
基于深度学习的多模态融合三维人脸识别①
2022-08-25 02:51胡乃平贾浩杰
计算机系统应用 2022年8期
胡乃平, 贾浩杰
(青岛科技大学 信息科学技术学院, 青岛 266061)
近年来, 得益于数据集的日益庞大和硬件设备日新月异的发展, 深度学习应用越来越广泛, 带动了人脸识别的快速发展. 目前二维人脸识别已趋于饱和, 在光照统一、表情一致的实验室条件下, 识别准确率已经非常高. 但是二维人脸识别受光照、遮挡和姿态等的影响较大, 在光线昏暗、面部遮挡的情况下, 不能正确地识别出人脸.
三维人脸除了包含彩色图的纹理信息之外, 也包含了深度信息. 相对于二维人脸识别, 三维人脸识别应对遮挡、光照和姿态的变化更具有优势. 因此, 三维人脸识别适合更多的场景. 三维人脸识别根据数据来源的不同可分为3类: 基于RGB图像的三维人脸识别、基于高质量三维扫描图像的三维人脸识别、基于低质量RGB-D图像的三维人脸识别. 基于RGB图像的三维人脸识别通过RGB彩色图像重建三维人脸模型, 但是重建模型较为复杂, 且参数极多速度较慢. 基于高质量图像的三维人脸识别使用高质量三维人脸数据进行识别, 但是获取高质量的三维人脸数据代价高昂, 需要特定的高精度扫描仪进行采集, 并且采集的数据非常大, 会导致模型过于复杂. 目前高精度三维人脸数据集有Bosphorus[1]和BU-3DFE[2]等, Bosphorus为点云数据, BU-3DFE为网格数据. 基于低质量RGB-D图像的三维人脸识别采用的数据来源于RGB-D相机, 这类相机能够同时采集彩色图和深度图, 速度快且成本较低.但是低质量的深度图存在大量的空洞、毛刺, 造成识别困难. Mu等人[3]单独使用低质量深度图训练神经网络, 得到的模型训练准确度较低. 这说明了单独使用低质量深度图进行人脸识别难以进行有效的区分. 因此本文使用基于低质量RGB-D图像的三维人脸识别方法, 结合彩色图和深度图进行人脸识别, 弥补单独使用低质量深度图的不足. 低质量人脸深度图的数据集有Lock3DFace[4]、EURECOM[5]和Texas3DFRDatabase[6]等, 深度图数据集都含有对应的彩色图. 本文使用的数据集是Texas3DFRDatabase.
1 相关工作
本节介绍基于高质量图像的三维人脸识别方案,基于低质量RGB-D图像的三维人脸识别方案和人脸识别损失函数.
基于高质量图像的三维人脸识别. 随着技术的进步, 学者逐步转向三维人脸识别, 但是高质量三维人脸数据库数量依然比较少. Gilani等人[7]在现有高质量三维人脸数据的基础上, 通过不同图像之间的组合来合成新的人脸数据, 并且得到不同视角下的点云数据, 用来训练CNN. Cai等人[8]在三维人脸数据上选取眼睛和鼻尖3个点进行姿态校准. 之后从三维人脸图像中提取4个子图像, 4个子图具有一定的重叠, 把子图分别输入到CNN中, 得到4个特征向量串联进行识别.Kim等人[9]将单一的三维人脸数据合成多个不同表情的人脸数据, 之后对二维人脸识别模型进行迁移学习,少量的数据得到不错的效果.
基于低质量RGB-D图像的三维人脸识别. RGBD图像包括彩色图和深度图. 单独使用深度图进行识别任务不能得到较好的效果, 因此将彩色图和深度图进行融合会得到更好的识别结果. 融合的方式分为3种: 信号层融合、特征层融合、决策层融合[10]. 信号层融合即在原始图像上进行融合. Kusuma等人[11]使用主成分分析(PCA)在信号层方面融合了二维人脸图像和三维人脸图像, 并探讨了不同模态数据之间的依赖关系. Jiang等人[12]将二维数据的3通道和三维数据的3通道组合成6通道的数据输入到卷积神经网络中进行识别. 特征层融合即将不同模态数据的特征进行融合. Lee等人[13]使用两路神经网络分别提取彩色图和深度图的特征, 并进行融合. 并且针对训练数据不够的问题进行了迁移学习. Li等人[14]利用多通道稀疏编码进行不同模态之间的人脸对齐, 提取不同模态的人工特征进行特征融合. 决策层融合分别对不同模态的数据进行识别, 将对应得分通过策略进行融合. Chang等人[15]使用主成分分析法对彩色图和深度图进行识别, 将两个得分进行加权融合. Cui等人[16]对3种融合进行了对比研究, 并且提出了一种基于特征层和决策层的混合融合, 取得了当时最先进的性能.
人脸识别损失函数. 通常来说, 识别或分类任务使用Softmax损失函数, 但是Softmax损失函数只能保证目标具有可分性, 对人脸识别这种类间相似性较大的任务来说, 具有非常大的局限性. 因此, 损失函数是人脸识别方向的研究热点. 人脸识别损失函数主要有两种思路: 减少类内差异, 增大类间可分离性. 基于第1种思路, Wen等人[17]提出了中心损失(center loss),惩罚了样本与其中心的欧氏距离, 将相同的类聚集在类特征中心周围, 减少了类内差异, 结合Softmax损失函数, 取得了不错的识别效果. 基于第2种思路, Deng等人[18]提出角边缘损失, 将角度约束加入到Softmax损失函数中, 极大限度地提高了类间可分离性, 能够获得人脸的高分辨率特征. Cai等人[19]结合两种思路, 提出了岛屿损失(island loss), 顾名思义, 使相同的类聚集在一起像岛屿一样, 减少类内变化的同时扩大类间的差异, 性能得到显著提升.
本文的主要贡献如下:
(1)设计自动编码器将彩色图和深度图在特征层面进行融合. 得到融合图像作为识别任务的输入.
(2)基于巴氏距离的思想, 提出一种新的损失函数cluster loss. 结合Softmax损失进行识别任务, 不仅能够减少类内的变化, 而且能够扩大类间的差异.
(3)使用迁移学习, 将融合图像训练得到的模型使用彩色图像进行微调. 得到的新模型使用彩色图像作为输入, 依旧可以克服光照和面部遮挡这一缺点. 将人脸彩色图像模拟戴口罩和变暗, 识别率依然较高.
2 算法
2.1 多模态融合
多模态融合指融合不同形式的数据. 本文需要融合的数据是人脸的彩色图和深度图. 使用卷积自动编码器对两种不同形式的图像进行融合. 卷积自动编码器是将传统的自编码器的无监督学习方式, 结合了卷积层、池化层、上采样层或者转置卷积层等操作. 图像经过解码层得到特征向量, 特征向量经过编码层得到重构图像. 自编码器自动从样本中学习相关特征而不是通过人工进行提取.
卷积自编码器网络结构如图1所示. 网络分为编码层和解码层. 编码层包括4组卷积层+池化层和两组全连接层. 解码层包括4组卷积+上采样层和一个卷积层. 原始图像r和d分别是同一人脸图像的彩色图和深度图, 具有互补的关系. 彩色图和深度图同时作为卷积自编码器输入, 经过编码层之后, 得到两组1 504维的向量. 将两组1 504维的向量进行串行结合得到3 008维的向量, 并将融合后的向量和两组1 504维的向量作为解码层的输入. 经过解码层之后, 两组1 504维的向量会分别输出重构图像, 融合向量会输出融合图像. 公式表示如下:
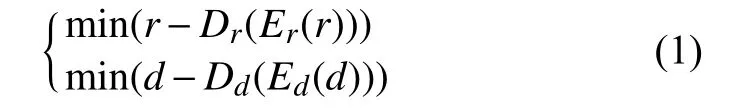
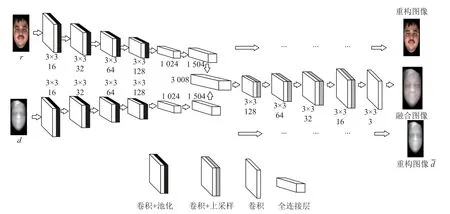
图1 卷积自编码器网络结构
以图像r为例,Er是图像r的编码过程, 从r中提取特征,Dr是图像r的解码过程, 通过特征解码出重构图像图像d亦是如此. 图像r和d分别学习各自的特征, 在编码层末端将特征进行串联, 解码层共享权重,实现不同模态特征的联合统一表达. 损失函数是原始图像与重构图像之间的差值, 损失函数公式表示如下:
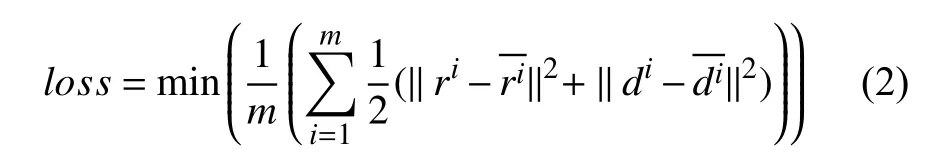
其中,m表示共有m组数据,ri和di分别表示原始的彩色图和深度图,和表示重构的彩色图和深度图.
在使用卷积自编码器进行多模态数据融合时, 有以下几点说明:
(1)不能将全连接层去掉或者使用卷积层代替, 否则编码器不能学习到有用的特征, 图像无法正常生成.全连接层的作用是打乱空间结构. 全连接层可用1×1的卷积网络去代替, 1×1的卷积网络也可打乱空间结构, 并且参数比全连接层少, 速度更快, 缺点是重构图像效果没有使用全连接层的效果好.
(2)解码层的卷积+上采样层可用转置卷积(transposed-convolution)[20]代替, 转置卷积为卷积的反向操作, 可以使低分辨率图像向高分辨率转换. 但是文献[21]中指出使用convolution+upsample组合, 较之于transposed-convolution, 可以更好地生成图像细节,并且运算速度相当. 因此本节算法使用convolution+upsample组合.
2.2 损失函数
人脸识别或者表情识别存在着较高的类间相似性,导致识别性能显著下降. 传统的卷积神经网络进行人脸识别任务时, 使用Softmax loss作为损失函数, 惩罚分类错误的样本, 能够分离出不同类别的特征, 但是特征向量是分散的, 并且会出现不同类别的特征重叠的情况, 如图2(a)所示. Wen等人[17]提出了center loss,结合Softmax loss, 实现了类内紧致性, 计算每一个类的中心, 并惩罚了每一类的样本和类中心之间的距离.使特征向量聚集在一起, 但是center loss没有考虑到类间相似性, 依然会出现特征重叠的情况, 如图2(b)所示. 本节提出了一种新的损失函数cluster loss, 能够提高人脸特征的判别能力. 惩罚不同类别的类中心之间的相似度, 将不同的类别远远推开. 结合 Softmax loss,不仅实现了类内紧致而且能够扩大类间差异, 如图2(c)所示. 在本节首先简要回顾一下center loss, 然后重点介绍我们提出的损失函数cluster loss.
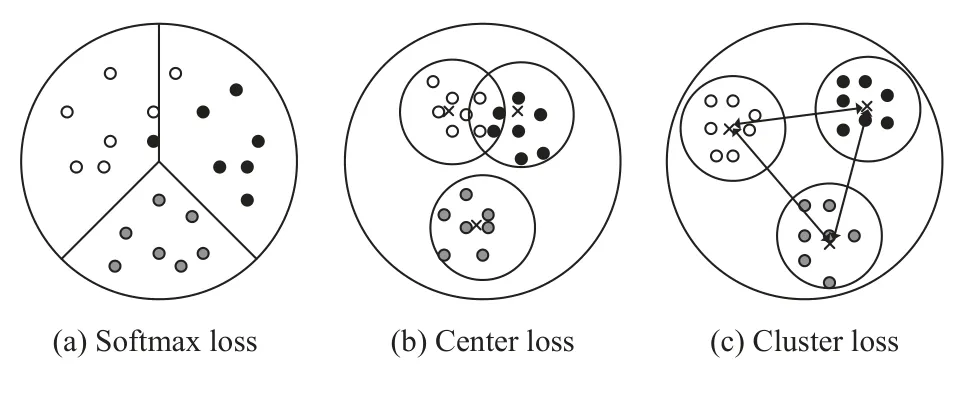
图2 3种损失函数示意图
2.2.1 Center loss
Center loss为特征向量与类中心的距离的平方和,公式表示为式(3):
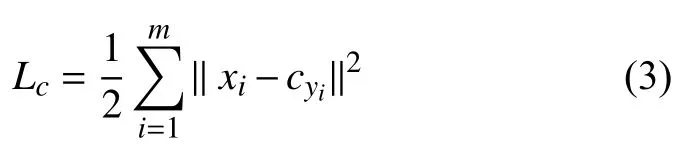
其中,yi为样本xi对应的类别,cyi为类别yi的类中心.前向传播过程中, 损失函数为联合Softmax loss和center loss的加权和, 公式表示为式(4). λ为平衡因子,用来平衡两种损失函数.

2.2.2 Cluster loss
如图2(b)所示, 单纯使用center loss不能避免特征重叠的情况, 为了解决这个问题, 我们提出了一个新的损失函数cluster loss, 能够扩大类间差异. 使用巴氏距离定义cluster loss, 并用来衡量两个向量之间的距离. Cluster loss公式表达为式(5):
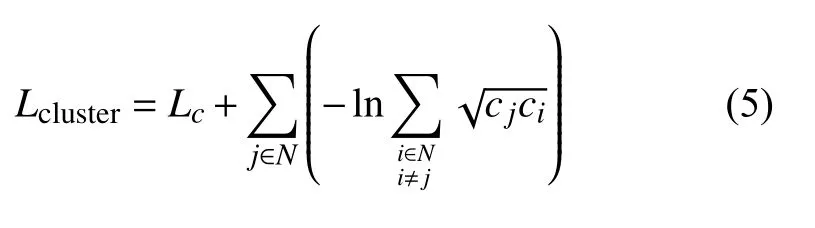
其中, 第1项为center loss, 用来惩罚样本与对应类中心之间的距离, 第2项表达式用来减少不同的类中心的相似性, 以扩大类间距离.N为类别标签集合,i和j分别代表不同的类别,ci和cj分别是i和j对应的类别中心. 前向传播过程中, 整体损失函数由式(6)给出:

式(6)为Softmax loss与cluster loss的加权和,λ为平衡因子, 用来平衡两种损失函数. 由图2所示, 网络由两个输出Out1和Out2, Out1用来计算Lcluster,Out2用来计算Ls.
反向传播过程中, cluster loss对输入样本xi的偏导数可计算为式(7), 偏导数将反向传播到全局池化层和卷积层.

计算第j个类的特征中心的差值, 公式为式(8):
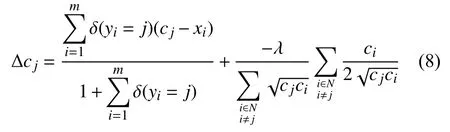
其中, 第1项是中心损失计算的特征中心的差值, 第2项是对Lcluster的第2项求cj的偏导数得出第j个类的特征中心的差值. 使用随机梯度下降算法(SGD)来对每一批次数据的第j类的特征中心进行更新, 学习率是α, 公式为式(9). 在算法1中, 我们给出了使用cluster loss进行识别任务的算法伪代码.
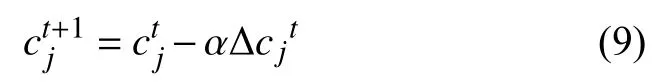

算法1. 使用cluster loss进行识别任务的算法伪代码输入: 已经标记的训练数据{xi, yi}μ α λ ω 1. 初始化批次大小为m, 训练轮次T, 学习率 和, 超参数, 网络权重 和cluster loss参数cj.2. for t in range(1, T+1)L=Ls+λLcluster 3. 计算整个网络的损失函数∂Lt∂xit=∂Lst∂xit+λ∂Ltcluster∂xit 4. 计算反向传播的误差ct+1 j=ctj-αΔcjt 5. 更新cluster loss参数ωt+1=ωt-μ∂Lt∂ωt=ωt-μ∂Lt∂xti∂xit∂ωt 6. 更新网络权重7. end for ω输出: 网络权重 , cluster loss参数cj和网络损失
2.3 迁移学习
迁移学习, 即让模型具有举一反三的能力. 让网络在任务A中学习到的知识应用到任务B的学习中, 使得网络不仅有任务A的知识也有任务B的知识, 任务A和任务B需有一定的相关性. 文献[22]通过大量实验证明了深度学习中迁移学习的可行性. 迁移学习包括4种: 样本迁移、特征迁移、模型迁移和关系迁移[23].本文我们使用模型迁移. 如图3所示, 首先使用融合图像预训练一个模型, 将预训练模型的block1, block2,block3中的所有层的冻结, 不进行权重更新, 然后使用RGB图像作为输入, 对预训练模型的其余层进行训练.之所以冻结3个block中的网络层, 是因为在卷积神经网络中, 前面几层学习到的都是通用特征, 越靠后的层学习到的特征越具有特殊性[22].
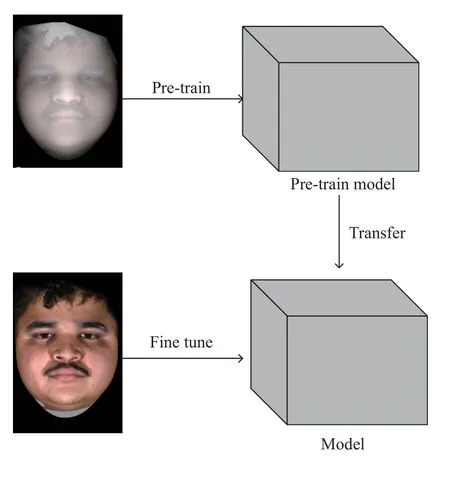
图3 迁移学习过程
3 实验结果和分析
3.1 数据处理和训练策略
本文实验使用RGB-D人脸数据集Texas3DFRDatabase, 共118个人的1 149个样本. 使用TensorFlow 2.0深度学习框架来搭建网络. 实验室GPU型号为GTX1080Ti.首先使用第2.1节中提到的自动编码器进行RGB数据和深度数据的融合, 图4分别展示了RGB图像、深度图像和融合图像. 对融合图像进行处理, 包括以下几部分.

图4 RGB图像、深度图像、融合图像
(1)用dlib库自带的frontal_face_detector特征提取器进行人脸检测, 并提取出人脸图像.
(2)将提取出来的人脸图像大小重新设置为112像素×112像素.
(3)数据增强. 随机对图像进行水平翻转、亮度调整, 裁剪、添加噪声, 以防止过拟合问题.
(4)将增强后的图像进行归一化. 将每一像素的数据类型转换为float32, 再把每一个像素值除以255, 使得每一个像素的值在0–1之间.
本文实验在使用融合图像预训练模型时, 批量为64, 共训练60轮. 图2中Out1使用cluster loss进行监督训练, Out2使用Softmax loss进行监督训练. λ设置为0.07. 前40轮使用Adam优化器[24]对损失函数进行优化, 学习率设置为0.001, 后20轮用SGD优化器[25]进行优化, 学习率设置为1×10-4. Adam的优点是收敛快速, 而正是因为他的优点使得算法有可能错过全局最优解, 因此在前期使用Adam加快收敛速度, 后期切换到SGD, 慢慢寻找最优解. 完成训练后得到一个预训练模型, 然后对预训练模型进行微调. 以RGB图像作为输入, 冻结block1、block2和block3中的所有层, 使用SGD, 学习率设置为1×10-4, 对剩余层训练40轮, 得到最终模型. 除此之外, 本文分别使用Softmax loss和Softmax loss + center loss对模型进行预训练, 用来和本文提出的损失函数进行对比.
3.2 不同算法性能比较以及λ 的选择
为了评估有效的评估cluster loss, 本文在其他因素不变的情况下, 根据不同的损失函数先后训练了3个模型: 1)基于Softmax loss; 2)基于Softmax loss +center loss; 3) Softmax loss + cluster loss. 表1展示了3种算法训练的结果, 单独使用Softmax loss的识别准确率为92.06%, 加入center loss之后, 准确率提升了2.29个百分点, 为94.35%, 使用Softmax loss + cluster loss准确率为97.13%, 提升了2.78个百分点. 图5为3种模型在训练过程中的对比. 单独使用Softmax loss收敛最快, 但是准确率相对较低. Softmax loss +center loss和Softmax loss + cluster loss在训练过程中局部有准确率下降的现象, 但是不影响最后结果.

表1 3种算法训练结果(%)
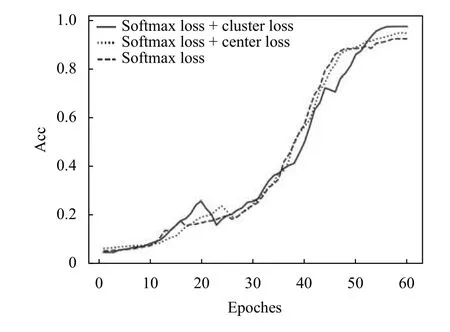
图5 训练过程对比
超参数λ 为平衡因子, 用来平衡两种损失函数, 选择合适的λ 是非常重要的, 能够将两种损失函数达到最佳状态下的平衡, 提高识别准确率. 本文将 λ控制在0–0.1之间, 测试了不同的λ 对准确率的影响, 实验结果如图6所示, λ值在一定范围内时, 准确率波动不是很大, 相对稳定. 当λ=0.07左右时, 准确率达到峰值, 因此本文中λ 选取0.07.
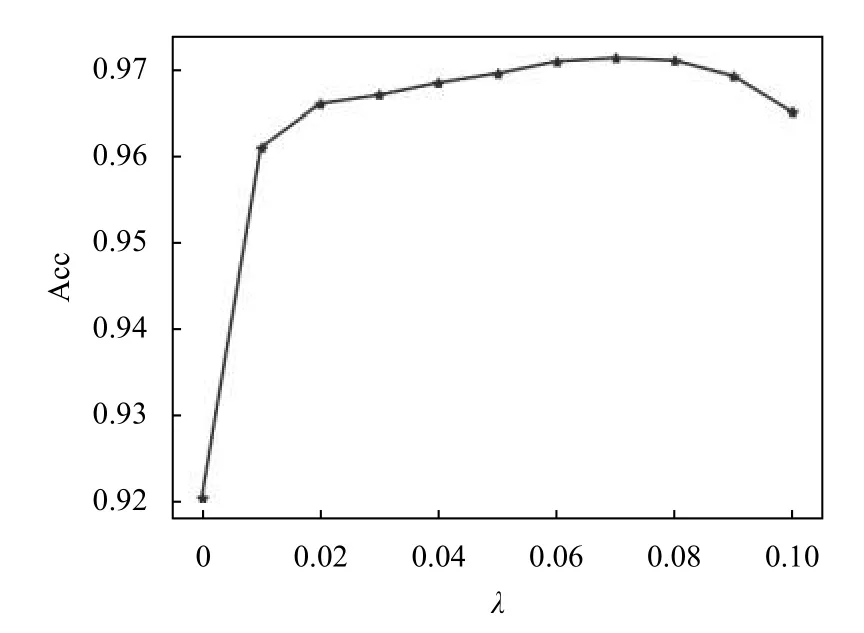
图6 不同λ 值对准确率的影响
3.3 测试
本文论述的是三维人脸识别, 前期使用未遮挡、没有光照变化的人脸图像作为训练集, 因此后期我们需要使用有遮挡、有光照变化的RGB人脸图像进行测试来验证本文提出的三维人脸识别算法的有效性.我们对原始数据集进行了处理, 给人脸加口罩和墨镜模拟了人脸图像在真实条件下的遮挡, 人脸图像调暗模拟光线昏暗的情景, 具体算法本文不详细论述. 处理后的条件如图7所示, 分别表示加入口罩、墨镜和光线变暗之后的图像. 处理完之后, 使用处理后的数据分别测试3种算法生成的模型, 表2展示了测试结果, 限于篇幅原因, S即为Softmax, 记录了3种算法中不同条件下的识别准确率和平均准确率, 由表可以看出,3种算法在不同情景下的准确率相较于使用原始数据训练时都有略微的下降, 这属于正常现象. 本文算法在3种情景下都取得了最好的结果, 并且具有很好的鲁棒性, 最后平均准确率高达96.37%.

图7 加入遮挡、光线处理后的图像

表2 3种算法在不同条件下的识别准确率比
3.4 过拟合分析
本实验中, 仍然存在着过拟合现象, 即训练误差与测试误差相差较大, 其原因在于数据量过小. 在算法中采用了dropout和图像增强(水平翻转、亮度调整, 裁剪、添加噪声)的方法在一定程度上降低了过拟合现象. 图8展示了使用dropout和图像增强方法对过拟合的抑制程度. 由图可知dropout和图像增强都对过拟合有一定的抑制作用, 两者结合使用效果非常明显, 但是使用图像增强之后, 训练误差上升了一小部分.
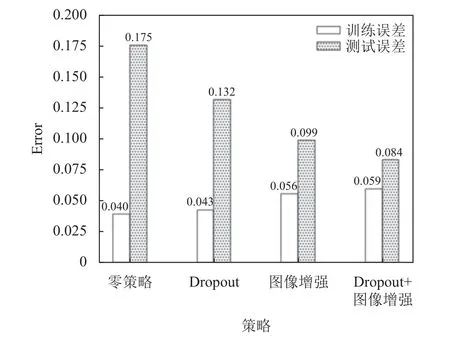
图8 Dropout和图像增强方法对过拟合的抑制程度
3.5 多模态有效性实验
为了验证多模态融合特征在三维人脸识别任务中的有效性, 设计了3组实验, 分别将融合后的图像、深度图和RGB图像作为输入, 进行训练, 3个模型除输入数据不一样之外, 其余均一致. 训练完成之后, 分别用正常人脸图片、带遮挡人脸图片和暗光线环境下的人脸图片进行测试. 表3记录了不同测试环境下的识别正确率.

表3 多模态有效性实验结果
实验结果表明, 使用多模态融合数据训练出的模型比单独使用RGB数据进行训练出的模型, 在正常环境下测试的准确率稍低, 但是在遮挡条件下和光线暗淡条件下, 测试准确率提升非常明显. 由于灰度图质量比较低, 所含信息较少, 因此单独使用灰度图训练出的模型识别精度相对较低. 此实验结果可以证明多模态特征融合的有效性.
4 结论
二维人脸识别受光照、遮挡和姿态的影响较大,们的算法受光照和遮挡的影响非常小, 并且我们提出的损失函数在测试中较其他两种取得了最优的效果,识别准确率达到了96.37%. 但是本文提出的方法具有一定的局限性, cluster loss需要和Softmax loss联合使用, 超参数λ 的根据经验设置, 没有具体的公式来量化.我们仅考虑了闭集测试, 没有考虑开集测试. 在下一步的工作中, 我们会继续优化算法, 并且使用开集测试.而基于高质量三维扫描数据的人脸识别计算量大, 非常复杂. 针对这一系列问题, 本文基于RGB图像和深度图像, 提出了一种多模态融合的三维人脸识别算法.并且针对人脸数据类间相似性较大的问题, 基于巴氏距离的思想, 提出了一种新的损失函数cluster loss, 用来惩罚类特征中心的相似性, 使得不同类的特征中心尽可能地分离. 之后使用Softmax loss、Softmax loss+center loss、Softmax loss+cluster loss三种算法分别训练了模型进行比较, 用来验证我们提出的损失函数的优越性. 我们使用处理过的RGB图像(模拟真实情况下口罩和墨镜对人脸的遮挡和光线较暗的情景)对预训练的模型进行微调, 使得模型仅使用RGB图像作为输入即可, 并且不受光照和遮挡的影响. 测试表明, 我
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
奥秘(2021年5期)2021-06-15
文萃报·周五版(2021年17期)2021-05-31
中国计算机报(2020年13期)2020-04-26
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小雪花·初中高分作文(2017年9期)2018-05-21
通信产业报(2018年10期)2018-04-13
中国新通信(2017年9期)2017-05-27
米娜·女性大世界(2016年8期)2016-08-17
