
基于异质信息网络的推荐模型①
2022-08-25 02:52陈可迪陈心怡施科男
计算机系统应用 2022年8期
陈可迪, 赵 雷, 陈心怡, 施科男
(苏州大学 计算机科学与技术学院, 苏州 215006)
1 概述
近年来, 伴随着互联网技术的不断发展, 信息的洪流逐渐淹没人生活的方方面面, 以至于用户想要在短时间内获得自己需要的内容是一件非常困难的事情.为了解决这些问题, 个性化推荐系统应运而生.
传统的推荐系统模型主要有基于内容的推荐、基于协同过滤的推荐以及混合模型3大主流方法. 由于用户的历史信息过少, 即数据稀疏性问题, 可能会影响推荐系统的结果. 并且, 如果有新进入的用户, 那么此用户没有历史行为数据, 此时会产生冷启动问题, 无法根据用户的历史偏好进行有效的推荐. 为了解决这两个问题, 人们尝试引入补充信息(边缘信息)来协助推荐.
知识图谱是近些年来使用非常广泛的边缘信息之一. 以知识图谱(knowledge graph, KG)作为边缘信息构建的推荐系统主要有两类常规的方法. 第1类是基于知识图谱表示学习[1]的方法, 包括了联合学习, 交替学习和依次学习3种主要模式, 如联合学习中的KGCN模型[2]和交替学习中的MKR模型[3], 这些方法考虑到了实体之间的关联性, 但是没有充分利用知识图谱的语义信息, 从而未能够沿着知识图谱的边关系方向深度挖掘潜在的有价值的信息. 第2类是基于知识图谱路径信息的方法, 如Zhu等提出的知识注意力推理网络[4]等. 除了这两类以外, 知识图谱推荐系统还可以利用其他知识图谱或者是其他异质信息网络来进行知识的迁移学习, 但是这些方法所需要的数据量庞大, 需要的计算成本高并且跨领域学习解释性相对有限.
本文的模型可有效解决上述问题. 由于知识图谱中大多不止一种关系, 整个信息网络就蕴含了不止一种约束. 本文依次根据知识图谱中的每个三元组构建蕴含不同边信息的有向图, 从而形成了异质信息网络.随后通过构造两条元路径, 使用图神经网络(graph neural network, GNN)根据两层实体近邻学习得到用户和实体向量表示. 同时, 构建注意力网络连接知识图谱表示任务与推荐任务, 使俩任务同时进行. 最后, 利用知识图谱表示任务的损失作为约束项控制整体的训练过程, 从而实现了基于知识图谱表示学习和基于知识图谱路径信息的混合模型, 即异质信息嵌入知识图谱推荐模型(heterogeneous information with multi-task feature learning for knowledge graph recommendation,HeteMKR). 本文主要贡献如下:
1)结合了知识图谱表示学习和路径信息两种方法, 一方面利用了注意力网络强化了知识图谱和推荐任务之间的互动, 另一方面在知识图谱中融入了元路径信息, 充分挖掘被推荐项之间的潜在的语义联系.
2)在进行推荐的同时更新知识图谱的表示过程,将“用户偏好”的信息融入知识图谱的建模过程之中,将知识图谱嵌入(knowledge graph embedding, KGE)作为约束项, 来为整个模型进行正则化.
3)贡献了以DBLP (digital bibliography & library project) 论文数据集为基础的, 可被用作推荐任务测试数据集的文献图谱.
2 相关工作
2.1 相似度推荐与协同过滤
相似度推荐的方法, 是在所有待推荐项中计算与已知推荐项的相似度, 进行排序后选择相似度最高的项目, 从而进行推荐. 其常用的算法包括皮尔逊相关系数法[5]和聚类算法[6]. 皮尔逊相关性准确计算两个用户以及其属性之间的相似性, 该算法根据两个变量(或用户)的属性来度量两个变量之间的线性相关性, 对相似性进行量化处理. 而聚类算法是无监督学习的一种, 是根据事物自身的特性对被聚类对象进行类别划分的统计分析方法, 其目的是根据某种相似度度量对无监督数据集进行类别的划分.
协同过滤算法[7]是推荐系统中最早诞生的算法之一, 并且在推荐系统领域已经被普遍使用. 不同于之前的相似度推荐方法, 协同过滤的目标是找到其相似用户而不是相似性待推荐项, 其通过相似用户的喜好进而挖掘出目标用户的喜好. 在预测过程中通过使用目标用户的行为及日志等用户信息去挖掘目标用户的偏好模型, 然后通过这个偏好模型再去找出相似的带有该偏好模型的用户.
2.2 知识表示学习
随着数据类型逐渐多样化, 项与项之间的关系越来越复杂, KGE的难度也越来越高, 对知识的表示方法也同样提出的更高的要求. 知识表示学习, 这一新的研究方向受到了广泛的关注[8]. 知识表示学习的模型主要分为两类: 平移距离模型和语义匹配模型. 前者使用基于距离的评分函数, 后者使用基于相似度的评分函数.平移距离模型经过发展, 形成以TransE[9]为代表的翻译模型, 其通过计算真假三元组之间的差来进行向量表达方式的优化. 为解决TransE在处理1-N、N-1、N-N关系时存在的缺陷, 又派生出TransH[10]、TransR[11]和TransD[12]等模型. 语义匹配的代表方法则是RESCAL[13]模型和神经网络模型.
2.3 知识图谱推荐系统
将知识图谱作为边缘信息应用于推荐系统, 有基于路径的推荐方法和知识图谱表示学习的推荐方法.基于路径的方法将知识图谱视为一个异质信息网络,构造被推荐项之间的路径以此来挖掘实体之间的潜在关系, 如RKGE模型[14], 其基于循环神经网络来构造元路径并且推理路径信息. 知识图谱表示学习的推荐方法是为知识图谱中的每个实体和关系学习得到特征向量, 将特征向量输入传统的推荐模型进行训练. 结合知识图谱表示学习的推荐系统有3种训练方式, 分别是依次训练、联合训练和交替训练, 如依次学习DKN模型[15]利用图嵌入得到的特征进行推荐、联合学习Ripple Network模型[16]利用水波在水面传播模拟用户的兴趣在图谱上传播. 这些方法描述了真实世界中存在的各种实体概念, 以及他们之间的关联关系, 采用端到端的学习方式, 能够进行更精确的推荐. 本文模型则是基于知识图谱表示和基于路径表示的混合模型.
3 HeteMKR模型
3.1 推荐问题的形式化描述
常见的推荐场景中, 包含一个拥有m个用户的集合U={u1,u2,···,um}以及一个拥有n个被推荐项的集合V={v1,v2,···,vn}. 与此同时, 数据集还提供一个用户-被推荐项交互矩阵Rm×n, 矩阵中Ri,j的取值为1或者0, 表示用户i是否对被推荐项j进行了点击或者产生了兴趣.
除此之外, 本文使用知识图谱G作为边缘信息. 知识图谱G是由三元组(head,relation,tail)构成的,head表示头部实体结点,relation表示实体间的关系,而tail表示尾部实体结点. 在具体的推荐任务中, 被推荐项集合V和知识图谱G中的实体集合拥有非空交集, 知识图谱的头部实体集合和尾部实体集合也存在大量重合.
在拥有已知用户-被推荐项交互矩阵Rm×n和知识图谱G的前提条件下, 模型需要对新用户u对新的被推荐项v的点击率或者是否感兴趣进行预测. 整个推荐问题就可以公式化的表达为^γ =f(u,v|R,G).
3.2 模型设计
本文的模型HeteMKR在传统的知识图谱表示模型中, 融入了知识图谱中所隐含的元路径信息. 整体的模型框架如图1所示.

图1 HeteMKR模型
在图1所示的模型中, 首先将知识图谱中所有的三元组拓展成为异质信息网络, 沿着信息网络中人为规定的两条的元路径, 使用GNN得到相应的用户和被推荐项的向量表达. 随后利用交叉注意力网络进行推荐任务和知识图谱表示任务的交互, 即使用多个被推荐项向量对头实体向量进行学习建模, 而被推荐项向量本身则与权重矩阵内积. 最后将高维被推荐项向量与高维用户向量拼接后传入多层感知机(multi-layer perceptron, MLP)训练得到最后推荐任务的点击率预测结果. 知识图谱表示任务的尾实体预测结果则作为整个模型的正则项, 进行学习训练与约束.
3.3 异质信息网络与实体近邻
异质信息网络是一种具有多种连接关系的图结构.在异质信息网络中, 网络模式描述了网络的元结构——对象类型及其交互关系. 而元路径则是一个连接两个对象的关系序列, 其被提出用于捕捉对象之间的结构和语义关系. DBLP异质信息网络如图2所示, 不同实体节点之间使用不同类型(不同颜色)的边相连.
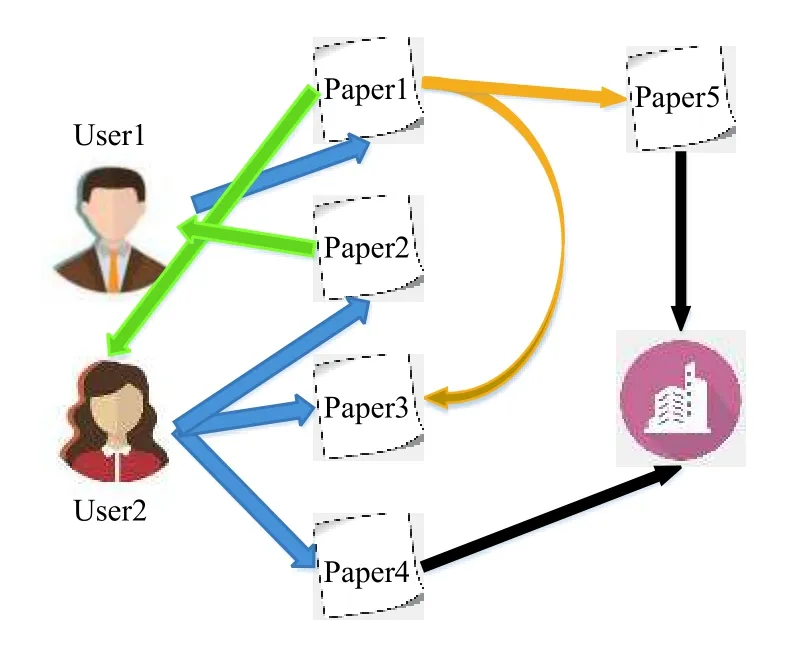
图2 DBLP异质信息网络
对于异质信息网络中的任意一个实体, 该实体在异质信息网络中的实体近邻被定义为: 由该实体作为起点, 经过一条边可以到达的所有的实体的集合. 同样地, 由该实体出发经过两条边可以到达的实体集合称作二阶实体近邻. 以图2为例, 对于实体User1, 其实体近邻为{Paper1}, 其二阶实体近邻为{Paper5, Paper3}.
3.4 基于元路径的图神经网络
元路径A1→A2→···→Al是指一个异质信息网络中的两个结点 A1和 Al的复合关系, 其不仅可以同时利用用户和被推荐项间的多种关系, 还使推荐具有了可解释性.
根据两条元路径, 即可对异质信息网络中的用户和被推荐项(或实体)进行向量化表示. 本文提出了一种基于两条元路径UTAT和UTT的图神经网络, 利用元路径来获取用户和被推荐项的不同步长的实体近邻,用户和被推荐项的向量是它们在不同元路径下的邻居的向量聚合. 首先使用统一的正态分布对向量初始化.图3表示了对于每一个用户实体u, 两条元路径中该实体的多阶实体近邻聚合的过程, 图中箭头的方向表示图神经网络的正向传播方向. 以路径UTT为例, 首先对于u结点的其中一个二阶近邻{ T1,T2,T3}, 使用映射函数g1于一阶近邻{ T5}, 从而蕴含了路径信息, 重新构建实体T5:
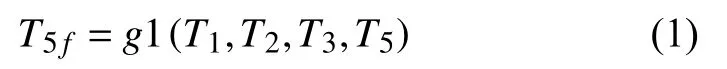
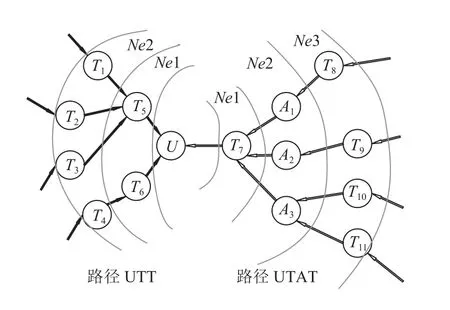
图3 基于元路径的图神经网络
同理可重构该路径下的用户实体向量, u1f表示经过第一条元路径UTT得到的用户实体向量表示:
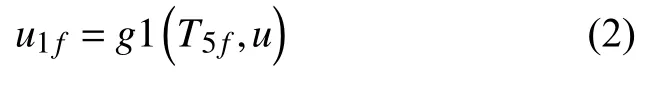
通过路径UTAT同理得到 u2f, 将两者使用函数g2融合, 得到最终的用户实体向量表示:
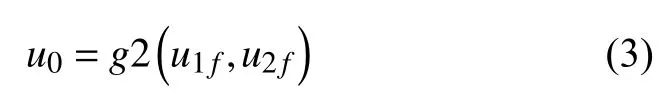
采用同样的方法可以获得被推荐项实体的向量表示. 其中函数g1和g2的选择将在实验部分展开论述.
3.5 交叉注意力网络
为了实现推荐任务和知识图谱表示任务之间的交互, 本文使用了被推荐项-实体交叉注意力机制网络,从而丰富了被推荐项向量和头部实体向量的特征, 如图4所示.
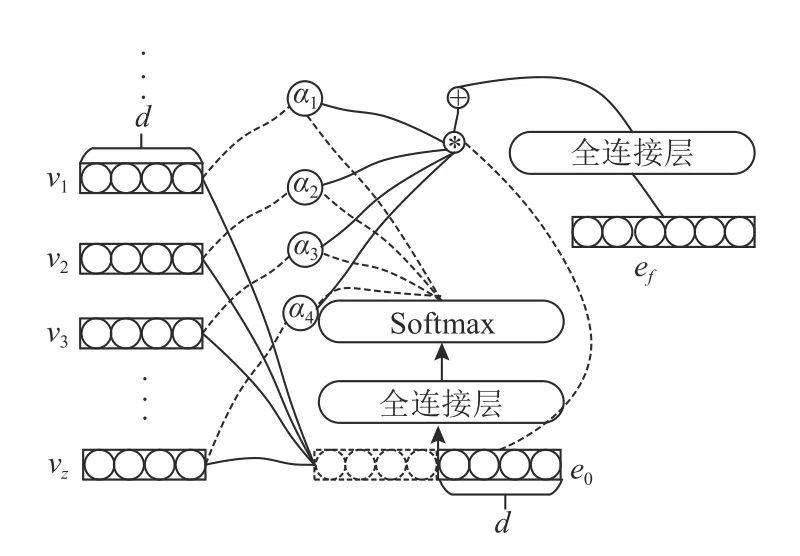
图4 项—实体交叉注意力机制网络
首先, 推荐任务经过z轮学习后, 将传入的z个d维被推荐项向量{ v1,v2,···,vz}与知识图谱表示任务中同样为d维的头部实体向量e0进行注意力交互, 再经过一个全连接层之后得到高维头实体向量:

其中,A代表一个全连接层. 每个被推荐项向量也同样通过全连接层, 以达到维度的扩增.
图中,vi(i=1,2,···,z)代表推荐任务经过z次学习后得到的z个被推荐项向量,e0代表初始化头部实体向量, 而ef则代表经过交叉注意力网络后的头部实体向量. 经过一个key的数量为z的交叉注意力网络的过程记为Cz. 推荐任务学习轮数与知识图谱表示任务学习轮数的比值z和向量维度d将在实验部分进行讨论.
3.6 推荐任务和知识图谱表示任务
在推荐任务中, 将用户向量u0经过全连接层得到最终的用户向量uf, 将其与交叉注意力网络输出的被推荐项向量结合, 从而得到预测的点击率.

其中,f表示预测函数(如MLP),表示点击率预测值.
在知识图谱表示任务中, 将初始化关系向量ro通过全连接层, 得到最终关系表征向量rf, 将其与交叉注意力网络输出的头部实体向量结合, 经过MLP从而得到尾部实体向量的预测向量.

其中,是尾部实体向量的预测值.
得到尾部实体向量后, 最终得到的三元组(head,relation,tail)的相似度使用得分相似度函数fKG得出:

其中,t是尾部实体向量的真实值. 在本文的模型中, 使用了归一化内积, 作为向量间相似度得分函数的选择.

3.7 学习优化
模型初始化之后, 完整的损失函数为:
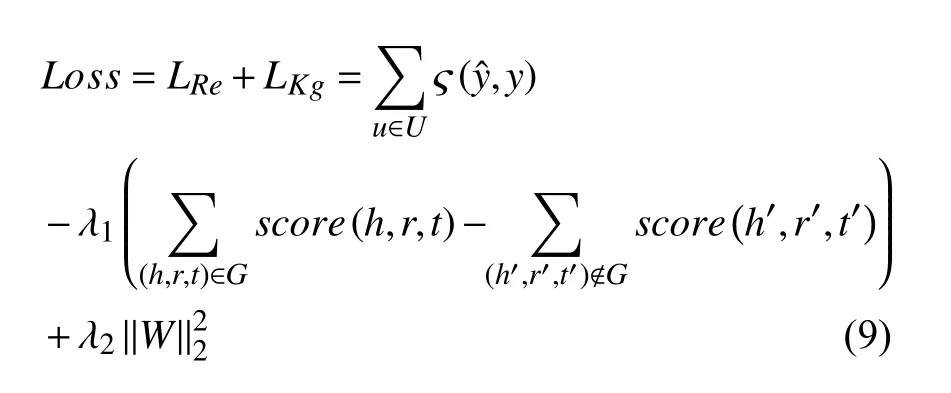
在损失函数中, 第1项为推荐层中函数的损失,ς为交叉熵函数,U和G分别是最初定义的用户集合和知识图谱. 第2项为知识图谱层中的损失, 本文需要增加真实三元组的得分并且减少虚假三元组的得分, 其中 λ1为 平衡参数. 第3项则是损失函数的正则项, λ2为正则项系数.
在整个训练过程中采取负采样训练, 在每次训练过程中在推荐任务上训练z轮之后, 在知识图谱表示任务中训练1次作为知识图谱的修正和信息的补充.λ1和 λ2作为参数的设定将在实验部分提及.
4 实验
在本节中, 本文将HeteMKR模型应用于两个来自真实生活中的推荐场景: 书籍推荐和论文推荐, 并且进行了性能的评估. 本文在推荐领域公开数据集Book-Crossing和我们自己创建的DBLP数据集上进行实验.
4.1 数据集
Book-Crossing数据集来自于Book-Crossing社区中的1 149 780个书籍评分(从1分到10分). Wang等[2]使用Microsoft Satori来为Book-Crossing数据集构建知识图谱. 由于此数据集大多为显式反馈数据, 所以将其转换成了隐式反馈: 若本文对每一个书籍条目标记为1, 代表用户对该书籍做出了评级; 若对书籍条目标记为0, 表示用户没有对当前书籍进行评级. 由于Book-Crossing数据集中无效信息很多, 数据的稀疏性很大, 所以没有设置正评级的阈值.
而本文还贡献了自己的DBLP论文数据集. DBLP网站作为大型数据库, 为了方便访问者快速地收集所需要的数据, 增加了“索引”——引文网络. 根据DBLP引文网络中的4 894 081篇论文和45 564 149个论文引用关系, 本文构建了DBLP知识图谱. 知识图谱包括了6种关系: 论文作者, 论文标题, 论文的发表年份, 论文关键词, 论文参考文献和论文出版商. 本文使用论文的引用量构建了用户-论文引用条目, 为了正负数据集之间的平衡, 将阈值设置为3, 从而构建了用户点击率列表. 同样, 本文对所获得的十万余篇论文数据进行了进一步筛选. 去除包含无效url链接以及6种关系数据不全面的实体条目. 最终提取出共包含10 001篇论文实体, 6种关系, 26 897个作者实体, 52个年份实体,76 310篇参考文献实体, 6 857个关键字实体, 1 174个出版社实体的共拥有251 702个三元组的DBLP图谱.
在DBLP数据集中, 本文将注意力放在知识图谱本身而非用户上, 所以仅将用户数设置为1, 从而通过结果可以更好地展现出本模型中知识图谱的表达能力,并且能够解决数据稀疏性问题.
两个数据集规模如表1所示.
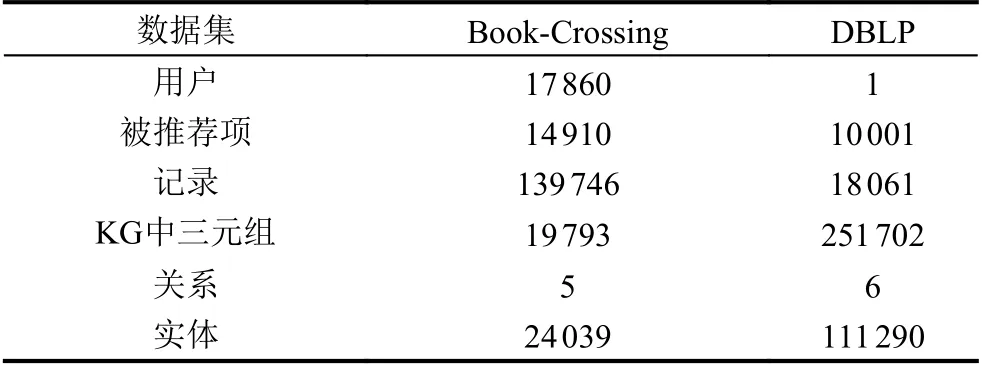
表1 数据集基本信息
4.2 评价指标
对于Booking-Crossing和DBLP两个数据集, 本文将训练集, 测试集按照8:2的比例进行划分. 调整参数后进行5次实验, 计算平均值作为最终结果.
本文在上述两个实际的推荐场景中使用点击率预测CTR, 对模型进行评估. 实验总共设置了4个评价指标: 曲线下面积AUC, 准确度Acc, 召回率Recall和F1.
4.3 参数设置
实验在两个数据集上的参数具体设置如表2所示.其中,g1和g2表示图神经网络的聚合函数,d表示用户向量和被推荐项向量的初始维数, λ1和 λ2分别表示总体的损失函数平衡参数和正则项系数,z表示一个周期中推荐任务和知识图谱表示任务训练次数之比,lr表示学习率.

表2 实验参数设置
4.4 超参数对比实验
首先, 对于向量维度, 本文分别在d=16, 32, 64,96的设置下进行了实验, 实验结果如图5所示. 在Book-Crossing数据集上, 一开始小维度向量对于实验结果的影响趋于平稳, 而在DBLP数据集上也是缓慢增长, 但是两者的实验结果AUC都在d=64左右达到了最值点. 当d继续上升时, 向量中将会蕴含大量干扰信息, 比如噪点等, 从而无法达到最好的信息表达效果.

图5 d对AUC的影响
为了让知识图谱的知识表示训练和推荐任务的交互达到最好的效果, 本文测试了一个周期中推荐任务和知识图谱表示任务训练次数之比z对结果的影响,z的取值分别是1, 3, 5, 10. 实验的结果如图6所示.

图6 z对AUC的影响
首先对于公开数据集Book-Crossing, AUC在z=3的时候达到了最值, Book-Crossing中用户的数目可观,并且用户被推荐项的交互条例数较多, 从而首先对推荐任务进行少量次数的训练后便可以得到相对良好的建模结果. 但是对于DBLP数据集, 虽然知识图谱中三元组数量是Book-Crossing的数量的5倍左右, 但是由于数据集仅针对单一用户设计, 从而用户数量有限, 因此用户论文交互难以集中, 为了达到相应的建模效果就必须增大z的数值. 最后我们发现, 对于DBLP数据集, 当z很小时, AUC约等于0.5, 表明整个模型近乎随机分类, 只有当z=5时结果才有所改观, 并且达到了最大值, 而当z大于5, 则又容易产生过拟合现象.
最后, 本文对图神经网络聚合函数g1和g2进行了实验分析. 一共使用了Mean, GCN, Pooling和LSTM四种聚合方法. 两种聚合函数的实验结果分别如图7和图8所示.

图7 聚合函数g1对AUC的影响

图8 聚合函数g2对AUC的影响
实验结果表明, 在两个数据集中同一路径内近邻聚合时采用LSTM达到了AUC的最高值0.73和0.74.而在进行两条路径之间进行聚合时, 对于Book-Crossing数据集适合使用Mean方法, 而对于具有很强稀疏性的DBLP数据集则使用Pooling时达到了AUC的最高值0.71.
4.5 对比实验与消融实验
本文将HeteMKR模型与近些年来优秀的知识图谱推荐方面的模型进行了比较, 这些优秀的模型如下.
MEIR[17]: 将KG视为异质信息网络, 并提取基于元路径的功能, 以表示用户和项目之间的连接. 在本文中, 对于Book-Crossing数据集, 使用“用户-书籍-流派-书籍”这一条元路径.
DeepFM[18]: DeepFM是FM的衍生算法, 其使用FM做特征间低阶组合, 用DNN做特征间高阶组合,通过并行的方式融合了连续的特征和离散的特征.
DKN: DKN的关键部分是一个多通道和单词-实体对齐的知识感知卷积神经网络(knowledge-aware CNN, KCNN), 它融合了新闻的语义层面和知识层面的表示. KCNN将单词和实体视为多个通道, 并在卷积过程中显式地保持它们之间的对齐关系.
MKR: 利用知识图谱嵌入去协助推荐任务, 两个任务是相互独立的, 但是由于推荐系统中的item和KG中的实体相互联系而高度相关, MKR使用交叉压缩单元交替优化推荐和知识图谱表示任务来训练.
实验的最终结果如表3所示. 由表中结果可以知道, MEIR在DBLP上近乎随机分类, 而DeepFM则需要将数据集处理成离散和连续两种形式, 这对于统一标号的知识图谱实体无法形成区分. DKN模型的效果也不尽人意, 这是由于DBLP数据集难以展现具体物品的语义信息, 只能够从知识层面建模, 但是由于DBLP数据集只设置了一个用户, 所以在这个数据集上注意力机制发挥了一定的作用. 而MKR方法则有较好的表现. HeteMKR的性能最为优异. 最后本文还实验了HeteMKR的变体: 使用LSTM替代MLP. 这样的效果没有提升, 并且加大了运行的成本. 本文还进行了消融实验, 发现减少了模型中的GNN或者注意力机制后,模型的性能将会下降明显.

表3 在Book-Crossing和DBLP数据集上的点击率预测
5 结论与展望
本文提出的异质信息嵌入知识图谱推荐模型将知识图谱转化为了异质信息网络, 提取出其中的元路径信息, 通过图神经网络将其融入到知识图谱中, 再利用交叉注意力网络连接推荐任务和知识图谱表示任务, 最后进行用户点击率预测. 本文还提供了原创的DBLP数据集, 包括DBLP用户点击率条目和DBLP知识图谱.最终实验在公开数据集Book-Crossing和DBLP数据集上均比其他算法在AUC,F1等指标上达到了更好的效果.
我们计划进一步使用实体关系抽取等方法优化自己的知识图谱, 并且期望对于特定的用户, 能够在推荐系统中以时间序列进行被推荐项的动态推荐.
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
家庭教育报·教师论坛(2021年42期)2021-12-23
科学导报(2020年44期)2020-07-27
经济数学(2020年4期)2020-01-15
分析化学(2019年3期)2019-03-30
新城乡(2018年6期)2018-07-09
新教育时代·教师版(2016年26期)2016-12-06
求知导刊(2016年30期)2016-12-03
职工法律天地·下半月(2016年10期)2016-11-30
