
面向智慧教育的自适应学习路径生成方法探究
2022-08-18 03:51赵润哲芦培龙张亚洲姬莉霞
郑州大学学报(理学版) 2022年6期
张 晗, 赵润哲, 芦培龙, 张亚洲, 姬莉霞
(1.郑州大学 网络空间安全学院 河南 郑州 450002; 2.郑州市区块链与 数据智能重点实验室 河南 郑州 450002)
0 引言
智慧教育的核心之一是自适应学习[1]。自适应学习是根据学习者之间的差异性特征采用智能化手段为学习者创建自适应的教学环境,也是我国教育未来发展的主要方向[2]。作为自适应学习的核心功能,为不同的学习者在不同的场景下选择合适的学习对象构成不同的学习路径,是一项复杂的任务,吸引了诸多研究者对这一主题进行研究。然而,在已有的研究中,多为关注场景,即学习目标对用户的影响,缺乏对学习者认知能力进行动态感知的考虑。研究[3-5]表明,认知能力是学习者选择不同学习路径的首要参考目标。
此外,有研究表明,网络学习者更喜欢利用时间碎片来学习知识[6]。这就要求推荐的学习路径最好由多个细粒度的知识单元组成。因此,知识单元的组织也会直接影响学习路径的推荐,而当前关于学习路径生成的研究只有少部分考虑了学习者的认知特征与知识单元之间的内在的依赖性,但忽略了其他关键因素,如细粒度的知识单元组织和有限的时间。
为解决上述问题,本文将知识图谱引入自适应学习路径生成方法,构建更细粒度的知识单元与学习者认知能力相关联的知识图谱模型,并在此基础上完成自适应学习路径生成算法。另外,随着深度学习模型在各领域取得良好效果,自适应学习路径生成领域也开始采用神经网络模型为学习者生成合适的学习路径,例如LSTM[7]、RNN[8]等,但这类方法需要通过大量训练才能达到较好的性能,并难以从错误预测中学习总结,导致出现重复构建非最优路径等问题。鉴于深度强化学习在寻找最优路径问题上的良好表现[9-10],本文提出一种结合了知识图谱与深度强化学习的自适应学习路径生成方法,该方法不需要大量的训练数据,而是基于环境的反馈而行动,通过不断与环境的交互、试错,最终完成特定目的。本文贡献如下。
1) 提出一种知识图谱与深度强化学习相结合的自适应学习路径生成方法,解决其他基于深度学习模型的路径生成方法中需要大量标注数据,并且难以从错误预测中总结经验等问题。
2) 提出一种将细粒度知识元与学生认知能力相结合的知识图谱模型,解决学习者的认知能力与知识单元之间的依赖问题,并考虑网上学习者的学习特征,通过将知识点划分成更细粒度的知识元,以满足网络学习者利用时间碎片学习的需求。
3) 提出一个动态强化学习的最优路径生成方法,该方法通过将网络模型DQN(deep Q network)[11]和双DQN(double DQN,DDQN)[12]加权整合到强化学习模型中,解决其在构建最优化路径中的模型估计误差问题,提高生成最优学习路径的精度。
1 相关工作
近年来,随着知识图谱技术的发展,基于知识图谱的模型开始应用在自适应学习路径生成领域[13-15]。Wan等[16]提出了一种面向学习者的通过相关知识生成学习路径的推荐方法,其中节点表示知识单元,知识单元之间的关系则由节点之间的连接表示。Ouf等[17]利用知识图和SWRL提出了e-learning智能系统框架。Shmelev 等[18]提出了一种结合遗传方法和知识图对学习对象进行排序的方法。Chu等[19]建立了一个基于概念图的e-learning系统,可以根据概念图中的关系生成学习路径。Zhu等[20]考虑到学习者在不同场景下需要不同的学习路径,提出了一种需要指定起始和结束节点的学习路径生成方法。Shi等[21]提出了一种基于多维知识图框架的学习路径推荐模型。
以上研究选择将学习对象视为节点,将关系视为路径。然而,这些基于知识图的方法并没有充分利用知识图谱的信息,没有将知识与学习者认知能力相结合。不同的学习者对于同一个学习对象可能需要不同的学习路径,一个好的学习路径推荐模型应生成满足不同认知能力学生的学习路径。因此,本文将构建一个将知识单元与学习认知能力密切相关的知识图谱,并提出一种动态深度强化学习模型,在训练数据较少的情况下,快速生成最优路径。
2 自适应学习路径生成方法
首先构建细粒度知识元与学生认知能力相结合的知识图谱模型,然后通过学生当前知识掌握情况生成新的目标子图,接着通过拓扑排序获取当前节点到目标节点的所有路径,组成路径状态集合,最后通过强化学习方法来获取最佳路径。
2.1 领域知识图谱模型
与传统的以三元组为基本组成单元的知识图谱不同,本文所构建的知识图谱目标是将细粒度的知识元与学生的认知能力结合起来。而目前,考查学生针对该知识元认知能力最简单有效的办法是通过对包含该知识元的习题的掌握情况进行了解,因此可将该知识库模型定义为一个六元组,表示为
G=(K1,relation,K2,QS,CA,chapter),
其中:K1、K2表示课程中细粒度的知识元;relation表示K1和K2之间的关系;QS表示针对知识元K1的问题集合;CA表示掌握K1的认知能力;chapter表示K1所属的章节单元。接下来,对该模型中出现的概念进行逐一定义。
定义1细粒度知识元 学科领域中不可再分割且能完整表达知识的最小独立知识单元,如数据结构课程中的“单链表”就是一个细粒度的知识元。
定义2relation表示知识点之间的关系,对其中的关系定义:依赖(rely)表示某个知识点依赖于另一个知识点,两个知识点有必要的前后顺序关系,或者某个知识点的存在必须依赖于另一个知识点的存在;被依赖(b-rely)表示某个知识点依赖于另一个知识点,两个知识点有必要的前后顺序关系;同义(syno)表示两个知识点名称不同但指代同一个内容;反义(auto)表示两个知识点意义相反;近义(simi)表示两个知识点有相似的内容。
定义3QS针对知识元K1的习题集合,该习题集合以选择、填空以及判断等客观题为主,并设置约束条件,即在进行习题扩充时,只把包含知识点K1以及K1之前的知识点的习题填充进QS。
定义4CA评价学习者掌握知识点K1的能力,是一个整数类型。如果学习者通过QS中的习题得到的分数>CA,则认为学习者已经掌握了该知识点,否则表示没有。
定义5chapter知识点K1所属的章节,表示为浮点数类型,例如3.2表示的是知识点K1处于本课程中的第三章第二小节。这里chapter可用于描述知识点之间非必要的前后关系。例如,单链表的chapter值为3.3,而栈的chapter值为3.2时,这两个知识点之间没有必然存在的前后关系,只是在章节安排上认为栈应该在3.3之前掌握。
关于该知识图谱构建过程中知识点、章节值和关系的抽取,可采取目前在相关领域表现优异的预训练语言模型[22-24],而相关习题的填充则由于受到约束条件以及存储条件影响,本文将习题存储在本地普通数据库中,而在知识图谱中存储的是这些习题在普通数据库里存储的地址。最后,再进行学习能力即CA值的填充时,本文拟采用Gridsearch[24]方法训练出具体的阈值。
2.2 基于深度强化学习的自适应学习路径生成模型
在领域知识图谱构建完成之后,将结合学习者的认知能力动态地为学习者生成最佳学习路径。该问题表述如下:有领域知识图谱G,学生认知能力子图G′,此时可以得出学习者当前认知能力下的学习目标子图T′,T′=G-G′。另外,在生成T′时,只考虑其中的rely关系、syno关系和simi关系,对于不存在这些关系的其他节点,通过其chapter属性,认定为同父知识点。这样可以保证生成的子图T′中知识点之间要么没有关系,要么知识点之间的关系方向性是有序的。
接着,对T′进行拓扑排序可以得出路径集合R={r1,r2,r3,…},从中找出最优路径ri。
鉴于深度强化学习在寻找最优路径问题上的表现及其存在的问题,本文提出一种动态强化学习优化方法来指导最优路径选择。模型结构如图1所示。

图1 动态深度强化学习模型图Figure 1 Dynamic deep reinforcement learning model diagram
首先,对路径进行向量化处理,完成初始化,这个过程不需要添加额外信息。之后,把路径向量输入到评估网络evel_net,初始化路径向量通过与环境交互,根据探索策略选择连接的动作作用到环境,并得到新的状态。重复这个过程,得到最优路径。
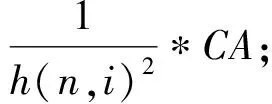
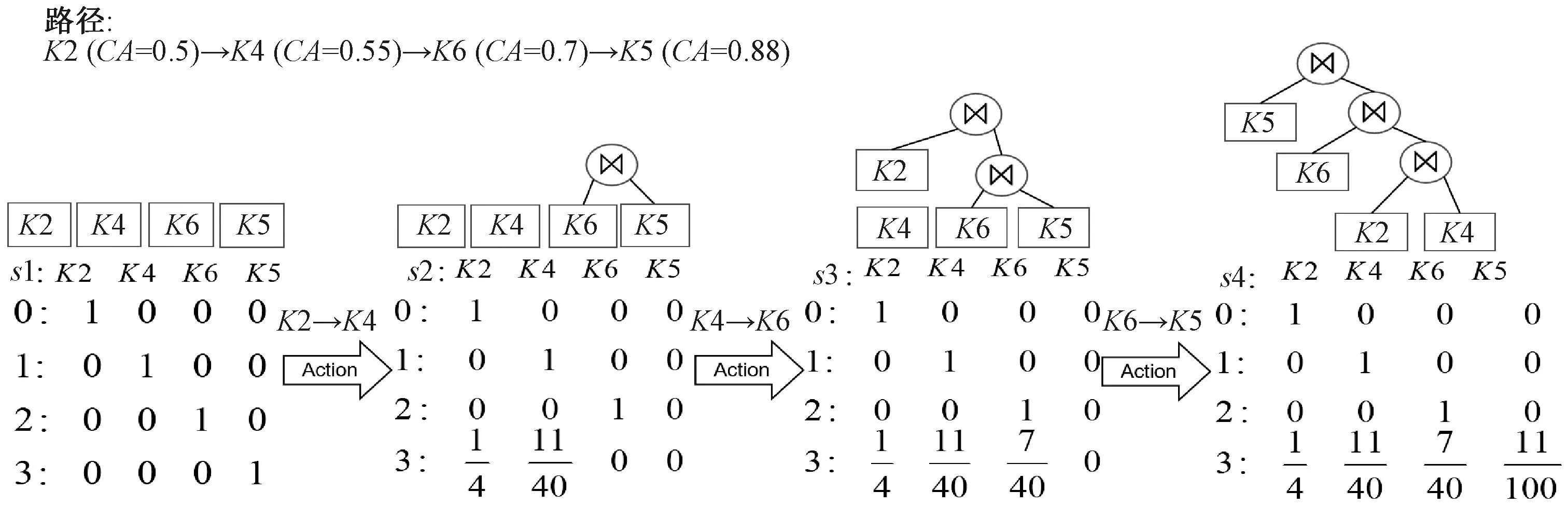
图2 路径向量化表示图Figure 2 Path vectorization diagram
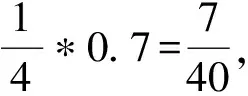
2.2.2模型架构 在标准的DQN网络中,选择和评价动作都是基于相同的参数,使Q值产生过估计,这就造成DQN网络具有过高估计动作值的缺陷[11]。为解决上述问题,Haselt等提出了DDQN[12],大幅度缓解了过拟合问题,但同时也带来了过低估计动作值的新问题,进而造成性能的降低。因此,本文把加权的双估计器的思想应用到DDQN上,构建一种动态强化学习优化方法来选择优化路径,该方法在保留了DQN和DDQN的基础上,通过平衡两者的权重,减少目标估计值的误差,实现更精准的估计Q值。
本文仍然使用DDQN网络结构,包括评估网络和目标网络两部分,不需要添加额外网络。其中,评估网络的目的是挖掘最大值对应的动作,而目标网络负责最大动作值的评估。使用Q(s′,a*,θ)和Q(s′,a*,θ-)组成的线性关系来计算出目标值,计算公式为
yDDQN=r+γ[βQ(s′,a*,θ)+
(1-β)Q(s′,a*,θ-)],
其中:β定义为权重,动作选择通过评估网络和目标网络两者的加权来计算出动作值。β∈[0,1],当β=0时,该网络就相当于DDQN网络,当β=1时,算法完全忽略了DDQN评估,仅用DQN网络来选择动作,权重β计算公式为
其中:c为超参数,用来计算权重β,在进行计算时,具有不同特征的问题中,c的最优值不同,超参数c会影响到网络分配权重,动作a*表示为评估网络具有最大动作值的动作;aL表示评估网络具有最小动作值的动作,计算为
a*=argmaxQ(s′,a,θ),
aL=argminQ(s′,a,θ)。
因此,Q(s′,a*,θ-)表示目标网络在状态s′的最大动作值,Q(s′,aL,θ-)表示目标网络在状态s′的最小动作值。在获取Q值时,则根据代价模型[2]和对行动所产生的执行延迟来完成计算,在更新Q值时将损失函数差值通过均方误差计算,根据代价模型得到执行查询动作对应的奖励。
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)-
Q(s,a)],a∈Edp(a),
其中:r为奖励;α为学习率,用来决定误差学习的大小;γ表示折扣因子,表示目的Q值;Q(s,a)表示估计Q值。Q值更新过程为
L(θ)=E[r+γmaxa′Q(s′,a′,θ)-Q(s,a,θ)]。
由于代价模型能够在短时间内迅速给出需要估计的成本,虽然在计算精度上存在与实际延迟有部分偏差的情况,但计算的成本仍然是可参考的。此外,为缓解代价模型带来的估计偏差,本文添加执行延迟的训练,每一次查询执行都需要较长时间去获得实际的反馈。因此,在成本训练后,结合前期的代价模型训练收集的数据,重置输出层的网络权重,使用执行延迟进行微调,具体训练如算法1所示。
算法1训练网络算法
输入: SQL查询语句,初始化θ,θ-。
输出:θ。
1 初始化评估网络参数、目标网络参数以及记忆库D
2 for episode=1 toMdo
3 初始化状态s0
4 fort=0 toTdo
5 基于动态渐进搜索策略的选择行动at
6 执行动作at,获取下一个状态s′和r
7 存储训练样本 (st,at,rt,st+1) 到记忆库D
8 抽取记忆库中n个训练样本进行评估网络更新
9a*=argmaxQ(s′,a,θ)
11 计算网络权重β
12 计算目标值
yWDDQN=r+γ[βQ(s′,a,θ)+(1-β)Q(s′,a,θ)]
14 每隔C步,θ-复制θ网络参数
15 end for
16 end for
3 实验结果与分析
本节主要通过实验来验证本文所提方法在自适应学习路径优化方面的优越性。
3.1 实验设置与基线模型
本文以计算机专业核心课程“数据结构”为例,在文献[25]的基础上,与本学院线上系统中2014—2020年的数据结构题库相结合,构建了数据结构知识图谱。每个知识点选取5道客观题,并通过历年试卷分析描述以及人工筛选的方式,在IRT理论的指导下,根据知识点的难易程度对CA值进行设置。接着,以“数据结构”课程中“树”和“图”两个单元为例,抽取424名学生作为志愿者,根据认知能力在不同的知识节点上进行分组,根据自己的喜好标注认为最为满意的学习路径,然后与通过拓扑排序的学习路径混合在一起,组成了实验数据集。
本实验室中所涉及的基准模型分为两部分。
(a) 用于最优路径生成模型性能比较的基准模型,分别是:1) 文献[7]所提模型,通过LSTM进行最优化路径生成;2) 蚁群算法[22];3) 文献[26]所提到的SVR预测模型。
(b) 与本文所提的动态强化学习相比较的基准模型:1) DQN; 2) DDQN。
实验在4核Intel Core i7-6700 CPU(主频3.4 Hz),运行内存8 G,GPU设置为关闭状态的服务器下运行。训练迭代次数20 000,学习率2.5e-4,隐藏层为256,30分钟代价模型训练,2小时的延迟微调,超参数c为10时表现最好。其他基准模型参数设置以各自论文中的设定为准。
3.2 结果分析
3.2.1验证优越性 将本文所提方法与(a)中基准模型作用于实验数据集,其性能比较如表1所示。所采用的性能比较指标分别为均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absolute error,MAE)。

表1 各方法生成最优路径的结果Table 1 The result of each method on optimal path generation
从表1中可以看出,本文所提方法与其他模型相比具有较好的性能。主要原因在于LSTM模型、蚁群算法以及SVR模型都需要有大量的先验知识或者标注数据,而本文所提模型是在强化学习模型的基础上,用较少的训练信息对未知环境进行探索,以便学习得到一个最优策略,从而减少了对训练数据的依赖。而从实验结果中也可以看到LSTM模型和本文所提方法同时高于传统算法中的蚁群算法和SVR模型,主要原因也在于基于深度学习的方法可以挖掘数据更深层次的特征。
3.2.2验证可靠性 本文所提动态强化学习方法采用动态搜索策略,不仅加快了模型的收敛速度,同时也提高了模型的精度。为了验证这一点,并分析训练数据对模型性能的影响,对本文所提方法与(b)中基准模型进行了对比。本文以路径生成平均相对代价为参考,在不同数量路径集合的情况下进行了验证。这里路径生成平均相对代价的计算方法参考了文献[27]所提出的计算方法。比较结果如图3所示。

图3 不同训练数据下各模型比较结果Figure 3 Comparison results of different models with different training data
由图3可以看出,当训练组数量达到50~80时,模型拥有较低的执行代价。其中,在训练组数量为80时,本文所提模型的平均相对代价为0.210,DQN为0.254,DDQN为0.243,本文所提模型的平均相对代价比DQN低13.48%,比DDQN低17.55%。在实验过程中,本文所提模型在训练组数量为70时收敛速度最快且趋于稳定,增加训练组数依然平稳,说明算法具有较高的稳定性。随着训练数量的增加,DDQN和DQN也能够稳定下来,但与本文所提模型的相对代价相比仍有差距。因此,可以看出,本文所提出的动态渐进策略搜索在控制贪婪参数跳跃的同时,提高了模型训练初期的搜索效率,同时尽可能避免局部最优方案,在训练后期更快地收敛和稳定。
4 结论
该方法包含了一种将细粒度知识元与学生认知能力相结合的知识图谱模型,和一个动态深度强化学习优化模型,解决目前自适应学习路径生成领域所面临的问题。从实验结果中可以看出,本文方法与其他基准模型相比,在自适应学习路径生成任务上能够达到更加优越的性能,所提的动态深度强化学习优化模型改善了深度强化学习模型的整体性能。
基于目前的工作进展,还需要进一步研究以下内容:本文在计算知识图谱中所用到的认知能力参数时,依然选用了人工计算的方法,未来可以尝试通过多维度数据分析在IRT理论下实现智能化计算;本文对学习者进行分组时采用的评价指标是认知能力,未来将考虑融合进更多的学习者特征。
猜你喜欢
红外技术(2022年11期)2022-11-25
少先队活动(2020年12期)2021-01-14
学生天地(2020年15期)2020-08-25
安阳工学院学报(2020年2期)2020-06-05
意林·少年版(2020年2期)2020-02-18
湘潮(上半月)(2019年3期)2019-05-22
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
