
基于深度学习的目标检测研究综述
2022-08-26 01:52:00谷永立宗欣欣
现代信息科技 2022年11期
谷永立,宗欣欣
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
我们将可对图像中的目标进行识别和定位的技术称之为目标检测,这些目标包括人物、动物以及日常生活中常见的物品。目标检测技术应用广泛,在建筑工地用于监视以确保安全施工,在工业零件的生产中可用于检测出瑕疵产品,在医疗场景中可进行辅助诊断,在汽车行业可用于自动驾驶。在现实生活中,由于光照、遮挡所造成的阴影、成像品质等诸多因素,使目标检测具有更大的挑战性。
传统的目标检测方法会产生大量冗余候选框,从而增加了运算负担;整体算法由多个部分组成,难以达到全局最优。
20多年来目标检测技术不断创新和发展,从最开始传统的手工设计特征的目标检测方法到目前采用深度学习设计特征的目标检测方法,检测精度和检测速度也随着方法的更新而不断提升。
1 基于锚框的两阶段目标检测算法
本节主要介绍基于锚框的两阶段目标检测算法,首先介绍R-CNN系列算法的发展,然后介绍经典的两阶段目标检测算法Faster R-CNN的网络框架。
1.1 R-CNN系列基础框架的发展史
2014年,Girshick等人提出了R-CNN算法。R-CNN算法的执行过程可分为四部分:首先在所输入的图像中使用Select Search算法提取约为2 000~3 000个目标候选框;接着归一化候选框,将先前所提取的候选区域缩放成一定比例大小后再使用卷积提取特征;然后使用SVM分类器对候选区域进行分类,随后使用边界值回归和非极大值抑制两种方法对区域进行调整,最后得到回归并确定的位置。RCNN算法在VOC-07数据集上测试的结果显示平均精度由原来的30%提升到了近60%。但缺点是其网络只能输入固定比例尺寸大小的候选区域,并且检测速度慢,同时需要较大的存储空间来存放候选区域。
2014年,何凯明等人提出了SPP-Net解决了R-CNN只能接受固定大小的输入,SPP-Net中使用SPP层,用于生成统一尺寸的特征向量的输出,只计算一次全图特征,从而避免重复计算。SPP-Net在VOC-07数据集上检测的结果显示其检测精度与R-CNN算法基本保持一致,但推理速度比R-CNN算法要快了近24倍。和R-CNN一样,SPP训练过程也需要较大的存储空间来存放候选区域;候选层提取依旧十分耗时。
Girshick等人在2015年对R-CNN算法检测速度较慢的问题进行了创新进而提出了Fast R-CNN算法,Fast R-CNN借鉴了SPP层的思想,在网络结构中增加了简化的ROI Pooling层用于生成统一尺寸的特征向量的输出。Fast R-CNN算法在VOC-07数据集上测试的结果显示平均精度均值将SPP-Net算法所达到的59.6%提高到69.9%,Fast R-CNN算法的推理速度更是比R-CNN算法快了200倍。
Fast R-CNN算法检测精确时得到了一定程度上的提高,但是候选区域的生成方式仍采用的是较为传统的算法,于是,2015年Ren等人再一次对Fast R-CNN算法进行了改进提出了新的Faster R-CNN算法,设计了RPN网络来生成候选区域,实现了端到端训练。
1.2 Faster R-CNN
Faster R-CNN算法在VOC07、VOC12和COCO数据集上都实现了SOTA精度,其网络主要分为四部分:特征提取网络、ROI Pooling层网络、RPN网络和NMS算法。
Faster R-CNN网络结构如图1所示,首先将整张图片输入CNN中通过主干网络获取整体特征图,然后通过RPN网络生成大量的候选区域(Anchor Box),其次在获取每个候选区域相对应的特征矩阵,然后使用RoI pooling来固定特征矩阵尺寸,接着再通过目标分类器和边界框回归器来预测每个候选区域所对应的类别以及边界框回归参数得到预测结果,最后通过NMS算法去除大部分概率较低的候选框得到最终的结果。
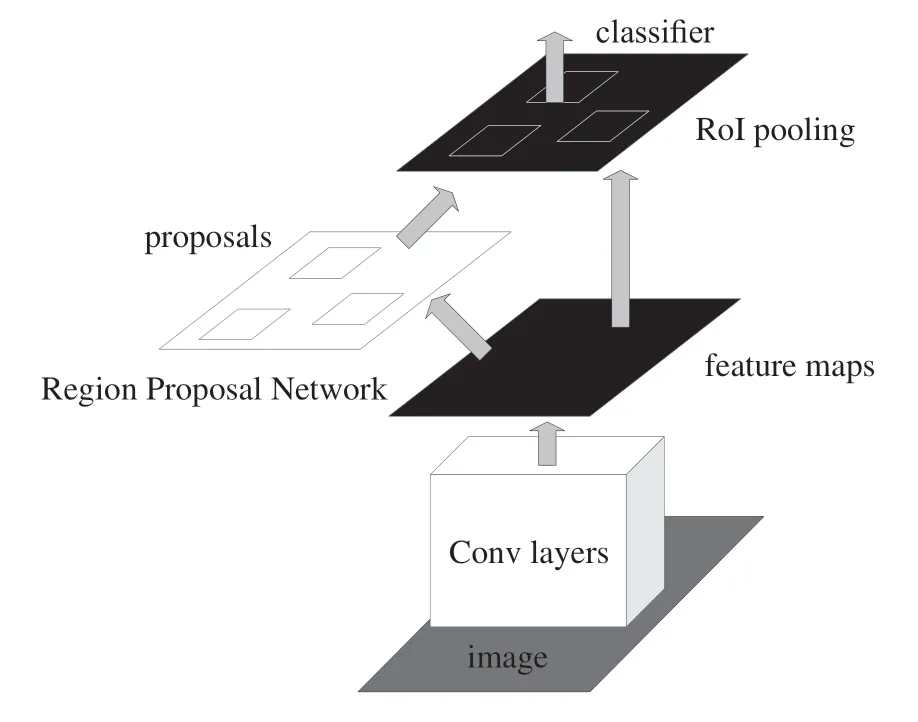
图1 Faster R-CNN网络结构
如图2所示为R-CNN算法中滑动窗口与Anchor的关系,使用3×3大小的卷积核来滑动生成多个锚框,滑动窗口的中心会经过特征图的每个点,特征图上的每一点都对应着一组预先已设定的Anchor Box。
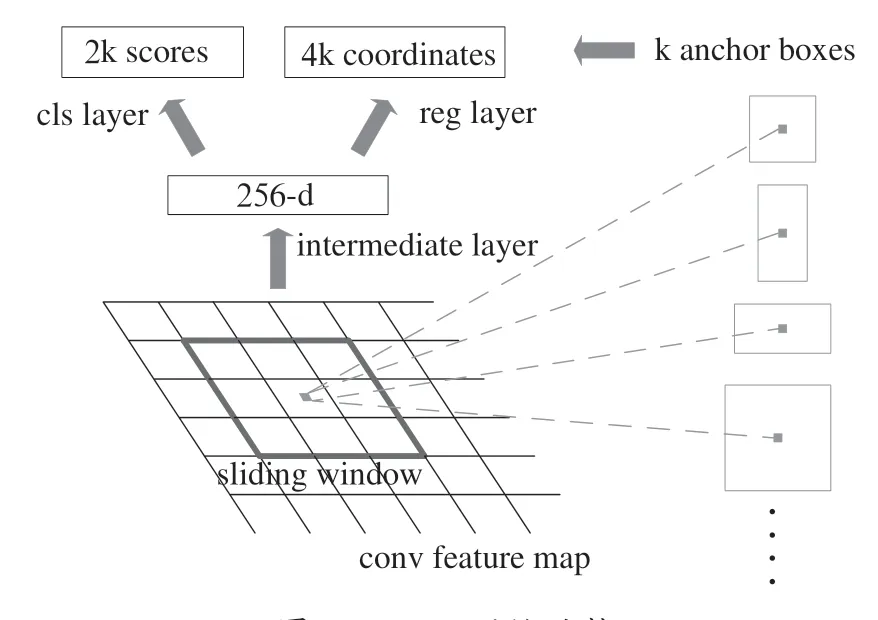
图2 RPN网络结构
Faster R-CNN算法与上述其他算法相比检测的精度和速度都有了更进一步的提升,但仍然有着重复或多余的计算;同时,当IOU阈值较低时,会部分噪声的检测会对结果产生影响,当IOU阈值较高时,也同样会产生过度拟合的问题,所以对IOU阈值的设置需要较为合理。
2 基于锚框的单阶段目标检测算法
基于锚框的单阶段目标检测算法,对于给定的输入图像,直接在生成的候选区域进行分类和回归。本节主要介绍YOLO系列算法和SSD算法。
两阶段目标检测算法具有高精度低速度的特点,YOLOv1算法的提出真正实现了实时检测。YOLO的网络结构较为简单,具备较快的检测速度,但是其精度要远低于两阶段目标检测算法,检测小目标的效果也很差。YOLOv2在原先基础上又增加了BN层,借鉴了两阶段算法中的Anchor思想,首先得到先验框,再在先验框上微调得到预测结果。YOLOv3中融合了其他检测算法的优点,在速度与精度上进行了一定程度上的取舍,虽然检测速度明显低于YOLOv2,但检测精度有了一定提升。YOLOv4的创新有马赛克数据增强方法、自对抗训练方式、改进注意力机制方式、改进通带组合方式等;YOLOv5采用了自适应锚框、跨阶段局部网络等技术。
Liu等人提出了SSD算法。SSD算法使在特征图上生成多个默认框,直接在默认框上微调来预测最终的结果,此外,SSD算法在许多特征图上预测,其对于小目标的检测的性能相比于其他算法也更加高效。
2.1 YOLO系列目标检测算法
2.1.1 YOLOv1算法
YOLOv1是首个单阶段的深度学习目标检测算法,具备非常快捷的检测速度,如图3所示,该算法的操作步骤是先把输入的图像分成×个不同的网格区域,每个网格设置了类别分数和置信度信息。由于在YOLOv1算法只对每个网格生成预测同一类别的两个边界框,所以对于密集的小目标其检测精度急剧下降。
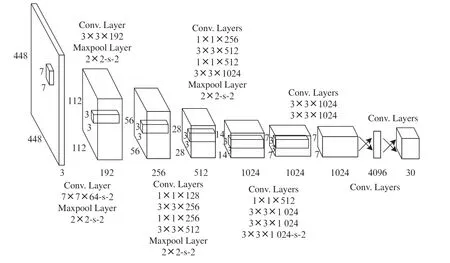
图3 YOLO网络结构
2.1.2 YOLOv2算法
首先,YOLOv2通过增加BN层从而提升了2%的mAP,BN层能帮助模型起到正则化的作用,使用BN层后能够将不再需要dropout操作(dropout操作起到减轻过拟合的作用);其次,采用了更高分辨率的分类器,YOLOv1算法使用224×224大小图像训练网络,而YOLOv2算法使用的448×448大小的图像输入网络训练能够得到更大分辨率的分类器,进一步提升了约4%的mAP值。然后,YOLOv1中是直接预测目标的高度、宽度和中心坐标的。YOLOv2采用基于先验框偏移的预测相比于直接预测坐标,能简化目标边界框预测的问题。最后,YOLOv2使用k-means聚类得到合适的先验框尺寸,对于网络而言,如果选取合适的priors去训练网络,是更容易去学习并且能得到比较好的检测效果。YOLOv2进行预测时,将priors的中心坐标设置在cell的左上角,计算相对偏移量。
YOLOv2算法具有更高的精度、更快的速度和更多的分类量。YOLOv2所使用的DarkNet-19网络也使其具备更快的速度。如图4所示为YOLOv2的网络结构。YOLOv2算法在VOC 2007数据集上测试所得到的mPA值随着检测速度FPS的改变也存在小范围的改变。当FPS达到67时,mAP为76.8,当FPS降低为40时,mAP上升到78.6。由于YOLOv2算法检测分支很少且只有一条导致YOLOv2算法在小目标检测中的表现不佳。
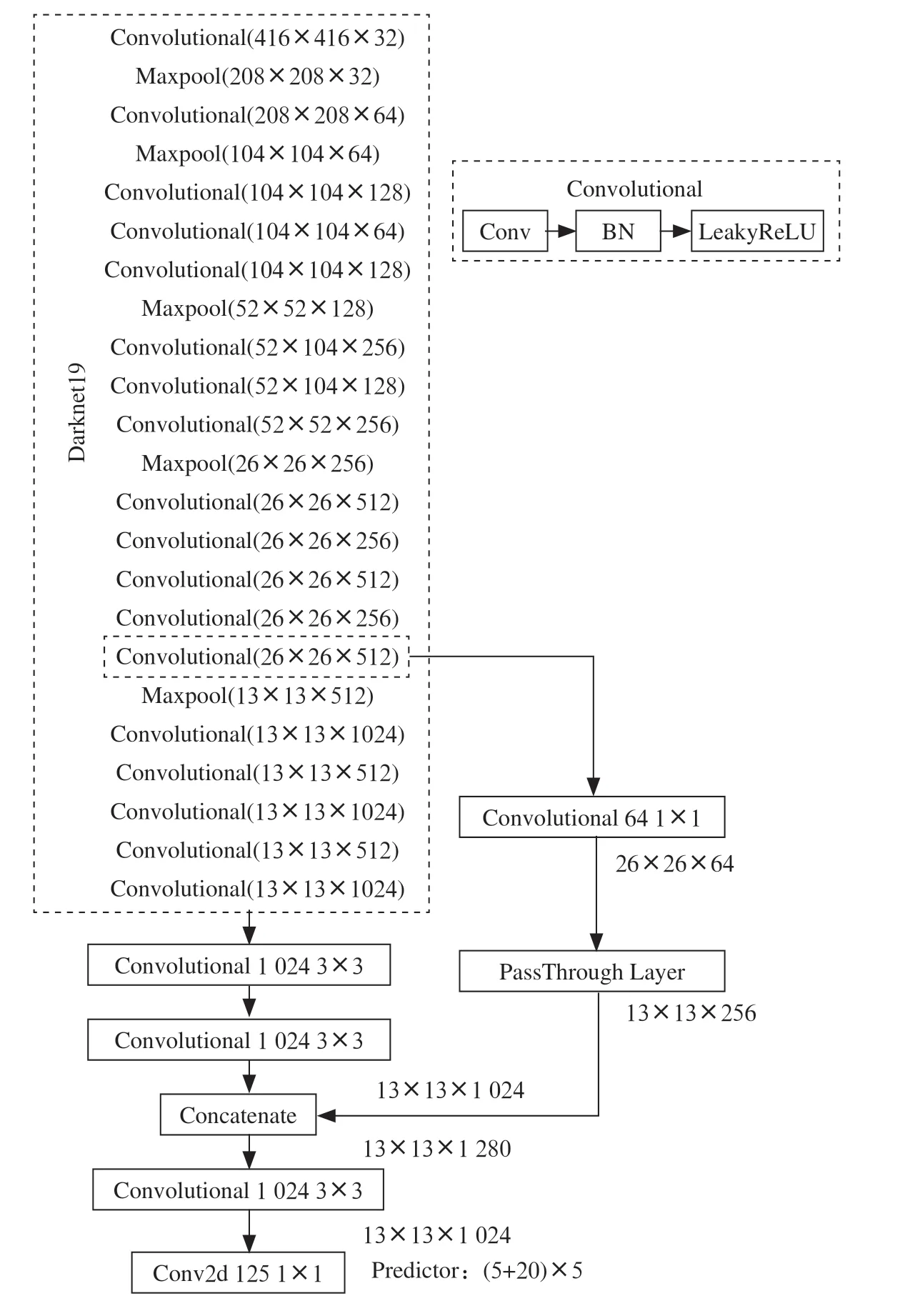
图4 YOLOv2网络结构
2.1.3 YOLOv3算法
YOLOv3算法将不再使用DarkNet-19网络而是使用了DarkNet-53网络,同时使用Logistic分类器,并借鉴了提高模型鲁棒性的FPN多尺度检测思想。如图5所示为YOLOv3的网络结构图,YOLOv3中先验框的尺寸通过图像由K-means算法得到,如图6所示主干网络为Darknet-53。
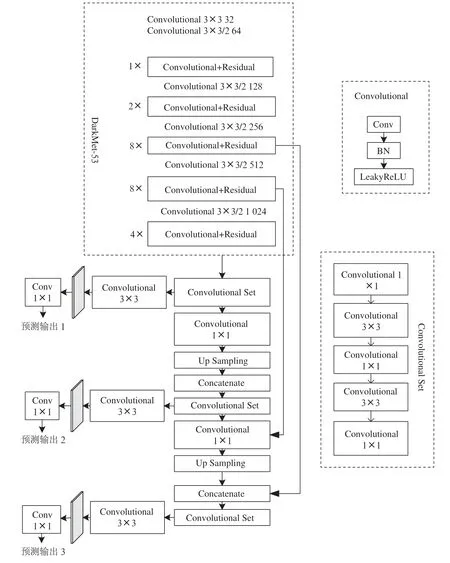
图5 YOLOv3网络结构
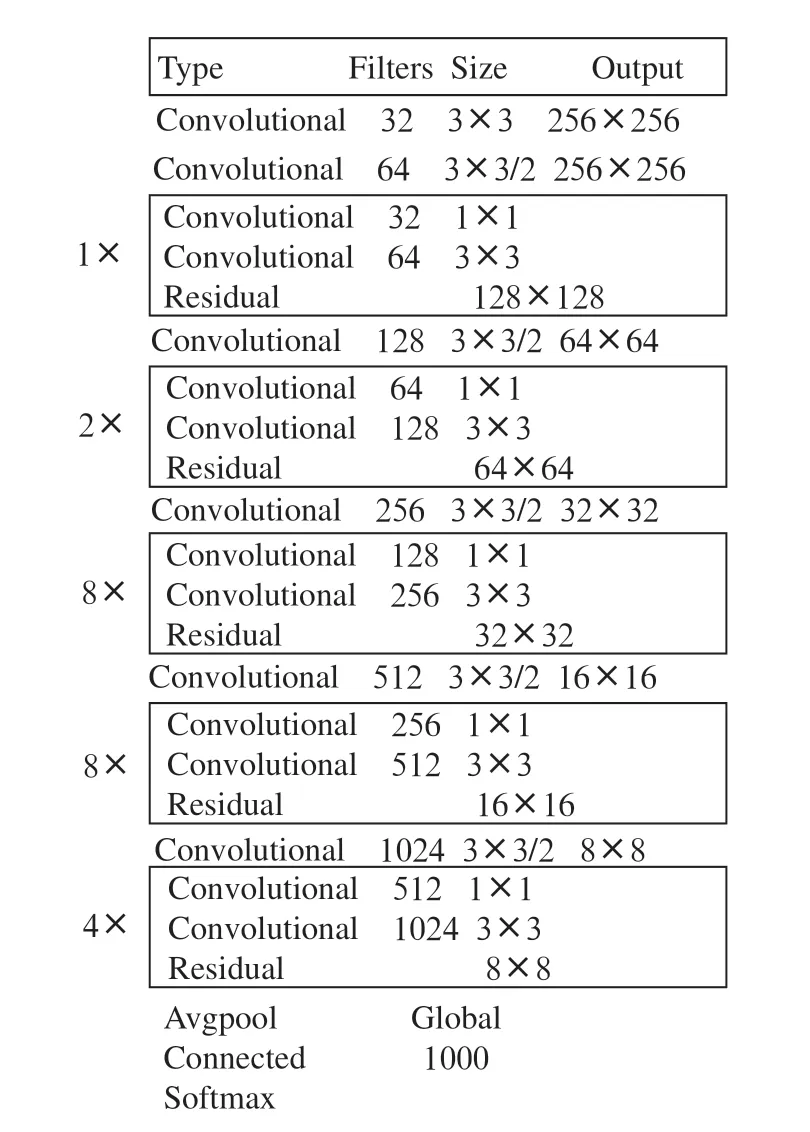
图6 Darknet-53网络结构
YOLOv3算法对输入图像通过Darknet-53网络来提取特征,经过第一个Convolutional Set,一条分支通向预测特征层1,另一条分支经过一个上采样层,高和宽会扩大为原来的2倍和Darknet-53中26×26的输出在深度上进行拼接,将拼接后的特征矩阵再经过一个Convolutional Set进行处理。YOLOv3在VOC数据集上检测速度可以达到20 FPS,mAP也可以达到60%。在YOLOv3刚推出的时候,其使用MSE为边框回归损失函数,但在后续的使用中发现MSE函数的定位能力并不够强,于是后续又提出了IOU、GIOU等一系列边框回归损失函数。
2.1.4 YOLOv4和YOLOv5算法
YOLOv4算法在输入端比YOLOv3算法通过增加Mosaic数据增强和SAT自对抗训练来丰富检测目标的背景和增强数据,使用cmBN来保证BM中batch的统计维度更加准确。在检测端中,YOLOv4算法在引入了SPP的同时还引用了FPN+PAN结构。YOLOv4算法的提出对深度学习的发展也起到了促进作用,当前深度学习中最新设计的训练方式都使用YOLOv4算法来验证训练效率。
YOLOv5算法的产生源自于视觉领域SOTA方法的整合,大量SOTA方法的使用也使得其具备更加优秀的性能。YOLOv5算法在速度和使用的灵活性上有了明显的提高的同时速度也只是稍慢于YOLOv4。
2.2 SSD系列目标检测算法
对于输入图像尺寸为512×512像素的SSD网络,其检测精度甚至超过了Faster R-CNN。
如图7所示为输入图像尺寸为300×300像素的SSD网络结构。图像在输入网络前需要先经过旋转、缩放等预处理,然后图片输入到以VGG16作为主干网的部分,SSD网络中修改了VGG16网络中的部分池化核,SSD网络将VGG16网络的Conv4_3的输出作为SSD网络的第一个预测特征层。依次通过1×1×1 024的卷积层和3×3×1 024的卷积层后得到第二个预测特征层,接着通过一系列的卷积层,共得到6个预测特征层。与YOLO系列算法不同的是,SSD算法含有多个检测分支,这使得SSD算法在对包含多尺度的数据集进行检测时具有更高精度。
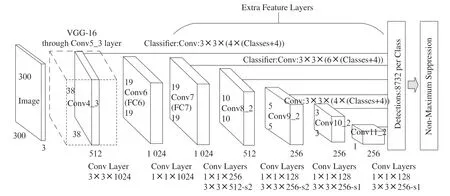
图7 SSD网络结构
3 基于Anchor-free的目标检测算法
基于锚框的目标检测算法在公用数据集上虽然取得了较好的结果,然而引入锚框机制四个缺点:(1)Anchor相关参数(如长宽比例、数量等)的变化都可能导致该算法的测试结果发生很大的改变;(2)固定化的Anchor大大降低了使用的灵活性,对于不同的数据集,Anchor都可能不相同,这也使得前期的准备工作较为烦琐;(3)在训练的过程中为了目标边界框能够进行匹配,大量生成了会被标记为负样本的Anchor,从而导致样本无法均匀分布;(4)大量生成的Anchor会会消耗大量的系统内存。
Law等人在2018年提出了Cornernet算法,将Cornernet应用到检测人体关键点的问题上时体现出了较好的性能,使用左上角和右下角作为目标边界框的两个关键点,将对目标进行检测的问题转换为对关键点进行检测的问题,将CornerNet在COCO数据集上进行测试的结果显示Average precision可以达到42%,该平均精度已经优于当前所有的单阶段检测算法。但是CornerNet也存在只重点关注所检测物体的边角点,而对物体内部的细节不进行考虑的问题。
Zhou等人在2019年一月提出了ExtremeNet算法,ExtremeNet算法在关注物体边缘点的同时和也关注物体内部的信息。为了减少关键点检测方法中产生大量错误的目标边界框Duan等人提出了CenterNet,该网络结构直接对物体的中心关键点进行检测,完全体现了Anchor free的思想。与之前提出的Cornernet网络相比,CenterNet具备更高的准确率和预测正确率。
4 目标检测数据集和评价指标
4.1 目标检测数据集
Pascal VOC 2007、Pascal VOC 2012、ImageNet、MS-COCO等。
PASCAL VOC数据集是计算机视觉领域常用的数据集,图像分类、目标检测、语义分割等计算机视觉任务通常使用PASCAL VOC数据集来验证相关研究的可行性,该数据集中包含的20个类别基本涵盖到日常生活中的所有目标。
MS-COCO数据集中包含更多实例对象,不仅标注了边框信息,还对每个目标进行实例分割来辅助定位。除此以外,MS-COCO数据集中包含了更多复杂情况,使得整个数据集更加符合真实世界的数据分布。
ImageNet数据集类属CV领域数据集,包含1 400万以上被注释过的图像,ILSVRC竞赛作为机器数据领域权威的学术竞赛使用的图像就是在ImageNet数据集中抽取样本。
4.2 评价指标
检测速度(FPS)、精确率(PR)、召回率(RR)是目标检测算法性能的三个基本指标。其中检测速度(FPS)和各个类别的平均精度(mAP)作为性能评价主要指标。
mAP计算公式如下:
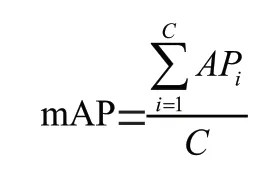
其中,AP表示每一类别的准确率,表示类别数量。
每秒传帧数(FPS)在目标检测领域中FPS指的是模型每秒可以处理图像的数量。假如FPS=20,即每秒钟该模型可以处理20张图像。在目标检测领域中FPS和mAP都是很重要的评价指标,在实际应用的过程中,我们还需平衡上述各个指标,寻找出处理当前任务的最优模型。
5 结 论
目标检测在如今依然具有广泛的应用前景和较大的提升空间,本文章先介绍了目标检测技术的背景,然后将目标检测算法划分为基于锚框的双阶段、基于锚框的单阶段和基于Anchor Free的目标检测算法三个阶段分布进行介绍,并介绍了主流的数据集及主要性能评价指标。随着二十多年的研究目标检测已经广泛应用在日常实践中,但是在其发展的过程中也存在着一些挑战:目标尺寸小,像素点少,无法提取足够的有效特征;目标物体的背景复杂,难以定位准确的目标轮廓;匹配过程中大量负样本的Anchor,导致样本分布不均衡。
结合当前目标检测领域中仍有较大发展空间的问题,未来可以从以下六个方面进一步研究:
(1)轻量型目标检测。在保证一定精度的情况下,减少计算量来加快检测速度。比如智能相机、人脸验证等可以在移动设备如手机上实现的应用。当前目标检测算法的性能仍难以满足移动设备的需求,这使得需要通过购买更高端的设备来提升运行的速度,但也将增加相应的费用。因此在未来轻量级目标检测依旧会是研究的主要趋势之一。
(2)领域自适应的目标检测。在现实生活中很多数据不满足目标检测训练的条件,如何快速且高质量的训练这些数据也是一个非常大的挑战。
(3)与AutoML结合的目标检测。当前基于深度学习的目标检测算法设计过程中人员的从业经验所占的影响依然很大。为了设计检测算法时减少人为参与未来的一个发展方向就是将目标检测与AutoML技术结合。
(4)小目标检测。在场景图像中检测小目标一直是目标检测领域长期以来所面临的一个挑战。如自动驾驶,远程医疗,卫星云图分析都与小目标检测息息相关,因此提高小目标检测的性能一直以来都是研究的重点和难点。
(5)视频检测。当前的目标检测算法大多都是基于对静态图像即单个图像的目标检测而设计的,没有考虑到图像与图像间的相关性。在未来可以通过研究视频帧序列之间的空间和时间相关性来改善视频检测性能。
(6)信息融合目标检测。自动驾驶领域中需要结合多种不同模态的数据源进行分析。所以如何将训练好的检测模型迁移到不同模态的数据中,如何通过信息融合技术来改进检测性能等也可以进行更加深入的研究。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
电子制作(2018年11期)2018-08-04 03:25:38
测绘科学与工程(2016年5期)2016-04-17 06:51:15
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
