
基于ALBERT的网络文物信息资源实体关系抽取方法研究
2022-08-23 08:40彭博
情报杂志 2022年8期
彭 博
(1.华中科技大学建筑与城市规划学院 武汉 4300742.华中师范大学信息管理学院 武汉 430079)
中国文物作为中华历史文化传承中的精华,记录着华夏文明上下五千年的历史变迁进程。随着数据爆炸式增长时代的来临,以往将结构化数据视为文物信息资源的观点已无法适应大数据环境下信息资源的定义,应该将广义的信息资源概念应用于文物信息资源中,数量庞大、形式多样的与文物有关的信息都可以被视为文物信息资源。因此,如何从非结构化数据组成的信息资源中抽取实体关系三元组并进行知识发现,成为了大数据时代文物信息资源利用与推广中需要解决的重要问题。
1 相关研究
1.1 信息资源实体关系抽取的有关研究
信息资源中实体关系抽取的普遍做法是在输入的文本数据中以句为单位识别出其中包含的实体及实体间的关系[1]。现有实体关系抽取研究分别围绕无监督的学习方法、半监督的学习方法、全监督的学习方法以及远程监督的方式进行。
无监督的学习方法利用实体关系对在句中的固定特征进行聚类,通过聚类后的结果进行实体关系抽取。早期开始于使用人工标注的特定领域语料与增强型的句法解析对待抽取文本按一定规则进行挖掘,如Miller等[2]通过统计方法设计匹配规则,经过词性识别、实体识别、句法分析、语义解析四步骤进行实体关系抽取。Kambhatla[3]采用最大熵模型整合文本中的词、句的语义特征,使用逻辑回归的方法进行实体关系的分类。Zhao等[4]使用核函数模型,将分词、句子解析、深度依存分析分别进行核函数表示,综合三种维度进行预定义关系下的实体关系抽取。Culotta等[5]使用随机条件场对文本中存在的类似关系进行抽取,提高了基于规则实体关系抽取的效率。Banko等[6]在预定义词汇-句法模式后通过随机条件场进行实体关系抽取,在特定领域的关系抽取中取得了更高的精度。
半监督学习通过多次重复抽样建立小样本进行实体关系标注,得到标注结果后再进行样本的实体关系抽取。Chen等[7]结合图模型与标签传播算法,对关系标签形成的图模型节点和边的权重加入提取条件,在少量关系标签可用的情况下实现了实体关系的抽取。Riedel等[8]提出使用矩阵分解模型来学习实体序列标注和关系的潜在特征向量,能够对结构化和非结构化的实体关联关系进行推理,实现开放领域的实体关系抽取。
全监督的学习方法是在已标注数据上训练模型,对数据集中的实体关系进行抽取,全监督的学习方法有基于规则、基于特征和基于核函数等。随着深度学习的出现,摆脱了传统机器学习算法需要进行特征设计的缺点,可以自动提取实体关系的特征。Socher等[9]使用Word2Vec与递归神经网络进行实体关系抽取,首先学习节点在句子中的向量表示,随后通过递归神经网络得到句子的向量表示进行关系分类,开创了深度学习在实体关系抽取中的应用。Zeng等[10]利用卷积神经网络提取词汇和句子级特征,将这两个级别的特征联结起来形成特征向量,随后将特征输入到softmax分类器中,从而预测两个标记实体之间的关系进行实体关系抽取。Nguyen等[11]使用多个尺度的窗口过滤预训练的词向量,得到了一种基于卷积神经网络的泛化实体关系提取方法。由于卷积神经网络会由于输入句子长度增加而导致精度下降,Xu等[12]提出使用长短时记忆网络(LSTM)进行关系抽取,在句子级别的实体关系抽取中找到两个实体在依存树中的最短路径可以去除无关信息。
远程监督有关方法诞生于外部知识库的出现与发展,其核心思想来源于一个基本假设:如果两个实体在知识库中存在关联,那么其在句子级别语料中出现则表明该句描述的是这种实体关系,在这个假设下可以利用知识库自动标记语料。Mintz等[13]使用Freebase知识库提取实体间关联关系,根据假设策略生成训练样本,设计特征训练关系分类器进行实体关系抽取。Yao等[14]对Freebase知识库进行远程监督关系抽取的方法进行了改进,使用Gibbs采样进行线性时间联合推理,通过多个文档确定实体间最可能存在的关联关系,提升远程监督关系抽取的准确率。Hoffmann等[15]为了减少远程监督噪音影响,使用多实例学习思想结合句子与文档特征进行重叠关系的抽取。
在实体关系抽取的有关研究中,高质量的实体关系标注数据是进行关系抽取的前提。由于文物信息资源具有认知性与历史性特征[16],知识属性是唯一的和排他的,已知的文物知识考证明确,准确性高,这为通过外部知识库对文物信息资源中的实体关系进行标注提供了高质量的数据基础。因此,通过远程监督与有监督学习融合的方法进行文物信息资源实体关系抽取相较于其他领域具有得天独厚的优势。
1.2 文物信息资源的有关研究
当前国内外有关文物信息资源的研究主要集中在结构化数据开发与数据间语义关系的利用两方面。
第一类研究结合文物特征进行数据标准的构建,在数据层面进行文物信息资源的开发和利用。如结合资源情境进行文物图像的标注,将文物元数据标准应用于图像等非结构化文物信息资源中[17]。艾雪松等[18]在文物信息资源与有关文物元数据标准的基础上,构建了面向博物馆领域的文物信息资源元数据模型。刘美杏等[19]依据不可移动文物的特征属性,制定了相应的文物元数据标准以进行后续研究。夏翠娟等[20]对可移动文物的有关特征制定了数据标准,意图从文物属性特征、时空变化特征、管理传承特征等方面进行知识发现。
第二类研究从文物信息资源的语义特征入手,使用关联数据、知识图谱等方法进行文物信息资源的开发与利用。如Hyvönen等[21]通过关联数据组织和整合文化遗产有关信息资源并使用语义网进行发布。DeBoer等[22]分析了关联数据在文物信息资源组织中的优势,提出了文物信息资源关联数据的资源采集、存储、加工与发布流程。曾子明等[23]围绕文化遗产多媒体资源、视觉资源中的潜在语义关系进行研究,提出了一系列语义关联方法。Cimmino等[24]研究了文物信息资源中的知识组织与知识图谱的构建与应用,探讨了数字人文背景下文物知识的深层次利用。
综合来看,文物信息资源数据层面的研究成果十分丰富,但使用自然语言描述的文物信息资源却不被重视。在实际应用中,受众面对的都是通过文本形式对文物进行描述的信息资源,如何利用丰富的结构化数据研究成果帮助受众解析有关信息资源,成为推广和传播文物知识的关键。
2 融合知识图谱与深度学习的文物实体关系抽取框架
进行文物实体关系抽取需要解决三个方面的问题:一是如何获得实体间关联关系,文物实体关系具有唯一性和即时性特征,唯一性指文物知识是经过科学考证的结果,不存在不确定的关系,即时性指随着文物研究中新考证的出现,实体关系存在更新的可能,这就要求文物实体关系的获取需要同时具有标准性和可操作性,以便确保数据准确与即时更新。二是实体关系的精简与统一,实体间关系多种多样,描述关系时的用词不尽相同,同时关系种类的增加也会导致后续关系抽取算法复杂度提高,因此文物实体间关系需要依照特定的数据标准进行归纳与合并。三是关系抽取模型的选取,由于文物描述规范化的特点,文物知识在自然语言中的出现顺序与排列方式具有统一特征,提取有关字、词在文本中的特征能够有效提高实体关系抽取效率。针对以上三方面问题,文章提出从文物实体关系获取、标记、抽取三方面构建融合知识图谱与深度学习的文物实体关系抽取框架,如图1所示。

图1 文物实体关系抽取框架
2.1 文物实体关系的获取
文物实体关系抽取的首要问题是关系的获取,外部知识库的出现成为实体名称及实体关系的重要数据来源[25]。以研究对象实体为检索入口,通过对与其有关联关系的实体进行检索,得到实体关系后再进行多次检索,最终得到与文物实体有关的关系集合(S,P,O)三元组[26]作为进行实体关系标记的数据来源。
2.2 文物实体关系的标记
在得到多个外部知识库检索的三元组集合后,使用数据清洗、去重等手段通过图模型将三元组中的实体及属性映射为节点和边,其映射过程可以表示为(S,P,O)→Gi=(Vn,Em)其中V={S}∪{O}、E={(S→O)},边E的标签表示为P,构建针对研究对象的文物知识图谱。
构建的知识图谱存在多种实体关系,需要对相似实体关系进行归类与合并,参考元数据标准以及标准间的相互映射作为实体关系归并的依据[27]。如都柏林核心(DC)[28]、艺术品描述类目(CDWA)[29]、地名本体(GeoNames)[30]元数据标准等,经过归并后的实体关系可以在有限的标记资源中为类似关系获得更多标记样本。文章依据远程监督方法假设句中存在两个字或词与知识图谱中的实体名称一致,则使用知识图谱节点名称(V1,V2)进行实体名称标注,实体关系标注为E1-2;若句中存在两个以上字、词与知识图谱中的实体名称一致时,则依次选取在知识图谱中节点距离为1的节点的名称进行标注,标注为(V1,V2)、…、(Vn,Vm),实体关系对应标注为E1-2、…、En-m。实体关系为“别名”、“字”、“号”等表示两节点指代同一实体时,则将这些实体间距离视为0,进行不同名称下同一指代实体的关系标注。
2.3 文物实体关系的抽取
实体关系抽取是分类问题的一种,以实体出现的句子为特征提取对象,根据特征对实体关系进行分类,进行关系抽取需要经过文本特征向量化和使用神经网络提取序列数据中的特征两个步骤。文本向量化的方法有Word2Vec[31]、以及预训练模型BERT[32]、Xlnet[33]、ALBERT[34]等,它们都是通过在一定维度内对文本中的字、词进行映射,利用向量间的距离进行文本语义的挖掘。如GOOGLE开发的预训练模型BERT,利用Transformer Encoder与Self-attention机制描述上下文的语义特征,加入Next Sentence Prediction与Masked-LM进行联合训练,从而能够获取句子级别的语义特征。随后推出的ALBERT模型对BERT模型通过一次尺度变换降低了参数量,参数量从V×H降低到了V×E+E×H,其中E代表词向量维度,H代表隐藏层维度,V代表词库。同时通过共享Transformer Encoder中的所有参数,进一步降低了模型的参数量,相较于其他预训练语言模型,ALBERT更小的参数量能够快速的提取小样本信息资源中的字符特征。
由于实体关系抽取需要处理前、后实体间存在的关联关系,也就是前后序列数据间的特征提取,循环神经网络(RNN)可以对同一神经网络多次赋值,每个神经网络模块会把消息传递给下一个,处理序列数据有着较高的效率[35]。其解决长距离依赖问题的长短时记忆神经网络模型(LSTM)[36]既能处理序列数据,又能应对循环神经网络中序列过长引发的梯度消失问题。LSTM每个隐藏层中包含了遗忘门、输入门及输出门。文章加入正向和反向两个神经网络,输入经过两个方向相反的LSTM,而输出则由双向门控循环单元(BiLSTM)进行文本深层次特征的提取。为了减小文物信息资源输入序列过长对神经网络模型学习效果的影响,文章加入注意力机制(ATT)择性地筛选特征。最终构建的实体关系抽取框架如图2所示,共分为五层,分别是输入层、用于文本特征提取的预训练模型ALBERT层、进行深度学习的双向LSTM层和注意力层,以及输出层。
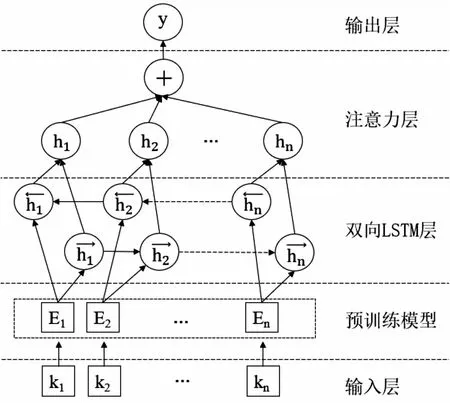
图2 基于深度学习的文物信息资源实体关系抽取框架
3 《清明上河图》文物信息资源实体关系抽取实验
为了验证文章方法在文物信息资源实体关系抽取中的效果,以中国十大传世名画之一的北宋风俗画《清明上河图》信息资源为例进行实证研究。
3.1 数据采集与预处理
数据来源以《清明上河图》为主题在百度百科、维基百科、搜狗百科中查询词条以及在线知识社区“知乎”检索“清明上河图”话题有关内容和中国知网中选择“CSSCI来源”的近三年期刊共100篇文本为研究对象。
在文物实体关系的获取方面,文章在Wikidata知识库中以“清明上河图”(编号:Q714802)进行检索,围绕结果进行了3次再检索,共得到RDF三元组380对。随后,在中文知识库CN-DBpedia中以“Named-Entity Disambiguation:清明上河图(北宋张择端风俗画)”同样检索得到RDF三元组108对,经去重得到401个节点、409条边的“清明上河图”知识图谱,结果如图3所示。

图3 《清明上河图》文物知识图谱
3.2 文物信息资源实体关系标记
由于没有统一标准,互联网中不同知识库中存储的实体关联关系名称不尽相同,信息资源实体关系的标注需要依照一定的标准对关系描述进行归类与合并,否则会由于名称问题造成实体关系出现歧义。同时依据已有的标准对实体关系进行归并能够减少实体关系标注的复杂度,在样本有限的情况下最大限度整合资源,提高实体关系标注的效率。
文章选择都柏林核心元素集(DC)[37]中的15个核心元素作为实体关系对齐的参考标准。都柏林核心元素集是由联机计算机图书馆中心(OCLC)和美国国家超级计算应用中心(NCSA)与众多专家联合研讨制定的一套专门用于描述网络信息资源的元素集。其承载的描述性数据信息在实现通用性特征的同时还能包含关系的详细描述信息,是网络资源与实体资源数据描述的纲领性标准。根据知识库实体关系的具体内容,文章共选择6个核心元素进行实体关系对齐,对知识图谱中的19种关系进行了归并,具体情况如表1所示。

表1 实体关系对齐表
在实体关系对齐实践中,文章将知识库中实体关系对齐为表1中的6个核心元素,如WikiData与CN-DBpedia知识库中北宋皇帝“宋徽宗”与“宣和”之间的关系既有“时间”又有“年号”,由于“年号”是中国封建王朝用来纪年的一种名号,代表的是一个时间段与实体关系中的“时间”意义相同,故在关系的对齐中将两种关系映射为核心名称中的“日期”,使用dc:data作为统一描述以减少相似关系在后续关系抽取中带来冗余,减少受众在文物知识理解中的误读。共根据知识库实体关系标注语料中的实体关系2094条,其中创建者关系380条、主题关系240条、描述关系244条、日期关系632条、范围关系414条、管理关系184条。而为了对比实体关系抽取方法对未标记关系的发现能力,文章使用人工标注的方法对语料中文物实体关系进行了二次标注,经过比对,新增实体关系标注590条,其中创建者关系66条、主题关系8条、描述关系116条、日期关系198条、范围关系162条、管理关系40条。
3.3 基于深度学习的文物实体关系抽取
文章实验平台为CPU:I7-9750H、内存:16GB、显卡:GTX-1660Ti、显存:6G,实验环境为Python3.6。为了研究基于ALBERT的文物信息资源实体关系抽取方法的实体关系抽取效果,从两个方面进行实验。一是将知识库实体关系标注语料按8∶2的比例划分为训练集和测试集,再随机抽取20%的人工标注中新增的实体关系加入进测试集,以模拟随机环境下通过知识图谱与深度学习方法在文物信息资源实体关系抽取中的效果。二是将知识库实体关系标注语料作为训练集,人工标注实体关系作为测试集,以探究文章方法在未标记文物信息资源实体关系中的发现效果。为检验模型在实体关系抽取中的效果,文章采用精确度(Precision,P)、召回率(Recall,R)和F1(F1-score)值作为度量指标。精确度代表被预测为正样本的正确率,召回率代表实际为正样本被正确预测的比例,F1 值为两种指标的调和平均值,模型的综合抽取效果与数值正相关。
随后,文章将1 674条知识库标注实体关系作为训练集,420条知识库标注实体关系与随机选取的118条人工标注实体关系共同组成的538条实体关系作为测试集。抽取方法选择ALBERT base预训练模型提取字在句子级别中的语义特征,词向量维度128、隐藏层维度768。使用BiLSTM神经网络与注意力机制提取深层次语义特征。对比模型有BiGRU+ATT、BiRNN+ATT以及深层金字塔卷积神经网络(DPCNN)[38]。训练时,最大序列长度采用样本中句子的最大长度347,train_batch_size为32,droup_out_rate为02,learning_rate为0.01,优化器为Adam,BiLSTM隐藏层维数为128,Epochs设置为20但由于实验为小样本,为了防止过拟合,文章加入early stopping机制,连续5个Epoch未超过当前训练最佳精度则停止。同时为了对比ALBERT预训练模型在字符级别语义特征提取中的效果,文章选择当前综合性能最好的中文词向量预训练模型:中文词向量语料库[39]提取字符与词级别的语义特征,使用Skip-Gram模型训练,字符窗口长度为5,词频阈值为10,词向量维度为300,语料分词工具为jieba,同BiLSTM+ATT模型融合与文章方法进行对比,结果如图4所示,精确度、召回率和F1值取6种关系类别的加权平均数。

图4 随机样本实体关系抽取结果
从图4可以发现循环神经网络及其有关改进方法在序列数据的处理中要优于卷积神经网络,实验结果中的F1值分别提高0.07、0.09、0.11。ALBERT预训练模型在字符特征的提取上要优于目前Word2vec中的预训练词向量模型,F1值提高了0.08。从随机样本中的结果来看,文物信息资源中的实体关系具有较为明显的语义特征,在通过知识库实体关系标注后使用ALBERT base+ BiLSTM+ATT方法能够抽取大部分文物信息资源中的实体关系。
为了更进一步研究ALBERT预训练模型在未标记实体关系抽取中的效果,文章以知识库实体关系为来源的2094条实体关系作为训练集,人工标记新增的590条实体关系作为测试集,对ALBERT base+ BiLSTM+ATT方法在未标记实体关系中的发现能力进行探究。实验采用ALBERT base、ALBERT tiny、ALBERT large、ALBERT xlarge以及BERT base预训练模型进行对比,BiLSTM+ATT参数与前文中设置一致,精确度、召回率和F1值取6种关系类别的加权平均数,其结果如表2所示。

表2 未标记实体关系抽取结果

续表2 未标记实体关系抽取结果
从表2可以发现,ALBERT预训练模型的各种分支在实验中表现各异,由于ALBERT tiny、base、large、xlarge的隐藏层维度分别为312、768、1024、2048,而词向量维度为统一的128,致使其对语料中字符特征的提取时间产生了明显差异。而由于语料为小样本,隐藏层维度的提升并没有带来抽取效率的提升,相反由于文物信息资源文本特征较为集中的特点,隐藏层增加反而由于小样本带来的数据的稀疏性导致抽取效果下降。在同BERT base预训练模型的比较中,ALBERT base在召回率指标上领先,这是由于在90%的情况下ALBERT的输入都是raw sequence length,最长限制512,而BERT在90%的情况下是128,输入越长模型更容易捕获上下文中的语义特征,因此其召回率相对较高,但同时由于BERT base模型词向量维度为768,相对不容易产生词义的混淆,这也是其精确度相对较高的原因。综合表3的结果,ALBERT为字符向量的提取提供了多种方案,小样本的关系抽取可以根据样本数据选择最为适应的预训练向量模型,相较于早先推出的BERT模型,ALBERT大大减少了模型参数,但在计算量方面没有明显区别,其实体关系抽取效果也较为类似。
在实体关系抽取的具体分析中,文章依照抽取效果最好的ALBERT base+BiLSTM+ATT方法进行实验,研究文物信息资源实体关系6分类在抽取效果中的不同。

表3 未标记实体关系详细抽取结果
如表3所示,位置和时间相关实体关系中的抽取效果与其他分类相比有明显提升,这与文物信息资源中的位置和时间信息具有明确的表达规范有关,使得深度学习模型能够识别其固定的语义特征,致使抽取效果较好。在关系预测的实践中,文章以CSSCI收录论文《张择端《清明上河图》绘画长卷的叙事性》[40]中的例句“卷后张公药诗,其中:“通衢车马正喧阗,只是宣和第几年。当日翰林呈画本,升平风物正堪传。”隐约道出张择端是宣和年间画师,《清明上河图》也作于宣和年间。”为例进行关系预测。该句从知识库获取的实体关系有“张择端”与“《清明上河图》”是“创建者”关系,“《清明上河图》”与“宣和”是“日期”关系,而“张择端”与“宣和”两个实体具有何种关系知识库并未收录,因此文章利用训练出的深度学习模型进行关系预测,预测结果“日期”代表的时间关系,与例句中“张择端”与“宣和”实体间的实际关系一致,说明文章方法能够预测实体间可能存在的关联关系,丰富实体关系抽取的数量提高抽取效果,同时为历史学研究人员推断文物有关实体关系时提供参考。以上结果说明实体的时空关系在文物信息资源中具有显著的语义特征,通过实体关系的抽取,能够较好的发现与时空有关的知识,为文物信息资源的开发与利用提供新的研究方向。
4 总 结
实体关系是知识的数据来源,为解决文物信息资源中知识发现的问题,文章提出从知识库获取实体关系后构建文物知识图谱,利用远程监督方法进行文物信息资源的知识关系标注,使用ALBERT预训练模型构建基于深度学习的文物实体关系抽取方法,进行了实体关系抽取与发现的有关实验。在实体关系抽取实验中取得了F1值0.9的性能,在未标记关系的发现实验中取得了F1值0.62的性能。同时,研究了不同体量预训练模型对于小样本数据在计算时间与抽取效率上的差异,发现了综合性能最好的抽取方法。挖掘了文物信息资源中具有明显语义特征的两类实体关联关系,为文物信息资源知识发现的有关研究提供了新的思路。
未来的研究中,文章将进一步提高文物信息资源实体关系抽取的效率,并针对时空数据进行文物信息资源有关知识的挖掘与发现,拓展文章方法在文物信息资源有关研究中的应用范围。
猜你喜欢
金桥(2022年6期)2022-06-20
北京大学学报(自然科学版)(2022年1期)2022-02-21
中国外汇(2019年18期)2019-11-25
东方考古(2019年0期)2019-11-16
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
读写算·小学低年级(2015年12期)2015-12-12
小学生·多元智能大王(2014年8期)2014-08-28
科技视界(2014年27期)2014-08-15
