
一种轴承核密度估计的剩余寿命预测研究
2022-08-26 07:58武冲锋
机电工程技术 2022年7期
武冲锋
(晋能控股阳泉固庄煤业有限公司,山西阳泉 045060)
0 引言
随着机械设备不断向智能化和精密化方向发展,轴承作为机械设备的关键部件,其性能退化直接影响整个设备的性能[1-4]。为此,对轴承进行实时监测和剩余寿命预测有着十分重要的研究价值和意义。现研究阶段可将剩余寿命预测的方法大致分为基于物理失效模型、基于知识表示和数据驱动的方法[5]。面对复杂的设备,获得物理模型是很困难的,知识表示方法更适合定性推理,不太适合定量计算,而且很难获得完整的知识。然而,数据驱动的预测方法,通过对轴承性能数据的描述,提取有用的信息并预测剩余寿命[6]。Si等[7]将数据驱动方法的伽马分布、回归模型、Wiener过程和随机滤波模型[8]等RUL模型进行总结分析。Pei等[9]提出双时间尺度的随机退化设备的非线性退化模型。Zhai等[10]提出基于高阶隐半马尔科夫模型的剩余寿命预测模型。上述数据驱动的方法大多需要假设退化模型和参数估计,而参数估计方法在模型选择上存在局限性,过分依赖概率密度函数形式的先验定义,因此不能保证预测模型的准确性和适用性。
本文提出一种轴承核密度估计的非参数剩余寿命预测模型,该方法不对数据分布附加任何假设,而是从数据本身研究数据分布的特点,避免了大多数数据驱动方法需要模型假设和参数估计的问题。该模型在核估计窗宽的选取上引入局部窗宽因子构建自适应窗宽模型。模型通过计算样本点的密度来自适应选择样本点窗宽,提高了核密度估计窗宽选择的可靠性,从而提高了预测精度。最后通过轴承磨损试验验证了所提模型的适应性和准确性。
1 核密度估计模型的构建
核密度估计方法不利用数据分布的先验知识,不对数据分布进行假设,它是一种用于从数据本身估计未知变量的概率密度函数的方法[11-12]。其由已知的N个样本点,通过选择任意核函数及窗宽得到N个核函数,通过线性叠加得到核密度的估计函数。设Δx1,Δx2,…,Δx n为n个独立且同分布的退化样本,f(Δx)为其服从十五概率密度函数,则核密度估计的概率密度函数f^(Δx)表示为:

式中:h为窗宽;K(·)为核函数;n为样本数。
其中,K(·)和h选用的恰当与否决定了核估计的准确度高低。核函数作为影响核密度估计的一个因素,一般情况下任何函数都可作为核函数,常用的有四次核、均匀核、三角核和高斯核。核函数的选择虽多,但对核密度估计的准确度作用不大。本文选用广泛应用的高斯核函数。即:

窗宽h作为影响核密度估计平滑性和核函数宽度的主要因素,当h较小时,核密度估计曲线不平滑且曲折,揭示了更多细节;当h较大时,核密度估计曲线平滑,但会覆盖更多的细节。因此,选择合适的窗宽对核密度估计是非常重要的。
2 自适应窗宽模型建立
目前自适应窗宽是窗宽选择的主流方向,其本质是随着样本点的增加能够自适应的选取窗宽,减少了计算量。在现有研究阶段常用的自适应窗宽方法大多采用的是通过式(3)积分均方误差求其最小值得到初始最优窗宽h n。

核密度估计模型中的初始最优窗宽h n,通过式(3)积分均方误差求其最小值点得到:

将高斯核函数代入式(4)可求出h n为:

式中:σn为n个初始样本特征退化增量的方差。
该窗宽方法解决了样本数据实时变化时选择窗宽和实际中固定窗宽造成的过度(不足)拟合问题。如果样本分布是近似正态的,这种方法是最佳选择。然而,当样本分布不对称或有多个峰值时,该方法会导致过度平滑,精度需要提高。
然而,在实时监测轴承的核密度估计过程中,为了提高窗宽对真实样本数据分布的适应性,引入了一个反映基于最优窗宽h n的样本点分散度的函数λi来自适应选择窗宽。λi可通过式(6)各个样本点处的概率密度得到:

将函数λi与式(5)计算出窗宽h n相乘可得自适应窗宽h i:

从而使得不同样本的窗宽可以根据样本数据的稀疏程度进行自适应调整,以更好地满足实践中核密度估计的需要。
因此,将自适应窗宽h(Δx i)方法引入核密度估计的模型中,从而构建自适应核密度估计的表达式为:

由于在实际应用中样本数据都是实时更新的,如果每增加一个样本都对其从头开始计算,那么计算量会随数据的增多变得复杂化。所以,为使核估计的计算性能得到提升,通过用已知的n个样本的核估计推导第n+1个样本的核密度估计,来实现核密度估计的实时更新。
3 实时剩余寿命
3.1 特征退化分布的计算
假设t n为轴承退化状态时间,可得到[0,t n]时间内所有退化样本的特征退化随时间变化的趋势可由图1所示。为使设备的剩余寿命预测准确,由核密度估计可得[0,t n]随机退化增量的概率密度,推出[0,t n]上随机退化增量累计特征退化量的,可由n重卷积得到:
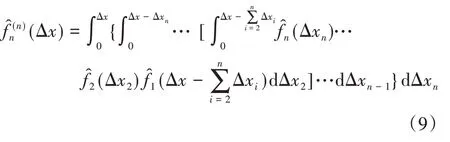
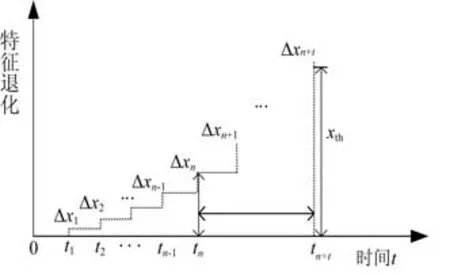
图1 样本特征退化随时间变化的曲线
3.2 剩余寿命预测模型
设t n+t时刻,特征退化量达到(图1)时轴承失效。剩余寿命预测的实现,要对当前t n时刻的剩余寿命预测,通过初始时刻到当前t n时刻的退化量(记,推出t n+t时刻的。设T为设备的剩余寿命,则剩余寿命的概率密度分布函数F T(t)为:

其中,[0,t n+t]特征退化量的概率密度为:

剩余寿命预测的概率密度为:

从而能够推出t n时刻剩余寿命的概率密度函数为:

随着实时监测的进行,监测的样本数量不断增加,样本的核密度估计也不断更新。当使用非实时寿命预测模型时,基于这些样本的核密度估计必须为每一个新的样本数据重新计算,这导致历史样本不断被重新计算,计算量越来越大。为避免实时监测系统中样本核密度估计的重复计算问题,提出了一种递推核密度估计模型的实时更新算法,并对模型的特征退化分布和剩余寿命进行了连续的实时更新。
4 实例分析
本文使用IEEE PHM2012提供的全寿命轴承数据对该模型进行了验证。该数据来自于FEMTO-ST研究中心的PRONOSTIA试验台的加速轴承寿命测试,振动信号的采样频率为25.6 kHz,采样时间为0.1 s,采样间隔为10 s,即每次获得2 560个数据样本。本文以Bearing 1-5在1 800 r/min和4 000 N载荷下的全寿命振动数据为例。在轴承故障诊断中,均方根(RMS)在实践中被广泛使用,因为它能更好地将轴承的退化状态反映出来。图2所示给出在时间变化下轴承的均方根特征退化趋势。从图中可看出均方根值基本上呈现出随时间单调上升的趋势,可以将轴承的退化趋势很好地展现出来。该轴承在t=2.463×104s时出现故障,均方根的故障阈值为1.396 mm/s2。
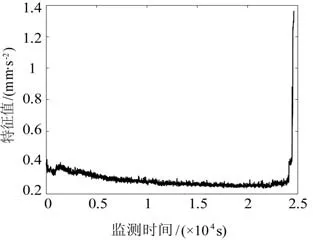
图2 特征值随监测时间的退化趋势
利用本文的模型预测轴承的剩余寿命,从图3可以看出,在轴承运行时间不断的变化下,接受到的样本数据逐渐越来越多,在核密度估计的剩余寿命模型不断的实时更新下,轴承的剩余寿命概率密度不断的增大且逐渐变窄,其方差也明显不断减小,可看出预测值与实际值相差不断减小,从而模型的准确性不断提高。

图3 不同监测时刻剩余寿命的概率密度
为了进一步评估所提方法的预测效果,表1所示为不同监测时间下实际剩余寿命和模型预测的平均剩余寿命的均方根误差(Root mean square error,RMSE)比较。从表中可看出,轴承在运行过程的实时预测下,预测值与真实值之间的RMSE在逐渐的减小,根据样本数据的增多,剩余寿命的预测值在不断的接近真实值,且误差也越来越小,从而可以验证本文模型对轴承寿命预测的有效性。

表1 不同时刻的剩余寿命均方根误差比较
为了能验证本文模型在轴承应用上的优越性,将本文模型与Wiener过程的剩余寿命预测模型进行比较,Wiener过程多用于对具有非单调退化过程的设备进行建模。在相同条件下对轴承的退化过程进行寿命预测,得到图4所示不同时刻下本文核密度估计模型与Wiener过程模型的剩余寿命预测值和真实值之间的比较。从图中可看出,本文模型的预测结果相比Wiener过程模型,更加接近真实寿命值,随着时间的变化预测的准确性不断提高,从而验证了本模型的适用性和精确性。

图4 不同时刻两模型剩余寿命值比较
5 结束语
本文提出了一种轴承核密度估计的非参数剩余寿命预测方法,以解决预测设备剩余寿命时在不同样本分布下核估计的窗宽不能准确选择的问题。在该方法中,通过引入局部密度因子来选择核估计的窗宽,构建了一个自适应窗宽模型。该模型根据样本点的密度自适应地选择窗宽值进行核密度估计,即较小的窗宽用于样本点密集区,而较大的窗宽用于样本点稀疏区。随着接收到的实时监测数据的实时更新,核密度估计也自适应地递归更新,从而避免每增加一个样本数据就要进行一次计算带来计算量复杂问题。实例分析表明,随着样本数据的增加,所提模型的轴承剩余寿命预测值越来越接近实际值,并于Wiener过程模型比较,验证了本文模型的准确性和有效性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
科技视界(2021年4期)2021-04-13
现代信息科技(2021年17期)2021-04-05
农业机械学报(2021年1期)2021-02-01
数学学习与研究(2020年15期)2020-11-28
河北建筑工程学院学报(2020年4期)2020-04-29
