
双层残差语义分割网络及交通场景应用
2022-08-19 01:32谭睿俊赵志诚谢新林
智能系统学报 2022年4期
谭睿俊,赵志诚,谢新林
(太原科技大学 电子信息工程学院,山西 太原 030024)
近年来,随着深度学习的不断发展,计算机视觉领域取得显著的成就。越来越多的交通场景需要精确且高效的分割技术,实现交通场景的图像语义分割成为广大人员研究的问题之一。交通场景的图像语义分割,是对交通场景图像底层的像素进行相应类别的分类,为自动驾驶中的车辆控制、路径规划等问题提供一个高效的解决方法。常见的图像分割算法有。传统方法的图像分割和深度学习的图像语义分割。传统的图像分割算法主要有阈值分割法、边缘检测法、交互式图像分割法等。阈值分割法主要是根据图像中像素的颜色或灰度值对不同的分割目标来设定不同的阈值,根据不同的阈值对每个像素点进行分类[1]。在交通应用场景中,当图像像素的灰度值接近甚至重叠时,该方法很难得到准确的分割结果。
边缘检测法通过检测确定区域的边界,再根据边界把图像分割成不同的区域[2]。该分割算法具有一定的局限性,适合分割边缘的灰度值变化较大且噪声比较小的图像。交互式图像分割法,是一种基于图划分的方法,该算法针对大量复杂交通场景的图像分割存在一定的难度[3-4]。
将深度学习与神经网络引入交通场景的图像语义分割领域中成为发展的潮流,通用的深度神经网络主要有:文献[5]提出的AlexNet 网络;文献[6]提出的卷积神经网络模型(visual geometry group,VGG)网络;文献[7]提出的卷积网络模型(GoogLeNet)网络;由微软实验室提出的Resnet网络,该网络由一系列的残差网络堆叠而成,可以在增加其网络深度的同时有效地解决梯度消失与梯度爆炸等问题[8]。
文献[9] 利用卷积神经网络(convolutional neural network,CNN)对使用类别定位过滤器对图像粗略地分割,对小目标的分割精度很低。文献[10]提出了全卷积神经网络(fully convolutional Network,FCN),该网络利用卷积层代替CNN 的全连接层,进行上采样操作恢复输入图像的分辨率,并在PASCAL VOC2012[11]以及室内环境语义分割数据集NYUDv2[12]进行实验。实验结果发现FCN对于小目标边缘细节的分割模糊甚至识别错误。文献[13]提出的U-net 网络,通过跳跃连接融合两路径的特征信息,实现图像语义分割,但由于该网络未充分考虑各像素与像素之间的关联,缺乏语义特征的空间一致性。
基于此,本文提出一种基于双层残差网络的图像语义分割网络(dresnet network,DResnet)。首先利用双层残差网络对图像进行更加全面的特征提取,获得更多高分辨率的细节信息,并将输出的不同尺度的特征图进行融合作为上采样网络的输入;其次通过深层跳跃连接将高层信息与底层特征融合,充分利用底层的细节特征;最后将DResnet 网络应用到交通场景中,采用网络分支训练方法对该网络进行训练以及测试。根据交通数据集CamVid 和Cityscapes 的实验结果表明,本文提出的DResnet 网络对分割小目标物体具有一定的优势。
1 DResNet 语义分割网络
图像语义分割的任务主要包括准确地分类、精确地分割物体的边缘轮廓两方面,FCN 能够在一定程度上对图像各物体分类以及预测出物体的边缘轮廓,但对于边缘细节的分割,准确度很低,这是因为FCN 中的池化操作,在增大感受野的同时使图像损失了部分边缘细节信息。
为此,本文提出了DResnet,具体结构如图1所示。DResnet 由双层残差网络特征提取、跳跃特征融合网络组成。利用双层残差网络对训练集图像进行双层特征提取,并将每一层输出特征图进行相应位置融合,输出融合特征图X1~X5;在跳跃特征融合网络中,首先将最高层(第5 层)的融合特征图进行2 倍反卷积操作,从第4 层到第1 层,依次将融合特征图与其高一层的反卷积操作结果相加融合得到特征图W1~W4,然后对其进行2 倍反卷积操作,从而添加更多的跳跃连接结构,将高层信息与底层信息进行充分融合,最终将不同分辨率的特征图上采样恢复至原输入图像的相同尺寸。

图1 DResnet 网络结构Fig.1 DResnet network structure
1.1 双层残差网络
从提高网络特征提取能力的角度出发,本文提出了双层残差网络代替原FCN 网络的特征提取网络VGG,双层网络在提取的特征图融合了更多的边缘细节特征。还可以解决由神经网络层数加深而引起的梯度消失或者梯度爆炸问题[14-15]以及网络模型出现的退化问题[16]。
具体来说,双层残差特征提取网络如图2 所示。该网络包含两个相同的特征提取网络单元,每一单元均由5 层组成。整体网络的输入为RGB 三维数组,第1 层由大小为7×7,步长为2 的卷积核进行卷积操作,输出的特征图尺寸为原输入的1/2,卷积之后进行批量归一化处理、Relu 函数激活以及最大池化下采样操作,池化窗口大小为3×3,步长为2;第2 层到第4 层由不同数量的Block1 模块和Block2 模块构成,对应的Block 模块如图3 所示,本文的主特征提取网络(第2 层)由4 个Block1 构成;第3 层由1 个Block2 和3 个Block1 构成;第4 层由1 个Block 2 和5 个Block1 构成;第5 层由1 个Block 2 和2 个Block1 模块构成。
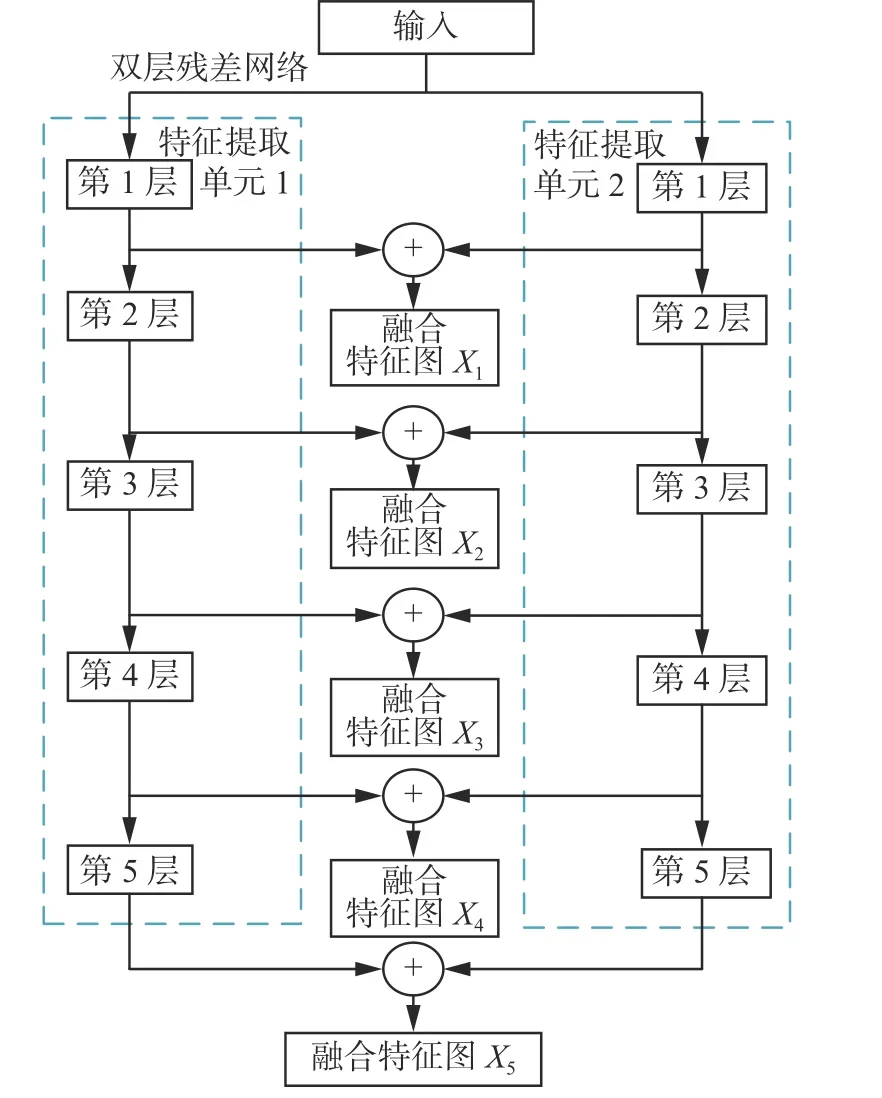
图2 双层残差特征提取网络Fig.2 Double residual feature extraction network

图3 Block 模块结构Fig.3 Block module structure
1.2 跳跃特征融合网络
考虑原FCN 网络模型存在池化操作,在增大感受野的同时,减小了特征图的分辨率,从而导致这些高层语义特征和之前的底层细节特征分辨率不一致,将底层特征与高层特征有效地融合,对提高网络的分割精度至关重要。
本文在原FCN 网络的基础上融合了更底层第1 层与第2 层的细节特征信息,具体结构如图1 所示。具体步骤:将第5 层输出的融合特征图X5进行2 倍反卷积操作,将其大小恢复至原图的1/16,与第4 层输出的融合特征图X4进行叠加得到特征图W1;再对特征图W1进行2 倍反卷积操作,将其大小恢复至原图的1/8,与第3 层输出的融合特征图X3进行叠加得到特征图W2;再对其进行2 倍反卷积操作,将其大小恢复原图的1/4,与第2 层输出的融合特征图X2进行叠加得到特征图W3;再进行2 倍反卷积操作,将图像恢复至原图的1/2,与第1 层输出的特征图融合X1进行叠加得到特征图W4;最后进行2 倍反卷积操作,得到与输入相同大小尺寸的图像。
利用跳跃特征融合,将高层的语义信息与底层的细节信息相结合,降低了由上采样操作所带来的部分细节特征损失,提高了交通场景下图像语义分割的精度。
1.3 网络分支训练
本文为了获得更高精度的语义分割结果,在下采样过程加入了双层残差网络,在上采样过程中加入了更多的卷积层,整体增加了网络的深度,为了使DResnet 网络得到充分的学习,更好地对图像中的细节信息的训练,本文提出了网络分支训练法,先对整个训练集的目标的大体轮廓位置进行训练,其次,在此基础上对所训练的目标进行细节方面的准确训练,可以提高网络的训练准确度。
2 实验设计与结果分析
2.1 实验环境
本文所有实验是基于深度学习Pytorch 开源框架进行的,实验环境的配置:操作系统为64bit-Ubuntu16.04,GPU 为GeForce RTX 2080 Ti,内存为64 GB,网络镜像为Pytorch 1.7.1,数据处理为Python 3.8。
2.2 实验数据集
本文采用数据集CamVid 和Cityscapes 验证本文DResnet 网络的有效性。
CamVid 是常用的交通场景数据集之一,本文使用其中的701 张的逐像素语义分割的图像数据集,其中训练集、测试集、验证集各421、168、112张,每张图像的分辨率为720 dpi×960 dpi。
Cityscapes 是一个侧重于城市环境理解的数据集,主要包含50 个城市不同场景、不同季节的5000 张精细标注的图像,其中训练集、测试集、验证集各2975、500、1525 张,每张图像的分辨率为1024 dpi×2048 dpi。
数据处理:1)由于该数据集类别过多且部分类别与其它类别的界定相对比较模糊,所以参考文献[17-21],在实验时选择CamVid 12 类和Cityscapes 20 类,CamVid 12 类主要包括背景、天空、建筑物、电线杆、道路、人行道、树、信号标志、栅栏、汽车、行人、骑自行车的人;Cityscapes 20 类主要包括背景、道路、人行道、建筑物、墙、栅栏、杆、交通灯、交通标志、植被、地形、天空、人、骑手、汽车、卡车、公共汽车、火车、摩托车、自行车等。2)由于该数据集的分辨率过高以及GPU 服务器显存有限,对2 组数据集分别进行中心裁剪至352 dpi×480 dpi、512 dpi×1024 dpi,再输入网络训练。
2.3 训练参数
为了得到交通场景分割较好结果的网络,进行了特征提取网络的替换、特征融合方法的相关实验,测试的对象为CamVid 12 类和Cityscapes 20 类。该实验在相同数据集、固定参数下进行实验,考虑到硬件原因,将两数据集中图片大小分别裁剪为352 dpi×480 dpi 和512 dpi×1024 dpi,采用反向传播和随机梯度下降法来进行训练,将训练批次大小设置为4,设置基础学习率为0.0001,经过10 次epoch 迭代后,对应的学习率减半。冲量设置为0.9,迭代次数为200 次。在设置完超参数之后,分别对不同的卷积神经网络进行训练并保存训练最好的权重,作为网络模型最终的参数,然后对测试集进行测试,得到不同网络的最终分割结果。
2.4 评价指标
在图像语义分割技术中,为了合理评价改进网络的分割精度,本文采用平均交并比、准确率以及平均像素准确率3 个评价指标。
1)平均交并比PMIOU(mean intersection over union,MIOU),作为图像语义分割最常用的评价指标,通过计算标签集合与预测结果集合的交集与并集之比,并计算所有类别的平均值,计算公式为

式中:k为图像中的类别总数(不包含背景);Pii为真实像素类别为i被预测为像素为i的像素数量;Pij为真实像素类别为i被预测为像素为j的像素数量。
2)平均像素准确率PMPA(mean pixel accuracy,MPA),首先对每个类计算正确预测的像素比值,其次对所有的类取平均,计算公式为

3)平均准确率PACC(accuracy,ACC),所有分割正确的像素点与总像素点的比值,计算公式为
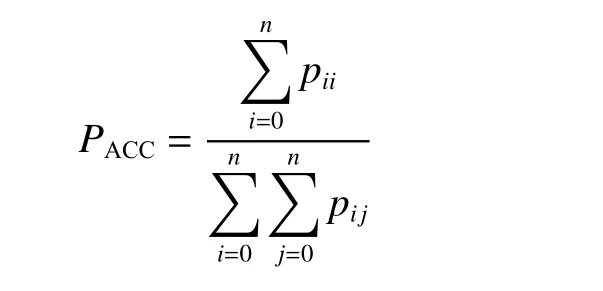
3 实验结果分析
3.1 CamVid 实验结果
为了验证本文网络的可行性,本文在Cam-Vid 数据集上得到原FCN 网络、不同深度Resnet 网络、不同深度DResnet 网络的测试分割结果。分别使用相同的数据划分对FCN、Resnet-34、DResnet-34 不同的特征提取网络进行网络分支训练,得到表1 所示的结果,由表1 可以看出,DResnet 网络可以得到更高分割精度的结果。

表1 不同网络在CamVid 测试集结果对比 Table 1 Comparison of the results of different networks in the CamVid test set %
原FCN 网络、不同深度DResnet 网络的测试分割结果,具体如表2 所示。可以看出,随着DResnet 网络的层数不断加深,网络的3 项测试评价指标的测试精度逐渐增加,但当网络达到50 层时,测试的PMIOU精度出现下降,这是因为在训练的过程中出现了过拟合,考虑到网络本身的参数问题、训练集的数目问题以及测试精度问题,本文通过实验分析,选择DResnet-34 网络作为主网络的特征提取网络。

表2 不同深度DResnet 在CamVid 测试集结果对比 Table 2 Comparison of the results of different depths of DResnet in the CamVid test set %
跳跃特征融合网络实验。为选取合适的上采样网络,在DResnet-34 网络作为特征提取网络的基础上,对融合不同尺度特征图网络DResnet-2S 到DResnet-32S 进行训练与测试,得到测试结果如表3 所示。

表3 不同跳跃特征融合在CamVid 测试集结果对比Table 3 Comparison of the results of different jump features fusion in the CamVid test set %
由表3 可以看出,仅仅融合Layer5 层的特征图,DResnet-32S 网络的平均交并比PMIOU仅仅为56.74%,测试的PACC为60.00%,通过不断地融合不同Layer 层的特征图,测试精度出现了上升,融合所有尺度的特征图,DResnet-2S 网络的测试准确度PACC高达61.93%,平均交并比PMIOU达到59.44%。
从表4 中可以看出,不同深度的DResnet 网络对电线杆(Pole)、信号标志(SignSymbol)、栅栏(Fence)、行人(Pedestrian)、骑自行车的人(Bicyclist)等小目标的物体的分割精度提升较大,整体的PMIOU由49.72% 提升到59.44%,通过增加DResnet 网络的深度,可以改善部分小目标的分割精度。

表4 不同网络在CamVid 测试集的各类别精度Table 4 Accuracy of each category of different networks in the CamVid test set %
3.2 Cityscapes 实验结果
为了进一步验证DResnet 网络的可行性,在另一交通数据集Cityscapes 上进行实验,但考虑到该数据集图像较多以及显存硬件原因,本文选取DResnet34 网络作为主特征提取网络,分别对FCN、不同特征融合的DResnet 网络进行网络分支训练以及测试,测试结果见表5。

表5 不同跳跃特征融合在Cityscapes测试集结果对比Table 5 Comparison of the results of different jumpfeatures fusion in the Cityscapes test set %
从表5 中可以看出,DResnet-32S 网络仅融合特征图X5,平均交并比PMIOU仅达到47.16%,测试准确度PACC达到41.29%,DResnet-2S 网络融合所有尺度的特征图,再对其进行上采样操作,测试准确度PACC高达42.33%,平均交并比PMIOU达到47.77%。因此再次验证融合所有尺度特征图的融合方法可以提高整体的测试分割精度。
在Cityscapes 测试集上部分预测结果如图4所示,第1 列为Cityscapes 测试集的RGB 图像,第2 列为对应的标签,第3 列为FCN-8s 的测试结果,第4 列为DResnet-18 的测试结果,第5 列为DResnet-34 的测试结果。对比FCN-8s 与DResnet网络的结果图,可以明显地看出DResnet-34 网络分割后的栅栏、杆、交通标志、人等小物体边缘更加精细,分割边界更加规整。
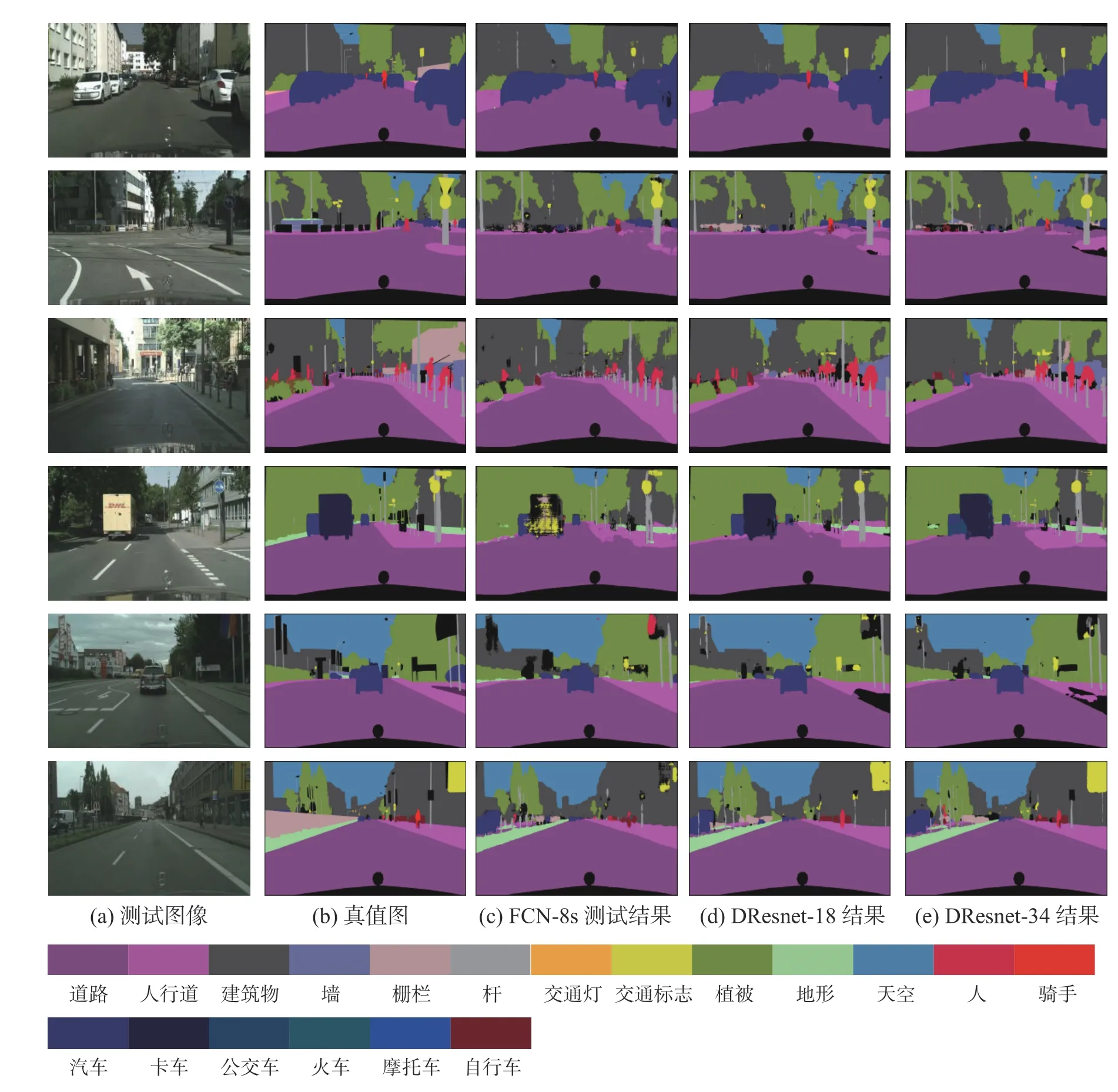
图4 Cityscapes 测试集部分图像预测结果Fig.4 Cityscapes test set partial image prediction results
4 结束语
本文提出了一种基于双层残差网络特征提取、跳跃特征融合的图像语义分割网络(DResnet)。它能够解决由特征提取网络带来的分辨率减小以及空间细节信息损失问题。DResnet 网络构建双层残差特征提取网络与跳跃特征融合网络,双层残差网络对标准训练集的图像同时进行两次特征提取操作,以获得更全面的图像细节特征信息;跳跃特征融合网络在第1 层与第2 层开始融合跳跃连接,更好地融合图像的背景信息与语义信息,使网络获得更高的特征提取能力与识别精度。通过交通场景数据集CamVid 和Cityscapes 的实验结果表明,本文的DResnet 网络模型在CamVid 12 类上的评价指标PMIOU、PMPA、PACC分别提高了9.72%、3.63%、7.68%,在Cityscapes 20 类上的评价指标PMIOU、PMPA、PACC分别提高了3.42%、1.64%、3.48%。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
长江学术(2016年4期)2016-03-11
