升。

图9 平均奖赏值变化图Fig.9 Variation diagram of average reward values
地面无人战车在从起点位置到终点位置的运行中,不同跟瞄控制方法对应的跟瞄角度误差均值能够反映控制效果的好坏。
将战车从跟瞄稳定位置到终点位置运动过程中上装跟瞄角度误差的变化情况进行记录,并对比基于PID控制与强化学习补偿控制两种方法的跟瞄角度误差变化情况,对比结果如图10所示,其中图10(a)为方位角度误差变化,图10(b)为高低角度误差变化。由图10可知:基于强化学习补偿的控制方法平均跟瞄误差明显更小,控制效果更优。

图10 跟瞄角误差变化图Fig.10 Variation diagram of tracking/aiming error
4 结论
本文提出一种基于强化学习补偿的地面无人战车行进间跟瞄自适应控制方法,有效地提升了地面无人战车的动态作战性能。首先建立地面无人战车一体化运动学模型以及强化学习模型,然后具体介绍了基于强化学习补偿的跟瞄控制方法架构,最后基于V-REP动力学仿真软件进行了控制方法效果对比,得出结论:强化学习补偿能够较好地削弱速底盘运动以及路面起伏对上装跟瞄的非线性干扰。不过,目前的工作仍是初步的:1)在跟瞄系统建模方面采用了简单运动学模型,后续会针对该模型进行完善并深入分析底盘运动与路面起伏对跟瞄性能的影响特性;2)后续将补充开展与上装载荷任务相协同的底盘运动规划研究。
猜你喜欢
军事文摘(2022年17期)2022-09-24
小哥白尼(军事科学)(2022年4期)2022-07-08
导航定位学报(2022年2期)2022-04-11
语数外学习·高中版中旬(2021年11期)2021-02-14
考试周刊(2018年15期)2018-01-21
中学生数理化·七年级数学人教版(2017年4期)2017-07-08
中学生数理化·七年级数学人教版(2017年1期)2017-03-25
科技创新与应用(2016年9期)2016-05-14
数学大王·中高年级(2015年3期)2015-07-31
光学仪器(2014年6期)2015-01-22
