
基于深度学习的微服务故障检测研究
2022-08-19 08:34庄卫金
计算机工程与应用 2022年16期
庄卫金,张 鸿
中国电力科学研究院有限公司 南京分院,南京 210003
近年来,随着企业信息化的快速发展,现代软件系统的数量越来越多,规模越来越大,结构也越来越复杂。面对新形势的变化,传统的系统架构设计方法显露出了明显的弊端:系统变得非常臃肿冗杂,无法提供可靠的服务,维护成本变得越来越高,想要扩展一些新功能变得越来越困难[1]。而微服务则从架构的角度出发,在根本上解决了这些问题。
微服务的概念最早由Fowler 和Lewis[2]提出,它的核心在于将一个大的应用系统按照业务逻辑划分成若干个独立的微服务,每个微服务负责完成一项单一的业务功能,各个微服务之间存在清晰的边界,并通过轻量级的通信机制(例如HTTP)进行信息交互。由于单个微服务的复杂程度并不高,这样每个微服务都可以由少量的开发人员负责,分别进行开发。而传统的大型应用服务则需要大量的开发人员共同维护一个代码库,维护成本、交流成本都很高,并且容易弱化开发人员的责任意识。此外,由于采用微服务架构的系统赋予了每个微服务不同的业务功能,并且彼此相互独立,这样当出现扩展新功能的需求时,通过简单地向系统中添加一些新的微服务就能实现,具有很强的可扩展性。考虑到微服务架构相对于传统方法的巨大优势,目前已经有很多的企业采用了微服务架构,例如Twitter、Netflix、Amazon等。
虽然微服务架构具有更高的可维护性和可扩展性,但同时它也为系统的故障检测带来了更大的挑战。由于采用微服务架构的软件系统是由一系列彼此独立并且更新频繁的组件构成的,这些组件之间还需要通过复杂的网络交互模型进行通信,从而大大增加了系统发生故障的几率,并且有关故障点的定位也变得更加困难。除此之外,各个微服务组件之间联系密切,相互之间往往存在依赖关系,因此一个组件发生故障就可能引发连锁反应,影响其他组件的正常服务,最终可能造成整个应用系统的崩溃[3]。根据以上分析,不难得出以下结论:故障检测问题是阻碍微服务架构进一步发展的关键问题之一,如何在应用系统发生故障时快速定位出故障发生的位置并准确地分析出故障发生的原因是当前研究的重点方向,对于提高微服务架构的服务质量(quality of service,QoS)具有非常重要的价值和意义。
目前关于面向微服务架构的故障检测方法主要有建立依赖图(dependency graphs)和故障树(fault trees)两种[4]。其中依赖图是用来对微服务架构中各个应用服务之间的依赖关系进行建模,并且目前还没有成熟的自动构建依赖图的方法,已有的方法往往存在着准确性不足、效率不够高效的问题。故障树由Rausand 等人[5]定义,是一种可以显示应用系统中潜在关键事件与该事件原因之间相互关系的逻辑图,它可以是定性的,也可以是定量的。故障树分析就是构造这样一个故障树的过程。由于一个应用系统中存在着众多的关键事件,这些事件与其对应的原因之间的相互关系错综复杂,因此故障树的构造是一个非常耗时、低效的过程,这影响了这类方法在现实场景中的应用。
深度学习作为机器学习研究中的一个新领域,近年来已经在分类、检测、识别等多项任务中取得了前所未有的成就,受到了各界的广泛关注,但目前还没有人尝试将深度学习方法用于微服务架构的故障检测中。本文将深度学习方法引入到面向微服务架构的故障检测研究中,提出了一个基于门控循环单元(gated recurrent unit,GRU)[6]的故障检测方法MS-GRU。该方法的核心在于它能够从以往的应用数据中分析、学习到导致故障发生的模式信息,并将这些信息用于未来的故障诊断和预测中,从而显著改善了微服务架构的服务质量。GRU是一种特殊的循环神经网络(recurrent neural network,RNN)[7],与普通的RNN 网络相比,GRU 能更好地处理长范围依赖的问题。虽然长短期记忆网络(long shortterm memory,LSTM)[8]也能处理该问题,但GRU 模型结构更简单,处理效率更高,效果更好,因此本文选择GRU作为基础网络来构造一个高效的面向微服务架构的故障检测模型。为了评估本文方法的性能,进行了广泛的实验,实验结果证明了本文方法的有效性和优越性。
1 相关工作
微服务架构将一个大型的服务拆分成一系列相互独立、功能各异的微服务,增强了应用系统的可扩展性和可维护性,但同时也为系统内部的故障检测带来了更大的挑战。目前故障检测问题已经成为阻碍微服务架构进一步发展的瓶颈。为了改善微服务架构的服务质量,使其能够得到更加广泛的应用,近些年来研究者们针对故障检测问题展开了一系列的研究。本文首先对国内外现有的一些面向微服务架构的故障检测方法进行详细的介绍。
采用传统架构的应用系统通常利用人工设定报警规则[9]来进行故障检测,但该方法并不适用于微服务架构。这是因为采用微服务架构的应用系统中,各个微服务之间往往存在着复杂的交互关系,所以系统管理员很难设定合理的故障检测规则,也不能细粒度地诊断发生故障的原因。为了解决该问题,王子勇等人[10]提出了一种面向微服务架构的基于执行轨迹监测的故障检测方法。具体来讲,该方法首先借助动态插桩技术来监测各项微服务的处理流程,并利用树形结构来刻画各项微服务请求处理的执行轨迹;接着基于树编辑距离和主成分分析来分别进行系统错误的诊断及性能异常的检测。但该方法也存在一些尚未解决的问题,例如可能会遗漏一些关键方法,性能开销比较大等。
徐康明[11]指出当前基于故障树的检测方法在构造故障树的过程中忽略了应用系统中的差错容忍因素,并且没有考虑到在系统实际运行过程中不同执行路径的执行概率不一致的实际情况。针对这些问题,徐康明[11]提出了一种新的基于故障树的检测模型,该模型在系统中增加了差错容忍机制并考虑了不同执行路径执行概率的差异,从而增强了系统运行的稳定性,提高了系统运行的成功率。
Ma等人[12]提出了一个能够有效管理各个微服务组件之间复杂调用关系的基于图的微服务分析和测试方法(graph-based microservice analysis and testing,GMAT)。GMAT 能够自动生成服务依赖图(service dependency graph,SDG),用于分析并可视化各个微服务之间的依赖关系。利用GMAT,人们能够在开发的早期阶段通过分析具有潜在风险的微服务调用链来检测异常,并在开发新版本的系统时有效跟踪各个微服务之间的联系。实验结果证明GMAT 在小型的和大型的微服务应用系统上都有着良好的表现。
刘一田等人[13]针对全链路应用服务监控的扩展问题,设计了一个灵活的微服务监控框架并部署在现有的服务管理层,以监控微服务的状态及不断变化的服务负载。此外,该框架还使用了Raft算法[14]来增强系统中的数据一致性,从而有效避免了单点故障问题的发生。然而该框架也存在着部署架构较为复杂,性能损耗较大等不足。
Celesti 等人[15]专注于解决物联网设备中微服务的可靠性问题,提出了一个基于容器虚拟化的物联网看门狗系统。当在物联网设备上运行的微服务出现故障时,该系统首先会尝试修复它,若修复失败,会尝试用另一个备用的微服务替换它,从而大大增强了物联网设备中微服务的可靠性。Heorhiadi 等人[16]指出当前的互联网应用系统大都采用了微服务架构,这些系统里面的微服务组件一天往往会被更新、部署数百次。为了应对加速的软件生命周期,Heorhiadi等人[16]提出了Gremlin,一个用来系统性地测试微服务故障处理能力的框架。Gremlin基于这样的观察:各个微服务之间是低耦合的,因此它们依赖于网络中标准的信息交换模式来进行通信。Gremlin允许操作人员通过在网络层操纵各个微服务之间的通信来轻松地设计和执行系统测试。Mayer等人[17]提出了一个可以实现微服务监控及管理的系统,能够满足不同用户的需要。该系统支持不同监控设施的集成,以收集充足的与微服务相关的运行数据。除了运行数据之外,该系统还支持其他信息源的融合,从而能够在微服务系统出现故障时,更准确地分析出故障发生的原因。
彭天舒[18]分析总结了采用微服务架构的应用系统可能会遇到的一些异常情况,主要包括两方面:由于微服务之间互相信任而引发的内部攻击,以及攻击者通过避开权限管理机制来提升自身权限而引发的权限攻击。这些攻击可能会造成调用路径的异常,调用顺序与层次关系的异常,功能与角色对应关系的异常等。为了能对上述异常进行及时有效的检测,彭天舒将入侵检测技术和分布式追踪技术结合在一起,提出了基于特征规则的异常检测方法。不过由于该方法采用离线的检测方式,会有一定的滞后性。
以上的故障检测方法都是基于传统方法,本文将深度学习方法引入到面向微服务架构的故障检测研究中,提出了一个基于GRU 的故障检测方法MS-GRU,显著提升了故障检测的精度和效率,从而改善了微服务架构的服务质量。
2 MS-GRU故障检测模型
基于微服务架构设计的应用系统中的每个微服务组件都有可能发生故障,如何快速地检测到故障的发生,并准确地定位出故障发生的位置,对于改善微服务架构的服务质量有着非常重要的意义。为此,本文提出了一个基于GRU[6]的故障检测模型MS-GRU,模型架构如图1所示。
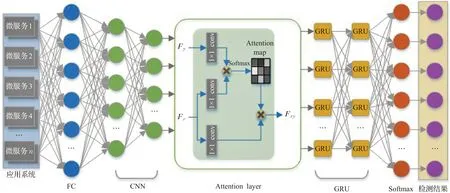
图1 MS-GRU模型架构图Fig.1 Architecture of proposed MS-GRU model
首先对MS-GRU 模型进行一个整体的概述。MSGRU模型是一个数据驱动(data-driven)的方法,与传统的微服务故障检测方法相比,MS-GRU对于未知以及不断变化的应用场景更具鲁棒性。MS-GRU 输入层神经元和输出层神经元的数量与处于激活状态的微服务组件数量保持一致。各个微服务组件的工作状态信息、与其他组件的依赖关系、通信状况等各类有关数据在经过标准化处理后得到一组向量,作为MS-GRU 模型的输入。MS-GRU利用这些数据进行网络的训练,以从历史数据中学习导致故障发生的模式信息,包括空间模式和时间模式两种。其中空间模式主要指各个微服务组件之间的依赖关系,时间模式主要指输入的负载情况、资源冲突情况等。MS-GRU的核心思想在于,以往导致故障发生的条件可用于预测在未来的某个时间点是否会有故障发生。MS-GRU 的输出即是每个微服务组件将要发生故障的概率。
MS-GRU 模型是将深度学习方法引入微服务故障检测任务的首次尝试,如何设计一个与该任务特性相适配的神经网络是本文要重点解决的问题。具体来讲,针对微服务故障检测任务中存在的数据类型不统一,数据量庞大,各特征间依赖关系难以学习,网络训练容易出现梯度消失和梯度爆炸等各个问题,设计了一系列相应的模块来解决。下面对MS-GRU 模型的各个模块进行具体的介绍。
数据预处理模块。MS-GRU 模型的输入包含了属性不同、度量单位各异、值域差异明显的各类数据,如果不对这些数据进行预处理,可能会对最终结果造成不可预估的影响。例如,时间数据采用秒或毫秒,距离数据采用米或厘米,可能会导致完全不同的结果。一般而言,使用较小的度量单位来表示属性会导致该属性具有较大的值域,而值域较大的属性往往具有更大的“权重”去影响最终结果。为了避免由于度量单位的不同而对最终结果产生干扰,在将原始数据送入网络模型之前应该预先对其进行标准化处理,以赋予所有属性相同的权重。这里采用了z-score标准化方法来处理MS-GRU模型的原始输入数据x:

其中,xi为x中第i项数据,μx为x的均值,σx为x的标准差,xi′为经过标准化处理后的数据。
全连接层(fully connected layers,FC)和卷积层(convolutional neural networks,CNN)。输入MS-GRU的数据除了种类各异外,在数量上也非常庞大,其中往往蕴含着很多无用和冗余的信息,它们会阻碍模型检测精度和检测效率的提升。为了从原始数据中提取出关键特征(feature)信息,传统方法通常采用手工设计(hand-crafted)的方式,但这种提取特征的方式是非常主观、低效的,很难处理海量的输入数据。为了解决这个问题,本文引入了深度学习的方法,将经过数据预处理后的微服务数据输入若干个全连接层和卷积层,这里网络层包含了成千上万的参数(parameters),能够在模型的训练过程中自动、高效地从输入数据中提取出关键的特征信息,用于后续的故障检测。
注意力层(attention layer)。各个关键特征之间往往不是相互独立的,而是存在一定的依赖关系,并有着强弱之分。而全连接层和卷积层只对数据中的关键特征进行了提取,没有考虑各个特征之间的依赖关系,限制了故障检测模型的性能。为了解决这个问题,本文提出了一种新的注意力机制(attention mechanism)来学习各个关键特征之间的依赖关系。注意力机制最初由Bahdanau等人[19]提出,现已成为神经网络结构的重要组成部分,并被广泛应用于自然语言处理、计算机视觉、统计学习等领域。本文针对故障检测任务的独特性,提出了一个与其特性相适应的新的注意力层。具体来讲,对于前一卷积层输出的任意两个特征Fx和Fy,将其转换到两个特征空间s和t以计算它们之间的attention:
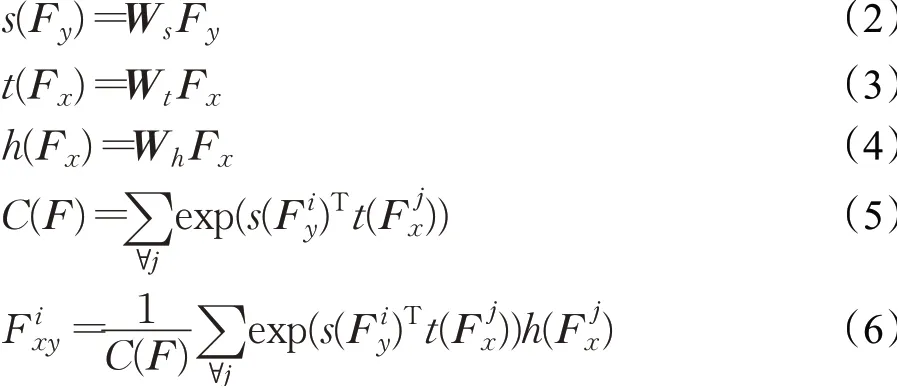
其中,Ws、Wt和Wh是可学习的权重矩阵,对应于图1中的1×1 卷积。i是输出位置的索引,j代表所有可能位置的索引。
本文提出的注意力机制与传统的注意力机制的主要区别在于:传统的注意力机制的目标在于学习一个注意力权重矩阵,应用于当前层的各个神经节点,对于那些重要的节点,赋予它们较大的权重,对于那些次要的节点,赋予它们较小的权重。由于每个神经节点都包含着某种特征信息,经过上述操作,神经网络就能从众多特征信息中选择出对当前任务目标更关键的信息。而本文所提出的注意力机制则不同,其更多地关注到了各个特征信息间的依赖关系,这是与面向微服务架构的故障检测任务更相适应的。而对于关键特征信息的提取,通过前面的全连接层和卷积层已经实现。
总的来说,通过本文提出的注意力层,模型学习到了各个关键特征之间的依赖关系,有利于模型检测精度的提升。
GRU 层和Softmax 层。GRU 网络解决了长序列训练过程中经常发生的梯度爆炸和梯度消失问题,因此即使对于很长的数据序列,GRU 也有着很好的表现。这里引入了多个GRU 层,它们以注意力层的输出作为输入,在不断的网络训练中去学习导致故障发生的模式信息。接着Softmax 层以GRU 层输出的模式信息f作为输入,输出各个微服务组件发生故障的概率p:

其中,pi代表第i个微服务组件发生故障的概率,fi代表最后一层GRU里第i个神经元的输出,n代表应用系统中微服务组件的数量。
值得指出的是,虽然GRU层和Softmax层都不是新的方法或技术,现已得到了广泛的研究和验证,但本文主要的贡献在于将它们扩展应用于一个更具挑战性的新任务:面向微服务架构的故障检测。并且为了让GRU网络与新任务更加适配,还对其进行了结构上的调整:对于GRU 网络中的状态单元,先使用Leaky ReLU激活函数对其进行处理,之后再让其进行下一步的计算。经过这样的调整,进一步避免了梯度爆炸和梯度消失问题,从而可以使用更深的网络结构,能够解决传统的面向微服务架构的故障检测方法难以深入挖掘数据的问题,有利于提高模型的检测精度。本文将深度学习方法引入该领域,这为该领域的进一步发展提供了一种新的思路。
损失函数。根据模型预测结果与实际情况的差异,定义了交叉熵损失函数(cross entropy error function):
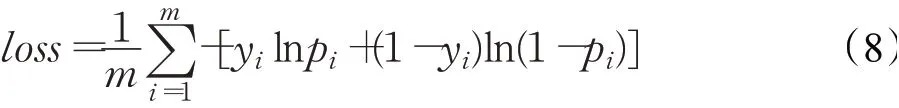
其中,m代表样本数据的数量,yi代表现实中的故障发生情况(0代表未发生故障,1代表发生了故障),pi代表MS-GRU所预测的故障发生的概率。
训练方式。本文采用反向传播算法(back propagation)来训练网络模型,主要包含激励传播、权重更新这两个环节。其中激励传播指正向传播过程:输入数据经由各个网络层逐层处理最终得到预测结果,然后根据预先定义的损失函数计算预测结果与实际情况之间的误差值。权重更新指反向传播过程:根据预测结果与实际情况之间的误差值,从输出层开始向着输入层逐层计算损失函数对各神经元权重的偏导数,并随之更新各神经元的权重,完成一次迭代。在本文的实验中,MS-GRU模型共经历了20万次迭代。
图2展示了MS-GRU 模型具体的工作流程。其中(a)展示的是训练阶段的工作流程,具体来讲,主干部分为正向传播时的工作流程,左侧分支为反向传播时的工作流程。(b)展示的是测试阶段的工作流程。
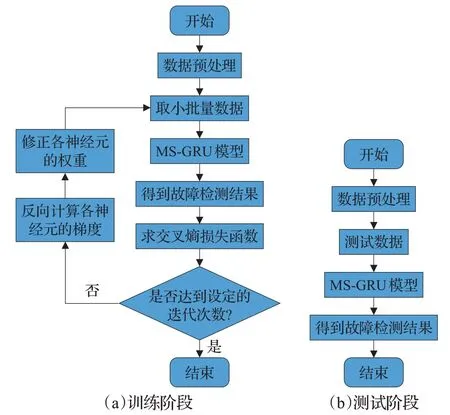
图2 MS-GRU模型工作流程图Fig.2 Flowchart of proposed MS-GRU model
3 实验
为了证明本文所提出的MS-GRU 模型的有效性和优越性,在仿真数据和真实数据上分别进行了广泛的实验,并和一系列现有的故障检测方法进行了对比。
3.1 仿真实验环境搭建
本文使用了一台PC机及七台虚拟机搭建了一个面向电网调控的微服务架构的应用系统。其中PC机主要负责面向电网调控的微服务故障检测系统的部署和运行,七台虚拟机主要负责微服务应用程序的运行。表1展示了PC机和虚拟机的具体配置信息。

表1 实验软硬件环境信息Table 1 Information on software and hadware used in experiments
3.2 评价指标和基准模型
本文采用精度(precision)、召回率(recall)和F1分数这三个量化指标来评估故障检测模型的效果,它们的定义如下:

其中,TP(ture positive)代表真阳性,即被故障检测模型正确分类的故障;FP(false positive)代表假阳性,即本来没有故障却被故障检测模型判定为有故障;FN(false negative)代表假阴性,即本来有故障却被故障检测模型判定为没有故障。除了上述出现的三种情况,还有一种情况为TN(true negative),代表真阴性,即被故障检测模型正确分类的无故障情况。
精度是准确性的度量,召回率是完全性的度量,而F1分数则将精度和召回率组合到了一个度量中,可以视作二者的调和均值。
本文将王子勇等人[10]提出的基于执行轨迹监测的故障检测模型(简称为轨迹监测模型)、徐康明[11]提出的基于故障树的故障检测模型(简称为故障树模型)、彭天舒[18]提出的基于特征规则的故障检测模型(简称为特征规则模型)作为基准模型,与本文所提出的MS-GRU 模型进行性能对比。
3.3 仿真实验结果
受文献[16-17,20-22]的启发,本文采用人为注入故障的方式来评估各个故障检测方法的表现。注入的故障主要分为四类,分别为应用程序故障(例如设置不当、配置出错等)、服务器故障(例如端口被占、Java Virtual Machine、线程池配置错误等)、数据库故障(例如运算溢出、并发事物死锁、违反完整性限制规则等)、操作系统故障(例如CPU、网络、内存、IO 等出现异常)。将各类故障单独注入到本文所搭建的微服务应用系统中,每类故障各注入25次,然后分别使用轨迹监测模型、故障树模型、特征规则模型以及MS-GRU 模型进行故障的检测。检测结果如表2所示,可以看到相较于其他的故障检测模型,本文提出的MS-GRU 模型在精度、召回率和F1分数这三个指标上都有着更好的表现。
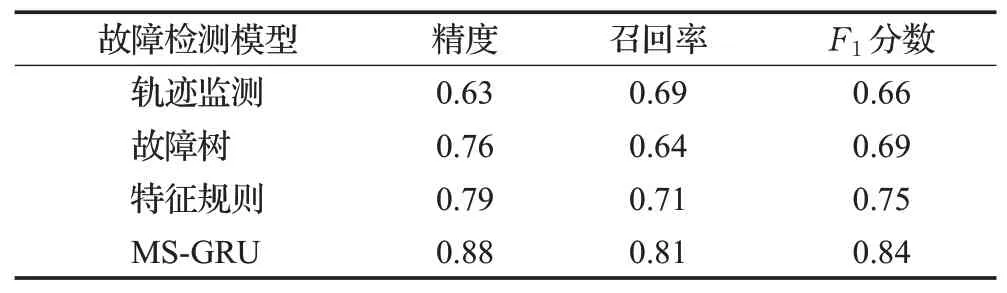
表2 各模型检测准确性对比Table 2 Comparison of different methods about accuracy
除了准确性之外,效率也是衡量一个故障检测模型性能的重要指标。图3 展示了各个方法的平均检测时间,可以看到MS-GRU模型具有最高的检测效率。

图3 各模型检测效率对比Fig.3 Comparison of different methods about efficiency
此外,为了评估本文提出的注意力机制的有效性,在三种不同的条件下进行了实验:(1)不使用注意力机制;(2)使用传统的注意力机制;(3)使用本文提出的注意力机制。实验结果如表3所示,可以看到与传统的注意力机制相比,本文提出的注意力机制能够以更小的时间成本获得更高的检测准确度。

表3 注意力机制的有效性评估Table 3 Effectiveness evaluation of attention mechanism
3.4 真实数据上的实验结果
前面的实验已经证明了本文所提出的MS-GRU 模型在仿真数据上的有效性,为了进一步测试MS-GRU在实际应用场景中的性能,将其部署到了某真实电网系统上。在部署之后两个月的时间里,MS-GRU模型共检测到了465 次故障(87%的准确率),避免了427 次故障(80%的准确率)。此外,借助于MS-GRU,开发人员对于故障发生的条件、模式、原因等都有了更为深入的理解和认识,在系统的设计上也做出了相应的改进,从而进一步避免了故障的发生。图4 展示了部署MS-GRU模型后,该电网系统在两个月内的故障发生情况,可以看到故障发生的次数呈现出明显的下降趋势,这再次验证了本文方法的有效性。

图4 MS-GRU模型两个月内的故障发生情况Fig.4 Fault occurrence of MS-GRU model in two months
4 结束语
本文针对微服务应用系统里的故障检测问题,引入了深度学习的方法,提出了一个基于GRU 的故障检测模型(MS-GRU)。本文方法的核心在于它能够从以往的应用数据中分析、学习到导致故障发生的模式信息,并将这些信息用于未来的故障诊断和预测中。为了评估MS-GRU模型的性能,在仿真系统和真实系统上进行了广泛的实验。实验结果表明与传统的故障检测方法相比,MS-GRU模型有着更高的效率和准确度。在未来的工作中,希望能够进一步精简网络模型,在不影响检测准确度的同时进一步提升检测效率,以实现实时检测,这样本文模型的实用性可以得到进一步的增强。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
汽车工程(2021年12期)2021-03-08
汽车维修与保养(2019年7期)2020-01-06
时代人物(2019年27期)2019-10-23
汽车维护与修理(2016年10期)2016-07-10
海峡科技与产业(2016年3期)2016-05-17
互联网天地(2016年1期)2016-05-04
