
在线同伴反馈情感识别与可视化:促进教师深度反思与教学问题改进*
2022-08-17 02:29王阿习余胜泉湛志强刘秀英
中国远程教育 2022年8期
□ 王阿习 余胜泉 湛志强 刘秀英
一、引言
课例研究活动是由教师学习共同体围绕特定的专业发展目标合作开展教学设计修改、教学实施、课堂观察、课后研讨与教学反思的专业发展实践活动(Dudley,2013)。当前,随着互联网与智能移动设备的普及应用,基于互联网平台的大规模在线课例研究已成为促进教师专业发展的重要活动。教师在课例研究活动中能够获得大量的同伴反馈数据。已有研究发现,帮助学习者从同伴反馈中获得必要信息能够促进学习者的自我反思与同伴学习(Markham,Markham,&Smith,2016)。
然而,面对大量的同伴反馈数据,尤其是文本评论类数据,教师没有足够的时间浏览大量的同伴反馈文本(Saito,2012;Dudley,2013;Larssen,et al.,2018;Lee&Tan,2020),也没有足够的数据分析能力(Larssen,et al.,2018),因此难以从大量的反馈中发现集体的共识信息,获得关键改进建议(Lee,2008)。为了帮助教师从大量的同伴反馈数据中快速发现集体共识信息,获得关键的教学改进建议,本研究采用机器学习技术构建在线同伴反馈文本情感识别与可视化模型,设计与开发同伴反馈情感可视化报告,以期实现教师同伴反馈文本情感识别,促进教师深度反思,支持教学问题的智能诊断与改进。
二、文献综述
(一)教师在线课例研究中的同伴反馈研究
在线课例研究活动是促进教师专业发展的重要活动,强调教师以团队的形式在虚拟学习社区中的协作和互动,以促进教学知识共建共享(Lee&Tan,2020)。完整的课例研究活动通常分两到三轮进行,在这期间教师会收到大量的同伴反馈。已有研究表明,帮助学习者从同伴反馈中获得必要信息能够促进学习者的自我反思与同伴学习(Markham,et al.,2016),有助于学习者实现学习效果的迁移,将知识应用到实践中(闫寒冰,等,2019)。因此,为帮助教师从同伴反馈中获得改进建议,Milner-Bolotin(2018)采用了协作注释系统,可视化同伴反馈内容,促进职前教师的反思性学习。该研究发现,同伴对教学视频和教案的反馈在帮助学习者认识自己的优缺点、反思进步和建立采用科技教学信心方面发挥着重要作用;Zhang等(2019)认为,采用文本挖掘方法和知识网络分析教师在线专业学习社区中的交互内容,对促进教师专业发展具有重要意义。
已有研究表明,深入挖掘教师讨论中的过程性信息,并识别有价值的评论,有助于提升教师团队的课例研究活动效果(Lee&Tan,2020;Wang,et al.,2019)。但是,面对课例研究活动中的大量同伴反馈,仅仅挖掘与可视化文本语义内容,难以帮助教师快速发现集体共识信息与关键改进建议。若要从众多同伴反馈中挖掘集体共识信息与关键改进建议,需要采用文本情感分析技术识别同伴反馈的情感倾向,对正向反馈文本与负向反馈文本进行归类,从正向反馈文本中提炼教学优势,从负向反馈文本中提炼教学问题,进而增强教师教学特色,实现教学问题的智能诊断与改进。
(二)在线评论文本的情感分析研究
文本情感分析是自然语言处理领域的一个重要研究方向。在线评论文本的情感分析是对带有感情色彩的主观性互联网文本进行分析、处理、归纳和推理的过程。目前常见的情感分析方法有两种:基于语义的研究方法和基于机器学习的研究方法(张乐,等,2017)。基于语义的研究方法主要利用现有情感词典或建立倾向性语义模式库,应用情感规则匹配的方式实现文本语义的理解,从而实现对文本的情感识别。例如,曾子明等(2018)构造集成情感分类模型,对公共安全事件的微博进行情感分析;张继东等(2019)采用基于语义的研究方法,提出基于用户交互行为和情感倾向的影响力度量算法,能够挖掘出真正具有影响力的正面意见领袖。
基于机器学习的研究方法则将文本情感分析看作分类问题,受益于神经网络模型的快速发展,近年来基于机器学习的文本情感分析研究取得了显著成果(Guo,et al.,2016;Elaheh,et al.,2019)。神经网络模型能够自动学习训练数据中的特征,并据此预测输入文本的情感倾向,大大提升了文本情感分析的效率。然而,神经网络模型需要大规模的标注数据,训练数据的规模严重影响模型的性能表现。通常情况下,大规模的训练数据是很难搜集的,而且数据的标注工作需要大量专业人员完成,工作量较大。为了解决这个问题,Devlin等(2018)基于Transformer模型,在大规模的数据集上训练得到了BERT(Bidirectional Encoder Representations from Transformers)预训练模型,其性能在多个自然语言处理任务中取得了很大提升。另外,以往研究基于长短期记忆网络开展商品评论文本分析(於雯,等,2018)和学生反馈文本中的学业情绪识别(冯翔,等,2019),也取得了较好的预测效果。
对比词典法和机器学习两种文本情感分析方法,发现两种主题模型分析法的结果差异较大。基于词典的分析方法需要借助于情感词典库,属于粗粒度的情感识别方法;基于机器学习的分析方法需要依赖标注好的训练集,实现相对简单,可以对普通网络文本语言进行快速分类,而且能够分辨网络语言中更细微的区别(Guo,et al.,2016)。因此,为了识别同伴反馈文本情感倾向,挖掘文本隐含信息,本研究采用基于机器学习的方法开展在线反馈文本的情感倾向识别。研究问题如下:
(1)如何识别教师同伴反馈文本的情感倾向,发现大量同伴反馈中的集体共识信息?
(2)如何可视化教师同伴反馈文本的情感倾向,促进教师深度反思与教学问题改进?
三、在线同伴反馈文本情感识别与可视化
(一)模型构建依据
文本情感分析又称为“意见挖掘”,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程(赵妍妍,等,2010),旨在识别文本中的主观性句子,判断情感倾向,可视化情感状态,挖掘隐含信息。网络文本情感分析的一般过程包括选择信息源、识别文本情感倾向和可视化呈现情感分析结果(朱琳琳,等,2017)。
一方面,识别同伴反馈文本的情感倾向。通过分析大量教师在线课例研究活动中的同伴反馈文本数据,本研究发现与电商、社交等领域的文本数据不同,教师反馈文本数据的情感表达较为委婉、含蓄。例如,教师在评论同伴的教学效果不理想时,经常采用类似的表达方式:“概念图可以画简单一些”“如果能留点时间,让学生通过朗读来更好体会诗人的内心世界,效果就会更好了”。与基于词典的分析方法相比,基于机器学习的分析方法能够分辨网络语言中更细微的区别(Guo,et al.,2016)。与Word2Vec、fasttext等基于词向量的固定表征模型相比,BERT预训练模型采用多层Transformer进行特征提取,是基于词向量的动态表征,具有强大的表征能力和并行计算能力,目前已出现了大量基于BERT的文本语义分析研究(Liu,et al.,2019;Omelianchuk,et al.,2020;Wu,et al.,2020)。因此,为了识别课例研究活动中教师同伴反馈文本的情感倾向,本研究将基于BERT模型开展同伴反馈文本的情感倾向分析。
另一方面,可视化呈现文本情感分析结果。已有研究设计了基于计算机的自我报告式情感标记工具(Molinari,et al.,2013),并探索其对促进合作学习中共享同伴情感、合作后觉察情感与交互质量的影响。结果表明,情感意识工具可以激发学生参与情感交互,提高学习者间的交互质量。也有研究通过采集300多名学生使用电脑进行编程的过程性交互文本数据,设计了四种学习者情感可视化方式:基于时间的情感可视化、基于情境的情感可视化、情感变化趋势的可视化和信息汇聚的可视化。这四种情感可视化方式能够改善学习者学习中的情感意识,促进自我反思(Leony,et al.,2013)。
在借鉴已有的文本情感识别与可视化模型研究成果的基础上,结合课例研究活动同伴反馈文本委婉含蓄、课例研究活动参与人数多和周期长等特点,本研究采用基于BERT模型识别同伴反馈文本的情感倾向,并基于课例研究活动时间线与活动情境,可视化呈现同伴反馈文本的情感分析结果。
(二)在线同伴反馈文本情感识别与可视化模型构建
教师在线课例研究中的同伴反馈文本情感识别与可视化模型包括同伴反馈数据采集与预处理、基于机器学习的同伴反馈文本情感识别和生成同伴反馈文本情感可视化报告三个部分,各部分之间的关系如图1所示。
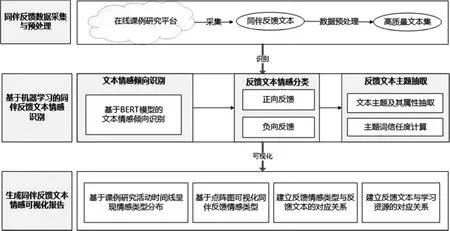
图1 在线同伴反馈文本情感识别与可视化模型
1.同伴反馈数据采集与预处理
一轮完整的课例研究活动通常包括教师自主撰写教学设计、教师群体协同修改教学设计、执教教师开展教学活动、教师群体协同开展课堂观察、课后讨论与教学反思改进等环节。本研究主要采用听课本APP开展课例研究活动(陈玲,等,2018),此活动由教师群体围绕特定的活动目标协同完成。移动端的听课本APP用于采集课例研究活动中的教师同伴反馈数据;使用基于学习元平台的在线教研空间(余胜泉,等,2009,2021),汇聚课例研究活动全过程的同伴反馈数据,包括协同修改教学设计(备课)、课堂观察(听评课)与教学反思等活动中生成的同伴反馈文本数据。文本数据预处理之后形成高质量的文本集,用于同伴反馈文本情感识别。
2.基于机器学习的在线同伴反馈文本情感识别
(1)基于BERT模型的同伴反馈文本情感倾向识别
首先,BERT预训练模型是在Transformer模型的基础上采用大规模的数据集进行训练得到的(Devlin,et al.,2018);其次,本研究邀请两位教师教育领域专家作为编码者,标记同伴反馈文本集的情感倾向,验证两位编码者编码结果的一致性,并经过两位编码者充分讨论形成最终的文本情感倾向编码结果;最后,本研究采用Pytorch深度学习框架,将预训练的BERT模型在特定数据上微调后用于预测输入的同伴反馈文本的情感极性(如图2所示)。关键代码主要包括预训练模型加载、模型微调和模型测试。
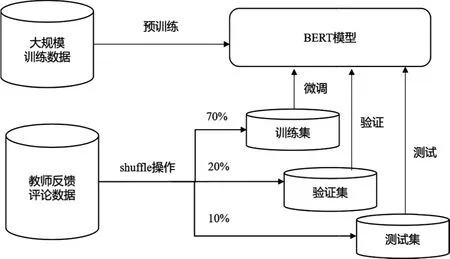
图2 基于BERT模型的同伴反馈文本情感倾向识别
为了准确分析课例研究中的同伴反馈文本数据的情感倾向,本研究采用了主流的“预训练+微调”模式。这种模式的操作顺序是,先将教师反馈评论数据进行shuffle操作,以对教师反馈评论数据进行随机排序,然后按照7∶2∶1的比例随机将数据分为训练集、验证集和测试集。训练集用于微调BERT模型,验证集用于验证微调后的BERT模型准确度,测试集用于测试模型的分析效果。这种“预训练+微调”的模式,不仅可以有效利用预训练模型强大的表征能力,同时也可以根据特定的学习任务对模型进行针对性的调优。
(2)同伴反馈文本情感分类与主题抽取
抽取文本主题词需要构建学科教学知识库,本研究以小学语文学科为例,构建了语文学科教学知识库。该知识库是依据《小学教师专业标准(试行)》《语文学科知识与教学能力》(王荣生,等,2011)等文献、由语文学科专家经过多轮协商建构而成的,由教学理论、教学内容和教学策略等维度组成,各维度下包含多个子维度的知识点。以教学策略维度为例,包含导入策略、提问策略、阅读策略、支架策略和总结策略等子维度的知识点,各个子维度下包含若干个关键词(如图3所示)。尽管该知识库是由学科专家经过多轮协商反复修改而成的,但仍不是最终的版本,除了以上知识点外后续在应用过程中仍需要持续迭代完善。
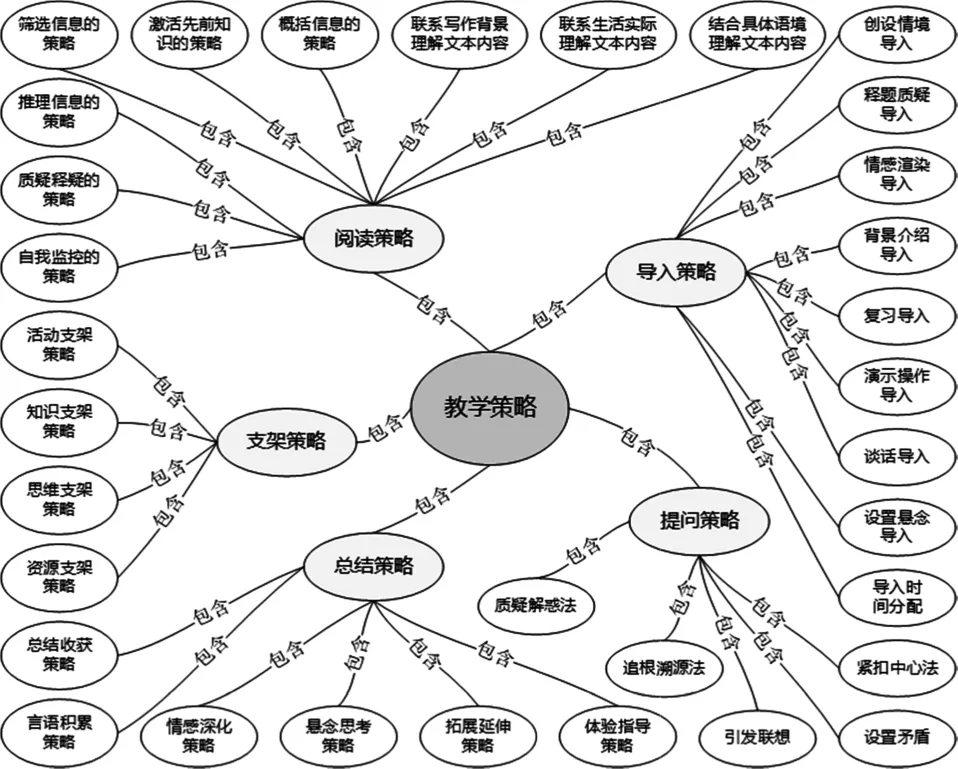
图3 小学语文学科教学知识库(节选部分)
在识别反馈文本情感倾向的基础上,本研究将反馈文本分为正向反馈和负向反馈,并采用文本关键词抽取方法抽取文本主题词。例如,教师同伴反馈文本“本节课教学目标清晰,学习活动设计具有层次性”。本研究可以提取的主题词有教学目标、学习活动、活动设计、有层次性等。每条同伴反馈文本都会被分成若干个主题词,在众多的教学主题词中如何判断哪些主题词比较重要呢?这就需要构建主题词可信度计算模型,确定主题词的可信度。结合教师课例研究活动实践,本研究从众多影响主题词可信度的因素中,选择主题词出现的频次、听课者判断的一致性(对同一个关键词多位听课教师判断的一致程度)和主题词的历史可信度,作为主题词可信度计算模型的指标。本研究邀请学科教学领域与计算机教育应用领域的9位专家,采用层次分析法对主题词可信度计算模型的因素进行相对重要性比较,得出主题词出现频次、听课者判断一致程度和主题词历史可信度三个主要因素的权重值分别为0.32、0.56和0.12。在此基础上,从大量的教师同伴反馈文本中提取主题关键词,挖掘隐含信息,进而发现教师集体共识信息。
3.生成同伴反馈文本情感倾向可视化报告
在识别同伴反馈文本情感倾向的基础上,采用可视化技术与点阵图技术生成同伴反馈文本情感可视化报告。该情感可视化报告具有以下四个特点:基于时间线呈现反馈文本情感类型分布,基于点阵图技术可视化同伴反馈情感类型,建立反馈文本情感类型与反馈文本的对应关系,以及建立反馈文本与学习资源之间的对应关系(如图4所示)。
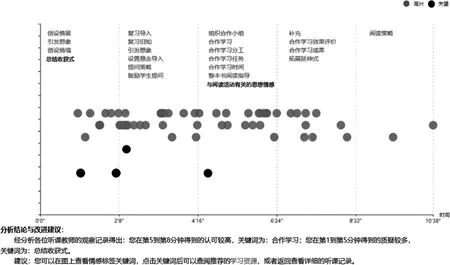
图4 教师在线同伴反馈文本情感倾向可视化报告
首先,基于课例研究活动时间线呈现反馈文本情感类型分布。以课堂观察活动为例,执教教师上完一节课后会收到许多来自同伴教师的教学效果反馈。基于时间线可视化教师同伴反馈情感倾向可以清晰地表征执教教师在各个时间节点的教学活动实施情况。如图4所示,执教教师在第1到第3分钟收到的负向反馈较多,说明课堂教学起始环节的活动实施效果有待讨论。
其次,基于点阵图技术可视化同伴反馈情感类型。采用“点阵图”技术(Dotted Chart Technology),可视化呈现听课教师群体在各个时间节点的反馈文本情感倾向分布情况。点阵图分析技术是一种发现技术,由两个正交的维度构成,即横轴显示时间长度和纵轴显示成分类型(如事例、发起人、任务、事件类型或者数据成分等)(Song&van der Aalst,2007),提供了一种有用的、综观全局的视图模式,能够快速洞悉执教教师教学过程中存在的关键问题,并将其直观地呈现给用户。如图4所示,当教师将鼠标移动到不同颜色的圆点上时,系统会呈现该圆点的反馈提供者昵称、反馈文本内容和反馈文本提交时间等信息;当教师点击不同颜色的圆点时,系统可以自动跳转到该反馈提供者的课堂观察记录页面,这种设计方式既有利于执教教师与听课教师之间智慧共享,又有利于教师群体之间互动交流。
再次,建立反馈文本情感类型与反馈文本的对应关系。为了便于教师直观地发现各个教学步骤的实施效果,本研究采用文本关键词抽取技术提取教学各个时间段的重要关键词,以词云的形式呈现在各个教学时间段中,进而基于教学时间线建立反馈文本情感类型与反馈文本内容之间的对应关系。为了突出显示反馈文本的情感倾向与文本内容之间的对应关系,本研究采用不同的颜色标识,如浅色的圆点代表正向反馈,浅色的关键词代表正向反馈内容;深色的圆点代表负向反馈,深色的关键词代表负向反馈内容。这种设计方式便于教师一目了然地发现教学活动的实施情况,促进教师深度反思与同伴研讨交流。
最后,建立反馈文本与学习资源之间的对应关系。为了增强教师的教学特色和改进教学问题,本研究在设计同伴反馈文本情感可视化报告时采用超链接的方式建立了反馈文本与学习资源之间的对应关系。如图4所示,当教师点击“与阅读活动有关的思想情感”时,系统能够为教师自动推荐情感目标达成相关的学习资源。除此之外,同伴反馈文本情感可视化报告也为教师提供了“分析结论与改进建议”,有助于教师开展有针对性的学习与问题改进。
四、在线同伴反馈文本情感识别与可视化效果分析
(一)研究设计与实施
本研究从在线课例研究平台中随机选择若干节课的同伴反馈文本数据。首先,分别采用BERT模型和fasttext模型对教师课例研究活动中的同伴反馈文本数据进行情感倾向识别。fasttext模型能够提供简单高效的文本语义分析方法(Joulin,et al.,2016),支持多语言分类处理,尤其是对于开展中英文混合的文本语义分析效果较好。其次,对比两种模型分析结果的差异。再次,邀请教师教育领域专家对同伴反馈文本数据的情感倾向进行人工编码,对比基于BERT模型和fasttext模型自动分析结果的一致性程度,以验证BERT模型的鲁棒性。最后,采用案例研究法分析反馈文本情感可视化报告的应用效果。本研究选择了处于不同发展阶段的8位教师作为案例研究对象,分别是4位职初期的新手教师、2位职中期的骨干教师和2位学科教研员。8位教师均采用同伴反馈可视化报告开展课例研究活动。研究设计如图5所示。
图5 研究设计
(二)研究数据收集与结果分析
1.研究数据收集
为了检验同伴反馈文本情感可视化报告的准确度,本研究以北京、广州、河北涿鹿与安徽肥西等区域的小学语文教师的课例研究数据为例,包括课例研究活动中的教师同伴反馈的文本、教学反思、课堂观察记录文本等共计2,800多条,剔除无效数据后总计2,500条数据计入分析。
为了分析同伴反馈文本情感可视化报告的应用效果,本研究采用访谈和参与式观察收集案例研究的资料。在正式访谈之前,首先,研究者依据研究目标制定了半结构化的访谈提纲,包括采用同伴反馈文本情感可视化报告的优势、不足和改进建议;其次,告知访谈对象此次访谈的目的、主要访谈内容,说明访谈形式和访谈所需时间,并约定正式访谈时间;最后,在访谈中征求教师的意见是否同意全程录音,得到访谈对象的同意后,本研究采用录音工具对访谈全程进行录音。8位教师的访谈结束后,研究者采用专业软件完成录音转文字后,再对文本进行审核校对,最终形成访谈文字稿。
2.研究结果分析
(1)基于BERT模型的反馈文本情感倾向识别效果分析
为了减小数据切分的随机性对模型预测结果的影响,首先将教师同伴反馈评论数据进行shuffle操作,以对教师同伴反馈评论数据进行随机排序,然后按照7∶2∶1的比例随机将数据分为训练集、验证集和测试集。其中,训练集有1,750条用于微调BERT模型,验证集有500条用于验证微调后的BERT模型准确度,测试集有250条用于测试模型的分析效果。其次,使用训练集进行了三轮的微调,并在微调过程中使用验证集对模型进行监测,保留验证准确率较高的模型。最后,在测试集上验证了模型的情感分析能力,模型预测部分源码(如图6所示)。

图6 模型预测部分代码示例
为了说明模型的鲁棒性,本研究进行了多次实验,并将实验结果与fasttext模型进行了性能对比,结果如图7所示。根据BERT模型和fasttext模型的对比结果,可以得出:①BERT模型取得了更高的情感分析准确率,达到98%,而fasttext模型仅取得了88%的准确率;②BERT模型具有更强的鲁棒性,在多次随机测试中的性能表现更稳定。虽然fasttext模型能够在公开的主流分类数据集上取得良好的结果,但在教师的课例研究活动反馈文本数据集上和BERT预训练模型有较大的差距。原因主要在于:①通过在大规模数据集上进行预训练,BERT模型能够学到更丰富的语义信息表示,表征能力更强;②在微调过程中,BERT模型能够利用已学到的语义信息标识迁移到教师反馈文本数据集上,学习教师委婉含蓄的表达方式。因此,“预训练+微调”的模式能够取得更高的分析准确率和更强的鲁棒性。
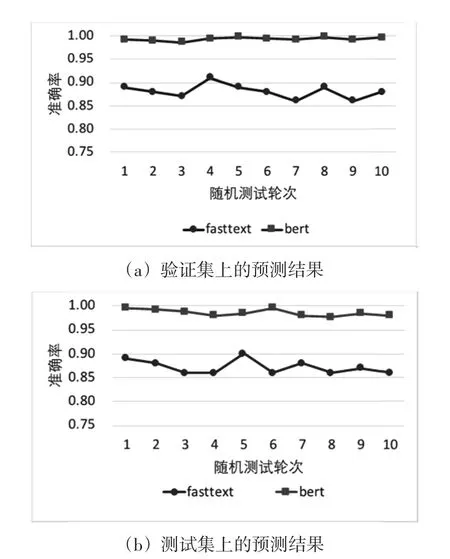
图7 BERT模型和fasttext模型的性能对比
(2)同伴反馈文本情感可视化报告的应用效果分析
同伴反馈文本情感可视化报告的优势在于清晰地呈现各个教学环节的实施效果,准确定位存在问题的教学活动,便于教师精准改进各个教学环节的活动设计与时间分配等,为课后研讨交流环节提供明确的方向。正如教研员1所言:我认为情感可视化图很有帮助,一下就看到了突出的点,那肯定是大家认为不好的地方,这样评课的时候可以针对反映出的问题做深入的讨论,修改教学策略。教研员2指出:情感可视化图能让老师重点反思各个时间段的教学行为,看出听课老师对于各教学环节的节点把握的一致程度,重点研讨如何改进。新手教师2提出:通过这个情感可视化时间轴,我能够看出自己在教学时间的把握上存在问题。例如,在第15~20分钟这个教学环节,黑色的点比较多,说明识字教学环节存在问题,那么我可能会重点学习识字教学的方法。骨干教师1认为:我觉得情感可视化这张图对授课老师是有帮助的,因为通过这张图能明显地看出自己教学中哪些地方需要改进。比如说在《小王子》整本书导读课的中间高潮引导学生读文,走进故事情节,让学生带着前面的总结,小组合作读这篇文章,这是课中不太理想的地方。
同伴反馈文本情感可视化报告中呈现的各个教学环节的关键词,便于教师一目了然地发现自己的学科教学知识特色与不足,利于教师依据各个教学活动的实施效果开展基于证据的深入反思。骨干教师2指出:我从这个图里面能够直观地看到自己在“写话支架”设计方面做得比较好,因为这个环节的情感圆点都是灰色。另外,这个图能够提示我在“总结收获”方面需要改进,就是课堂小结这儿差了一点,这样就是特别直观地让老师看到自己这个课的得与失。骨干教师1也指出:对于执教者来说,我一眼就能看出来哪个环节需要完善,然后回忆到当时那个环节哪里做得不太好,可以为自己写反思服务。这个情感可视化图也很明显地展示了听课老师们对自己教学的点评意见和观点,反思时就可以将这些意见与自己上完课的感受融合在一起,这样写出来的教学反思会更具体更深刻。
关于同伴反馈文本情感可视化报告的不足之处,教师们认为设计方式中黑点表示获得的负向反馈,其文字标记为“失望”。这种“失望”表述过于负面,会让教师感到压力(新手教师2和新手教师4)。同时,新手教师1和新手教师3认为,自己作为年轻教师缺乏教学经验,需要专家教师给自己提供直接的教学改进建议。这从新手教师1的访谈中可以得到印证:我是年轻老师,比较需要一些这种直接的教学改进建议。毕竟上课经验还不足,需要经验丰富的老师告诉我们哪些环节需要改进。其实压力也还好,关键是对我们以后改进上课效果挺好的。
五、结语
为帮助教师从同伴反馈中获得必要信息,促进教师的自我反思与同伴学习,本研究基于机器学习技术构建了教师在线同伴反馈文本情感识别与可视化模型,设计了同伴反馈文本情感可视化报告,并检验了基于BERT模型的同伴反馈文本情感识别的准确度与可视化报告的应用效果。具体内容如下:
(一)采用BERT模型识别反馈文本情感倾向,实现教师集体共识信息发现
采用BERT模型能够较好地识别同伴反馈文本情感倾向,原因主要在于BERT模型是在大规模数据集上训练得到的,能够学到更丰富的语义信息表示,其表征能力与并行计算能力较强;采用“预训练+微调”的模式,不仅可以有效利用预训练模型强大的表征能力,同时也可以根据特定的学习任务对模型进行有针对性的调优。在微调过程中,BERT模型能够利用已学到的语义信息标识迁移到教师反馈文本数据集上,学习教师委婉含蓄的表达方式。因此,“预训练+微调”的模式能够取得更高的同伴反馈文本情感倾向分析准确率和更强的鲁棒性。在识别反馈文本情感倾向的基础上,本研究采用文本关键词抽取方法,从大量的教师同伴反馈文本中提取主题关键词,挖掘隐含信息,进而发现教师集体共识信息。
(二)生成同伴反馈情感可视化报告,促进教师深度反思与教学问题改进
同伴反馈情感可视化报告的优势在于清晰地呈现各个教学环节的实施效果,准确定位存在问题的教学活动,便于教师精准改进各个教学环节的活动设计与时间分配等,能够为课后研讨交流环节提供明确的方向。同伴反馈情感可视化报告中呈现的各个教学环节的关键词,便于教师开展数据驱动的基于证据的深入反思。另外,同伴反馈情感可视化报告建立了教学问题与学习资源之间的关联,教师能够快速查阅与教学问题相关的教学设计、课件与文献等资源,促进不同校际和区域的教师同伴互助,支持教师开展面向教学问题解决的深度学习。
尽管本研究构建的教师同伴反馈情感倾向识别与可视化模型有助于提升教师深度反思与教学问题改进,但客观地反思整个研究过程仍存在不足与局限:一是仅以语文学科为例构建学科教学知识库与同伴反馈情感识别与可视化模型,未深入分析模型在其他学科的适用性;二是仅用案例研究法分析同伴反馈情感可视化报告的效果,研究对象的数量与代表性不足。后续需要研究者持续更新学科教学知识库,优化分析算法,运用多种方法验证同伴反馈情感可视化报告的应用效果,以期为教师提供更加便利的同伴反馈支持工具,提升大规模在线课例研究活动的实施效果。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
大学(2021年2期)2021-06-11
少儿美术(2020年1期)2020-12-06
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
北京心理卫生协会学校心理卫生委员会学术年会论文集(2018年1期)2018-05-10
青少年科技博览(中学版)(2017年10期)2018-01-19
公民与法治(2016年12期)2016-05-17
语文知识(2014年11期)2014-02-28
