
人物交互检测研究进展综述
2022-08-25 03:03张志莹吴昆伦
西南交通大学学报 2022年4期
龚 勋 ,张志莹 ,刘 璐 ,马 冰 ,吴昆伦
(1.西南交通大学计算机与人工智能学院,四川 成都 611756;2.西南交通大学唐山研究生院,河北 唐山063000)
作为视觉理解的子任务,人物交互(humanobject interaction,HOI)检测往往需要对模糊、复杂且难以识别的行为进行分析判断.同样是利用对象间潜在的关系来提升分类效果,视觉关系检测(visual relationship detection,VRD)使用 < 物体 A,谓语,物体 B > 定义关系表达式,会涉及人-人、人-物、物-物等多种目标对象的动作关系组合.而HOI检测将交互行为限定在人和物之间,谓语也主要集中于动词范畴,对于行为识别的发展有显著的借鉴价值.
HOI检测旨在利用人体、物体以及人-物对的特征将人与物体之间的交互进行关联,从而实现对图像或视频中动作的定位及分类.同时,HOI检测可以与计算机视觉的其他工作协作以完成复杂任务,如目标检测、动作检索[1]、字幕生成[2-3]等,具有广阔的应用前景.
HOI检测主要通过全局检测模型将空间、外观与人体姿态在内的感知信息进行整合,生成场景中人物对的关系[4-6].近年卷积神经网络与注意力机制的出现也推动了基于局部身体部位的HOI检测方法的发展.此外,研究人员还从语义规律、视觉相关性和上下文信息等角度对于图像理解展开了更为深入的研究.
人物交互检测首先通过目标检测模块提取图像中人与物体的候选区域作为实例对象,然后通过交互识别模块输出人物关系的三元组表示 <h,i,o>,其中h代表“人”,i代表“交互”,o代表“物体”.图1以“人骑自行车”为例,先由目标检测得到“人”(h)与“自行车”(o)两个实例,然后交互识别模型判别出图像中的人属于“骑”(i)的状态,最后将人、物以及交互行为三者组合,输出关系三元组.

图1 人物交互关系检测流程Fig.1 Flowchart of HOI detection
HOI检测的数据对象包括图像和视频两类,视频中的人物交互检测涉及时序信息融合以及多目标动态分析,关系建模难度大,相关研究成果较少.本文主要对基于图像的人物交互检测研究成果进行综述,统计了从2009年至今计算机视觉主要国际期刊及会议的文章.
本文第1章详细介绍了人物交互重要数据集及其评价指标;第2章将人物交互检测算法分为基于全局实例和基于局部实例的方法,并依次介绍;第3章探讨了零样本学习、弱监督学习和Transformer模型在人物交互检测领域的应用;第4章分析了人物交互检测当前所面临的主要挑战,并指出未来值得探索的研究方向.
1 数据集分类与评价指标
目前,人物交互公开数据集的不断涌现反映了HOI领域朝着规模更大、场景更复杂、动作类型更多的方向发展.本章将HOI关系检测涉及的主流数据集分为传统的语义描述数据集和基于目标检测的实例数据集两类.
1.1 传统数据集
Sports event[7]是2007年提出的小型运动数据集,它包含了从互联网上收集的8种体育赛事类别.由于早期的人物交互检测研究缺乏数据支持,该数据集的发布使得人物交互检测领域得到了更多学者的关注.
TUHOI[8]是一个通用的人物交互数据集,其中的图像来自ILSVRC 2013检测数据集.该数据集是根据英语单词的含义来进行类别划分,然而动词的语法时态以及一词多义现象会带来映射偏差,导致验证时难以区分语言理解错误和HOI检测错误.
HICO[9]是由密西根大学安娜堡分校在2015年ICCV (IEEE International Conference on Computer Vision)上提出的基准数据集,收录了来自80个对象的117种常见行为.在真实场景中人可能与多个物体同时产生交互行为,因此,该数据集以物体为中心,对交互类的标签注释进行了大幅度扩展.
一些用于动作识别的数据集也被用于HOI检测分析,包括早期的 Sports event、The sports[5]以及MPII[10]人体姿势数据集.其中,Sports event和 The sports数据集使用大量的语义级标签描述场景和对象;MPII作为2D人体姿态估计的基准数据集,提供了3D躯干和头部方向标签、关节点标签和身体部位的遮挡标签以及行为标签.
1.2 实例数据集
传统的语义描述数据集缺少对粗粒度行为的分解,所以对于人物交互关系的准确评估较为困难.VCOCO[11]针对每一类别的单个目标进行了实例分割并为每张图像提供了5种文字描述,实例框使人物交互模型能更好地估计目标对象的区域位置,实现对视觉场景语义的深入理解.
HICO-DET[12]使用无向边作为交互类标签,将人与物体的实例框相连接,提供了15万个带注释的人-物实例,每个实例框由介于人和对象边界框之间的类标签表示,该数据集与V-COCO是人物交互检测领域中公认的两大基准数据集.
HAKE[13]是人物交互领域最新发布的数据集.它使用了大量的人体局部(part state,PaSta)状态标签来推断人的身体部位状态,成为第一个带有细粒度注释的大规模实例数据集,涵盖了247 000个人体实例、220 000个物体实例和7 000 000个局部动作标签.
HOI-A[14]来自真实场景,涵盖了不同外观类型、低分辨率以及具有严重遮挡的图像,识别难度较大;HCVRD[15]是目前规模最大的以人为中心的HOI数据集,图像数量较多且交互动作多.
表1对现有HOI数据集进行了对比分析.总体上,现有的HOI数据集涉及体育运动[7,10]、室外场景[11,14]、室内场景[16]以及不同交互方式[7,13,17],在一定程度上解决了训练数据不足和标注不完整的问题,但仍然存在以下不足:
1) 交互类型单一:动作类数据集往往包括个体行为、交互行为以及群体行为等多种动作类型,而HOI检测数据集需要筛选出人与物体同时存在且有交互的图像,采集难度更大,因此,目前主流数据集中的交互关系类别不够丰富.
2) 动词标注歧义性:对于图像中的不同对象,标注出来的动词在语义层面和视觉特征的表达上存在一定偏差,给交互检测带来阻碍,动词的一词多义现象已经成为HOI检测的一个难题.
3) 人物标签欠细化:鉴于人的性别和年龄会对人物的交互方式产生一定的影响,细粒度的人物(成人/孩童、男人/女人)标注有利于HOI检测技术的进步,图像中的人物信息需要得到更加详细的标注.
1.3 评价指标
早期的人物交互检测主要使用准确率(Acc)进行评估:

式中:nTP、nTN、nFP及nFN分别为检测正确的正样例、检测正确的负样例、检测错误的正样例以及检测错误的负样例.
但当样本数据分布不均匀时,使用准确率评价易产生偏差(bias),不能客观描述错误类型.
当前HOI检测领域主要使用平均精确率(AP)与平均准确度(mAP)两种性能评估标准.AP基于精确率(P)和召回率(r)进行定义:

式中:N为测试集中图片总数;P(k)为能识别出k张图片的精确率; Δr(k) 为从k- 1变化到k时精确率的变化情况.
而P为分类正确的正样本个数与分类后判别为正样本个数的比值,r为分类正确的正样本数与实际正样本数的比值.综上,AP作为P与r乘积的累加值,其值越大,表示检测效果越好.
mAP由所有类别的平均精确率计算而得,作为衡量分类器对所有类别检测效果的评价因素,mAP成为人物交互检测的主流指标.定义如下:

式中:P1(R)为归一化的识别精确率.
2 人物交互检测方法分类
不同的HOI检测方法区别主要体现在交互识别阶段对实例对象采用的策略不同,下文将从基于全局实例和基于局部实例两个角度进行分类总结.
2.1 基于全局实例的方法
基于全局实例的人物交互建模强调人体、物体以及背景的整体性.为了充分利用图像中的线索,基于全局实例的方法有3种实现方式,分别是融合空间位置信息、融合外观信息以及融合人体姿势信息.
2.1.1 融合空间位置信息
目标检测器定位到人和物体实例后,空间布局能够为HOI检测提供重要的先验信息.如图2所示,由于交互类型的不同,人和物体在图中的空间位置分布有很大差异,合理利用空间关系有助于交互识别的判断,并在预测时排除可能性较小的分类.

图2 人物交互的相对空间关系Fig.2 Relative spatial relationship in HOI
Chao等[12]提出三分支网络HO-RCNN,用于提取人物空间关系的特征,如图3所示.该网络包含人体流、物体流以及人物对流3部分.首先,根据人体和物体框对原始特征进行裁剪;然后,归一化成相同大小的特征输入到各自的卷积网络中,生成对应的交互类别概率;最终,通过全连接层将视觉和空间特征融合,输出动作类别的预测得分.人体流和物体流的作用是对Fast-RCNN[18]检测的目标区域进一步提取特征,人物对流使得模型在不同类型背景下也能发现HOI类中动词与物体的潜在规律.
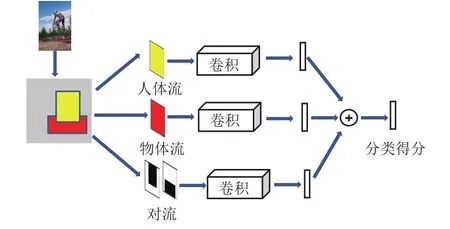
图3 基于人-物区域位置信息的HO-RCNN网络Fig.3 HO-RCNN networks based on human-object regional information
为了实现端到端的HOI检测训练,Gao等[19]提出了以人体为中心的注意力模块(instance-centric attention network,iCAN)来强调图中与交互相关的重要区域,即上下文信息.该模块的主要思想是应用ROI (region of interest)池与残差块进行全局平均池化,通过降低模型的参数量来降低过拟合效应.并使用softmax函数对融合的实例级外观特征和卷积特征进行映射,得到能够突显高层特征的注意力图.iCAN不仅可以与其他网络联合训练提高模型性能,而且能根据不同的对象实例自动调整关注区域.与基于手工设计的外观特征相比,该方法在V-COCO和HICO-DET数据集上检测精确率分别提高了10.00%和49.00%.
Wang等[20]改进了iCAN模块,在“人体流”和“物体流”中嵌入上下文感知外观和注意力模块,以提取全局图像中的外观和上下文信息.上下文感知外观模块通过上下文聚合[21]和本地编码块捕获人和物体实例附近的区域信息.同时,作者借鉴了动作识别[22]中的方式,引入上下文注意力模块以增强鉴别性强的特征,在一定程度上减少了背景噪声干扰.
Bansal等[23]为了强化人和物体间相对空间位置的作用,提出了空间引发模型(spatial priming model)结构,如图4所示,该模型包含视觉模块V和布局模块L两部分,它们在多个阶段共享视觉上下文.首先,堆叠和裁剪人和物体的边界框(bh和bo),输入到L和V中.然后,在L中利用不同卷积层C1 ~C8提取人的布局特征(f1),与物体的语义表示(wo)相连接,通过两个全连接层输出人和物体的联合框信息(p1)和加权损失(J1).V 通过残差块 Res1 ~Res4 与全局池化层 (global average pooled,GAP)提取物体的全局特征(f2),并结合来自目标检测的人和物体特征(fh和fo)与L的预测结果,联合输出谓词的最终概率(p2)和L与V的损失总和(J2).目前在融合空间位置信息的方法中,该方法效果最好,在HICO-DET与V-COCO上mAP分别达到了24.79%与49.20%.
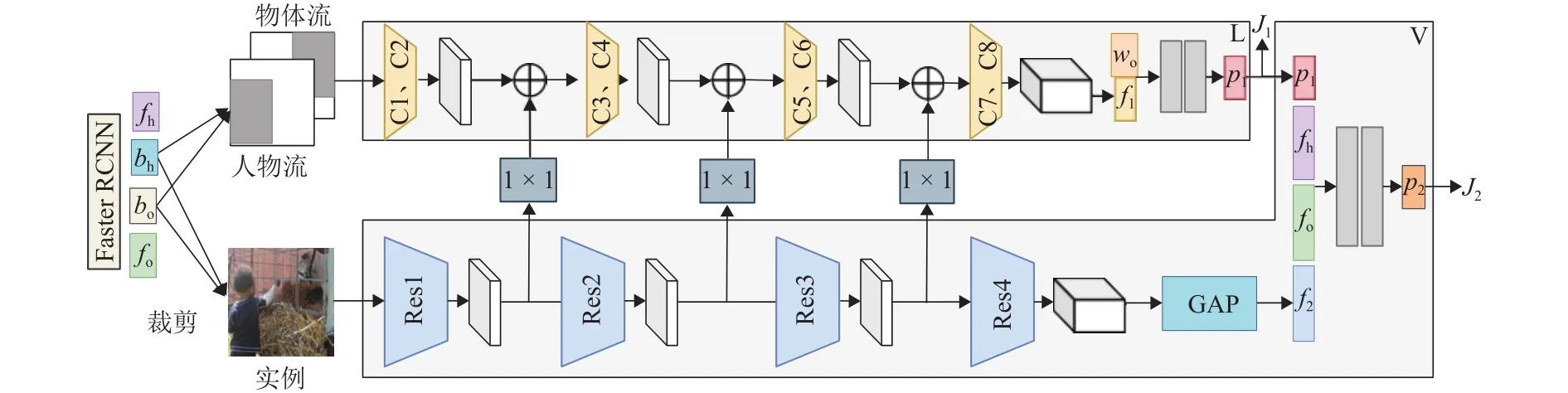
图4 空间引发模型框架Fig.4 Framework of spatial priming model
2.1.2 融合外观信息
在交互模式中,人与物体的外观信息作为主要的视觉表现,能够对实例对象的外部轮廓进行描述.在HO-RCNN的基础上,Gkioxari等[24]提出了一种三分支网络InteractNet,采用外观特征提取人-物互关系.第一个分支采用Faster-RCNN网络[25]进行人与物体检测;第二个分支对每一种动作类型中检测目标的相对位置进行密度估计;第三个分支将第二个分支中得到的特征与目标物体特征结合,得到两者之间的动作类别,最后将三分支的得分进行融合输出分类结果,该方法在V-COCO上可以达到135帧/ms的运行速度.
三分支网络模型(如InteractNet和HO-RCNN)复杂且训练时间长,给HOI检测的性能提升带来了挑战.Gupta等[26]提出一种两阶段外观编码方法:第一阶段为图像中每个人和物体创建一组候选框,然后将人候选框与物体候选框配对形成人-物候选框对.第二阶段使用分解模型对候选框对进行评分,通过不同交互类别之间利用参数传递评分结果,能够有效减少人物交互检测的误检.但该网络将区域候选框生成和交互检测分离开来,导致实时性较差,而且人-物候选框对的配对和分解进一步增加了计算复杂度.
针对以上问题,Liao等[14]提出了单阶段的并行点检测与匹配模型(parallel point detection and matching,PPDM),点检测分支负责估计人体点、交互点和物体点的位置,点匹配分支将源于同一交互点的人体点和物体点视为匹配对,仅筛选出少量的候选交互点,节省了计算成本.同时,该文献还使用了深层聚合(deep layer aggregation,DLA)[27-28]与Hourglass[29-30]两种关键点热图预测网络来扩大交互点和位移预测值的感受野,提取语义层次更高的特征.如图5所示,两种网络在HICO-DET上最好的达到37.03帧/s的检测速度与21.73%的平均识别准确度,PPDM方法在一定程度上解决了模型规模大、检测速度慢的问题.
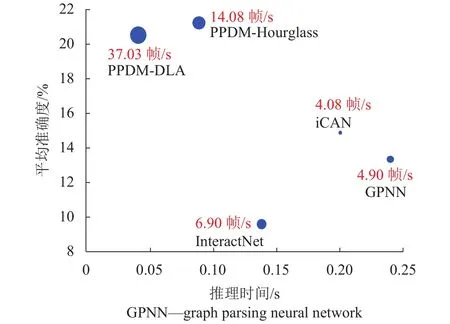
图5 PPDM与同类方法在HICO-DET上的推理时间、平均准确度以及速度Fig.5 Inference time, mAP, speed between PPDM and similar methods on HICO-DET dataset
2.1.3 融合人体姿势信息
一方面,融合空间特征的方法因缺乏人体形态的精确特征,性能无法得到进一步提升,人体姿势能将人体与相互作用的物体联系起来;另一方面手工特征方法[26]利用先验知识来帮助交互检测与识别任务,但这种方法获得的姿态表征能力较弱,因此,近年来一些工作将姿态估计与视觉特征进行融合.
在HO-RCNN基础上,Li等[31]利用姿态估计网络[32-33]与人体骨架分支提取人体姿势特征.骨架分支与“人物对流”组成的网络进行了互动性判别,使得模型能够学习互动性知识,从而带来更有效的监督约束,该方法能解决罕见类别由于信息稀缺而导致的训练困难.
姿态感知网络PMFNet[34]不是以成对的方式提取交互关系,而是利用身体部位与物体之间的空间位置作为注意力,动态放大了人体部位的相关区域.该方法使用姿势估计网络[35]将空间特征、外观特征和姿态信息共同输入到整体模块(holistic module)和放大模块(zoom-in module)中,然后从人体姿态中提取人体部位外观特征、人体部位空间特征以及增强相关人体部位对各个交互作用的注意力特征,最终通过融合模块结合整体和局部特征进行关系分类.
除了对人体姿态与物体的相对空间位置信息建模,Liang等[36]对人体边界框的中心归一化,构造绝对空间姿态特征,并提出基于姿态的模块化网络(pose-based modular network,PMN).该模块由两个分支组成,一个分支独立处理各关节的相对姿态特征,另一个分支使用图卷积更新各关节的绝对姿态特征,然后利用视觉语义图注意力网络(visualsemantic graph attention networks,VS-GATs)[17]融合相对空间姿势特征和绝对空间姿势特征,这能有效减少拥挤场景中的错误识别.
为了探索细粒度的人体姿势信息对人物交互检测的影响,Liang等[37]提出了视觉、语义和姿态融合网络VSP-GMN,利用图神经网络将一系列的语境线索进行组合,减少场景理解与内在语义规律之间的歧义.如图6所示,作者重新定义了相对空间姿态特征,把人体各个关节与物体边界框中心相连的整体作为相对空间姿态征.随后,将相对、绝对空间姿态特征姿态和视觉特征分别输入到 PMN 和 VS-GAT模块中,两个分支的动作得分因子相加,实现人、物体之间的三元组关系预测.
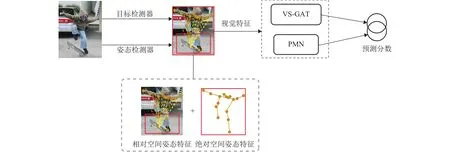
图6 融合视觉语义姿态特征的VSP-GMN网络Fig.6 VSP-GMN network integrating visual, semantic and pose features
目前,人物交互检测中基于全局实例的方法都体现了图像整体的视觉描述,不同的是,基于空间位置信息的方法偏向于快速定位与特定动作相关联的对象;基于外观特征的方法常利用人或物体的外观为条件,缩小目标对象的搜索空间;基于人体姿态信息的方法强调靠近交互区域的人体部位在检测时不同的重要程度.
2.2 基于局部实例的方法
与基于全局实例的方法不同,基于局部实例的方法重点从目标主体的骨骼、姿势、部位等局部特征出发分析人与物体的内在联系.局部实例方法需要解决如下两方面问题:
1) 如何将姿态各异的身体部位与物体的交互进行整合?
2) 身体部位配对增加了计算负荷,如何提高模型效率?
如图7所示,人体部位特征相比整体视觉特征更细致,数量更多也更难获得.Fang等[38]就关键部位与HOI识别的相关性进行了探索,使用姿势估计网络[39]提取了人体骨骼点,然后根据关键点将人体划分为11个部位,每个部位设置一个与待检测的人体躯干大小成比例的边界框,该方法通过将人体的各个部位配对输入注意力模型,学习得到相关性最大的部位作为整体结果.该方法灵活地利用了不同部位特征间的关联关系,在HICO数据集上相比于以人为中心的方法[40]mAP提升了10%.

图7 整体人体姿态与局部特征的对比Fig.7 Comparison of overall human posture and local features
基于局部特征的注意力模块会产生多个部位间的配对关系,计算开销较大.针对这一问题,基于GCN的方法是目前最好的解决方式.Zhou等[41]提出关系解析神经网络模型RPNN,使用Detectron[42]和Mask R-CNN[43]分别检测人体、物体框以及人体骨骼点信息,利用人体骨骼点信息生成4个人体部位,即头部、手部、臀部和腿部,加强了人体局部特征的表征能力,接着采用GPNN[44]整合局部信息生成图结构,该方法检测效果较成对的身体部位注意模型[38]有显著提升.
在一般情况下,只有少量的人体部位展现出了与交互行为的高度相关性,其他部分则很少携带有用的线索.为了提取人体部位状态的细粒度信息,Liu等[45]构建了基于身体部位的数据集HAKE,并提出多级成对特征网络PFNet.如图8所示,该数据集将每个交互动作细化为多个局部交互动作,比如“人开车”被分为“头看后视镜”、“左手握方向盘”、“右手握方向盘”以及“臀部坐在椅子上”等一系列相关交互.从实验结果看,各主流算法在该数据集上得到了性能提升,为后续的HOI检测算法提供了新基准.
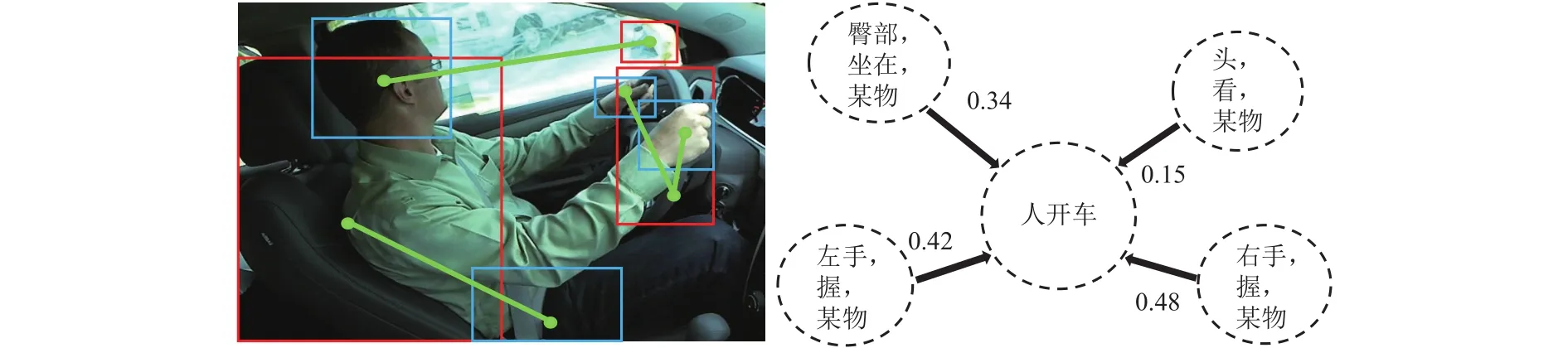
图8 基于实例行为的局部标签Fig.8 Local annotations based on instance behavior
由于人经常关注在交互过程中提供重要信息的区域,因此Zhong等[46]设计出单阶段的GGNet(glance and gaze network)网络,通过扫视和凝视两步骤自适应地对一组动作感知点进行建模.凝视步骤利用由扫视步骤生成的特征图,以渐进方式推理出每个像素周围的动作感知点,并聚合其特征以进行交互预测.GGNet不仅通过扫视策略改进了交互预测任务,还通过动作感知点匹配模块提高了人体对象对匹配的准确性,在HICO-DET数据集上mAP达到目前最优结果:29.17%.
同样是利用人的视线为交互识别锁定关键区域,Xu等[16]认为在弱监督场景中人眼的注视方向能作为线索帮助模型学习多个上下文区域的信息,为此,他们提出了以人类意图驱动的HOI检测框架(human intention-driven HOI detection,iHOI).该方法借助身体各关节到实例的相对距离对人体姿势进行建模,然后将不同的人-物对整合到特征空间中,最后结合注视位置的概率密度图输出关系三元组,这种方法利用人眼的注视方向作为人类意图的直观体现,为人物交互检测的改进提供了新思路.
2.3 小 结
本章总结了近几年基于外观特征建模、外观和空间特征结合、姿态特征和外观特征结合等方面的代表性工作,表2和表3按照时间顺序整理了2017年—2021年基于视觉特征的代表性方法,分别对比了各方法在HICO-DET和V-COCO两个主流数据集中的性能.
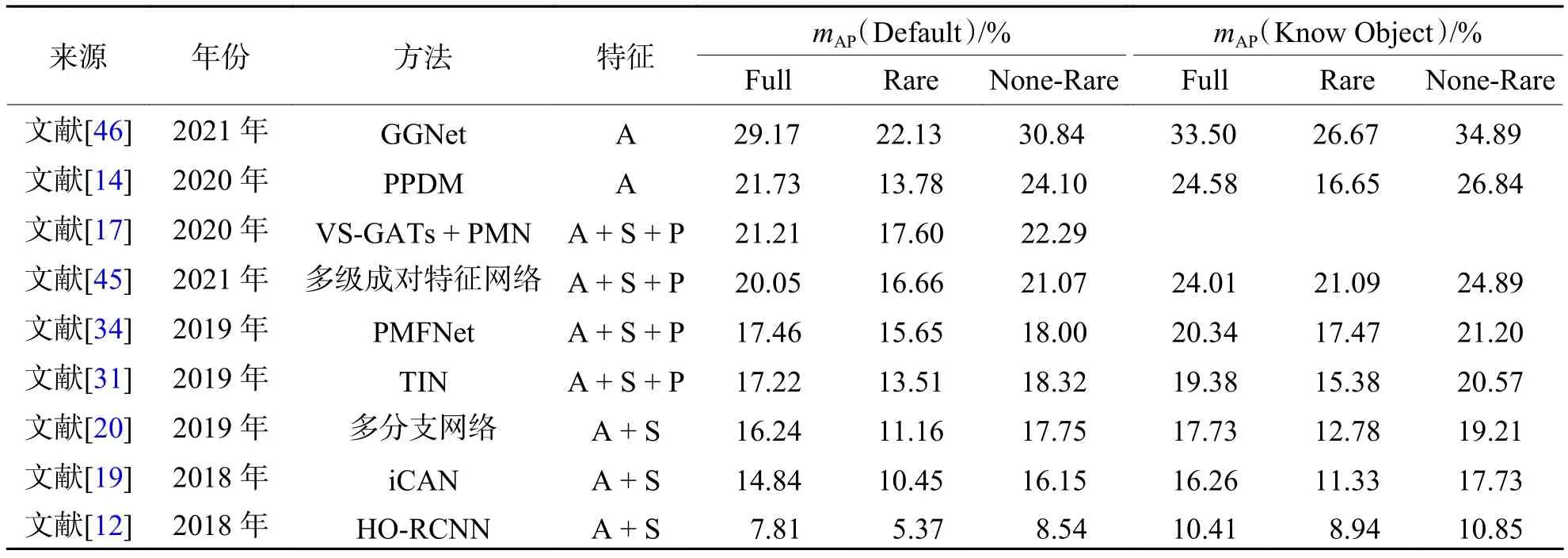
表2 基于视觉特征方法在HICO-DET数据集的mAP结果对比Tab.2 Result comparison of mAP with visual feature based methods on HICO-DET data set
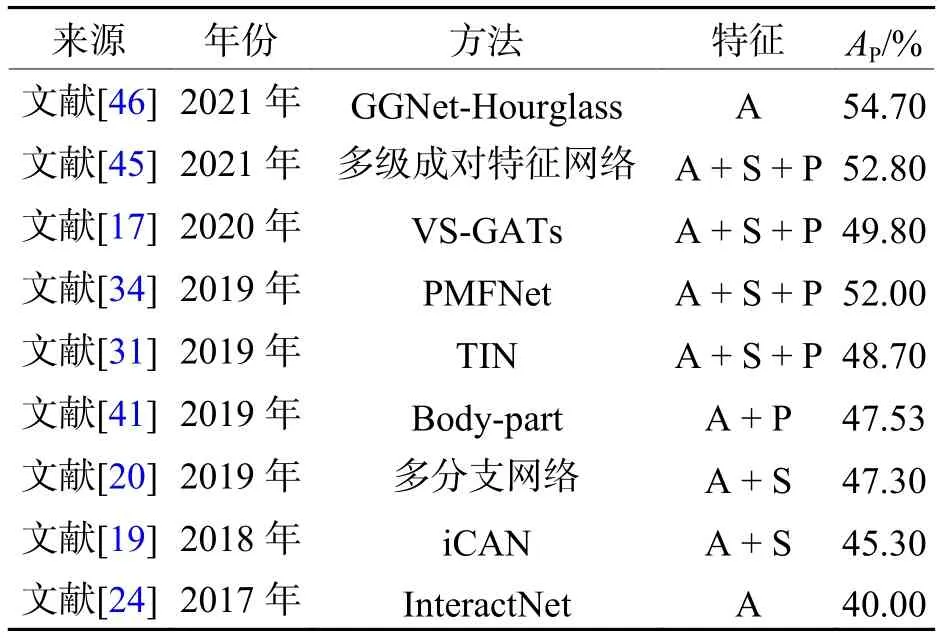
表3 基于视觉特征方法在V-COCO数据集结果对比Tab.3 Results comparison of visual feature based methods on V-COCO data set
结合图5可以看出:在主流的人物交互检测算法中,融合多个特征会提升模型检测的准确率,但其推理速度也会相应下降.在HICO-DET数据集上mAP大于17.00%的方法大多使用两个及其以上的附加特征,仅有基于全局实例的PPDM和基于局部实例的GGNet使用外观特征建模,并且这两个模型分别在检测帧数和识别准确度方面取得了第一的成绩,这说明全局实例模型在速度提升方面更有优势;而局部实例模型能更好捕捉交互动作之间的细微差异,在真实场景中具有更强的抗干扰力,由于人在和物体的交互行为中起到主导作用,针对人体局部进行建模仍是局部实例检测研究的核心.
两个公开数据集的整体结果说明人物交互检测正朝着降低模型规模和提高检测精度两方面发展,未来该领域的发展应切合实际问题,扩大模型的适用场景,以满足实际应用中对模型的检测时间和储存空间的需求.
3 其他新技术
鉴于HOI检测的一些工作不便于归类到视觉特征方法中,本章从零样本学习方法、弱监督学习以及基于Transformer的方法对其他新技术进行介绍.
目前,人物交互数据集中存在少量类别占用大量样本的现象,数据分布不均使得训练难度增大.零样本学习(zero-shot learning,ZSL)由 Lampert等[47]提出,“零样本”表示算法模型从未见过某个特定示例,该方法利用语义属性来预测对象类标签,能将HOI检测应用于类的长尾问题.如图9所示,其工作原理可概括为利用处理好的已见类数据集帮助其他实例获得有效的特征表示,然后根据HOI类的属性描述进行组合表示,该表示可以看作是未见类和已见类的伪特征级实例描述.
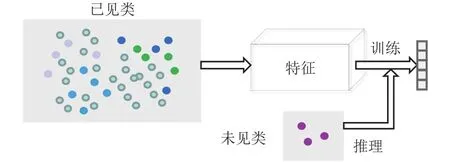
图9 零样本目标检测流程Fig.9 Flowchart of zero-shot object detection
Shen等[48]首次将零样本学习引入人物交互关系检测任务中,提出的HOI分解模型由一组视觉特征提取层与动词分离和目标检测网络组成.与基于视觉特征的方法不同,该模型分别对动词和目标对象建模,在测试时可以使用这些网络根据已见类的动词或宾语实例识别新的人-物对.该方法学习了成分动词和宾语的表示,有效抑制过拟合的现象.基于属性类间迁移的零样本学习,Eum等[49]将语义信息嵌入到前景对象所占据的局部区域中,使得对象的语义和空间的属性被联合嵌入到视觉的输入流中.Rahman等[50]在双流ZSL体系结构中使用动词-对象查询来推断人物交互,增强了零样本场景下视觉特征的表示.Peyre等[51]通过优化联合损失函数获得融合的语义与视觉嵌入空间,能在不同粒度层次的视觉语义空间中联合表示视觉关系.
Alessandro等[52]使用弱监督学习建立人物之间的交互模型,输入的图像仅使用动作标签注释,不带有人或物体的位置信息,这样能够大大减少训练需要的手工注释成本.Peyre等[53]引入了潜在变量来模拟参与交互的对象,使用预训练的目标检测网络为每个谓词构建分类器,并对潜在变量加以约束,从而合并图像级标签,该方法可用于预测从未见过的关系三元组.Sarullo等[54]使用功能属性图(affordance graph,AG)在人物表征和弱监督训练阶段提供预估标签,通过外部知识图像化的方式对动作和对象之间的关系进行建模.AG将物体和动作定义为节点,物体和动作的交互联系表示为边.其中,所有的链接设置为相互对称结构,且同一类型结点之间不存在连接关系,从而避免产生多余的语义组合.
Transformer是完全由注意力机制组成的编码器-解码器架构[55],在可扩展性和训练效率方面表现优秀,目前已被广泛应用于自然语言处理与计算机视觉等领域.Kim等[56]中第1次将Transformer架构扩展到HOI检测任务中,作者利用Transformer对交互之间的关系进行建模,同时实例解码器和交互解码器并行预测同一组对象,然后与定位实例框生成最终的HOI三元组.在Transformer的基础上,Tamura等[57]还添加了基于查询的检测模块选择性地聚合图像范围的上下文信息,避免了解码过程中多个实例特征的混合,目前在V-COCO数据集上达到了最优的检测精度.
表4归纳了本章的相关工作.总的来说,以上方法在图像范围的特征利用不足、全局实例框提供的上下文信息有限以及目标域的标注数据缺乏等方面有着广泛的研究空间.与单一的语义嵌入模型或视觉模型相比,零样本与弱监督学习方法充分利用了语义知识的指导信息,有效地提升了HOI检测在少样本场景数据集上的泛化能力.基于Transformer的模型在实际场景中能减少多个HOI实例重叠现象导致的错误检测.

表4 其他新技术总结Tab.4 Summary of other new technologies
4 挑战及展望
人物交互检测的研究工作已经扩展到物体功能、空间位置、人物姿态和语义描述等多个层面.随着与目标检测和行为识别相关领域的技术融合,人物交互检测技术趋向使用更加精准的局部特征来引导学习和推理.基于图像的HOI检测技术要从理论研究发展到实际应用,还面临如下挑战:
1) 交互类别欠全面.目前公开数据集的交互行
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
小猕猴学习画刊·下半月(2019年6期)2019-08-13
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
新高考·高一物理(2014年1期)2014-09-18
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
智慧与创想(2013年3期)2013-05-09
