
基于智能刷卡数据的地铁乘客分类研究
2022-08-26 09:54刘哲园孟品超
长春理工大学学报(自然科学版) 2022年2期
刘哲园,孟品超
(长春理工大学 数学与统计学院,长春 130022)
乘客分类是研究出行者群体相似性行为及规律的主要方法,乘客出行的个体特征主要体现在其本身的固有属性和出行链中,传统对乘客的分类大多基于乘客的自身属性,例如年龄、职业等,该分类的前提是相似个体属性的乘客具有相似出行行为,存在主观性较强等问题。智能卡刷卡数据(Smart Card Data,简称SCD)记录了丰富的用户出行时空信息,客观反映了乘客的出行特征,从中挖掘乘客出行轨迹信息并建立完整出行链,利用出行特征对乘客进行更准确的分类,分析不同群体的总体特征,推断该群体的出行目的,有助于政府和交通部门针对不同类别的用户,进行有针对性的调查以及各种运营和战略规划改进。
许多学者进行了基于SCD的用户出行轨迹数据的挖掘与乘客分类的研究。李军和邓红平[1]基于广州市公交车IC卡交易数据,利用出行链推导出乘客的下车站点,建立了描述单个乘客多天出行的完整数据框架。梁泉和林鹏飞等人[2]对北京市公共交通多源数据进行关联匹配,并提取出行链,采用多层规划理论构建了个体出行知识图谱,提取出行天数、出行空间均衡度等7类特征指标,以特征指标为输入,乘客分类为输出,构建了面向公共交通乘客分类的BP神经元网络模型。邹庆茹和赵鹏[3]以轨道交通自动售票数据为基础构建客观的分类指标,利用无监督聚类算法对乘客分类。Kieu L M和Bhaskar A[4]使用澳大利亚城市火车和渡轮的交易记录,基于密度的DBSCAN算法将乘客分为通勤乘客、出行起讫点稳定型、出行时间稳定型及不规律乘客四类。上述研究基于乘客出行链构建分类指标对乘客分类,均是将乘客全部出行特征放到一起考虑,没有对出行强度与时空特征分层次讨论。
鉴于以往研究中存在的不足,对地铁刷卡数据进行整理和挖掘,在建立用户出行链的基础上提取用户的个体出行特征,分层考虑出行强度与时空特征,利用二阶聚类算法实现乘客的分类,并分析不同群体的整体出行规律,识别乘客群体,框架流程图如图1所示。
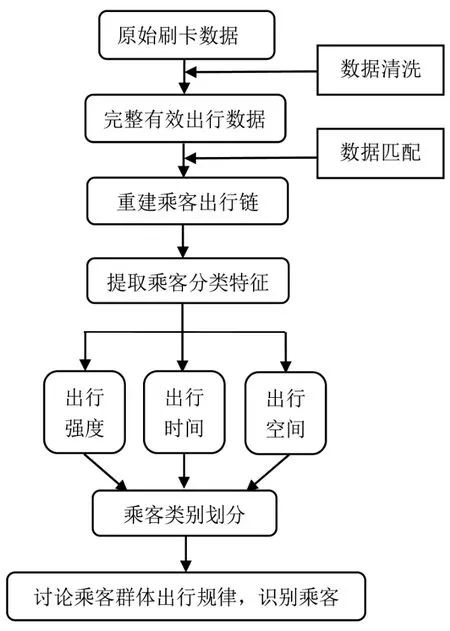
图1 框架流程图
1 地铁刷卡数据和分类指标选取
1.1 数据介绍和预处理
研究数据来源为杭州市2019年1月7日至11日五个工作日的地铁刷卡数据,五个工作日内有1 514 086位乘客进行了约1 000万次刷卡,每条刷卡数据包括以下字段:用户ID、刷卡时间、线路名称、站点编号、进出站状态(1代表进站,0代表出站)。
原始刷卡数据量庞大,存在一些不完整、时间不合理的记录,首先对数据进行清洗,得到完整有效的刷卡数据。数据清洗规则如下:
(1)根据同一卡号出现奇偶性来判断数据完整性,同一卡号出现奇数次说明持卡人刷卡数据不完整,删除该条记录。
(2)同一卡号出现偶数次,需要判断进出站刷卡时间和进出站顺序是否吻合,出站刷卡时间要晚于进站刷卡时间,否则为异常数据,删除该条记录。
(3)计算进出站刷卡时间间隔,删除进出站刷卡时间间隔大于180分钟的记录。
(4)乘车有效性检验,乘客从同一站点进出的数据为乘车无效数据,杭州市地铁的运营时间为5:30—23:00,其他时间段的刷卡数据为无效数据,删除无效记录。
依据此规则完成五个工作日数据的清洗,得到完整有效的刷卡数据。
1.2 建立用户完整出行链
要研究用户的出行规律,首先要从单个刷卡记录中重建用户的完整出行链。清洗后得到的刷卡数据记录的是每张卡的每一次刷卡记录,通过整合多天的数据,将每张卡的刷卡记录提取出来,以卡号为连接匹配同日期的进出站刷卡数据,建立每位乘客指定时期内的出行链。表1是一位乘客五个工作日内的完整出行链。
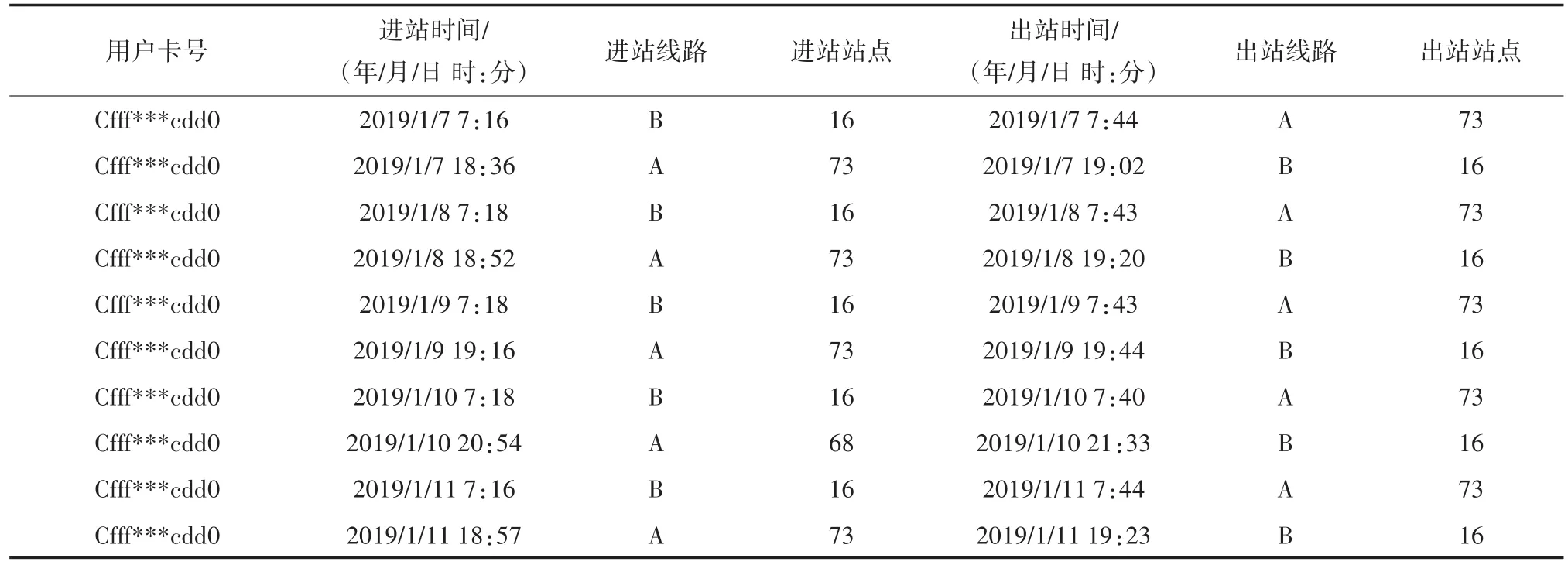
表1 乘客完整出行链示例
1.3 分类指标选取
出行链体现了乘客丰富的个体特征,在得到用户出行链的基础上,从出行强度、时间、空间三个方面选取分类指标对乘客分类,分类指标如表2所示。
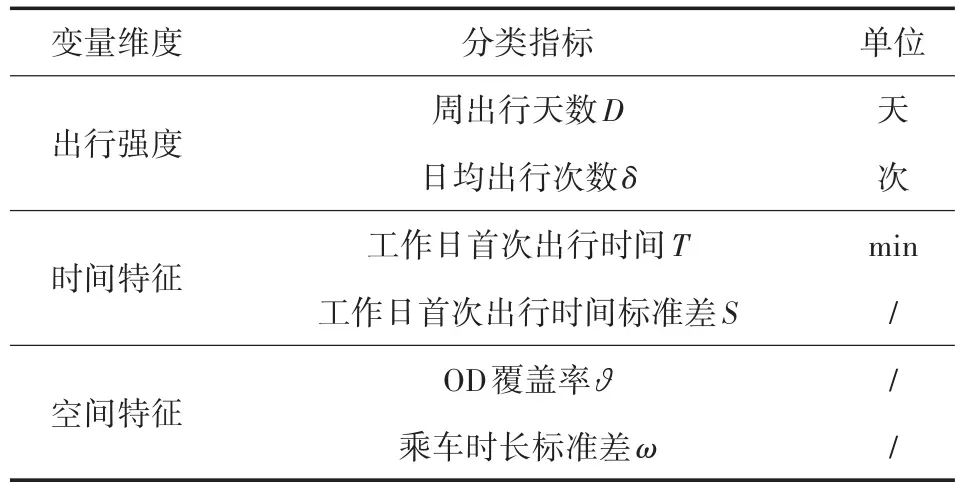
表2 分类指标
出行强度刻画了乘客对地铁的使用频率。不同人群对地铁出行的依赖性是不同的,选择乘客的周出行天数D和日均出行次数δ作为出行强度分类指标,分别衡量乘客一周内对地铁的使用频率和日均使用频率。
时间特征选择工作日首次出行时间T和工作日首次出行时间标准差S作为分类指标。出行时间反映乘客出行时间规律,以此能够判断乘客的类型,例如通勤类乘客会在早高峰时间段乘坐地铁。为方便计算,将出行时间转换为分钟数,用首次出发时间中位数表示首次出行时间。出行时间标准差度量了乘客出行时间的稳定性。
空间特征选择OD覆盖率ϑ和乘车时长标准差ω作为分类指标。出行链记录了乘客每次出行的进站站点(O)和出站站点(D),合并得到每次出行的OD对,OD覆盖率是指出行OD对数与总出行次数的比值,OD覆盖率越小,乘客的空间稳定性越高,乘车时长标准差判断乘客每次出行乘车时长的波动,是对出行稳定性很好的补充。
2 乘客出行强度的初始聚类
定义乘客的出行强度特征为x=(D,δ),利用二阶聚类算法根据出行强度对乘客聚类。第一阶段建立聚类特征树,将乘客聚集成诸多小簇,树的各节点由聚类特征构成,以表示乘客信息;第二阶段将得到的小簇再聚类,得到期望的聚类数量。
2.1 预聚类阶段
2.1.1 聚类特征(CF)的计算
簇C中含有N个乘客,其出行强度特征为x1,…,xN,乘客个体特征xi=(Di,δi),i=1,…,N,若x1,…,xN构成一个簇,定义该簇总体特征:
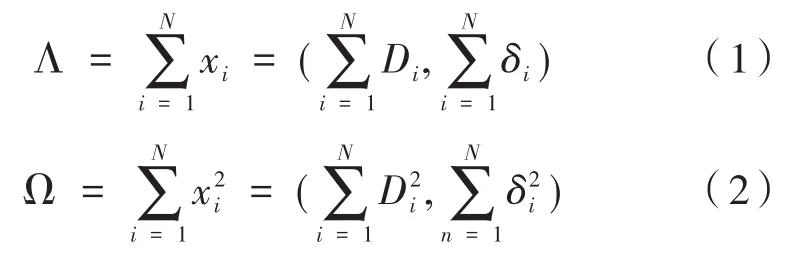
那么,该簇的聚类特征可用CF表示,CF=(N,Λ,Ω)。以这些聚类特征为节点构建聚类特征树,可对乘客进行分类。
2.1.2 聚类特征树
聚类特征树包含三个参数,第一个是每个内部节点的最大CF数(枝平衡因子),第二个是每个叶节点的最大CF数(叶平衡因子),第三个是阈值τ。聚类特征树的建立以所有乘客为数据集,从中读取第一个乘客的聚类特征作为根节点,然后逐个插入乘客的聚类特征,计算新乘客与现有节点的簇间距离,如果簇间距离d(Ci,Cj)≤τ,将新乘客与现有进行合并生成新结点,否则产生一个新的分支,当分支数大于枝平衡因子或叶平衡因子时,就将上一层节点分裂,如此递推归纳直到所有乘客都被添加到聚类特征树。簇间距离采用对数似然距离,计算公式为:
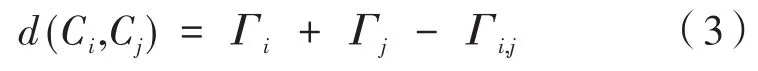
其中,Γi,Γj分别为簇i和j的似然函数值。设簇Cj中有Nj个乘客 {xjn,n=1,…,Nj}:
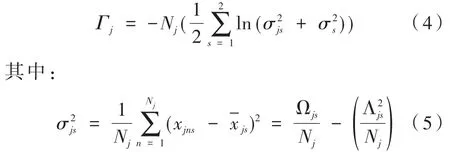
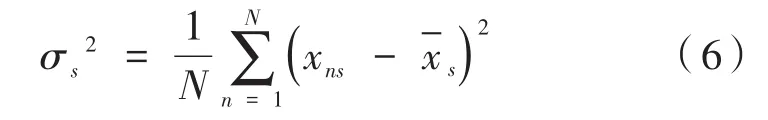
式中,σs2表示数据集中所有乘客在第s个特征下的方差,由于数据集不变,因此σs2可视为常量。一个简单的树结构如图2所示。
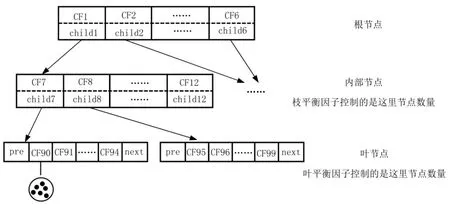
图2 聚类特征树结构图
生成聚类特征树的同时,预先聚类密集区域的数据点,形成诸多小的子簇,为第二阶段聚类做准备。
2.2 聚类阶段
该阶段对树中叶节点的子簇再次进行聚类。首先合并N个子簇中距离最近的一对,得到N-1个簇,然后合并剩下N-1个簇中距离最近的一对,重复实施此操作,直到把所有子簇合并成一个大簇,得到簇数为1的聚类,最后从这N个聚类中输出期望簇数的聚类,完成乘客聚类。聚类数目可以指定,在不主观指定聚类数目时,根据BIC准则自动选择最优的聚类数,BIC值越小的模型越优秀。对于聚类J={C1,…,CJ},BIC值由公式(7)计算得到:

其中,mJ为参数个数;N为聚类J中乘客总数。
2.3 初始聚类结果
在出行强度初始聚类阶段,指定聚类数目为3,聚类结果如表3所示。
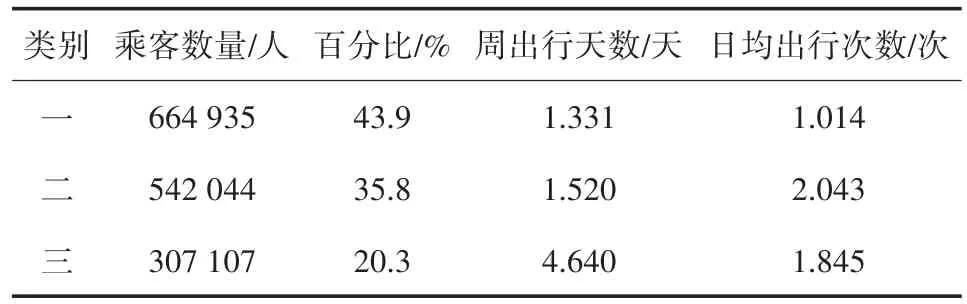
表3 乘客初始聚类结果
乘客聚类结果显示,三类乘客在工作日的出行天数与日均刷卡次数存在明显差异。五个工作日中,类别一的出行天数为1.33天,日均刷卡次数为1次,对地铁的使用强度较低,在总出行人数中占比为43.9%。类别二的周出行天数为1.52天,日均刷卡次数为2次,对地铁的使用强度介于类别一与类别三之间,占总出行人数的35.8%。类别三的周出行天数达到4.6天,日均刷卡次数为1.8次,对地铁的使用强度较高,在总出行人数中占比20.3%。因此可以定义三个类别乘客为低频乘客(类别一)、中频乘客(类别二)和高频乘客(类别三)。
由图3可以看到,乘客的出行规律总体上呈现正态分布,从左到右分别为类别一、类别二、类别三。低频乘客与中频乘客的出行天数没有太大的差异,出行一天的乘客更多被划分在低频,区分这两类乘客的主要标志为日均刷卡次数,中频乘客的日均刷卡次数多于低频乘客,划分高频乘客的主要依据是出行天数,这类乘客出行天数明显多于前两类。
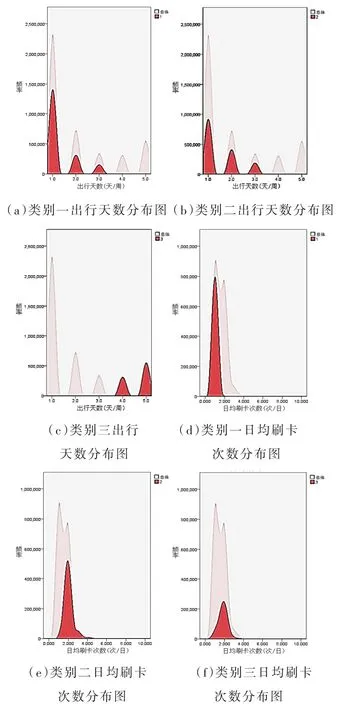
图3 三类乘客的周出行天数与日均刷卡次数分布图
3 乘客出行时空特征再聚类
乘客的出行通常具有一定的规律性,出行的规律性主要体现在出行时间与空间上,不同出行群体会有不同的时空特征以及出行稳定性,比如通勤者往往会在早高峰上班,晚高峰下班,并往返于固定的工作地与居住地站点,具有较高的出行稳定性。在出行强度聚类的基础上,依据乘客的出行时空特征对低频、中频和高频乘客分别再聚类以细分乘客群体。
出行时空特征包括首次出行时间T、首次出行时间标准差S、OD覆盖率ϑ和乘车时长标准差ω,定义乘客的时空特征y=(T,S,ϑ,ω)。根据乘客时空特征计算聚类特征CF以及簇间距离d(Ci,Cj),按照2.1.2节步骤建立聚类特征树将乘客聚成诸多小簇,对得到的诸多小簇再次进行聚类,根据BIC准则自动确定最优的聚类数,输出乘客聚类结果。
3.1 低频乘客时空聚类
对低频乘客再聚类,将低频人群依据时空特征分为两类。聚类结果如表4所示。其中,为方便计算,将出行时间转换为分钟数表示。

表4 低频乘客聚类结果
第一、二类乘客在低频人群中所占比例分别为22.7%和77.3%,他们的周出行天数为1.33天,日均刷卡次数约为1次。乘客出行时间分布图和OD覆盖率分布图如图4、图5所示。
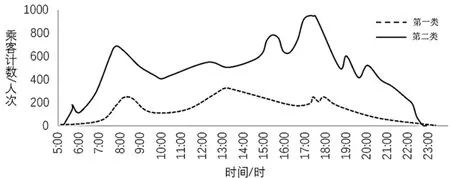
图4 第一、二类乘客首次出发时间
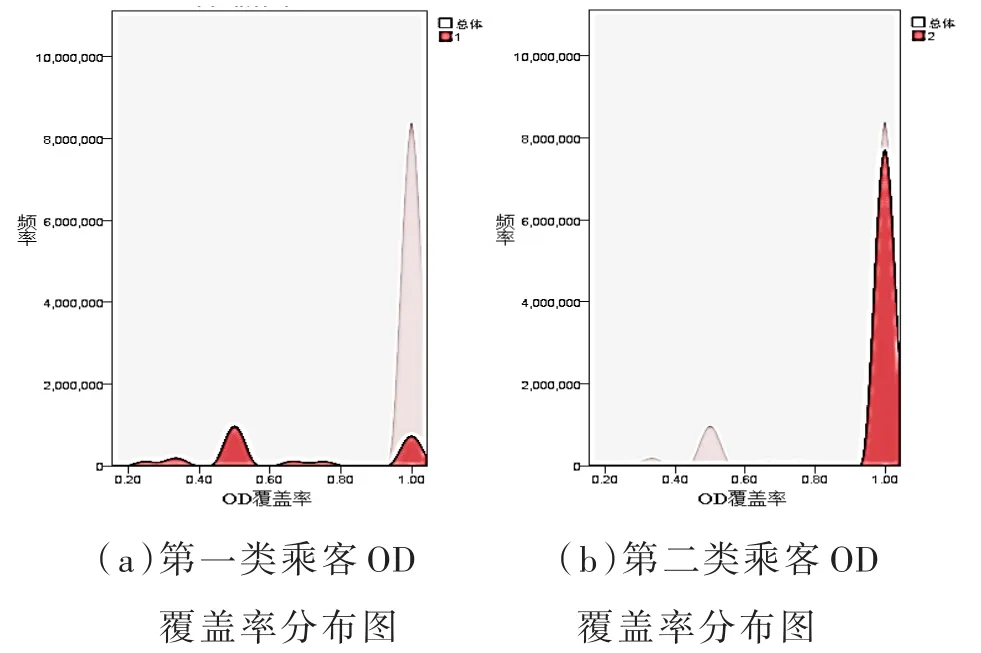
图5 第一、二类乘客OD覆盖率分布图
第一类乘客首次出发时间分散在全天各时间段,出发时间标准差较大,OD覆盖率分布较分散。该类乘客出行时空稳定性较弱,结合其低频出行强度,将他们定义为短期低频类乘客,可能是旅游出行乘客或偶然出行乘客。
第二类乘客首次出发时间分布在全天各时间段,与第一类乘客相比存在较为明显的早晚高峰,首次出发时间标准差较小,由于出行次数只有一次所以OD覆盖率取值为1。该类乘客出行时空较为固定,定义为特定出行目的乘客,这类特定的出行目的频率较低,基本符合一周一次,例如学生补课、探望亲友等。
3.2 中频乘客时空聚类
对中频乘客再聚类,将中频人群依据时空特征分为四类。聚类结果如表5所示。其中,为方便计算,将出行时间转换为分钟数表示。

表5 中频乘客聚类结果
第三、四、五、六类乘客在中频人群中所占比例分别为16.3%、24.9%、23.9%和34.8%,他们的周出行天数为1.52天,日均刷卡次数约为2次。乘客出行时间分布图和OD覆盖率分布图如图6、图7所示。
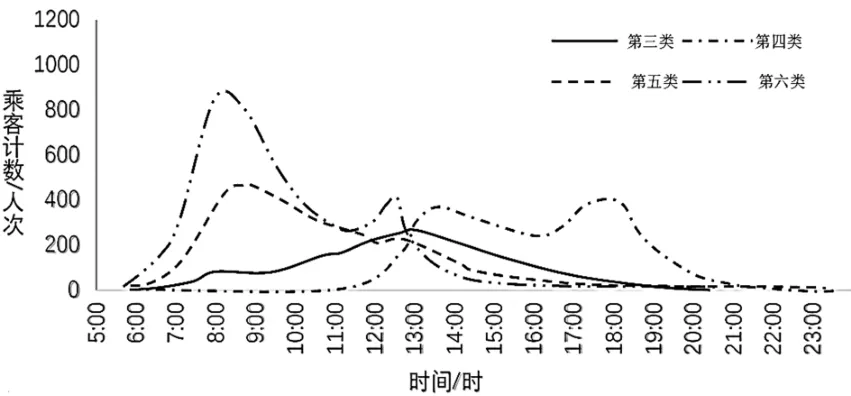
图6 第三、四、五、六类乘客首次出发时间
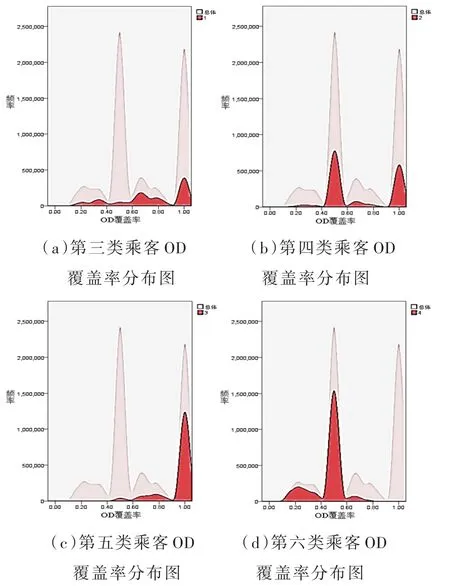
图7 第三、四、五、六类乘客OD覆盖率分布图
第三类乘客首次出行时间标准差大,出发时间分散,没有明显趋势,OD覆盖率中心0.74取值较大。该类乘客出行时空稳定性弱,结合中频出行强度可以认为该类乘客为不规律型乘客,若要得到这类乘客的出行规律需要结合多源数据进一步探索。
第四类乘客首次出行时间标准差较小,出发时间集中在下午和晚上,OD覆盖率较第三类乘客相对集中,取值偏大。该类乘客出行时间稳定,但空间不太稳定,将他们定义为生活类乘客,他们的出行无固定通勤需求,以生活需求与休闲出行为主,主体可能为大学生、家庭主妇和中老年人。
第五类乘客首次出行时间标准差较小,出发时间集中在上午,并且在8:00—9:00早高峰时段有小幅度集中,出行时间比通勤者略晚,OD覆盖率大,与其他几类乘客相比乘车时长标准差略大。出行时间相对稳定,空间稳定性弱,可将该类乘客定义为出发时间稳定型乘客,这类人群可能存在二次出行。
第六类乘客与前几类乘客相比出行时间标准差最小,出发时间集中在上午,在8:00早高峰时段有明显峰值,OD覆盖率集中在0.45,取值较小。该类乘客出行时空稳定,符合上班或上学人群出行规律,但考虑其出行频次较少,推测该类乘客有其他出行方式,并不主要依赖地铁出行,例如在小汽车限号日乘坐地铁的上班族,将该类乘客定义为低频通勤乘客。
3.3 高频乘客时空聚类
对高频乘客再聚类,将高频人群依据时空特征分为两类。聚类结果如表6所示。其中,为方便计算,将出行时间转换为分钟数表示。

表6 高频乘客聚类结果
第七、八类乘客在高频人群中所占比例分别为37.1%和63.9%,他们的周出行天数为4至5天,日均刷卡次数约为2次。乘客出行时间分布图和OD覆盖率分布图如图8、图9所示。

图8 第七、八类乘客首次出发时间
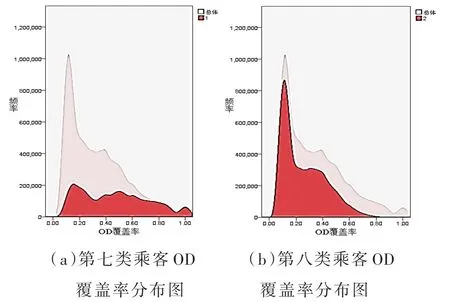
图9 第七、八类乘客OD覆盖率分布图
第七类乘客首次出发时间标准差较大,出发时间较为分散,在8:00—9:00早高峰时段存在小幅度集中,OD覆盖率分布十分离散。这类乘客出行时空稳定性较弱,结合其高频出行强度可以认为该类乘客为弹性通勤乘客,例如业务型乘客。
第八类乘客出行特征最为明显,出发时间集中在早上8:00—9:00早高峰时段,出发时间标准差小,基本没有分散在其他时间的出行,OD覆盖率集中在较小值处,表明此类乘客出行的站点比较固定,乘车时长标准差小。这类乘客出行时空稳定性高,可以认为该类乘客是典型的通勤型乘客。
4 结论
以杭州市五个工作日地铁刷卡数据为例,构建乘客完整出行链,挖掘乘客出行强度和出行时间、空间等特征,运用二阶聚类算法,首先依据出行强度对乘客进行初始聚类,在初始聚类基础上依据时空特征对乘客进行再聚类,最终将乘客划分为8类,并详细讨论了这8类人群的出行规律,识别乘客群体身份与出行目的。将低频人群分为两类,分别为短期低频出行类乘客和特定出行目的乘客;中频人群分为四类,分别是不规律型乘客、生活类乘客、出发时间稳定型乘客和低频通勤乘客;高频人群分为两类,分别为弹性通勤乘客和典型通勤类乘客。
从乘车刷卡数据中挖掘乘客的出行行为对乘客进行细分,对于运输当局有针对性的为乘客提供服务和优化公共交通系统有着重要的意义。对乘客出行行为的详细探究还存在研究城市空间布局、人群社交网络等许多潜在应用,未来的研究中可以将乘客分类结果结合其他领域信息进行进一步研究。
猜你喜欢
今日农业(2022年15期)2022-09-20
数学学习与研究(2018年14期)2018-10-29
价值工程(2018年3期)2018-01-23
电脑知识与技术(2016年7期)2016-05-19
小学生·新读写(2016年5期)2016-05-14
小学生时代·综合版(2014年12期)2015-01-17
奥秘(2014年8期)2014-08-30
中学数学杂志(初中版)(2014年1期)2014-02-28
意林(2010年13期)2010-05-14
故事作文·低年级(2009年7期)2009-11-23
