
可拓数据挖掘在学生成绩分析中的应用研究
2022-08-19 01:32:28刘大莲田英杰
智能系统学报 2022年4期
刘大莲,田英杰
(1.北京联合大学 数理部,北京 100101;2.北京联合大学 数理与交叉科学研究院,北京 100101;3.中国科学院虚拟经济与数据科学研究中心,北京 100190)
当代社会,随着信息技术的突飞猛进,高等学校的教育教学改革的深入化也受到了深刻的影响。尤其处于大数据时代,数据挖掘的各种方法被应用到教育行业[1-6],为寻找更好的教育教学方法提供了新思路。学生成绩在高等学校里不但是衡量学校人才培养水平的一个重要指标,同时也是教育大数据中的一个重要内容。由于学生成绩具有数据类型相对统一,数据量较大,相对容易获取等特点,因此依据恰当的数据挖掘技术,对学生成绩进行不同角度的深入挖掘和分析,从而得到指导教学的新方法或新理论的研究成为高等学校教学改革的一个研究热点。丁智斌等[7]利用决策树中的ID3 算法对学生成绩进行分析,从而得出了影响学生成绩的内部原因及一些其他相关结论。喻铁朔等[8]是基于支持向量机(support vector machine,SVM)等4 种数据挖掘的方法对学生成绩进行预测,从不同角度对4 种模型进行对比,得出不同模型适用于不同课程的结论,对高校学生课程成绩预测。钟文精等[9]基于k-means聚类算法,对学生成绩进行聚类分析,为进行深入的教学改革和设计提供数据依据。本文依据可拓数据挖掘中的几种重要算法及皮尔逊相关系数,对北京某高校经管类学生的数学课程相关成绩进行多角度深入分析,从而得到一些和教学相关的重要结论,为改进教学方法,提高教学质量给出合理化建议。
1 基础知识与算法
1.1 可拓支持向量机
可拓学是由广东工业大学蔡文研究员创立的一门原创学科。在众多专家学者的不懈努力下,历经30 余年的潜心研究,建立了可拓论体系和可拓创新方法体系[10-18]。可拓数据挖掘[19-20]是将可拓学的理论和方法与挖掘数据的方法技术相结合的一门新技术,可拓支持向量机[21]就是其中一种经典机器学习算法与可拓理论深入结合而产生的新算法。与标准的支持向量分类机不同,可拓支持向量机是解决可拓分类问题的,其在进行标准分类问题预测的同时,更注重于找到那些通过变化分量(特征)的值而转换类别的样本,这样的样本称为可拓样本,而相应的变量称为可拓变量。
算法可拓支持向量分类机算法(ESVM)
1) 给定训练集:其 中xi∈Rn,yi∈Y={1,−1},i=1,2,···,lxkj。给定可拓样本 的可拓变量 的可拓区间选择合适的惩罚参数C>0;
2)构造并求解最优化问题:

5) 对于输入xk,首先用决策函数f(xk)得到其对应的预测类别yk,然后用其可拓变量对应的可拓区间分别代替 [xk]j,这样对 |E|个可拓变量,就得到 2|E|个 不同的组合值。相应的,基于xk得到了 2|E|个新的输入,分别用决策函数来判断,若有一个被判断为 −yk,则认为该输入是可变换的。
1.2 基于可拓距的k-means 聚类算法
可拓k-means[22]基于可拓学中点x与区间X0=

3)遍历排序好的可拓距,将其中首个大于样本间可拓平均左侧距的可拓距对应中心点坐标作为第一个初始聚类中心;
4)计算排好序可拓距中下一个值对应中心点坐标并依次计算出其与已确定的初始聚类中心的可拓距,将其与样本平均可拓右测距进行比较,若其均大于,则该中心点坐标作为下一个初始聚类中心;否则重新执行步骤4;
5)如果遍历一次后,初始聚类中心未达到K,则按式(1)计算出缩小因子η,动态缩小样本平均可拓右侧距,重新回到步骤3;

式中:k′为每次遍历后所获得的初始聚类中心个数;K为指定聚类中心数
6)若聚类中心数达到K时,则完成初始聚类中心的选取。
1.3 皮尔逊(Pearson)相关系数
Pearson 相关系数[23]用于分析定量数据,当数据满足正态分布时可用Pearson 相关系数查看变量间相关性。其公式为
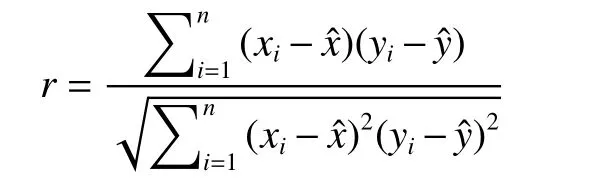
式中:相关系数r的取值范围为 −1 ≤r≤1 。r>0为正相关,r<0 为负相关,0 <|r| <1表示相关程度。
2 高校学生成绩特点分析
2.1 数据描述
收集了北京联合大学2018—2019 学年包括旅游学院、管理学院和商务学院3 个学院共计929 名学生的数据,包括经管类概率论与数理统计(I)课程的平时作业、期中和期末考试成绩等。根据期末试卷的5 道客观题(记为kg_1~kg_5)和10 道主观题(记为zg_6~zg15)共15 道题目,总结出15 个主要的知识点。为便于分析,我们把每个学生的知识点掌握描述成一个15 维向量,向量的每个分量即为该生在某个知识点上的掌握程度。而知识点的掌握程度则根据学生的平时作业成绩、期中和期末试卷上考核相应知识点的得分,综合计算得到。最后根据每个学生期末试卷的考试总成绩的及格与否把学生分成正负两类,及格为正类,不及格为负类。这样把所有学生组成一个大小为929 的两类分类问题的数据集1,记为S1。
收集了我北京联合大学2018—2019 学年包括旅游学院、管理学院和商务学院3 个学院共计841 名学生的数据,包括微积分(II)课程的平时作业、期中和期末考试成绩等。根据期末试卷的6 道客观题(记为kg_1~kg_6)和12 道主观题(记为zg_7~zg_18)共18 道题目,总结出18 个主要的知识点。同上述S1数据处理类似,我们把每个学生的知识点掌握描述成一个18 维向量,根据每个学生期末试卷的考试总成绩的及格与否把学生分成正负两类。这样把所有学生组成一个大小为841 的两类分类问题的数据集2,记为S2。
下面将基于S1和S2进行学生成绩特点的挖掘分析。
2.2 基于可拓SVM 的试卷题目影响力分析
基于成绩数据集1,探索哪些知识点是影响学生及格与否的主要因素,从而检测试卷是否满足出题意愿;进一步,对每个学生,可以给出决定其及格与否的某个或某几个具体题目,以便学生以后有所侧重学习。
首先,对建立的训练集S1={(x1,y1),(x2,y2),···,(xl,yl)}∈(Rn×Y)l,其中xi∈R15,yi∈Y={1,−1},i=1,2,···,929,利用5-折交叉验证方法,选取最优的参数C和径向基核函数参数,并用最优参数对整个训练集进行训练,得到最终的决策函数。利用此决策函数进行规则抽取[24],可以得到基本的分类规则,我们这里将分类规则按照决策树的形式表示如图1 所示。
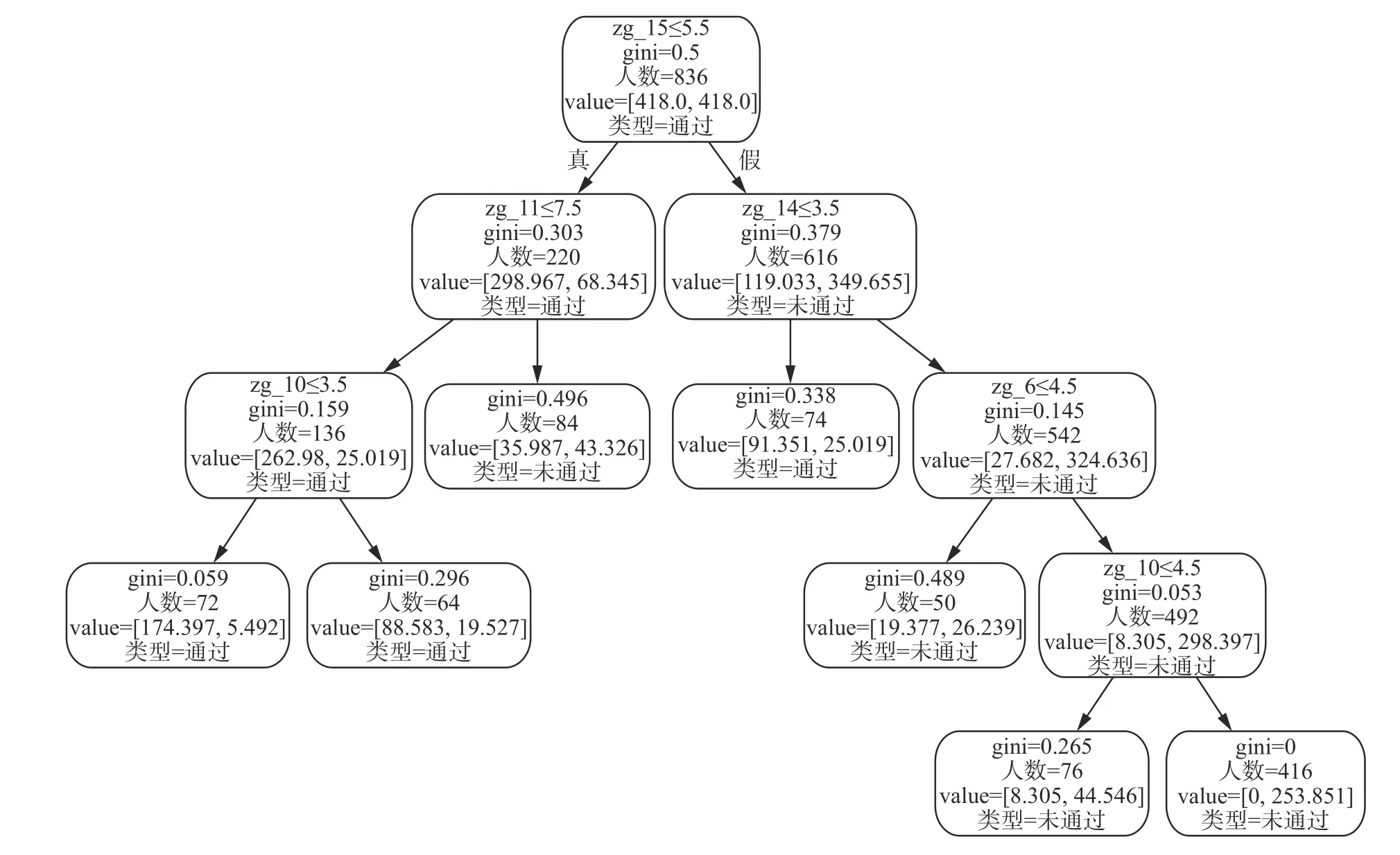
图1 分类规则图Fig.1 Classification rule diagram
由图1 可以看出,据此规则得到的节点数为13,叶子节点数为 7,树的最大深度为 5,最基本的区分规则是选择那些对学生是否及格判断起主要作用的题型及题号。从树中可以看出在众多规则中zg_15,zg_14,zg_11,zg_6 都被作为分枝的因素。从根节点带有特征取值范围来看,根节点的两个分支分别代表两类学生成绩分布,一类是zg_15 的得分大于5.5 分,另一类是zg_15 得分小于5.5 分。
从根节点的左分支中关于zg_11 得分是否大于7.5 的分支对比观察中可以发现,即便学生对zg_11 得分小于8.5,学生的及格率依然很高,由此可见,对该分支的进一步挖掘,可以找出更加具备辨识度的特征以及取值范围。
从根节点的右分支出发,我们可以发现,第个二分支节点判断的特征为zg_14 的得分是否小于等于3.5。从选择人数上看,zg_14 的得分大于3.5 的学生比相应得分小于3.5 的人数高出468人,但是在zg_14 得分超过3.5 的同学不及格的概率更高。由此可见,在众多主观题中,zg_15 对学生的成绩及格影响更高,而zg_14 对是否成绩及格的概率呈现出较低的相关性,所以导致在14 号主观题得分高的同学在最后的及格率分析中影响度不高。
将上述分析进一步总结到规则表1,从中可以看出,影响学生对概率统计及格率的主要因素有以下3 点:

表1 S1 及格率规则Table 1 Pass rate rules of S1
1)第15 号主观题:从5 条分支规则中可以发现,将第15 号主观题得分作为根节点分支范围的合计人数最多,由此可以推断第15 号主观题是影响学生对于概率统计课程及格率的主要因素。
2)第14 号主观题:在所有的规则中同样也对第14 号主观题的得分范围进行了划分,基于前面的第15 题的分支背景,第14 号主观题的取值范围也有了相应的调整。
3)第11 号主观题:在规则表中,存在前馈规则一致的两条规则。第11 号主观题的得分是否超过7.5 分是区分他们的关键。
另外,从结果上看,对规则主要的考虑因素也集中在主观题型中,而客观题影响度较低。为了进一步探究一张试卷中各个题型之间的重要性,我们对概率统计试卷上的题型进行了影响度可视化操作,可视化结果如图2 所示。
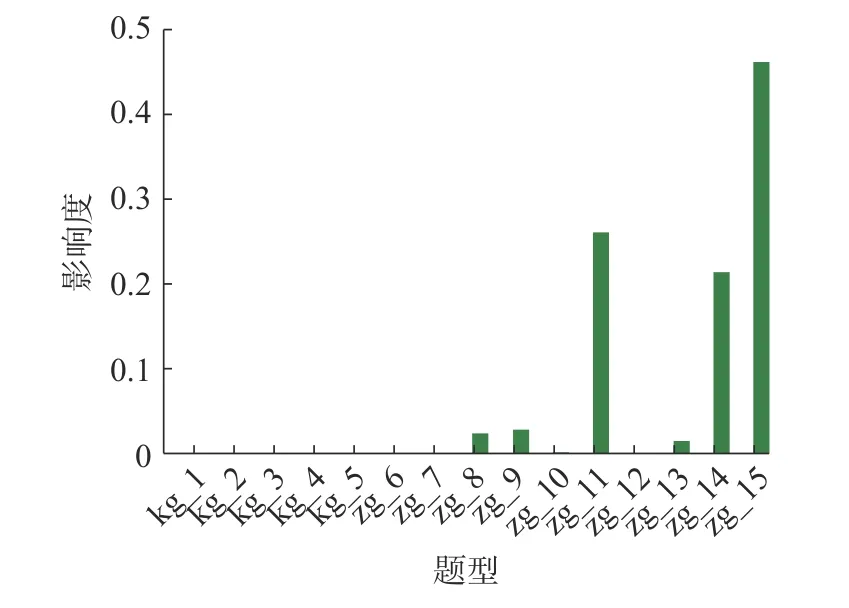
图2 各题影响度可视化图Fig.2 Impact of each question
主观题第15 题zg_15 作为影响学生概率统计及格的重要因素,该现象在管理学院、旅游学院尤为明显。主要原因在于zg_15 得分难度低,导致该题得高分的同学较多;对于其他的主观题,例如zg_14 和zg_11 也有类似的趋势。而反观客观题的影响比例,可以看到影响力几乎为0,原因在于客观题题型分值较小,且相对得分容易获得,所以导致客观题所占的影响力整体较低。结合上述表1 的分析研究,绝大多数及格学生的提分关键在于第11、14 和15 号主观题。
在上面已得到普遍规律的前提下,进一步分析影响每个学生是否及格的关键知识点:
因每个题目学生得分都有不同,所以每个题目对应的变量都是可拓变量。首先定义所有题目j(j=1,2,···,15) 的可拓区间,即 [aj,bj]。这里将每个题目不得分和得最高分设为可拓区间上下界,即aj=0,bj为该题目的得分。针对每个学生xk的每个题目对应的变量,用其可拓变量对应的可拓区间分别代替 [xk]j和 [yk]j,这样对 |E|=15个可拓变量,就得到 215个不同的组合值。相应的,基于xk,利用决策函数得到了 215新的输入,分别用决策函数来判断,若有一个被判断为 −yk,则认为该输入是可变换的。
以学生t1为例,我们得到kg_4,zg_13 是影响其及格与否的2 个关键题目,即如果学生t1在kg_4和zg_13 对应的知识点掌握程度从最低变为最高的情况下,其将由不及格而变成及格;而对于学生t2,同理可知学生对kg_2,zg_13,zg_15 对应的知识点掌握程度是影响其及格与否的关键。
2.3 基于可拓距的k-means 聚类算法成绩特定分析
基于成绩数据集S2,我们拟分析学生成绩分布的整个规律.首先建立数据集S2={(x1,y1),(x2,y2),···,(xl,yl)},其 中xi∈R18,yi∈Y={1,−1},i=1,2,···,841。为了对数据有整体的了解和把握,以便于进一步从不同角度进行分析。首先,我们对数据利用t-SNE 方法进行降维和可视化展示,图3(a)是微积分(II)课程的全体成绩分布图。可以发现,图中的成绩数据分布较为紧密,紧密的样本分布为数据聚类添加了难度。同时,为了验证“同一学院的学生,该门课程的总体水平较为接近”这一设想,我们按照学院划分,将管理学院、旅游学院和商务学院的学生成绩作为不同类别的数据,利用t-SNE 方法进行降维和可视化展示,如图3(b) 所示。很明显看出,结果和我们预期吻合。(可视化图均为示意图,坐标无实际意义。)

图3 整体数据可视化图Fig.3 Visualization of the overall data
对于具有上述特征的数据,采用上述1.2 节中所阐述的基于可拓距的k-means 聚类算法,把k分别取为3、4、5,并利用t-SNE 方法进行降维和可视化展示得到如下结果(如图4),可以看出k=3 时效果比较好。

图4 k-means 可视化图Fig.4 Visualization of k-means
进一步,我们对聚类的3 类进行分析,对每一类中所有点的每个分量求均值,探索每类的特点,得到表2。可以看出类别2 与1,3 在各个题目对应的知识点掌握程度都有明显区别,也就是类别2 的学生,几乎对所有知识点掌握都较差,这些学生需要全面补习;而类别1 和3 之间只在某些知识点上取值差别稍大,比如zg_18。

表2 k=3 聚类分析表Table 2 k=3 Cluster analysis table
2.4 基于Pearson 相关系数的试卷题目相关性分析
基于数据集S1,利用Pearson 相关系数进行相关性分析,结果如图5 所示,其中颜色越深代表着相关性越大。可以发现:正对角线代表着当前特征与特征自身的相关性计算值,正对角线上的值均为1,颜色最深。其余部分代表着当前特征与其他特征的相关性计算,颜色的深浅代表着相关性的强弱。具体而言:客观题kg_1,kg_2,kg_3,kg_4,kg_5 之间相关性热力图颜色为浅绿色,说明它们之间相关性较弱,但是总体保持着正相关的关系。据此可以推断,客观题一道题的得分情况对另外一题的得分情况影响较低,或者说题目本身考查的知识点不相关。而主观题之间的相关性则更加复杂。根据主观题之间的相关性热力图分布,它们之间存在负相关和正相关两种相关关系。相关性的数值越接近1 或-1,说明两组数据之间正向或反向线性关联越强。例如,zg_6 与zg_7、zg_7 与zg_8,zg_8 与zg_9 之间的相关性热力图颜色为黄色,说明它们之间的相关性为负相关。与之相反的情况为:zg_7 与zg_9、zg_11 与zg_12 之间的相关性热力图颜色为蓝色,说明具有很强的正相关性,两个特征的相关密切程度比较高。此时就要引起注意,试卷中zg_7 与zg_9、zg_11 与zg_12 之间是否考察知识点重合,还是题目难易程度相近引起的高度相关。如果出现命题知识点重合,是否符合我们考核的目的,从而对考试后试卷命题合理性分析给出提示。
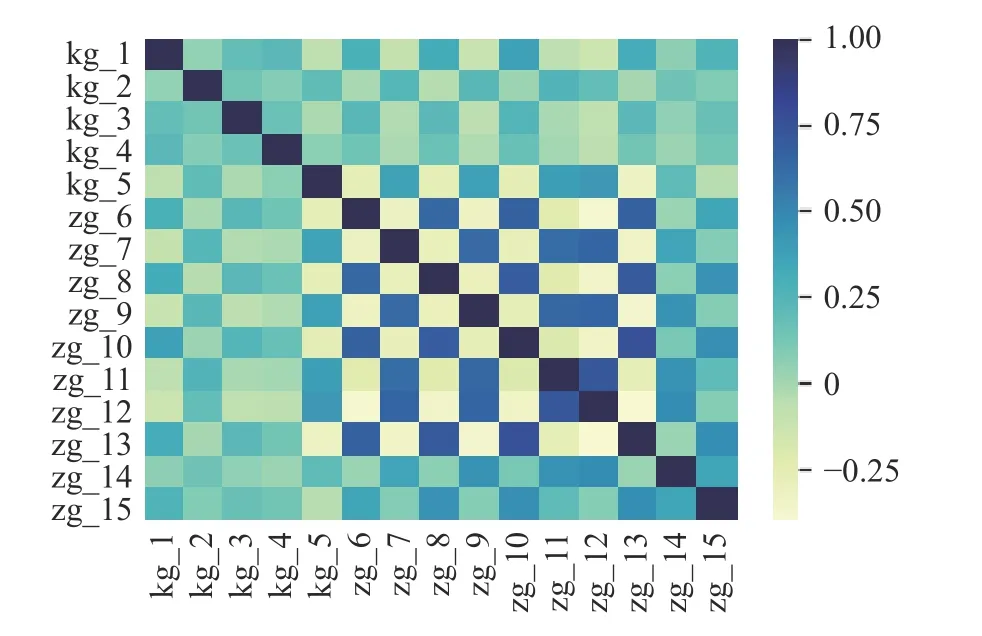
图5 题目相关性热力图Fig.5 Correlation map
3 结束语
本文主要基于可拓数据挖掘的几种重要方法及皮尔逊相关系数,对高校学生成绩利用不同模型,从不同角度进行分析,从而分析影响学生成绩的主要题目,探索学生对知识点的掌握程度。进一步,对每个学生,可以给出决定其及格与否的某个或某几个具体知识点,以便学生以后有所侧重学习。试卷中各题目相关性强弱分析的结论,也对课程考核等方面给出合理化指导和建议。将不断发展的、前沿的科学技术、科研方法应用于不断深化改革的教育教学中,同时也对长期沉睡的庞大的学生成绩数据加以充分利用,教学促进科研,科研反哺教学,起到了示范作用。采用的相关算法是我们精心选取的算法,针对相关成绩数据分析有一定的优势。将来我们可以进一步深入研究,探讨如何将解决矛盾问题的可拓学和机器学习的相关算法深度融合,起到如虎添翼的作用。深究如何进一步将科研的方法应用到教育大数据中,从而对推进教学改革,进一步提高高校教学质量做出贡献。同时也希望上述分析能起到抛砖引玉的作用。
猜你喜欢
考试与招生(2022年10期)2022-11-17 08:59:04
井冈教育(2022年2期)2022-10-14 03:11:28
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
中学生数理化(高中版.高考数学)(2022年6期)2022-07-02 03:36:26
云南化工(2021年8期)2021-12-21 06:37:54
甘肃教育(2021年10期)2021-11-02 06:14:28
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
