
基于iForest-BiLSTM-Attention的数据库负载预测方法
2022-08-18 03:51:02姬莉霞马郑祎赵润哲
郑州大学学报(理学版) 2022年6期
姬莉霞, 赵 耀, 马郑祎, 赵润哲, 张 晗
(1.郑州大学 网络空间安全学院 河南 郑州 450002; 2.郑州市区块链与 数据智能重点实验室 河南 郑州 450002)
0 引言
数据库系统应对负载变化往往缺乏实时响应的能力[1],数据库管理员需要花费大约25%的时间来调整数据库系统以获得更好的性能[2]。在未调度好工作负载与实际系统关系的情况下,极大可能会出现系统宕机以及资源浪费等问题。要实现数据库系统的实时响应,需要通过预测工作负载来把握未来的变化趋势。目前,对于工作负载的预测主要分为统计方法、机器学习方法和深度学习方法。其中,统计方法主要包括自回归积分移动平均法[3]、指数平滑法[4]等,这些方法简单直观,但要求数据有较高的稳定性,无法反映非线性因素的影响。机器学习方法主要包括人工神经网络[5]、支持向量机[6]等,这些方法相较统计方法拥有更高的灵活度,然而人工神经网络难以学习序列数据的相关性,支持向量机则难以处理海量数据。深度学习方法更适宜处理大规模数据,主要包括卷积神经网络、循环神经网络[7]等。由于结构问题,卷积神经网络的池化层会丢失大量有价值的信息,忽略了工作负载局部与整体之间的关联性;循环神经网络则通过循环结构处理序列数据,将先前的信息连接到当前的任务,但可利用的历史数据有限。长短期记忆网络[8](long short term memory,LSTM)改善了循环神经网络固有的梯度消失问题,能够学习长期依赖的信息,但容易丢失超出限度的序列信息,且未关注不同时间步的隐层状态权重等问题。
现有研究大多通过CPU以及磁盘的利用率来对工作负载进行建模[9],然而在对系统资源进行预测时,更换CPU类型、增加内存大小等物理资源的变化会引起工作负载的CPU利用率、内存利用率等指标随之发生改变,导致预测失效,须重新建模[10]。此外,数据库工作负载数据往往会产生异常性能数据[11],这些异常值会影响性能评估以及模型的学习。本文提出基于iForest-BiLSTM-Attention的模型来预测数据库中的工作负载,新增TPC-C基准规范指标作为数据库预测的工作负载特征,解决了传统内存利用率等资源指标随着物理配置更改导致预测失效的问题;采用孤立森林算法对数据进行预处理并以热卡方式填充,大大减少了工作负载预测模型在学习中受到少量异常值的影响,并结合BiLSTM和注意力机制,使包含重要信息的长序列不会丢失全局信息依赖。
1 相关工作
1.1 数据库工作负载
数据库性能的有效提高需要数据库管理员对其进行良好的配置,在此之前,需要对工作负载状态进行正确的判断。Zilio等[12]和Kwan等[13]在离线状态下完成物化视图和索引优化,并没有考虑到当前的负载状态。Holze等[14]则利用负载本身的周期性来降低系统工作量,并根据负载的大小变化对负载监控系统进行调整。Holze等[15]还根据负载的变化规律预测数据库管理系统的工作量。
在数据库中参考负载特征是进行调优的重要一环,主要有两种形式来描述工作负载[16]。第一种描述形式是数据库运行中的操作,例如每秒事务总数与事务类型的混合率[17]、结构化查询语言(structured query language,SQL)语句的到达率以及SQL到达率与数据库信息的结合体[18];第二种描述形式是数据库以及系统中的物理资源利用率或性能指标,例如系统资源(内存、中央处理器和磁盘等)的利用率、数据库资源(缓冲区、锁等)的利用率[19]、并发用户数和响应速度[20]、消息字节、消息计数、使用的记录、访问的记录和运行的时间等。林涛等[21]对云计算资源负载进行了预测研究,主要考虑内存使用率与CPU使用率对集群负载的影响。事务处理性能协会(TPC)提出了一系列工作负载测试基准规范[22],其中TPC-C是针对联机事务处理(OLTP)数据库的基准规范,利用这类描述数据库运行操作的工作负载如吞吐量指标,可以有效避免增大或降低内存容量而导致其利用率减少或增加情况的出现。
本文工作主要应用在现实工业生产环境中,这些负载会由于数据噪声以及异常值导致在性能分析与压力测试过程中结果不准确。通常有两种原因:一是由于系统或数据库的工具在启动与运行中存在爬坡过程与线程数量不稳定,使得测试数据的可靠性降低;二是由于网络异常等不可抗力因素的出现,导致出现异常值数据,这些极少量的异常值会影响对被测对象的预测分析[23]。为此,新增TPC-C基准规范数据库工作负载指标,并使用孤立森林算法检测异常值,减少对预测分析的影响。
1.2 负载预测
自回归积分移动平均法(auto regressive integrated moving average,ARIMA)是最传统的负载预测方法之一。仇媛[24]对LSTM和ARIMA的负载预测进行比较,发现LSTM负载预测模型的结果要优于ARIMA负载预测模型。林涛等[21]使用客观权重赋权法将ARIMA负载预测模型和LSTM负载预测模型进行数据融合,形成一种基于集成学习的组合预测模型。虽然模型可以在给定足够训练数据的情况下获得高性能,但也会受到特征选择和梯度消失问题的困扰。Zhang等[25]利用递归神经网络来预测工作负载,通过使用Google Cloud Trace数据集验证了模型的准确性,但是这些负载预测模型均使用单一的方式。Liu等[26]提出一种利用AR-RNN神经网络来捕获历史信息的工作负载预测模型,预测的数据库负载特征为物理资源的CPU和内存利用率,但是在面对某些复杂情况下的时间序列时,会出现信息丢失等问题。
针对上述问题,本文使用孤立森林算法对原始数据中具有显著离群特征的数据进行过滤并填充重构,提出一种基于注意力机制的双向长短期记忆网络,解决了处理序列数据中不同量级的全局依赖问题。
2 负载预测模型
2.1 预测模型构造
在传统的内存、硬盘利用率预测过程中,随着内存的增加,会出现利用率降低的情况,导致对之前的学习失效,从而使预测结果偏差过大。增加TPC-C基准规范指标作为工作负载的输入,解决重新建模问题,同时也通过对传统资源利用率进行预测的实验来验证方法的适用性。在PostgreSQL、MySQL等数据库中,由于JMeter 和LoadRunner这类测试工具存在爬坡现象和网络异常等问题,导致数据库工作负载中存在一些异常数据,从而影响模型对工作负载数据的理解和学习。因此,对原始数据先使用孤立森林算法进行检测处理,之后再将序列信息输入模型进行学习。为解决遗忘长距离历史信息的问题,改善预测精度,提出基于iForest-BiLSTM-Attention的数据库负载预测模型,其框架如图1所示。

图1 工作负载预测模型框架Figure 1 Workload prediction modeling framework
2.2 异常值重构
数据库工作负载的一般形式为序列(m1,m2,…,mn)∈x,这个序列包含了数据库工作负载特征值mn。一般来说,这些原始数据会被分为一系列的样本,将数据相关的特征集从样本中分离出来进行特征选择。输入层将数据库历史工作负载数据作为预测方法的输入,长度为n的工作负载数据经过预处理后输入预测模型中,可以用X=[x1,x2,…,xn]表示。在进行数据分析与学习之前,通常要对原始数据进行异常值筛选,但这些数据往往需要结合专家知识人工判断。孤立森林属于无参数和无监督学习的方法,是由多个孤立树(isolation Tree,iTree)组成,每个iTree是一个二叉树结构,其从n个样本的工作负载数据集中随机采样放入树的根节点,选择一个数据维度进行随机切分,直至叶子节点只剩一个数据或已达到限定高度。将数据库工作负载数据构建完成二叉树孤立森林后,整合全部孤立树的结果,用生成的孤立树来评估测试数据,即计算异常分数s。计算异常得分的公式为
(1)
c(x)=2ln(x-1)-2(x-1)/x+γ,
(2)
其中:E(h(x))表示x在iTree路径长度的期望均值;c(Ψ)为给定样本数Ψ时路径长度的平均值;γ为欧拉常数。
s(x,Ψ)用来对样本x的路径长度h(x)进行标准化处理,异常得分代表该样本点的异常程度,

(3)
对于筛选出的异常数据点采用热卡填充的方法。在工作负载中标记孤立森林算法检测出的异常点,再将这个异常点在完整数据中找到一个与它最接近的对象,然后利用这个对象的值进行填充,得到重构后的序列X′=[x′1,x′2,…,x′n]。将工作负载中的异常数据点进行数据重构,以便不影响对数据的建模。
2.3 隐层状态计算
2.3.1正反向隐层状态计算 在每个LSTM单元中拥有三个特殊的“门”结构:遗忘门f、输入门i和输出门o。LSTM网络的内部结构如图2所示。

图2 LSTM网络的内部结构Figure 2 Internal structure of LSTM network
LSTM单元接受此时刻的重构数据库负载输入数据x′t和上一时刻的状态信息ht-1,利用“门”结构能保留远处结点信息不会被丢失,具体公式为
it=σ(Wi×[ht-1,x′t]+bi),
(4)
ft=σ(Wf×[ht-1,x′t]+bf),
(5)
ot=σ(Wo×[ht-1,x′t]+bo),
(6)
(7)
(8)
ht=ot×tanh(ct),
(9)

在单向的循环神经网络中,模型实际上只使用到“正向”的信息,而没有考虑到“反向”的信息。但在实际场景中,预测可能需要使用到整个输入序列的信息。正向隐层状态与反向隐层状态输出值如图3所示。
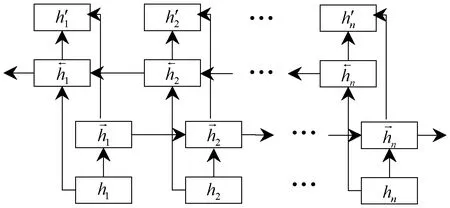
图3 正向隐层状态与反向隐层状态输出值Figure 3 Output values of forward hidden layer state and reverse hidden layer state
(10)

2.3.2Attention机制隐层状态计算 对输入序列建模时每一步的中间输出结果h′n,将Attention机制引入数据库工作负载模型中,根据输入的特征值对输出的影响来为神经网络中的隐层状态赋予不同的权重,并与输出序列的值联系起来,以选择性地关注不同时间步的输入对预测结果的影响,从而改善负载预测效果。训练模型学习如何选择性地关注输入数据,为相关性更高的输入向量赋予更高的权重。同时,也可以避免因序列过长导致信息丢失的问题,使模型更容易捕获序列中长距离相互依赖的特征。Attention机制计算隐层权重如图4所示。
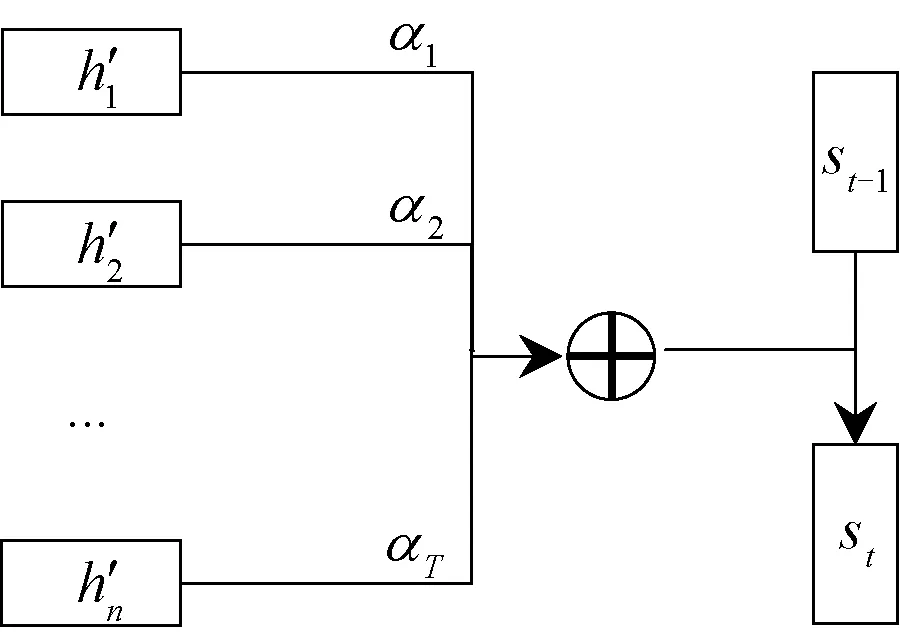
图4 Attention机制计算隐层权重Figure 4 Attention mechanism to calculate hidden layer weights
Attention层的输入为经过BiLSTM层计算的隐层状态h′t,et表示h′t所决定的注意力概率分布值,αt为注意力权值,在t时刻Attention层的输出为st,具体公式为
et=st-1×h′t,
(11)
(12)
(13)

(14)
其中:ω为权重矩阵;b为偏置。
2.4 训练方法
选取Adam优化算法,定义损失函数为均方误差(MSE),总损失可以表示为
(15)

周恩来在招待会上说,建设新民航,人才是主要的。林雨水和其他两航起义人员都表示要积极参加新中国的建设,为祖国的航空事业贡献力量。在随后的岁月里,林雨水先后在空军、海军航空兵、民航任飞行员和教员,一直珍藏着那张留有周恩来签名的法币,并于1979年将法币捐献给了中共代表团梅园新村纪念馆。
3 实验部分
3.1 实验数据
实验分为两个部分:第一部分选取TPC-C数据集对吞吐量等数据特征进行预测与分析,以验证该方法的有效性;第二部分选取阿里巴巴集团的集群追踪(Alibaba Cluster Trace)项目数据集中的资源使用率进行预测与分析,以验证该方法的适用性。TPC-C工作负载测试基准规范在服务器上部署的PostgreSQL 9.6数据库中生成了10 795条工作负载数据序列,提取其中的吞吐量等数据特征。TPC-C基准规范指标中包含吞吐量、平均延迟、中值延迟等12项记录,负载记录的时间间隔为5 s。Alibaba Cluster Trace数据集采集周期为8 d,由6个表组成,其中machine_usage表反映CPU利用率、内存利用率、磁盘IO利用率等10项字段,数据集文件大小为8.37 GB。
上述两个数据集反映了数据库中工作负载的变化情况,这样的数据具有规律性与周期性,使用时将与数据相关的特征集抽取一部分,从样本中分离出来进行特征选择。在TPC-C基准规范指标数据集中选择吞吐量、平均延迟和中值延迟指标进行输入,在Alibaba Cluster Trace数据集中选择CPU利用率和内存利用率进行输入。输入数据集的详细信息如表1所示。
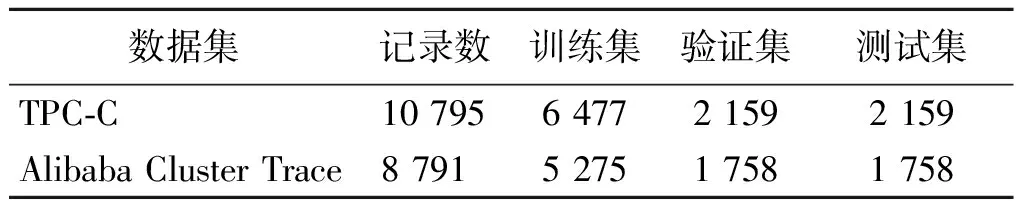
表1 输入数据集的详细信息Table 1 Input data set details 单位:条
3.2 评价指标
为评估本文提出的数据库负载预测方法的性能,采用均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2)作为衡量预测精度的指标,具体公式为
(16)
(17)
(18)

3.3 实验设计
首先将数据集中为负数或缺失的值标记为异常值,然后使用孤立森林算法进行检测,将检测后的异常值剔除,并用热卡填充法填充缺失异常值。将数据缩放至0~1,具体公式为
(19)
其中:x为缩放前的值;y为缩放后的值;MinValue代表数据集中最小值;MaxValue代表数据集中最大值。
在开始训练之前,将所有数据集划分为训练集和测试集,训练集占70%,测试集占30%。求解Attention权重,将Attention与BiLSTM对应数值相乘,优化器为Adam,损失函数为MSE,BiLSTM层的hidden_size1为128,hidden_size2为128,Attention层的attention_size为64,Dense层的units为64。
使用本文方法进行预测,并将结果进行储存。运用控制变量法对不同的参数选取适当的取值范围,在训练过程中不断调整参数,直至模型的预测效果最佳,最终得到的参数epochs为60,batch_size为64,sequence_length为96,alpha为0.004 97。
3.4 实验结果与分析
3.4.1异常数据检测 在数据集中存在部分异常数据以及缺失数据,这些数据会极大地影响模型的学习效果以及预测精度。先把不符合工作原理的负数以及缺失值标记为异常值,再将处理后的TPC-C工作负载测试基准数据集与Alibaba Cluster Trace数据集输入模型。使用模型中的孤立森林算法,图5为初始数据散点图,图6为过滤后数据散点图。异常数据检测结果表明,TPC-C工作负载数据集中异常数据数为421,占比为3.9%,Alibaba Cluster Trace数据集中异常数据数为211,占比为2.4%。将这些异常值采用热卡填充法进行数据重构,以便不影响对数据的建模,其工作原理是在数据集中为该异常值寻找与当前样本最近似的对象值进行填补。

图5 初始数据散点图Figure 5 Initial data scatter plot

图6 过滤后数据散点图Figure 6 Filtered data scatter plot
3.4.2负载预测对比分析 为验证和评价本文方法,使用TPC-C和Alibaba数据集,与GRU、LSTM、CNN-LSTM、BiLSTM-Attention负载预测模型[27]进行对比实验。吞吐量工作负载数据集预测曲线如图7所示。可以看出,吞吐量并未持续增加,不属于递增型负载,具有一定的周期变化规律,相比于其他模型,本文方法的变化趋势与原始数据基本一致,并且带有孤立森林检测异常点的方法比没有用该检测方法的曲线更加准确。CPU利用率工作负载数据集预测曲线如图8所示。可以看出,LSTM模型与GRU模型的预测效果相对较差,CNN-LSTM模型的预测效果则优于传统的单一方法,BiLSTM-Attention模型的准确性相比以上方法有明显提高,而本文方法与真实序列更能达到近似的趋势,说明带有孤立森林检测的负载预测方法能够更好地描述数据库指标的波动情况。

图7 吞吐量工作负载数据集预测曲线Figure 7 Throughput workload data set prediction curve

图8 CPU利用率工作负载数据集预测曲线Figure 8 CPU utilization workload data set prediction curve
不同模型的性能指标比较结果如表2所示。
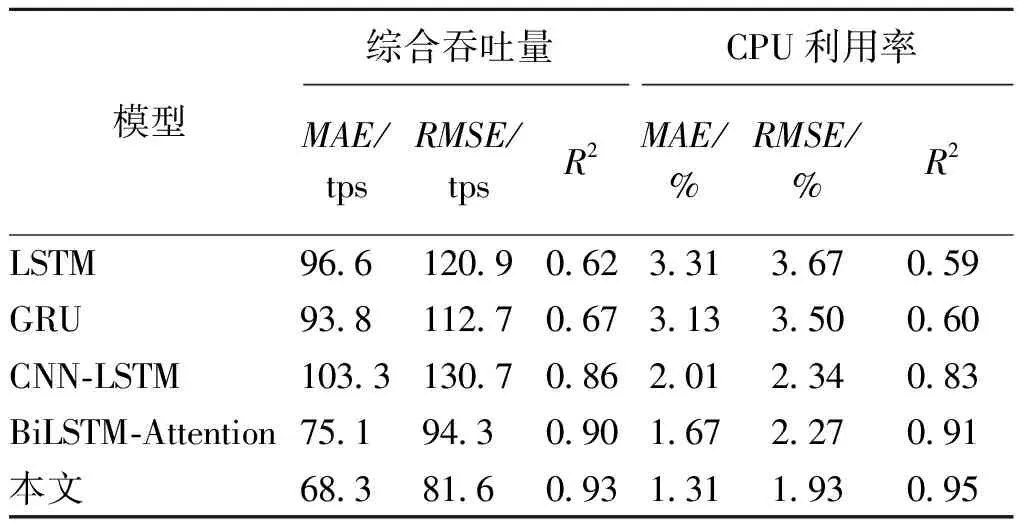
表2 不同模型的性能指标比较Table 2 Comparison of performance index of different models
由表2可知,相较于其他模型,本文方法的预测精度是最高的。其中综合吞吐量和CPU利用率的R2值分别为0.93和0.95,预测结果更为稳定与精确。此外,不带有孤立森林检测的BiLSTM-Attention模型的预测效果相较于其他的单一模型,在预测精度上也有较大提升。本文方法在更好地捕捉负载变化趋势的同时,也有一定的泛化能力,在研究其他指标建模时有一定的适用性。
4 结束语
针对数据库工作负载预测中存在的问题,本文提出一种基于iForest-BiLSTM-Attention的数据库负载预测方法。通过RMSE、MAE和R2指标分析了传统LSTM神经网络、GRU神经网络以及变体CNN-LSTM神经网络等预测模型在两个数据集上的预测精度,对比实验结果表明,本文提出的iForest-BiLSTM-Attention神经网络的预测模型结果为最优,适用性更强,具有更高的精准度。由于工作负载复杂多变,仍存在一些特征选取问题值得探讨,后续也将继续研究工作负载预测与调优相结合的方法。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
人民珠江(2019年4期)2019-04-20 02:32:00
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
消费导刊(2017年24期)2018-01-31 01:29:29
重型机械(2016年1期)2016-03-01 03:42:04
印制电路信息(2015年6期)2015-12-30 12:57:48
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
计算机工程(2014年9期)2014-06-06 10:46:47
