
基于不确定度和气动模型的气动数据融合算法
2022-08-23 06:50王文正孔轶男
空气动力学学报 2022年4期
邓 晨,陈 功,2,*,王文正,孔轶男
(1. 中国空气动力研究与发展中心,绵阳 621000;2. 国防科技大学 空天科学学院,长沙 410072)
0 引言
飞行器气动数据的来源主要有三种方式:风洞试验、数值计算和飞行试验[1]。三种方式各有优缺点:风洞试验可以模拟飞行状态和飞行环境,但是存在支架干扰、雷诺数影响、洞壁干扰等限制,不能完全模拟真实飞行状态[1];数值计算方法灵活,成本低,提供的数据多,但是因为物理模型不够完善,使得复杂状态的计算精度较低;飞行试验可以完全模拟真实飞行状态,但是试验代价昂贵,大气数据和传感器误差影响大,气动参数辨识困难,得到的有效飞行试验数据有限[1-2]。
为了弥补各种数据的“缺陷”,综合利用各种方式的优势,在降低试验代价的同时,提高气动数据精度,国内外很多专家学者提出了基于数据融合的方法并做了大量的研究。Alexandrov等[3]对复杂的模型进行设计和优化时,利用低精度数据进行迭代,并用高精度数据监控设计优化的进展,最终在三维问题的结果精度提高的同时,成本节约了三倍;Eldred等[4]采用了二阶加法、乘法和组合修正的数据融合算法,有效地克服了工程设计过程中的非光滑性和计算成本高的问题;Keane[5]在机翼的优化设计中,利用Kriging模型建立了基于试验的预测模型和基于CFD数据的响应面模型的融合模型,气动数据的预测精度有了较大的提高。国内,中国空气动力研究与发展中心的王文正等[6]创造性地提出了基于数学模型的气动数据融合,建立了反映气动力随着气动滚转角变化的数学模型;傅建明等[7]采用Chebyshev-Taylor-Fourier混合级数来平衡不同精度数据之间的不确定度,并采用最小二乘原理来求解级数参数,该方法高效实用,工程应用前景良好。
根据国内外的研究可以发现,气动数据融合算法可以分为基于不确定度和基于气动模型的数据融合算法[1]。目前两种算法的研究都有一些,但是缺少了对比分析,而有关于融合算法的适用性的研究几乎没有。鉴于此,本文首先提出并实现了两种数据融合算法:一种是基于不确定度的多保真度气动数据加权融合算法,通过建立各数据源的高斯回归模型来量化数据的不确定度,并利用专家经验等先验信息来对数据的不确定度进行修正,最后通过加权融合进行数据融合;另一种是基于建模的CoKriging模型算法,在Kriging模型的基础上考虑了不同数据之间的相关性,直接建立融合代理模型。然后以某型飞行器气动数据为例,对比分析得到了两种算法的优缺点。
1 数据融合算法
1.1 基于不确定度的加权融合算法
基于不确定度的加权融合算法,主要利用了高斯过程回归来量化每一种数据源的不确定度,并利用不确定度作为权值进行加权融合。下面简单介绍高斯过程回归算法和基于不确定度的加权融合算法。
1.1.1 高斯过程回归算法
高斯过程是一个随机过程,对处理小样本、非线性、高维数等复杂问题具有良好的适用性[8-9]。其本质是一种基于贝叶斯优化的回归算法。给定一个数据集在集合D中,定义具有联合高斯分布的变量集合f(x),由均值函数和协方差函数组成:
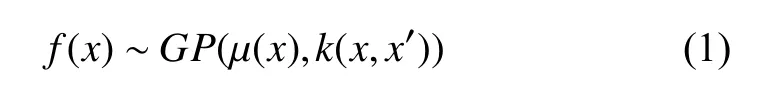
考虑到噪声,则高斯过程回归的一般模型为:

式中,ε为独立的高斯白噪声。
根据贝叶斯原理,高斯过程回归在数据集D建立了y的先验函数,则样本点和新的数据点f∗的联合高斯分布为:
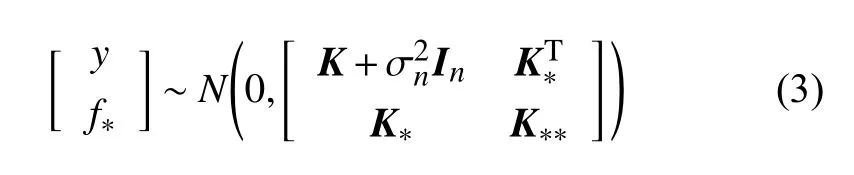
式中,K、K∗和K∗∗的定义如下:
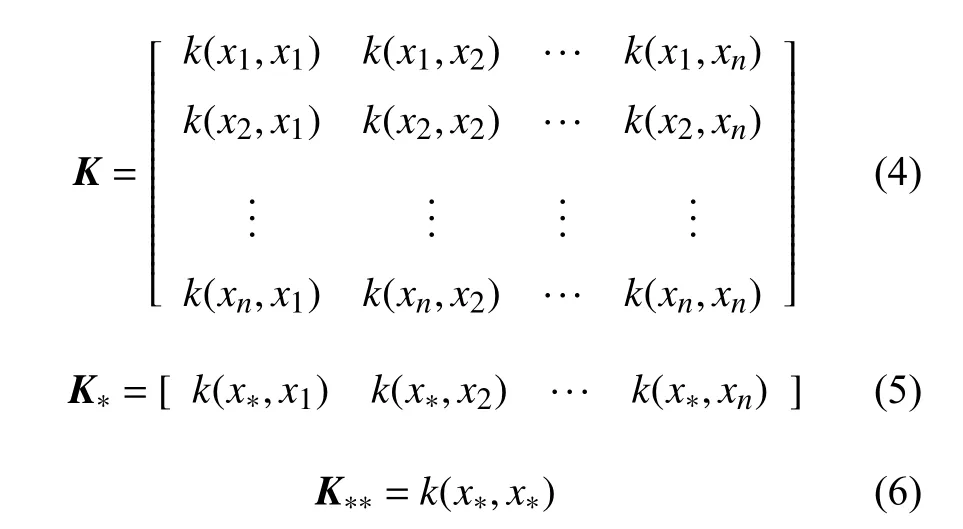
根据高斯过程的性质,f∗的后验概率分布f∗|X,y,x同样符合高斯分布:
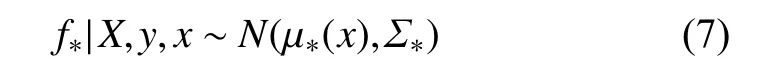
式中:
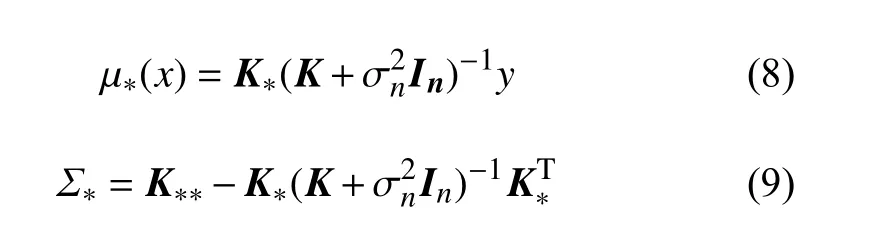
µ∗(x)即 新的数据点x∗预 测的输出值, Σ∗为预测输出的方差,这样便求得预测值的分布特征。即获得了数据集的不确定度。有关于高斯回归过程中的协方差函数的选择和超参数的优化参阅文献[10]。
1.1.2 加权融合算法
针对多来源的气动数据,采用高斯过程回归进行回归处理,得到每一种数据源的均值 µGPRi和方差接着采用基于不确定度的加权融合算法进行数据融合,具体流程图如图1所示。
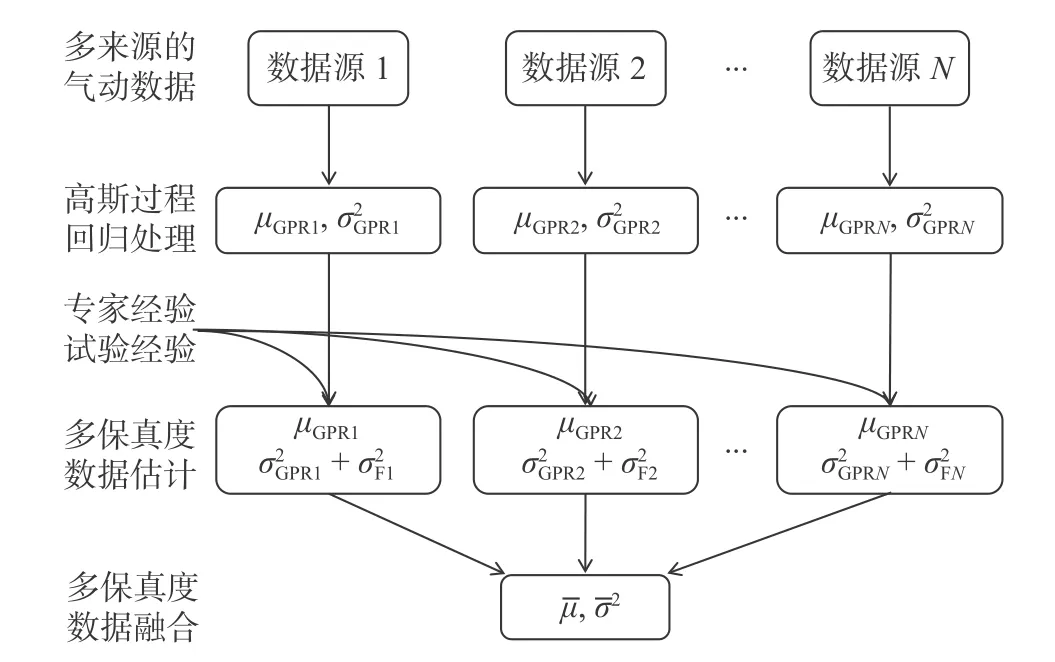
图1 基于不确定度的气动数据融合算法Fig. 1 Aerodynamic data fusion algorithm based on uncertainly
由图1可知,首先采用了高斯过程回归对不同来源的气动数据样本进行回归处理,得到模型的不确定度。接着因为每一种数据都来自计算或者测量,与真实值存在偏差,所以需要根据专家经验等先验信息,确定每一种数据的保真度。保真度反映了气动数据样本和真值间的不确定度,保真度越高,则数据越精确,并定义数据源i的保真度函数为。然后将模型的不确定度和数据的不确定度结合起来得到每一种数据源的总的不确定度 µTi和,如式(10)和式(11)所示。最后根据加权融合算法对每一种数据总的不确定度进行融合估计。
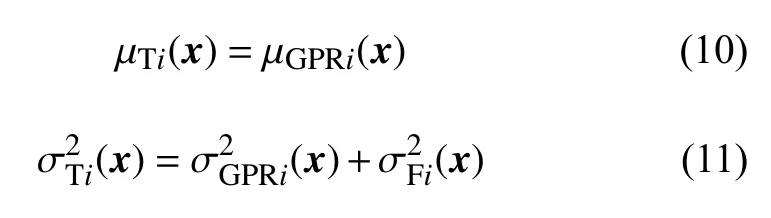
对于高精度数据,因为样本点过少,所以它的模型不确定度高,而高精度数据本身的不确定度低;而对于低精度数据,因为样本点很多,所以它的模型不确定度低,而低精度数据本身的不确定高。通过加权融合的方式,可以得到精度更高、不确定度更低的数据。加权融合算法即对每一种数据源分配不同的权重系数w,再进行相加处理。假定各数据源是相互独立的,则权重系数和数据的不确定度方差成反比,即方差越高,说明数据精度越低,权重系数就小。具体表达式如下:
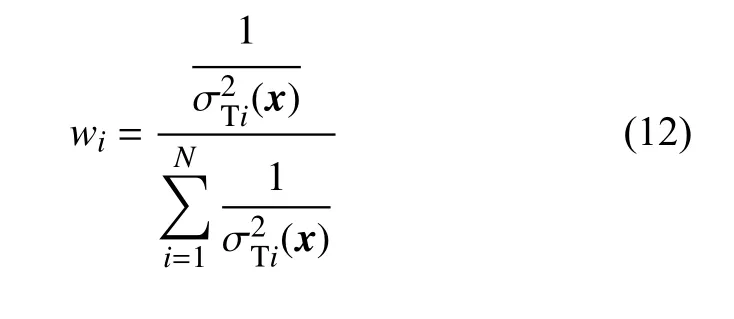
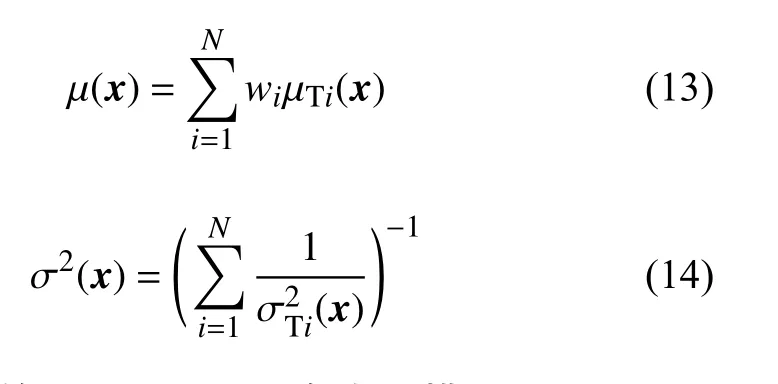
1.2 基于模型的CoKriging融合代理模型
CoKriging模型是20世纪70年代发展起来的一种更有效的地质统计学插值模型[11-12]。目前国际上对CoKriging模型的研究主要集中于地质统计学和数学统计学等领域,在航空航天等工程科学领域的研究也正逐渐得到重视[13]。
CoKriging模型的原理如下[14]:假设一个具有m个设计变量的优化问题,高、低可信度分析程序的抽样位置为:
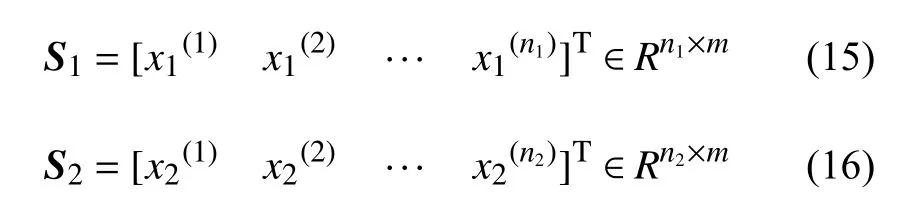
式中:下标“1”和“2”分别代表了高、低可信度,n1和n2分别代表高、低可信度样本点数。相应的目标或约束函数的值为:
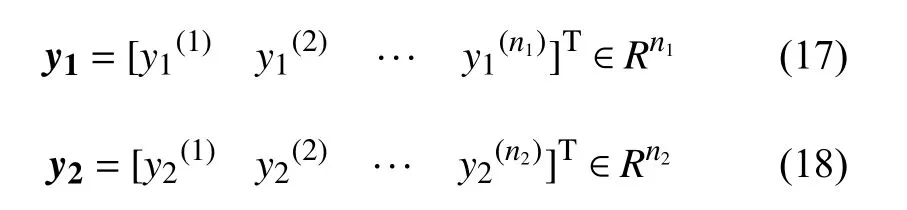
CoKriging代理模型的预估值为:
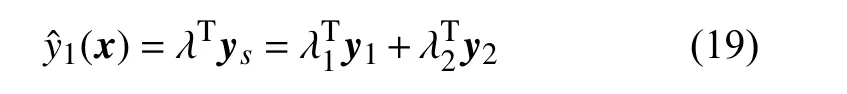
式 中: λ1和 λ2为 对 应的 加 权系 数。假 如 存在 分 别 与y1和y2对应的两个静态随机过程:
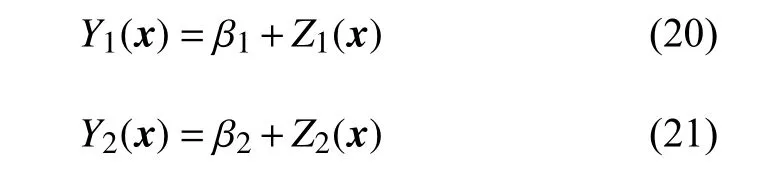
式中: β为全局趋势模型,代表Y(x)的数学期望值;Z(x) 为均值为零、方差为 σ2的静态随机过程。在设计空间不同位置处,随机变量之间的协方差和交叉协方差定义为:
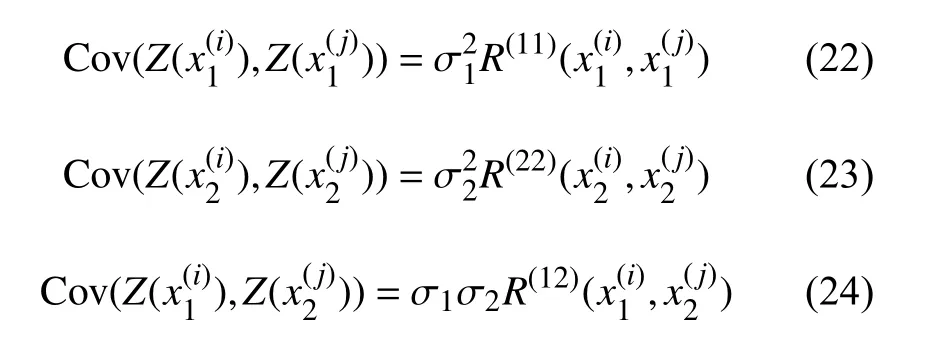
式中R为相关函数,只与空间距离有关,并满足距离为零时等于1,距离无穷大时等于0。
经过推导[13],得到CoKriging模型预估值和预估值的均方差如下:
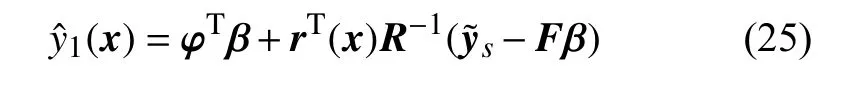
式中:
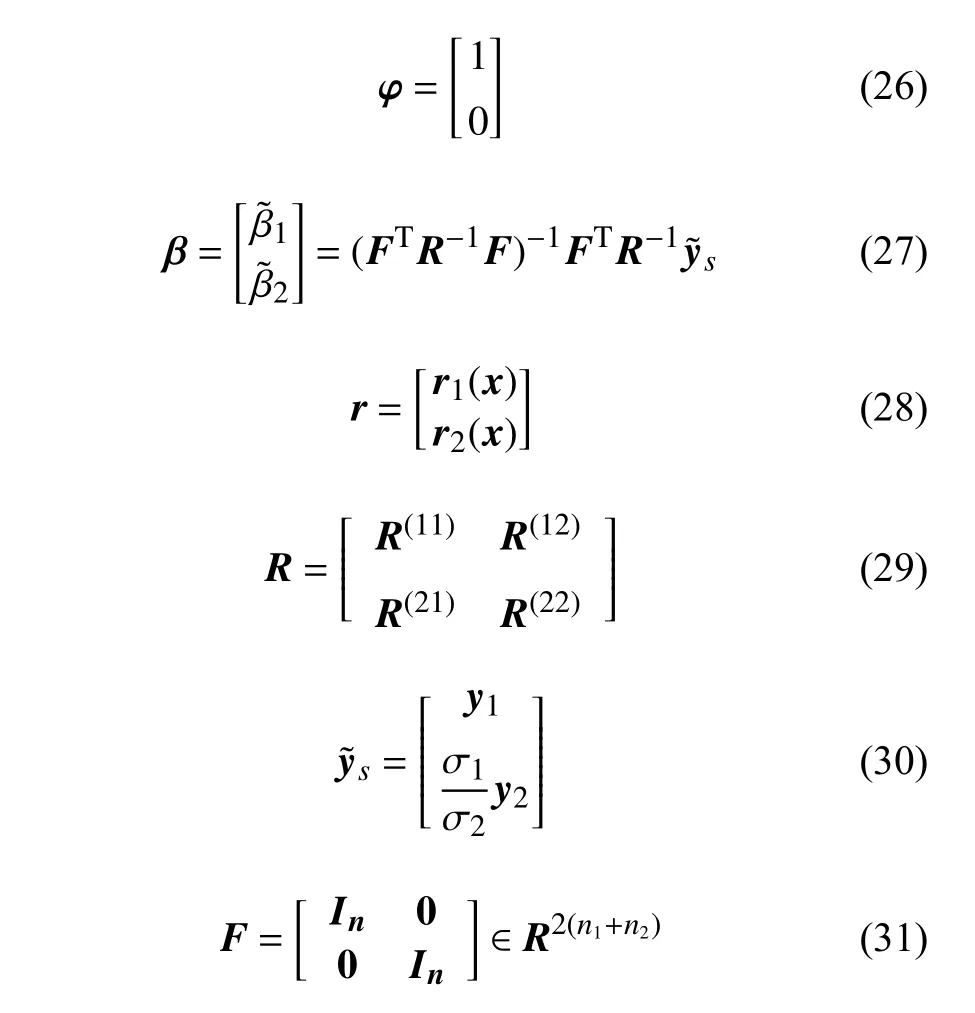
且有:
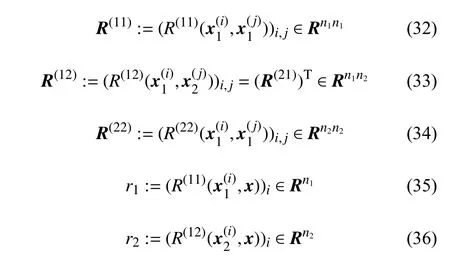
CoKriging模型预估值的均方差为:
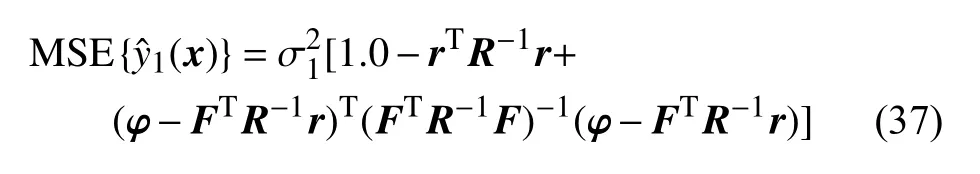
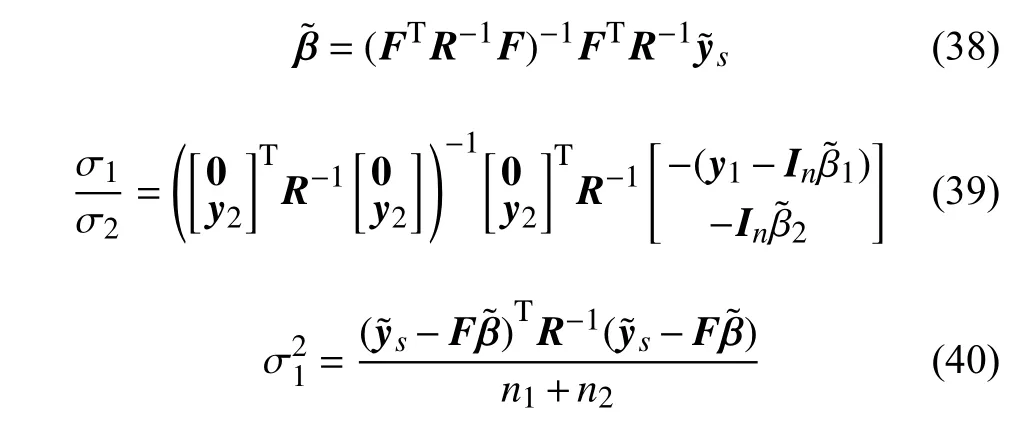
剩余参数θ(11)、θ(12)、θ(22)没有解析最优解,可以通过数值优化算法求解下式的最大值得到:
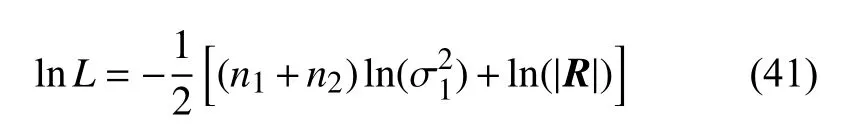
在算法实现过程中,需要注意如下几个关键点:
(1)样本点归一化。将样本数据归一化后再建立CoKriging模型,可以提高模型的精度和鲁棒性。
(2)模型参数优化。合理的模型参数,可以显著提高CoKriging模型精度。
(3)相关矩阵R保持正定。采用“正则化”方法,让R保持正定。
(4)合理的矩阵分解方法。采用Cholesky分解,可以有效提高计算效率。
2 两种数据融合算法结果对比分析
本节中,利用已有的典型飞行器高精度数据和低精度的数据来建立飞行器气动模型。首先使用Kriging模型对高、低精度数据分别建立代理模型,接着使用基于不确定度和CoKriging代理模型来建立融合模型,最后进行比较分析。
2.1 数据样本说明
选择马赫数Ma和迎角α作为设计变量,轴向力系数CA作为函数响应值。采用现代试验方法进行试验方法设计[15-16],一共得到高精度数据样本点11个,低精度数据样本点24个。并将高精度样本点分为两部分,一部分用来进行训练,另一部分作为验证。如表1~表3所示。

表1 用来训练的高精度数据样本点Table 1 High-precision samples for training

表2 用来验证的高精度数据样本点Table 2 High-precision samples for validation

表3 部分低精度数据样本点Table 3 Part of low-precision samples
2.2 建立模型及分析
利用样本数据建立了四个轴向力系数模型,分别是高高精度数据Kriging模型、低高精度数据Kriging模型、不确定度融合模型和CoKriging融合模型,具体结果如下。
2.2.1 高高精度数据Kriging轴向力系数模型
图2给出了高高精度数据Kriging模型对轴向力系数的预测值。由图可见,高马赫数时模型预测精度较差,与理论分析结果相差较远,这是因为缺少了高马赫样本点,而低马赫数时预测结果较好。
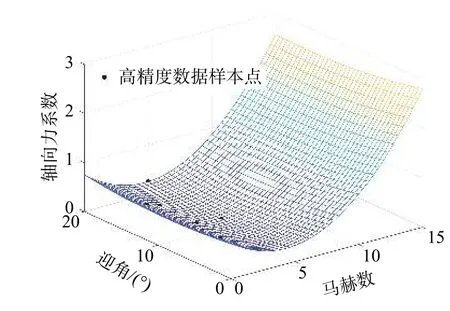
图2 高精度数据Kriging模型预测值Fig. 2 Predictions of the Kriging model using high-precision samples
2.2.2 低高精度数据Kriging轴向力系数模型
图3给出了低高精度数据Kriging模型对轴向力系数的预测值。由图可见,因为低精度数据样本点多且广,建立的模型在变量全设计空间预测情况较好,与样本点接近。但是因为低精度数据本身精度低,所以预测结果只是接近样本点,与真实情况的误差未知。
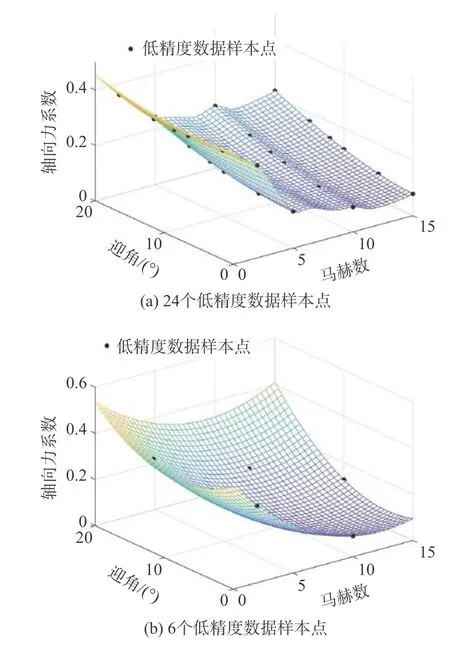
图3 低精度数据Kriging模型预测值Fig. 3 Predictions of the Kriging model using low-precision samples
2.2.3 融合模型—基于不确定度的加权融合模型
利用高斯过程回归量化了不同精度数据的不确定度之后,采用加权融合算法得到结果如图4所示。根据不确定度进行加权融合,这种融合方式没有考虑到不同精度数据之间的相关性,所以在高马赫数时的预测值与低精度数据样本值几乎一样,和真实值也有所差异。
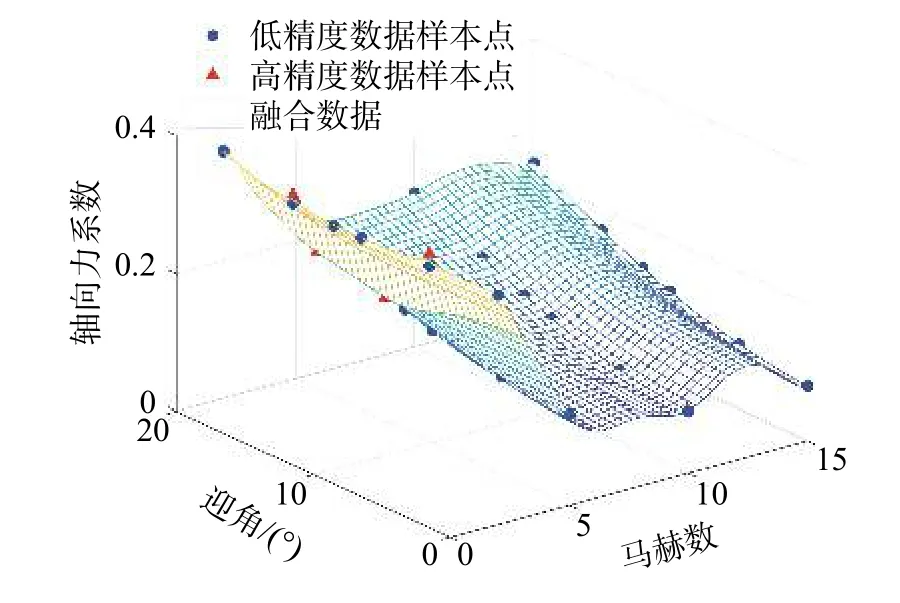
图4 基于不确定度的加权融合模型预测值Fig. 4 Predictions of the weighted fusion model based on uncertainly
2.2.4 融合模型—基于建模的CoKriging融合代理模型
CoKriging融合代理模型就是在Kriging模型的基础上,考虑了不同数据之间的协相关性,所以结果更符合真实情况。本节中,由于高、低精度数据具有相似的函数变化趋势,只是存在小幅度的平移或旋转现象,为简便,假设其具有如下的相关性:
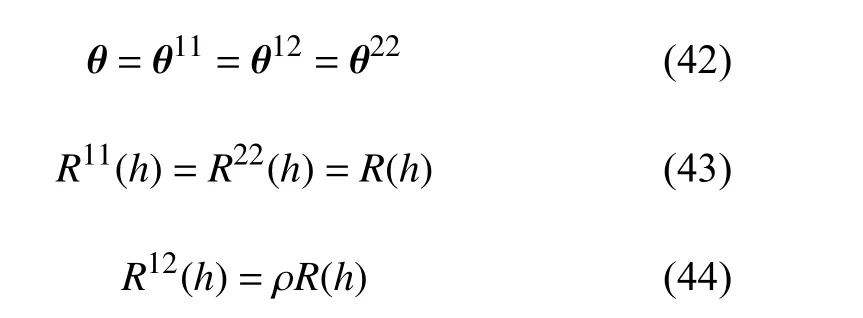
式中:h为空间距离;ρ为两种不同数据的相关系数,一般作为超参数进行优化寻优获得,可以表示两种数据之间相关性,这种相关性只是代表了数据数值上的相关,没有具体的物理含义。本文将 ρ 当成超参数,通过最大似然估计方法寻优求得值为0.930。得到CoKriging融合代理模型预测结果如图5所示。
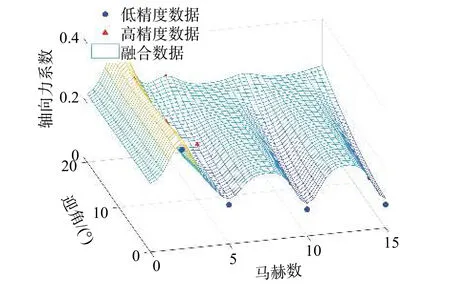
图5 CoKriging融合代理模型预测值Fig. 5 Predictions of the CoKriging fusion model
与不考虑数据相关性的直接加权融合相比,CoKriging模型的结果更符合真实情况:在低马赫数时,预测结果更接近高精度数据结果;在高马赫数时,高、低精度数据相互修正,得到了一个更加符合理论分析和真实情况的结果。
2.3 预测结果对比分析
训练得到两个单精度数据模型和两个融合模型。为了比较不同模型的预测结果,定义误差值Err:
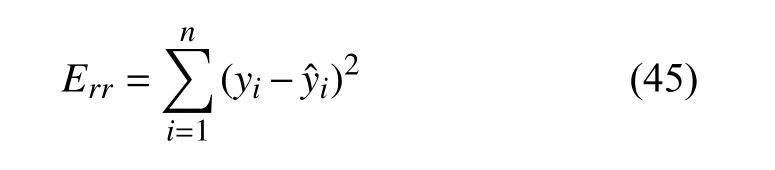
式中,yi为 用于验证的高精度样本值,yˆi为各模型对应的预测值。误差值Err越小,则越接近真实值。计算得到四个模型的误差值如表4、表5所示。对表4和表5进行横向和纵向对比分析,总结得到以下结论:

表4 不同单数据模型的预测误差值Table 4 Prediction errors of single-data models

表5 不同融合模型的预测误差值Table 5 Prediction errors of fusion models
1)单源数据建模时,用相同数量的数据点建模,高精度数据建立的模型精度比低精度模型高;
2)数据点越多,建立的模型越精确,数据点覆盖的设计变量空间越广,得到的模型越精确;
3)与单源数据的建模结果相比,两种融合模型的预测结果的精度都有较大的提升;
4)相比于基于不确定度的直接加权算法,CoKriging融合模型的精度更高。
本文用于训练和验证的高精度数据来自风洞试验,因为试验条件限制,没有高马赫数时的气动数据。为了获得参数空间更广的融合数据,所以对建立的预测模型进行了大范围的外插,这种方法虽然在工程上不适定,但是对于定性分析具有一定的参考价值。在高精度数据参数变量空间内,融合数据內填了高精度数据,精度也得到了提高,而在外推的变量空间内,融合数据也为数据的变化趋势提供了参考。后续研究方向可以为通过补充其他手段得到的高精度数据进行补充完善,让涵盖所需要的建模空间且相对均匀,这样能得到准确度、可信度更高的结果。
3 结论
本文研究了两种气动数据融合算法:一种是基于不确定度的直接加权融合算法,另一种是基于模型的CoKriging融合代理模型算法。并以典型飞行器气动数据为例进行了对比分析,得到以下结论:
1)与使用单精度数据的建模结果相比,两种融合算法预测结果的精度都有较大的提高。
2)对于融合算法,数据样本点对预测精度影响很大,数据点越多,覆盖范围越广,结果越精确;
3)和基于不确定度的加权融合算法相比,考虑了数据之间相关性的CoKriging算法建模得到的结果精度更高。
4)融合数据主要有两个作用:一是对高精度数据进行內填,补充参数空间内的数据;二是通过外推,对参数空间外的数据变化趋势进行预测。后续研究方向可以为通过补充其它手段得到的高精度数据进行补充完善,让高精度数据涵盖所需要的建模空间且相对均匀,这样能得到准确度、可信度更高的结果。
猜你喜欢
科学家(2022年3期)2022-04-11
科学与财富(2021年34期)2021-05-10
锦绣·下旬刊(2020年9期)2020-01-28
小天使·二年级语数英综合(2019年4期)2019-10-06
智富时代(2018年8期)2018-09-28
智富时代(2018年8期)2018-09-28
轻兵器(2015年16期)2015-09-10
电影故事(2015年16期)2015-07-14
