
深度卷积神经网络在品牌服装图像检索中的应用
2022-08-25 09:56董访访
软件导刊 2022年8期
董访访,张 明,邓 星
(江苏科技大学计算机学院,江苏镇江 212100)
0 引言
随着电子商务的迅速发展,网络上有越来越多的服装图像,如何从海量的数据图像库中精确查找出自己想要的目标图像成为许多奢侈品官方网站的研究热点[1]。
图像检索技术最早于20 世纪70 年代开始浮现,从刚开始基于文本的图像检索技术(TBIR)逐渐转变为基于内容的图像检索技术(CBIR)[2]。在如今的网络商业中,许多购物系统将TBIR 作为搜索的主流方式,例如京东、淘宝购物平台都是在人工标注文本的基础上进行图片检索的[3]。基于文本的图像检索原理是对图片上人工标注过的关键词进行查询,关键词包括图像的颜色、形状等,虽然其检索精度高且速度快,但在数据量如此巨大的情况下,需要耗费更多的人力资源,且这种方法对图像描述不够充分,具有人为主观性,由此基于内容的图像检索迅速发展[4]。图像内容指其本身特征,包括形状、颜色、纹理等,常见的特征提取方法有SIFT[5]、SURF、HOG 和GIST 等。
Perronnin 等[6]为了实现对大规模图像的有效检索,提出利用Fisher 核作为连接局部特征到全局表示的编码方法度量相似性,并通过压缩Fisher 矢量达到减少内存并加快检索效果。Yang 等[7]提出基于形状相关性方法得到图像相似程度从而使检索准确率提高,但是该方法只侧重于服装形状特征,对于服装丰富的颜色、纹理等特征欠缺考虑。Ji等[8]针对服装细节设计了采用多尺度的方向梯度直方图特征进行检索,并利用投票选择的方法对其检索结果进行筛选,然而该方法对于背景复杂的服装图像,难以产生较好的效果。Lu 等[9]使用人体部位检测器检测图像中人物主体的关键区域,如肩、膝盖等部位,然后提取和融合这些区域的HOG、LBP、颜色矩、颜色直方图等特征,以此进行图像检索,但该方法过于重视局部特征,反而忽视了服装的整体特征。基于以上问题,为了降低图像检索时间损耗并提升准确率,越来越多研究人员将深度卷积神经网络强大的特征提取能力应用于图像处理,进而达到目的。
随着神经网络的较快发展,ImageNet 竞赛中在图像识别率上实现不断突破的网络模型,如AlexNet[10]、VGGNet、GoogLeNet 等相继被提出,并且网络层数也在不断加深。但通过以往实验发现,只将卷积层与池化层进行简单堆叠而成的深度网络,会出现梯度消失、梯度爆炸、网络退化等现象,进而影响检索准确率。2015 年,何凯明等[11]提出的ResNet 较好地解决了这些问题。当前,大多数研究人员利用深度卷积神经网络在大规模数据集ImageNet[12]上针对预训练好的模型提取图像特征然后进行图像检索[13]。卷积神经网络目前在检索性能上仍然存在片面化的问题,这是因为它在图像检索上虽然能提取到图像的深层特征,在细节处理上表现较好,但是对底层特征提取不充分[14],而对于服装图像,提取的特征也会受到图像的拍摄视角、背景图像、遮挡情况等影响,因此需要进一步对服装图像检索进行研究。
综上可以看出,近年来服装图像检索或多或少都存在冗余过大或者提取特征不充分进而导致检索精度不够高等问题,因此本文基于图像处理中的卷积核删减策略对VGG16 进行改进得到新的模型modify_vgg,以达到减少时间与空间复杂度的同时提升检索准确率的目的。本文最后通过实验对比分析改进的模型以及原VGG16 和Inception_v3模型在已有数据集上的性能表现。
1 研究方法与相关理论
1.1 卷积神经网络
卷积神经网络[15](Convolutional Neural Network,CNN)是一种典型的深度学习架构[16],主要由输入层、卷积层、池化层、全连接层和输出层组成[17]。通过以往的实验证明,图像基本特征如纹理、颜色等是通过卷积神经网络较低的层进行学习,图像抽象特征则是通过较高的层进行学习。神经网络的卷积层作用是利用卷积运算对图像局部特征进行提取。卷积运算简单理解就是利用一个固定大小的卷积核与图像的各区域像素依次进行矩阵相乘相加操作。一个待检索图像输入卷积神经网络中,然后将它的像素依次与各卷积核进行卷积运算,得到与卷积核个数相同的特征映射图,卷积运算公式如下:

其中,x(l)表示上一层的输出,k(l)表示l层中某个卷积核,b(l)表示偏置,则当前层的输出为:

其中,f(*)表示激活函数。
池化层的作用是防止过拟合,通过聚合统计各位置的特征,然后进行降采样得到维度低的统计特征,目前池化常用方法有最大池化和均值池化等。全连接层的作用是将所有特征连接后将输出值送给分类器进行图像分类。卷积神经网络模型与其他模型相比主要优点是输入图像不用经过复杂的前期处理,简化了图像预处理步骤。
1.2 VGG16 Net模型
VGG16 网络[18]是应用广泛的深度网络模型之一,由牛津大学计算机视觉组和Google Deep Mind 公司研究员于2014 年共同研发。VGG16 网络结构如表1 所示,该网络一共有16 层,包含13 个卷积层、3 个全连接层和5 个池化层,其中卷积层和全连接层有权重系数,计入总层数,池化层没有权重系数,不计入总层数。卷积层使用3×3 卷积核提取特征,池化层选择最大池化方法,全连接层对输出的特征进行加权和,用来分类,其中1 000 表示类别数目,可以根据自己的分类种数进行更改。

Table 1 VGG16 structure表1 VGG16结构
VGG 网络的特点是采用尺寸较小的3×3 卷积核(步长为1),极大降低了计算量。通过padding 对卷积结果进行填充,保证卷积后特征图尺寸和前层保持一致,然后通过池化层运算,特征图的尺寸降低为前一层的一半。
1.3 Inception_v3模型
在深度学习中,许多神经网络模型深度增加了,但是精度却不高,因为会出现过拟合,并且深度增加会导致计算资源消耗更大[19]。为了避免出现上述情况,Szegedy等[20]提出Inception 系列模型,该模型能够在提升精度的同时减少参数量。它是GoogLeNet 模型的其中一个系列。将多个卷积和池化操作组装在一起就形成了一个Inception 模块,将多个Inception 模块组装就形成了一个神经网络结构,它是一种更深更窄的网络,可以自动判断是否需要创建卷积层和池化层,并且自己选择卷积层中的过滤器类型,从而减少人工成本。
Inception_v3 是经过改进的GoogLeNet[21]版本,总共有46 层,由11 个改进的Inception 模块组成,其中一个改进的Inception 模块结构如图1 所示,与之前的Inception_v2 相比,它最重要的改进就是将7×7 的卷积分解成两个一维卷积(1×7、7×1)、3×3 分成(1×3、3×1)。这种做法可以在加速计算的同时对网络进行加深。此外,可以将一个卷积操作拆成两个,例如一个两个3×3 代替一个5×5,在处理更丰富的空间特征以及增加特征多样性等方面,这种非对称的卷积拆分比对称的卷积结构拆分效果更好,同时能减少计算量[20]。

Fig.1 Improved Inception structure图1 改进的Inception结构
2 服装图像检索方法
2.1 服装图像检索系统概述
本文图像检索的系统模型如图2 所示。图像检索步骤首先是对数据集中的每张图片分别进行特征提取并将其名字与特征一对一存到特征数据库中,对于待检索的图片采取同一模型抽取特征向量,然后将该向量和数据库中的向量进行相似度匹配即向量距离计算,找出距离最小的特征向量,其对应图片即为检索结果。
2.2 服装图像数据集
本文数据集源自某知名服装品牌的图片数据,通过网络爬虫技术从官方网站上获取图片,经过筛选剔除某些读取异常的错误图片后剩余约34 000 张图片,包括女装、男装、童装以及配饰、帽子、腰带等。按照8∶2 的比例将图片随机划分为训练集和测试集,训练集包括约27 200 张图片,测试集包含约6 800 张图片。所有图片均来源于网络,可能有少量干扰元素比如水印,此外可能也会受模特动作和拍摄角度的影响,同时有些图片背景复杂,可能也会对提取的有效特征产生影响,从而影响到检索结果。部分数据集如图3—图4 所示,图3 是无背景的图像,受背景影响较小,图4 为背景复杂的图像,检索效果可能会受背景图像影响较大。

Fig.2 System model图2 系统模型

Fig.3 Part of data set without background image图3 部分无背景图像数据集示例图

Fig.4 Part of data set with background image图4 部分有背景图像数据集示例图
对于输入的图像由于大小可能存在不同,因此需要对图像进行预处理后再进行特征提取。由于需要检测的目标图像的像素分布不确定,为了提高系统的通用性并确保数据集的特征一致,逻辑中将图片统一处理成(224,224,3)类型的数据作为神经网络的输入。
2.3 模型改进与评价指标
通过以上介绍可以知道,在卷积神经网络中,有些层比较重要,对特征提取起到重要作用,但是也有些层作用不大,因此对一些不重要的卷积核进行删除,将比较重要的卷积核进行保留,这样可以降低时间复杂度,减少冗余,节约计算资源。图像处理中的删减策略主要有基于权重的删减、基于相关性的删减以及基于卷积核的删减[22]。本文主要利用基于卷积核权重大小进行删减的策略开展实验。
基于卷积核的删减策略最重要的步骤是正确判断卷积核的权重,可根据如下规则判断权重:如果神经网络某一层中神经算子的一个子集能够无限接近原来的集合,就可以进行无失真替代,那么这个子集之外的其他集合就可以进行删除。在进行卷积核删减操作时,还可以采用对权重取绝对值并求和的方法,对于计算结果中较大的权值所对应的卷积核予以保留,较小的则可以删除。计算卷积核权重的一个方法是根据神经网络算子的矩阵作特征值分析,对特征值进行分解,然后将计算得到的大的特征值所对应的卷积核予以保留,较小的则删除。
特征值的分解过程可以简述如下:假设用于图像处理的卷积神经网络中,卷积层的卷积核为向量(Q,L,W,H),其中Q 为卷积核数量,L 为长度,W 为宽度,H 为深度。首先对该向量中的各元素进行绝对值处理,然后将其转换成(Q,L×W×H)大小的矩阵如式(3)。

然后将上述矩阵转变成协方差矩阵(4)。

最后对上述协方差矩阵进行特征值分解可以得到式(5)。

其中,δ1,δ2,…,δQ决定了卷积核的权重,数值越大表示权重越大,对应的卷积核越重要,就要将其保留,否则进行删除操作。
本文利用卷积核删减思想改进VGG16,通过将原来模型中需要保留的卷积核复制到新的模型中以完成删除操作,新的模型在本文中命名为modify_vgg。网络删减后神经元与神经元之间的连接改变,此时模型准确率一般会降低,且删除过度会造成图像不清晰,因此需要再采用较小的学习率对过度删除的网络模型进行微调修正,删减完之后需要对模型作进一步训练,采用梯度下降算法,通过较小的动量更新权重,避免删减过度造成特征损失,随着迭代次数增多,网络性能逐渐达到最优。
评价指标是评价图像检索系统好坏的指标,即图像检索精确度。本文图像检索的精确度一般由检索结果分类准确率决定,若检索结果所属类别正确则判定为1,否则判定为0。准确率p定义如式(6)。

其中,m为检索结果中的正确类别图像数量,k为返回的检索结果总数。
3 实验与分析
3.1 实验运行环境
本文实验运行环境是Intel(R)Xeon(R)CPU E3-1226 v3 @ 3.30GHz;运行内存为16GB,操作系统是64 位Windows10 企业版,开发工具为pyCharm,需安装Python3.6。
3.2 特征向量提取与度量
服装图像检索的关键步骤是对图像特征进行提取,然后将其保存到数据库中。方便后续进行特征比对时快速找到对应图像。本文通过Google Brain 团队开发的开源深度神经网络软件库TensorFlow 中的VGG16、inception_v3 深度神经网络模型以及改进的模型modify_vgg 对获取的数据集进行训练并提取特征。
本文实验采用在ImageNet 数据集上预训练好的初始化模型参数,池化方法均选择最大池化层,全连接层include_top 设为False,因为只需进行图像特征提取,无需通过全连接层对其进行分类。
特征提取:特征向量是指一系列有特定意义的数值,可以将图像抽象为一个特征向量。图像的相似程度就是特征向量之间的距离,距离越近相似度越高。特征提取完成后,为了方便后续实验,需要将提取到的feature 进行归一化处理,将数据归一化到[0,1]范围内,并进行存储。
特征相似度度量:两个特征向量之间的距离表示两张图片的相似度,该距离计算方式有多种,常见方法如表2所示。以两个特征向量ki和kj为例,其中ki={ki1,ki2,ki3,...,kin},kj={kj1,kj2,kj3,...,kjn}。

Table 2 Vector similarity measurement method表2 向量相似度度量方法
本文选择余弦距离作为度量方式,计算两个特征之间的相似性。
3.3 实验结果比较与分析
在自建的服装图像数据集上进行测试,提取图像特征,然后进行特征匹配,比较VGG16、Inception_v3 以及modify_vgg 在模型参数量大小、检索消耗时间、检索相似度及检索准确率4个方面的性能。
模型的参数数量比较如表3 所示,可以清晰看出VGG16 模型参数量巨大,经过改进的网络模型参数量明显减少。参数数量与特征提取时间成正比,因此在特征提取过程中VGG16 消耗时间最长,Inception_v3 模型消耗时间最短。

Table 3 Comparison of model parameters表3 模型参数量比较
模型检索时间比较如图5 所示,其中Inception_v3 模型检索时间随检索数量增多而呈指数增长,平均检索时间最长,其次是VGG16,modify_vgg 模型平均检索速率普遍高于其他网络。

Fig.5 Comparison of different model retrieval time图5 不同模型检索时间比较
3 种模型检索出来的图片特征相似度如图6 所示,平均相似度均随着检索数量增多而下降。综合看来,改进的modify_vgg 模型平均检索出的相似度最高,其次是Inception_v3。
特征相似度仅仅表示两个图片特征向量之间的距离,检索准确度在于检索出的图像类别正确率,即模型检索准确率。
本文将新的改进模型在测试集上进行准确率验证。其中,验证的图片集包括有背景和无背景的,验证结果是计算所有测试集图片的平均检索准确率,结果如表4所示。
实验结果表明,在本文使用的品牌服装数据集上,改进的modify_vgg 模型检索效果总体表现更优。因此,本文选用modify_vgg 作为最终图像检索模型进行图像检索展示。对于无背景图片的检索结果如图7 所示,有背景图片的检索结果如图8所示。

Table 4 Comparison of model retrieval precision表4 模型检索准确率比较
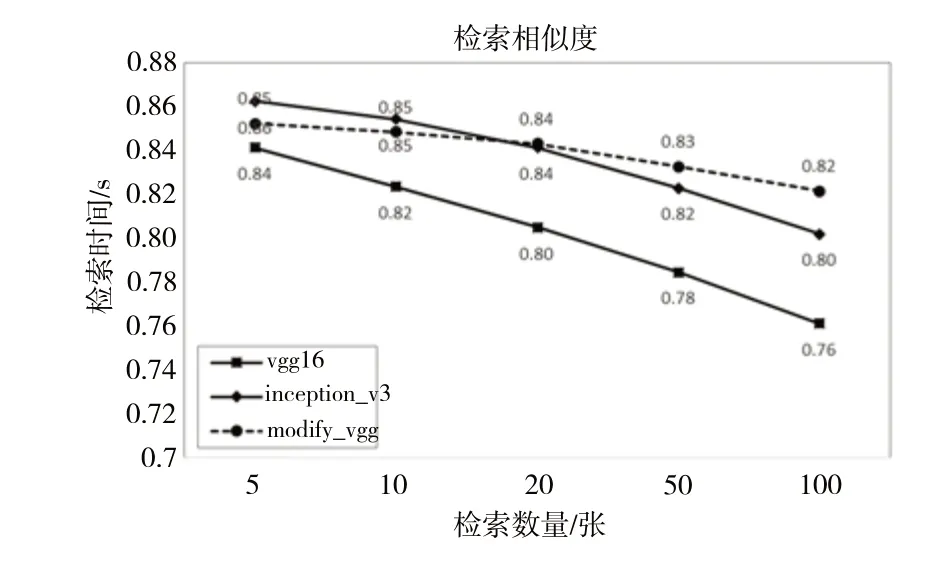
Fig.6 Comparison of different model retrieval similarity图6 不同模型检索相似度比较

Fig.7 Retrieval results of image without background图7 无背景图像检索结果

Fig.8 Retrieval results of image with background图8 有背景图像检索结果
图7、图8 中框选出来的图像是搜出来的同款,可以看出,无背景的图像检索出来的整体相似度比有背景图像的相似度更高。图8 中虽然检索出来的都是裙子的款式,但受背景颜色影响,整体样式相差较大,而图7 中待检索图像背景较简单,因此对检索结果影响不大,整体样式较为相似。
4 结语
深度学习的快速发展使得卷积神经网络提取图像特征的能力显著提升,本文在分析不同网络模型结构和特点基础上,分别采用经典的VGG16 和Inception_v3 模型,以及经过改进的modify_vgg 模型在品牌服装图像数据集上进行图像预处理后提取特征,将提取的特征保存为h5 文件,计算数据库中的特征向量与待检索图像特征向量之间的余弦距离,得到图像相似度,进而利用可视化界面进行展示。
从测试结果可以看出,由于模型参数量不同,占用内存空间不同,加载模型的速度也不相同,因此他们对品牌服装图像的检索效率及准确率也各不相同。对于检索的相似度,并不是层数越深相似度及准确率就越高,如含有13 个卷积层 的VGG16 相比46 层的Inception_v3 模型的检索准确率更高。经过实验验证,本文改进的modify_vgg 在检索准确率及效率上都有优势。
目前,深度卷积神经网络仍处于发展阶段,模型仍有许多不足,例如本文图像检索会受到水印、背景图、模特动作、拍摄角度等因素影响。因此,还需对图像处理作更深入的研究,比如:如何将图片中服装的主体精准定位进行特征提取;也可以对卷积层进行研究,让其提取特征更有效,大幅度提升检索效率和准确率。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
意林图解作文(小学版)(2019年6期)2019-07-16
电子制作(2018年19期)2018-11-14
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
自动化学报(2017年11期)2017-04-04
专利代理(2016年1期)2016-05-17
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
