
基于多源局部放电信号数据流聚类分离方法
2022-08-25 08:57:06陈昌川刘仁光冯晓棕覃延佳代少升张天骐
上海交通大学学报 2022年8期
—放电幅值
—一个集群中的样本数量
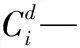
—区域密度值
—数据的属性数
核心半径的值根据集合中每个特征的标准差来计算,然后对其求平均.核心半径的计算式为
—纯度
—F-Measure的统计量
4.我产奶,我有犄角,但我不是奶牛。我是谁?(答案:a milk truck 奶车。horn 既有“犄角”的意思,又有“喇叭”的意思。)
—陡峭度
—微簇最小阈值
—不同宽度的高斯核线性组合成加权多宽度高斯核的个数
—微簇拥有数据量
—邻居的个数
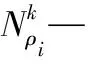
—数据集中的对象个数
—准确度
男人看似文质彬彬,喝茶的样子却正好于之相反,半杯茶要一饮而尽。女人拿一双好看的眼睛盯着他喝光杯里的茶,再捧起壶给他斟上,依旧是半杯,男人再一次端起杯子一饮而尽。然后拿手抹去额头上的汗珠,方朝女人笑一笑。
—精确率
—样本输入的速度
—放电量
—召回率
—微簇群的个数
—权重系数
—壳半径
—核心半径
对其每个数据点找到其-近邻、逆-近邻,以及每个数据点近邻的数量.
—常量因子
1)进一步优化和完善系统设计。根据系统试用发现的数据收集格式、数据兼容性等问题,联合系统研发公司一起制订优化方案。例如:对于原始数据库中的项目不能进行在线中期检查和结题申请的问题,将对数据进行处理,达到兼容的目标;对于数据采集中存在的非格式化数据,重新进行赋值定义,做好备注,引导项目申报者完成数据录入各项工作。
—第个相位的概率密度
—偏斜度
—处理时间
经略海洋、维护海权,建设海洋强国,是实现强国强军梦的必然要求。当前,我国与海域相邻国家间存在着许多权益争议,特别是美国打着海上自由航行的名义,不断挑战我守海卫疆的底线,使得海洋问题错综复杂,我维护海洋权益、护海守边的形势严峻多变,极有可能引发海上战事或军事冲突。海上民兵是我军海上作战时参战支前的重要力量,将围绕担负的海上游击作战、配合支援海上作战、组织海上“三战”等使命任务采取相应行动。
—加权多宽度高斯核函数
Optimization Research on Reverse Osmosis Treatment Technology for Flexible DC Valve Cooling Spay Water LU Xiang,XU Zhongya,WANG Jianwu,ZENG Qinghe(111)

—第个相位值
对生的眷恋是小说欢愉的地方,集中体现为对少女的崇拜。川端康成在这部作品中继承了以往的少女崇拜情结,在《自夸十讲》中曾经提过:“如果能够写一位永世不会泯灭的少女的话,那么我也不白活这一世。”在川端康成的作品中少女永远是最佳的女性形象,《睡美人》中作者就着重笔墨写了六位代表生命活力的少女。
Δ—相位的宽度
使微簇中的数据点之间距离的线性平移放大,在其特征区间内扩大样本的差异,可以更好实现对差别微弱的微簇之间进行聚类,从而微簇的半径和密度可通过NaN算法进行自适应变化.对微簇进行调整,该算法采用了一种简单的线性老化确定方法,从而缩短了微簇的寿命.该微簇作为未使用的微簇可看作完全消失,不仅可以替代老化的技术,而且还可以通过添加更多的数据点来将该微簇激活,从而更新微簇的图谱.当没有接收可用的数据时,微簇会逐渐消失.这种现象广泛存在时,微簇的寿命将逐渐达到0,从而被消除.
—自然特征值
—第个相位的均值

—方差
—工频相位
在人口稠密的城市中,对变电站的紧凑设计和小尺寸的要求,使得气体绝缘变电站(Gas Insulated Substation,GIS)的安装成为必要条件.由于紧凑设计、低维护要求及可靠的运行,近年来GIS在电力公用事业中得到了广泛的应用.像其他高压设备一样,在强电场的作用下,GIS设备绝缘体内部区域可能出现各种引起危害的潜伏性绝缘缺陷,产生不同类型局部放电(Partial Discharge, PD).不同类型PD反映的绝缘劣化机理不同,对GIS设备损害程度也不同.识别PD类型可以为变压器的诊断、检修提供依据,从而确保电力系统安全稳定地运行.
模式识别是气体绝缘变电站故障诊断的主要内容之一,用数学技术方法对有故障信息的数据进行自动处理和识别,提取有效的信息,从而对故障的数据点进行聚类和分离.通过PD信号监测系统采集到PD信号,通过模式识别方法对数据之中能反映气体绝缘变电站PD的特征信息进行辨识,从而可以判断PD的放电类型.如果气体绝缘变电站发生故障,产生了PD的现象,则可以对PD类型进行判断,为维修提供一定的技术指导.PD类型大概分为尖端放电、空穴放电、悬浮电极放电及自由金属颗粒放电.这些缺陷主要是由诸如断路器之类的运动部件的机械振动所产生.相位分辨局部放电(Phase Resolved Partial Discharge, PRPD)模式是PD测量分析中最常用的方法,本文采用的特征提取方法是统计特征法.利用特高频法对PD信号进行监测,对其放电特性进行分析.提取可以反映GIS设备缺陷的特征参数,这些特征参数包括偏斜度、陡峭度、上升时间、下降时间及脉冲宽度等.这些特征参数都应该具有很高的辨识度,将GIS的运行状态与各个特征参数相关联,来分析并以其结果预警GIS设备潜在故障,利用聚类分离算法将不用的特征参数的信号分离出来.针对不确定的数据流特征,Cao等提出DenStream聚类算法,该算法引入核心微簇来概括任意形状的簇,同时提出潜在的核心微簇和异常微簇结构来维护和区分潜在簇和异常值,扩展了传统基于密度的聚类算法,重点处理任意形状的数据流聚类问题.DenStream算法存在不足,没有限制核心微簇的数量,同时也没有删减或减少核心微簇的方法,会导致大量的内存开销.Chairukwattana 等提出SE-Stream聚类算法,通过减少执行时间和提高微簇的质量来提高算法的性能,确定每个活动微簇的适当维度子集来表达数据流中的微簇的特定特征,支持微簇结构随时间的变化,包括微簇的出现、消失、自我进化、合并及分裂.SE-Stream算法存在着缺陷,需要初始化定义较多的参数,后期的聚类效果受初始化参数的影响.该算法目的是为了在每个微簇中提取最佳的选定维度集,不能保证这些维度是否冗余.
任务实施是学生或小组按照计划逐步完成任务的环节。在这个环节中引入MOOC的知识点讲解,将学生任务中需要掌握的知识点,以线上MOOC的资源方式引导学生自主完成学习。再充分应用自己已经掌握的知识,并就解决问题、完成任务的实施步骤形成详细的计划。学生在这个环节要完成的工作主要是进一步收集信息,完成任务或解决问题,汇报PPT、图纸或其他形式的学习成果。
第三,就历史与现实的关系而论,文化多元性下的共识性对话不仅是与世界相关联的中国问题,而且是与历史相关联、与传统相关联的现代问题。从本质上来看,它理应是历史的对话,其开展的必要条件是以中西马各自的哲学史作为根基,以充分调动三种历史资源为前提,以“向上的兼容性”去总结成就、发现困难、揭露矛盾,在继承传统的基础上将古今中外的智慧结合实践经验进行融会、贯通甚至超越,以积极寻求不同理论、不同思想之间的对话,为构建具有中国特色的当代中国形而上学提供新的思维方式和理论格局。
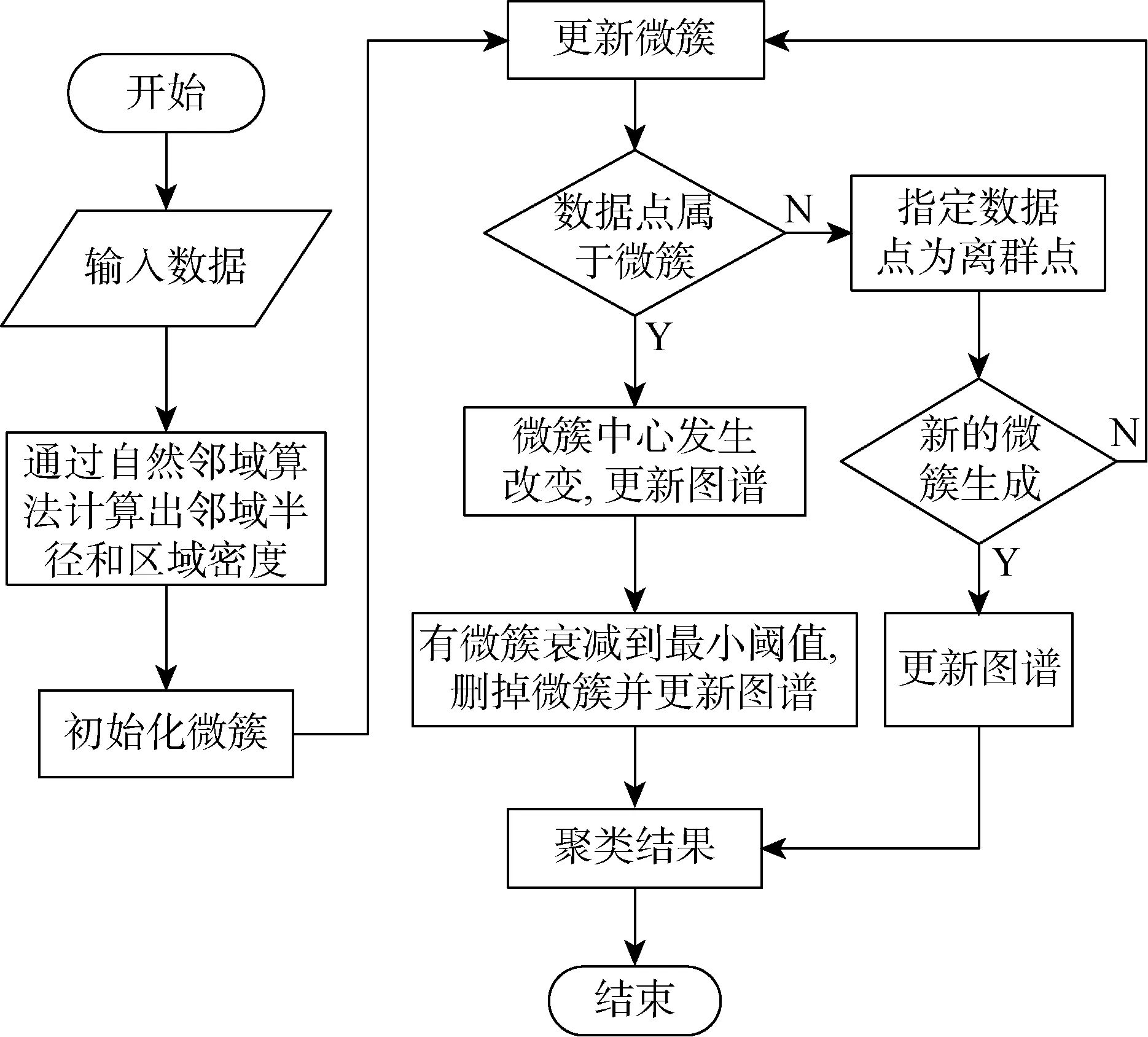
针对多种实时PD信号数据且不断变化的问题,系统需要能够实时对多种PD信号进行分离,本文提出了一种高效自适应在线数据流(Efficient Adaptive Online Data Stream Clustering Algorithm, EAOStream)聚类算法,该算法在传统数据流聚类算法上,利用自然邻域(Natural Neighbor,NaN)的方法,创建KD树(-dimension Tree)来提高查询近邻的效率,该方法通过流数据的特征值计算出适应的邻域半径和区域密度进行局部搜索,从而来支持最佳的聚类效果.在形成团簇后,半径可以跟着时间增加或减小,根据数据流结构动态变化,一些微簇会随着时间拆分或合并.实验测试效果表明,该算法为任意形状微簇聚类提供了一种有效的解决方案并具有更高的分类精度.
1 多源PD信号数据流聚类分离
为了测试多源PD信号数据流聚类算法的性能,本文在实验室设计4种典型的变压器PD缺陷模型.使用广州友智电气技术有限公司的PD监测设备对每种类型缺陷进行在线检测取样,设计特高频缺陷PD监测系统对PD信号的数据进行概率分析,使信号特征和聚类分离更加稳定.
黄厚江的“本色语文”教学理念认为其基本内涵为三点:一是“语文本原”,就是必须立足于语文教育的基本任务;二是“语文本真”,就是探索语文教学基本规律,在语文教学中体现语文的特点;三是“语文本位”,语文课要体现语文学科基本特点,实现语文课程基本价值。本文主要是在黄厚江老师《背影》课堂实录的基础上结合“本色语文”教学理念对黄厚江的教学语言风格——以小见大做一个解析。
1.1 PD信号特征提取
实现不同PD故障信号的分离,首先必须提取的特征量能够反映PD信号的时域特征.从而通过特高频提取到的特征值来表示PD信号.由于放电机理、放电缺陷位置、放电信号传播路径的不同,所以多种PD信号会在特征值中表现不同的差异,根据不同PD信号时域分布特征的不同,就可以将多种PD进行分离.用于类型识别的 PD 特征量选择方法主要集中在PD相位分析模式,统计特征参数用PRPD的特征描述.本文提取了信号特征中的、、和等特征量.
(1) 偏斜度用来描述PRPD图谱的差异,反映了图谱形状相对于正态分布的左右偏斜情况.具体计算公式为
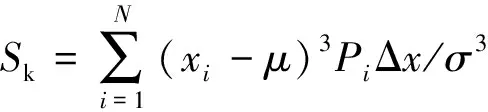
(1)
(2) 陡峭度用来描述PRPD图谱形状分布的突起程度,表示概率密度分布曲线在平均值处峰值高低的特征数.具体计算公式为

(2)
1.2 PD信号分离方法
根据PRPD图谱中统计参数中的、、和组成一系列二维或三维图谱及其统计特征来实现对多种PD信号的分类.传统的聚类分离算法存在一定的问题:通过特高频传感器接收不断变化的实时PD信号,需要保证完整的工频周期.而离线的聚类算法(例如DBSCAN)不能满足要求,从而提出了一种高效EAOStream聚类算法.
..基本概念
(1) 微簇形成:在一定半径的范围内,当数据点与其他的簇足够远的时候,那么这些点会组成一个新簇.
本研究通过谱效关系分析证实,紫荆叶提取物质量浓度为100 mg/mL(以生药计)时,P5、P8、P10、P12、P15、P16号共有峰与其对酪氨酸酶活性的抑制作用呈正相关,P2、P4号共有峰与其对酪氨酸酶活性的抑制作用呈负相关。但上述共有峰面积(代表化合物的含量)与酪氨酸酶活性抑制作用的正/负相关性只能表示其作用趋势,并不表示这些化合物直接对酪氨酸酶活性起抑制或激活作用;且谱效关系分析是以各个峰作为独立样本为假设前提,而忽略了不同化合物之间的相互作用。因此,这些特征色谱峰所代表的化合物的结构仍需进一步鉴定,化合物之间的相互作用仍需进一步深入探索。
(2) 微簇合并:如果一个微簇的外壳半径与另一个微簇的核心半径之和大于其中心距离,这两个微簇进行合并.
(3) 微簇分裂:如果微簇由一定数量的数据形成的候选微簇不与其他微簇的壳半径相交,则将这两个微簇分开.
(4) 壳半径:确定了微簇的边界,用于微簇的合并和分割的操作.离聚类中心最远的数据距离指定为聚类的壳半径.
(5) 核心半径:作为微簇集中区域,用于判断两个微簇是否能够合并为一个微簇.
()—数据点的近邻距离

(3)
微簇的中心有关的重心计算式为
在传统高中语文作文教学中,教师作为教学主体,学生只能被动接受。学生写好作文后,由教师一一审阅,教师虽是教学的引导者,但是教师作为一个个体,思想也有局限性,因此站在教师的角度和立场去评判所有学生的作文,未免太过片面,而不同的学生有不同的思想,不同思想的碰撞,会发出耀眼的光芒,所以应该开展学生之间的互相评审和自评,让学生在自评和互评的过程中认识自己的不足。通过学生的探讨,学习别人的长处,认识自己的短处,做到优势互补,共同进步。最后,教师和学生进行共同总结,为了以后更好地写作。

(4)
数据点到来的时候,确定该数据最近的微簇,如果数据点到聚类中心的距离小于聚类的,则将数据分配给相关微簇,并更新聚类重心.如果数据到聚类中心的距离大于聚类的,小于最大半径,并且小于聚类的和半径增量阈值之和,则将此数据分配到该聚类.微簇的可以增加到最大半径,但这个增加的过程是逐步实现的,该增加量可到一个阈值,超过一定阈值,数据将不会增加到该集合中,这样结构能够保证微簇更加稳定,增加微簇抗干扰能力.
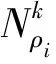
(∀)(∃)(∈)∧(≠)→

(5)
如果数据对象分布是规则的或数据集的大小很小,则的值很小.如果数据对象分布不规则或数据集的大小很大,则的值很大.但是,无论的值有多大,它仍然远远小于数据集大小的值.为了找到每个数据点的NaN,需要不断扩大邻域的搜索范围,当达到自然稳定状态,NaN搜索算法就停止.最大的邻域就是数据.NaN算法如算法1所示.

NaN算法
输入:数据集
输出:,NaN,NaN数据
初始化NaN.
将数据放入到KD树上进行最邻近搜索.
-—个不同宽度高斯核上的权重系数
判断是否达到稳定终止平衡条件.

该算法无需任何参数即可自动完成NaN的整个过程,如果将最近邻居的形成视为主动邻居搜索的过程,则NaN的形成是不可行的,数据中的每个对象的最邻近(-Nearest Neighbor, KNN)和逆最邻近(Reverse Natural Neighbor, RNN)的搜索成本非常高.因此将KD树引入到NaN搜索算法中.因为将KD树引入到NaN的搜索中,所以NaN搜索的算法时间复杂度为(log).
这幅肖像生长在现实的原野里,通灵通透,与城市现代人的画像差异迥然、对照鲜明,其中折射出的文化意味自不待言。《苏北女人》充满艰辛而又富有自然诗意的田园,既是作为被现代伤害的一面被仿写,又作为现代的“根”和“自己的开端”被想象,并被赋予拯救的力量。
..EAOStream介绍 EAOStream包括两个阶段.第一阶段中,引入NaN算法,EAOStream通过NaN算法对前个数据点组成的数据集进行处理得到值和微簇最小阈值,然后计算每个数据点与的距离之后,求其平均值设算法邻域半径为,通过引入NaN算法,得到EAOStream所需要的和,从而无需初始化参数值,通过数据点不断进入,自适应更新和
EAOStream框架如图1所示,的计算式为
其次,由于我国产业结构中高碳产业占据了很大的比例,为有效应对碳关税,应加快产业结构优化升级的进程,实现国家产业整体向两低两高(低能耗、低排放、高附加值、高技术含量)的方向转化,大力促进新兴产业的发展,例如太阳能产业、生物产业、风能等。因此,我国既要全面配合产业政策调整,又要同经济增长方式转变相一致,实现贸易与资源环境的协调发展,推动贸易政策优先向竞争力导向转变,提高出口产品的低碳竞争力。
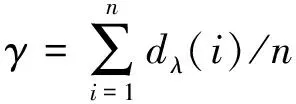
(6)
为了针对数据集分布的自然规律,对数据点分布稀少或分布密集的区域,搜索的半径可以采用加权多宽度高斯核函数 (Weighted Gaussian Kernel with Multiple Widths, WGKMW) 进行加权,动态设置微簇的邻域半径.区域密度值越大时,邻域半径越大,反之则邻域半径越小.加权公式为

(7)
—邻域半径
第二阶段是相交的微簇,将微簇分为壳区域和核心区域,通过考虑与微簇外壳相交的核心区域来对微簇进行分组,可以自动确定边缘的微簇群.不具有最小阈值的微簇会存在异常值,每个微簇都含有一个图形,图2演示了微簇的相交.通过应用图结构能够最大程度减少微簇的破裂或最终死亡时分离微簇所需要的计算.EAOStream采用实时更新图结构的方式得到聚类结果,当数据点到来后,计算修改后的微簇周围的几个相连的微簇的可达性,其余的点不需要修改,能够确保微簇划分的有效性.聚类形成过程和结果如图2所示,数据和数据分别为数据集中数据点的横坐标及纵坐标,不同颜色的微簇代表不同的类别.

算法处理流程总结如下.
参数选择.对前个数据,利用NaN算法得到,计算每个数据点近邻距离的和,并求平均值,所得到的值设为算法的邻域半径,从而能够自适应得到邻域半径和区域密度.
初始化微簇.初始化参数主要是邻域半径、区域密度和衰减值,算法将第一个数据点用来初始化微簇,并将微簇的属性设定初始值.
分配核心微簇.在到达新数据点时,判断数据样本是否属于当前任何微簇.如果不是,则创建一个新的微簇.如果数据在当前微簇中,进一步检查数据在微簇团的核心半径或壳半径内.如果判断数据点落在壳半径区域内,则更新微簇的中心位置.
删除衰减到最小阈值的微簇.所有的微簇寿命减少到衰减量时,将微簇移除,并删除与它相连的边.
更新集群.存在3种情况会使聚类图进行更新:在已存在的微簇中心点位置已发生改变;微簇发生移动或产生新的微簇;微簇的寿命衰减到设定的阈值.
在上述情况下可以更改算法的边缘列表,需要更新微簇群的数量,首先可通过NaN算法计算出合适的邻域半径和区域密度.当微簇达到阈值或微簇中心位置发生移动时,微簇的图形边缘将发生修改,则产生的微簇的个数也发生改变.
..EAOStream复杂度分析 EAOStream采用了NaN算法初始化参数,时间的复杂度是(log);新进入后的算法仅和存在的有限个微簇中心的距离进行比较,时间的复杂度为();检查是否有新的微簇生成、衰老到指定阈值、更新图谱结构时间复杂度为().
依据保存的微簇个数对数据流聚类算法的空间复杂度进行衡量.EAOStream仅保存当前微簇,以前的微簇不会保留,可以大量减少内存消耗.
2 实验与结果分析
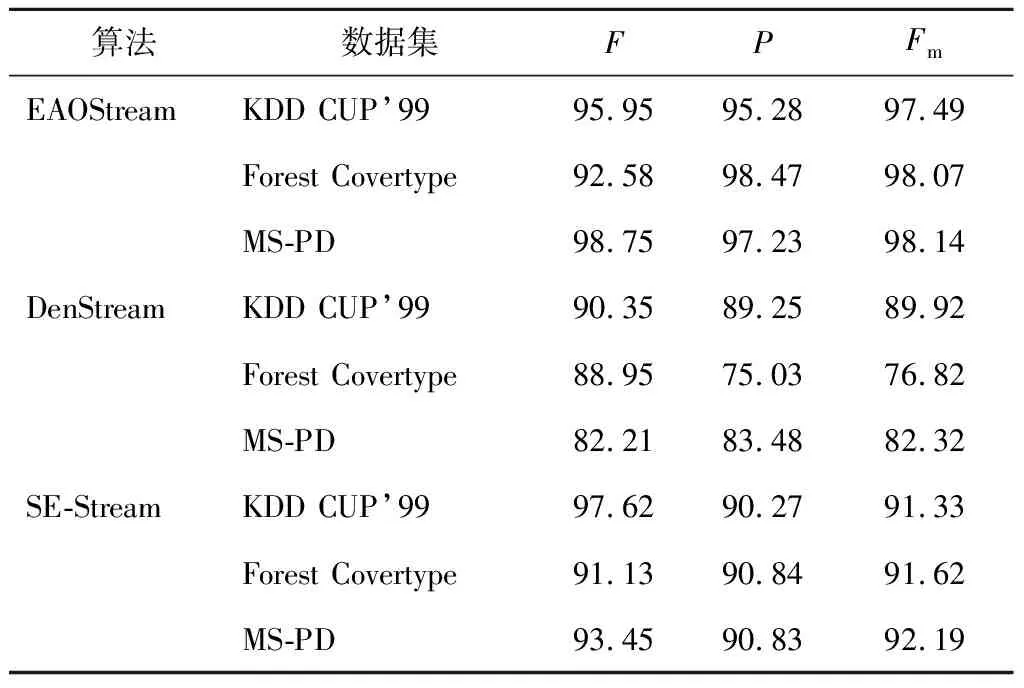
为了在不同的环境中测试EAOStream的性能,采用了数据挖掘与知识发现网络入侵检测数据集(Data Mining and Knowledge Discovery Network Intrusion Detection Data Set,KDD CUP’99)、森林覆盖类型Forest Covertype及多源局部放电信号(Multi-source Partial Discharge Signal,MS-PD)数据集进行验证.本文算法在软件仿真实现后移植到硬件中,实验的硬件环境为:Intel i7-8750 CPU,16 GB的内存,Windows 10操作系统,核心板为MZ7X 7035.KDD CUP’99数据集作为数据流输入到算法中,多源PD信号数据集来自于校企合作项目,现场通过PD监测系统对多种PD源放电信号进行采集得到数据集,并同时将聚类效果与DenStream和SE-Stream算法进行对比分析.为了评估聚类效果,通常采用的评估指标包括纯度、准确度及F-Measure.
(1) 纯度是一种对聚类效果的测量方法,代表着簇本身的纯度,其定义为
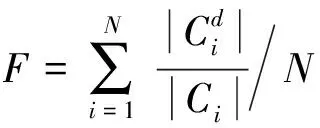
(8)
(2) 准确度通过将模型产生的聚类效果与真实聚类进行比较,来衡量模型是否成功,其定义为

(9)
(3) F-Measure的统计量为精确率和召回率的加权调和平均,主要用于评价分类模型的性能,其定义为
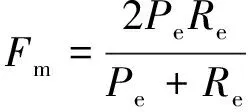
(10)
2.1 聚类实验结果分析
为了验证EAOStream的性能,通过性能指标纯度、准确度及来衡量聚类的质量,同时将DenStream、SE-Stream与EAOStream进行比较.在实验室中,采用3种真实的数据集,第1个数据集是KDD CUP’99,使用其中数据集中的子集,包含 494 020 条记录,每条记录对应一个正常的连接或4种类型的网络攻击之一,具有34个属性和22个类.第2个数据集是Forest Covertype,来自于加州大学欧文分校(University of CaliforniaIrvine,UCI)机器学习植被型数据集,其中包含 581 012 条记录,具有10个属性和7个类.第3个数据集是MS-PD数据集.与校企合作项目中的PD监测系统,在实地高压场景下模拟MS-PD信号,通过特高频传感器采集产生的多种混合的PD信号进行实验,采集到真实的MS-PD信号数据集.其中数据集包含 548 573 条记录,具有2个属性和5个类.在这3种数据集中创建500个间隔为 1 000 个样本的时间间隔并将它们分成25组,在这25组中求取平均的纯度、准确度及.KDD CUP’99数据集是流行的数据集,用来测试不断变化的聚类算法,将EAOStream、DenStream及SE-Stream进行比较.为了使聚类效果更好,将数据归一化到相对于区域半径合适的范围.通过取性能指标的平均值来进一步降低该度量的相关性,性能指标分析结果如图3所示,EAOStream平均纯度为97%,超过SE-Stream和DenStream,平均纯度最快达到100%.可以看出,EAOStream能够快速适应这种变化.在考虑准确度和时,注意到EAOStream平均准确度和保持接近95%以上,其余两者算法平均准确度都有降低到80%以下.EAOStream比其他两种算法聚类精度更稳定,在不断时间积累下,精度会逐步提高.这是因为其采用的NaN算法具有不断从自适应邻域半径和区域密度进入数据点的特征,从而达到更好的聚类效果.图4所示为MS-PD数据集3种聚类算法性能对比, 图中为样本输入的速度,设置数据流到达的速率单位为pt/s,pt为像素单位,每隔25 s显示一次聚类结果.采用了MS-PD数据集,研究其平均纯度和准确度.EAOStream针对多个样本速度和时间段来测量MS-PD数据集的平均纯度和准确度,验证EAOStream基于不同样本速度自适应参数的能力,算法的平均纯度和准确度在所有采样速度下都维持在85%以上,比其他两者聚类算法更好.


表1所示为不同算法在真实数据集的性能对比.可见,在MS-PD数据集中,EAOStream纯度为98.75%,准确度为97.23%,为98.14%,这表明EAOStream能够快速适应变化,因MS-PD数据集中PD信号存在从一种到多种PD渐变的过程,所以EAOStream可以克服人为主观选择参数的问题,通过NaN算法自适应邻域半径,创建KD树来提高查询近邻的效率,根据气体绝缘变电站PD信号产生的特性,从一种PD源到多种PD源渐变,其中包括干扰脉冲的存在.EAOStream是一种支持进化变化的算法,可以成功实现微簇群结构随时间的变化,这可以提高聚类的成功率.在大多数测试数据集中,EAOStream都优于其他的算法.EAOStream在KDD CUP’99数据集上,评价指标平均纯度比SE-Stream稍差,EAOStream在高维的数据集聚类效果不是特别稳定,而SE-Stream专为高维数据流设计.EAOStream设计对任意形状的微簇结构图都有很好的分类效果且能够自适应半径特征,当数据特征发生很大变化时也能够达到好的聚类效果.
2.2 多种PD源信号聚类分离现场实测
为了验证EAOStream在PD信号时域特征聚类分离的可行性和有效性,与校企合作项目建立PD监测系统,在实验室中对多种不同类型混合的PD类型进行系统测试,特高频缺陷PD模拟信号发生器实物如图5所示,将采集的信号输入到硬件系统板中,如图6所示,其中包括信号采集单元和信号处理单元,将EAOStream聚类算法移植硬件系统板中,实时在线处理完后的数据上传到上位机显示.本文选取PRPD图谱中统计参数中的和组成的二维图谱来实现对多种PD信号的分离.在实验室采集多种PD信号形成数据集,在3种聚类算法的效果对比图7所示,通过颜色来判断类别,相同颜色的团簇代表一类.由图7可知,有5类信号,Denstream和SE-Stream对图中第1类和第2类的分离的效果无影响,第1类信号和第2类信号微簇之间较近,容易将其判断为一类信号;图7(b)、7(c)所示第1类信号和第2类信号颜色被算法判断成一种颜色,EAOStream能够准确将两种信号分离出来.



在实际测试中,通过特高频传感器将多源PD信号输入到采集单元中,然后进入到处理单元提取脉冲的特征值,通过EAOStream将不同特征值的多源PD信号实时分离,将数据上传到上位机中,数据包括相位、放电幅度及标记3个参数.在整个过程中各个单元同步进行,数据源源不断进入到处理单元中.
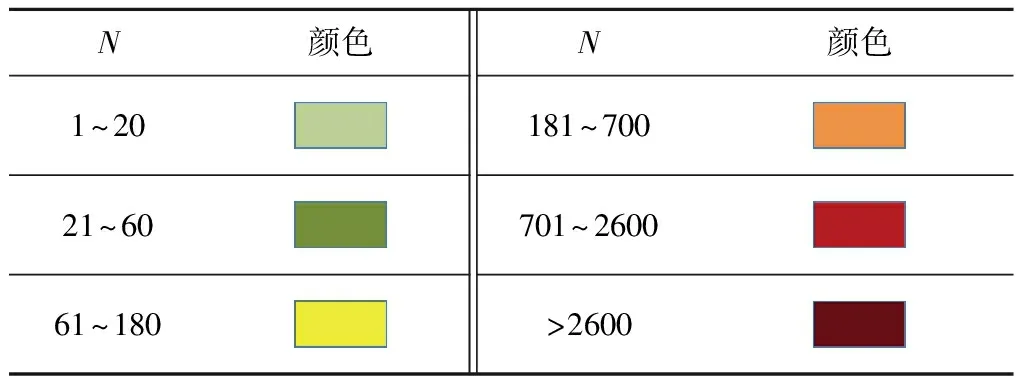
在实际项目中,将算法固化到硬件系统,很难通过人工在现场调试参数,需要算法本身根据流数据特征来自适应修改邻域半径和区域密度,从而达到最佳的聚类分离效果.在PRPD图谱显示结果如图8所示,放电次数映射到颜色空间上,每个分布位置可以叠加,从而可以做到颜色标识,根据累积的次数分为6个颜色级别,对应规则如表2所示.实验中采用两种信号混合输入,分别是悬浮电极放电信号和尖端放电信号.由于实验室悬浮电极放电信号的产生没有固定相位,所以随着时间的推移,相位会发生偏移,最后形成一条绿色的线条.尖端放电信号由实验室中高压试验变压器和特高频缺陷PD模拟信号发生器产生,因相位固定,随着时间累计,中间部分颜色会一直变深,最后趋于稳定.实验证明,EAOStream对多种混合PD信号分离效果不错.

3 结语
本文分析了当前气体绝缘变电站故障诊断的现状,针对传统的DBSCAN聚类算法不能处理实时且不断变化的多种PD信号特征,提出了聚类算法EAOStream,该算法可以完全在线处理数据,具有自适应半径的特征,对任意形状的簇的分类都有一定的效果.提出的算法中使用了NaN算法,主要用于自适应邻域半径和区域密度.基于使用纯度、准确度及的质量指标对真实数据集进行了广泛评估.与其他算法相比,实验研究表明该算法在合理的时间内具有较高聚类成功率.在未来的工作中,将着重于提高算法的稳健性,扩展处理高维数据流,集中处理在高维数据集情况下降低算法的计算复杂性以及消除复杂数据流中噪声对聚类的负面影响,从而进一步提高该算法的性能.
猜你喜欢
汽车维修与保养(2020年11期)2020-06-09 05:42:22
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
制造技术与机床(2019年6期)2019-06-25 10:17:18
自动化学报(2018年7期)2018-08-20 02:59:04
电脑与电信(2018年12期)2018-03-23 02:37:36
华东师范大学学报(自然科学版)(2017年1期)2017-02-27 13:41:05
周口师范学院学报(2016年5期)2016-10-17 06:36:47
西北工业大学学报(2015年3期)2015-12-14 13:08:48
中国海上油气(2015年3期)2015-07-01 16:32:08
中国卫生(2014年7期)2014-11-10 02:32:54
