
可扩展的数字电路在线演化架构设计
2022-08-16 03:11李元香
计算机工程与设计 2022年8期
聂 鑫,李元香
(1.武汉工程大学 计算机科学与工程学院,湖北 武汉 430205; 2.武汉大学 计算机学院,湖北 武汉 430072)
0 引 言
演化硬件(evolvable hardware,EHW)[1]在电子设计自动化、自适应以及容错[2]方面的优越性,有望使它成为突破传统电子设计领域瓶颈[3]的新技术。而基于虚拟可重构电路(virtual reconfigurable circuit,VRC)[4]实现的在线演化是当前研究的主要方向。Kyrre Glette和Jim Torresen利用嵌入式处理器进行演化操作,连同VRC共同集成在单片FPGA中,实现了单芯片演化系统[5]。Wang J,Chen QS等则用VHDL语言[6]来描述电路的演化行为,从而实现了纯硬件的电路在线演化,并且通过限制电路模块之间的连接来减少编码的长度[7]。Sekanina成功在FPGA platform-COMBO6 card上实现了图像滤波器的在线演化[8]。VRC中的各个演化模块目前均采用m×n的矩阵排列方式,各个模块中一般只定义了有限几个功能函数,在整个目标电路的演化过程中,各模块的功能只能从这些函数中选取,不能动态调整为新的功能函数,而且通常需要先通过大量的实验,确定一个较优的函数集。
本文在已有的在线演化平台模型[9,10]的基础上,对VRC中的各个单元模块提出了设计方法:①使用查找表(look-up-table,LUT)的方式来实现模块的函数功能,并通过多路选择器来连接位于其前列的模块,从而丰富了各个模块的连线与函数功能多样性,乃至整个电路群体的多样性;②针对基于CGP编码[11]的数字电路演化设计的收敛性问题[12],提出了一种节点相对位置编码方式和不等概率的变异算子,使得不会由于染色体的随机交叉和变异而产生“非法个体”,且能够进一步淘汰掉节点连接深度较高的“较差个体”。实验结果表明,这一设计架构和算法的改进对提高数字电路演化的收敛性起到了良好的效果,并且同时能在较大程度上保证生成电路的多样性。对规模不大的目标电路的演化设计具有优势,特别适合于电路的局部容错与自修复[13]。
1 虚拟可重构电路
1.1 基于LUT的演化模块
LUT本质上就是一个RAM,它的原理是把数据事先写入RAM后,每当输入一个信号,就等于输入了一个地址进行查表,找出该地址对应的内容,然后输出。数字电路中的每一种组合逻辑都可以表示成一个LUT,如图1将一个组合逻辑的真值表用LUT来表示。
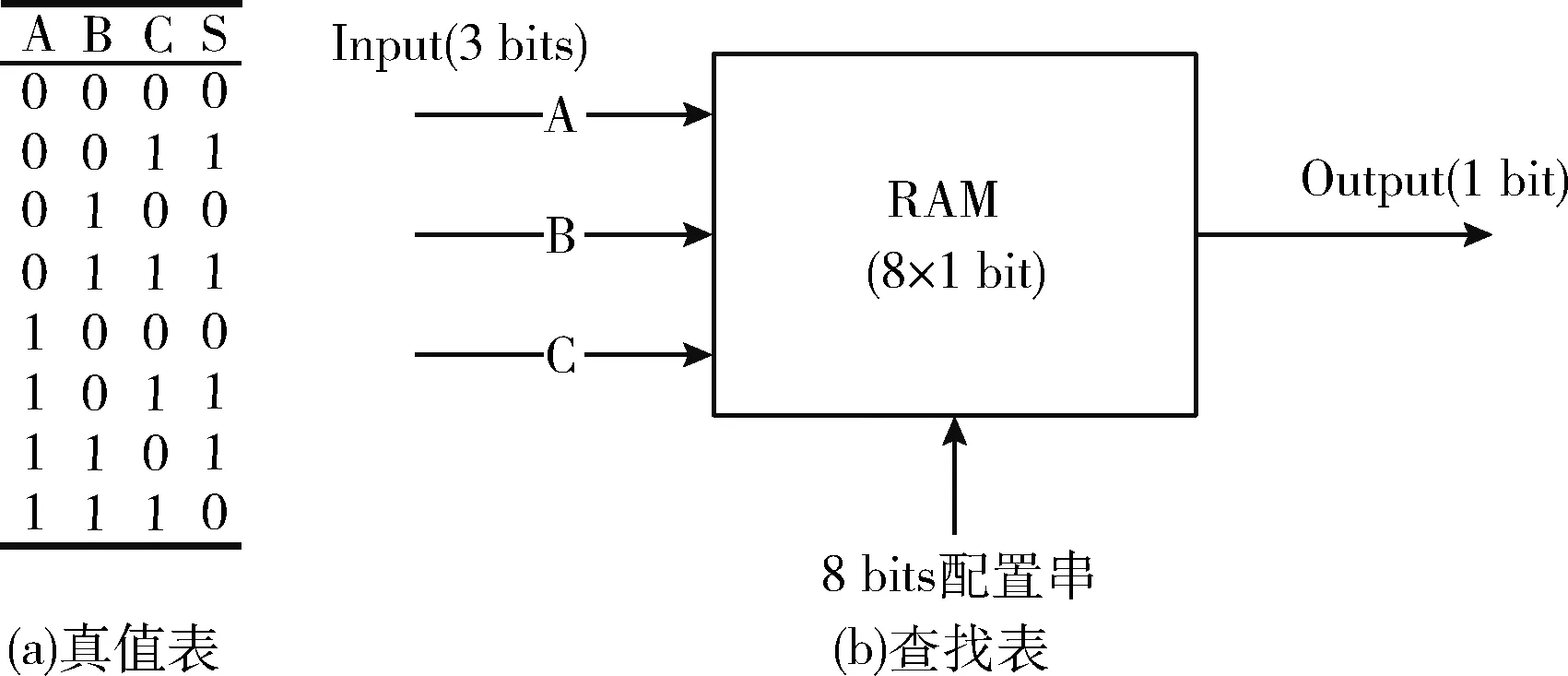
图1 组合逻辑电路的LUT表示法
当图1(b)中的8位配置串取图1(a)中的S序列时,该LUT就等效于这个组合逻辑电路所代表的功能。这种通过LUT来实现函数功能的方法,可以在电路演化过程中,通过改变配置串来动态调整该逻辑单元中所选择输出的函数功能。
此处设定每一个演化模块的LUT都是1 bit的n输入1输出,且模块的输入都能够与处于其前列的模块的输出相连接,这样,就需要在LUT前配置n个多路选择器(multiplexer,MUX)。一个由n个1 bit输入和1个1 bit输出的LUT,一共可以表示22n种函数。因此,考虑到函数功能的复杂程度和配置串的长度对搜索空间的影响,n的值通常取2或3,即演化模块中LUT的设计大多采用2输入或3输入的形式。例如:某一个3输入LUT的演化模块设计为能从处于其前列的8个模块中选择连接通路,则需要在该模块中配置3个8选1多路选择器,如图2所示。
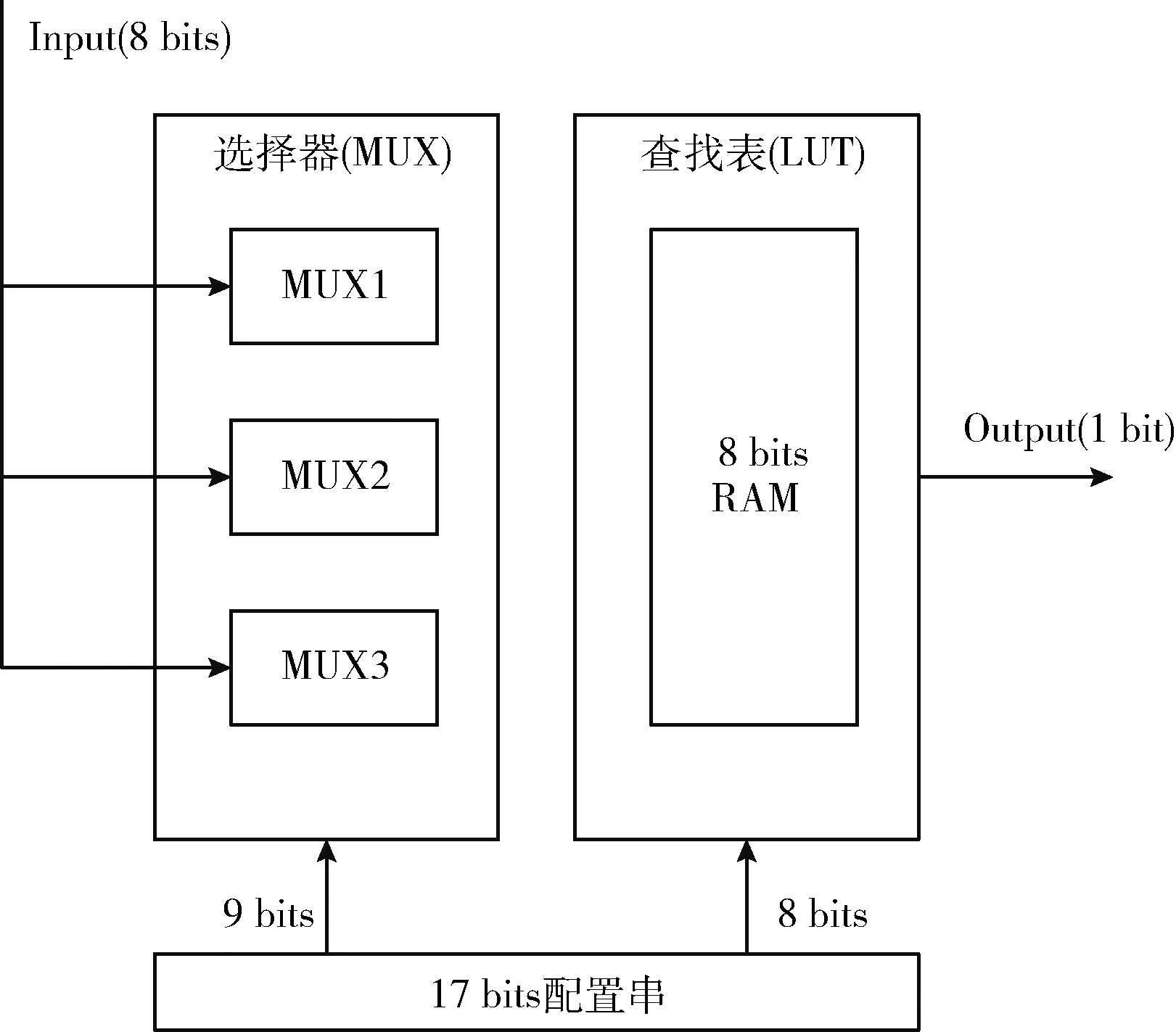
图2 基于LUT的演化模块
每个8选1多路选择器需要3位配置串来决定它的连线通路,所以对于这样一个演化模块,一共需要3×3+8=17 bits的配置串,即该模块的染色体长度为17。
1.2 可重构模块阵列
由以上多个可配置的演化模块组成的阵列便称为虚拟可重构电路。阵列的大小对硬件资源和系统性能都有着重要的影响,通常要经过多次的实验才能找到一个较优的组合方案。由于在标准CGP编码中,一个节点可以与其前面任意列上的节点连接,所以多路选择器的数据宽度将会增大,因而会极大扩展染色体的编码长度和搜索空间,不利于演化算法的最终收敛[14],后面会对这一问题进行深入的探讨。
将逻辑单元中的函数部分用LUT的形式来表示,其目的是为了使函数功能也能够用配置串的形式来表示,进而编码成染色体的一部分并执行演化操作。它能够使得在不需要先行设计具体函数模块的情况下,自动演化出所需要的目标电路。为了说明这种演化方式与函数级演化具有同样的有效性,首先通过在不同规模的虚拟可重构电路上演化两种测试电路来进行实验。
本文使用的FPGA是Xilinx公司生产的Xilinx大学计划Virtex-II Pro系列XC2VP30型开发板[15]。XC2VP30型开发板中提供了两个硬核(PowerPC 405),这两个硬核都是32位的精简指令集计算机(reduced instruction set computer,RISC)处理器。此外还提供了一个软核(Micro-Blaze processor),它的最高处理器频率和总线频率都是100 MHz,而PowerPC的处理器频率最高可达300 MHz。
系统开发的总体过程[16]与使用的各种软件工具如图3所示。
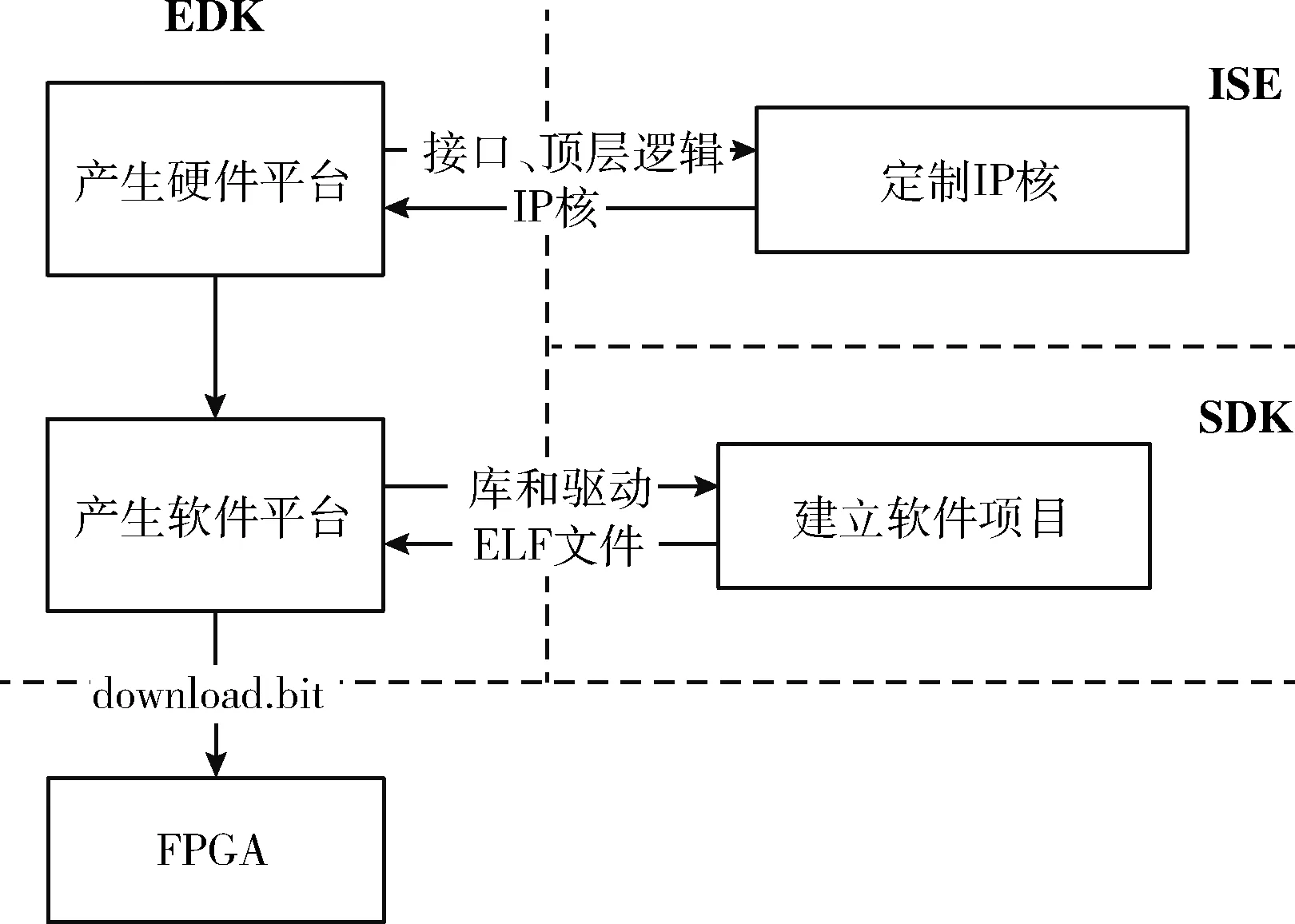
图3 系统开发总体
(1)加法器的演化
加法器是电路进化设计中常用的测试电路,分别用标准CGP编码采用函数级演化和LUT级演化来进行二位全加器的演化实验。函数级演化的函数集为{非,与,或,异或}。在上述两种演化策略中,分别构造4×4,5×5和6×6的演化阵列。设置的算法参数和演化算子完全相同,种群规模PopSize=128,最大迭代次数为20 000,变异概率Pm=0.1,采用大小为4的锦标赛选择算子[17]。表1和表2是10次运行中演化硬件找到目标电路的平均代数、设计成功的次数以及10次实验中最优电路的成本(活动节点的个数)。
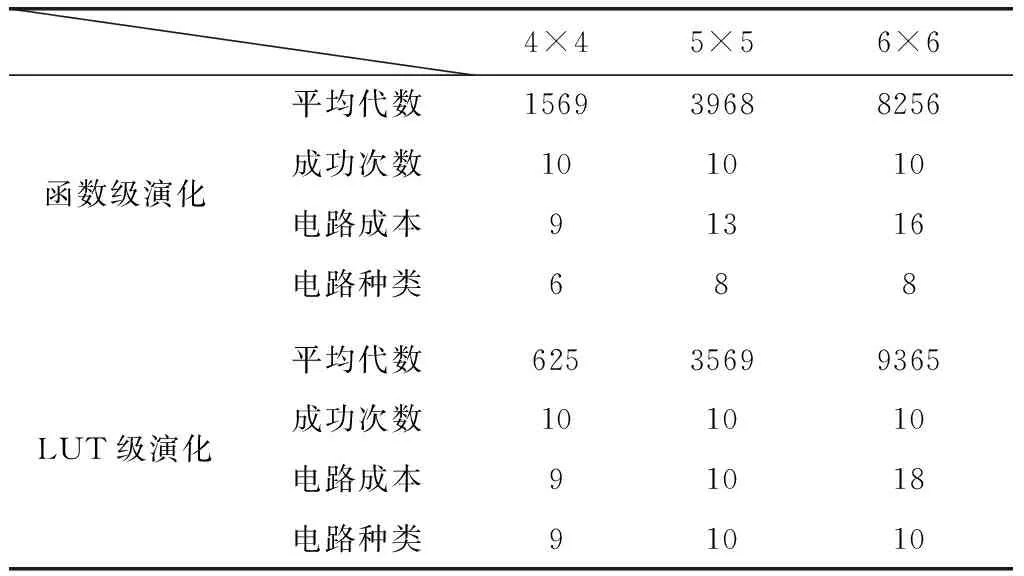
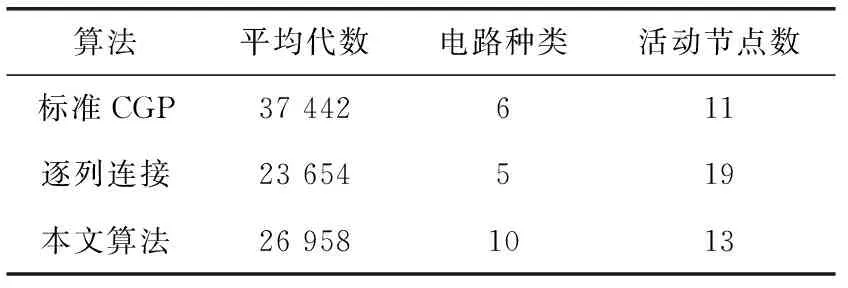
表1 演化设计二位加法器的实验结果
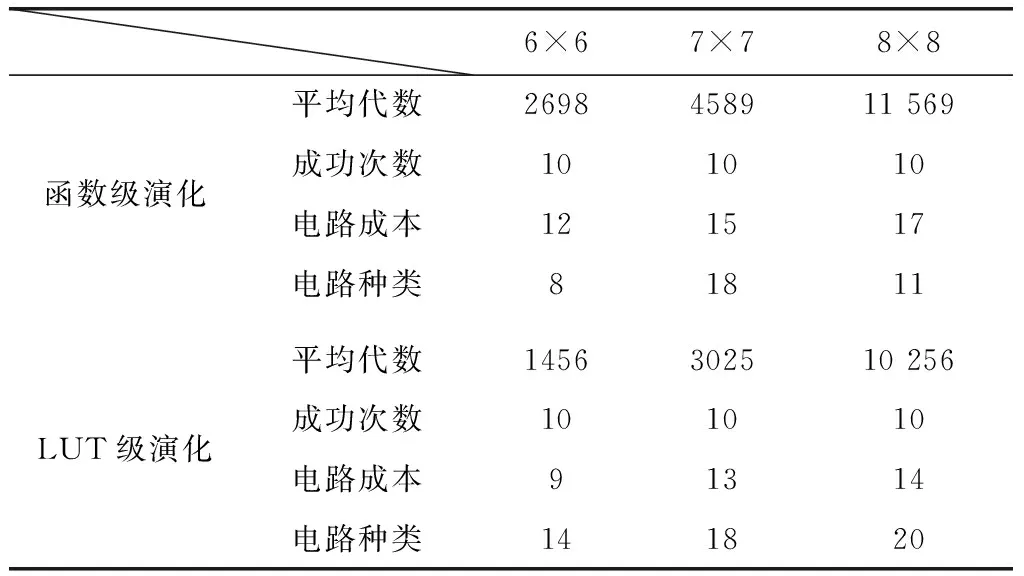
表2 演化设计三位加法器的实验结果
从表1和表2可以看出,在两种不同的演化平台上,均可以成功演化出目标电路。LUT级演化的演化效率甚至要优于函数级演化。这是因为在演化过程中,函数功能也能够同时做自适应调整的原因,但是这种演化效率的优势会随着目标电路逻辑功能的复杂以及演化平台面积的增大而急剧下降。
(2)乘法器的演化
二位乘法器是一个四输入、四输出的组合逻辑电路,分别用标准CGP编码采用函数级演化和LUT级演化来进行二位全加器的演化实验。采用与加法器演化实验相同的函数集。在两种演化方式下分别采用5×5,6×6和7×7的演化平台。演化算法的参数和算子完全相同,种群规模PopSize=128,最大迭代次数为50 000,变异概率Pm=0.1,采用大小为4的锦标赛选择算子。表3中是10次运行中演化硬件找到目标电路的平均代数、设计成功的次数以及10次实验中最优电路的成本(活动节点的个数)。
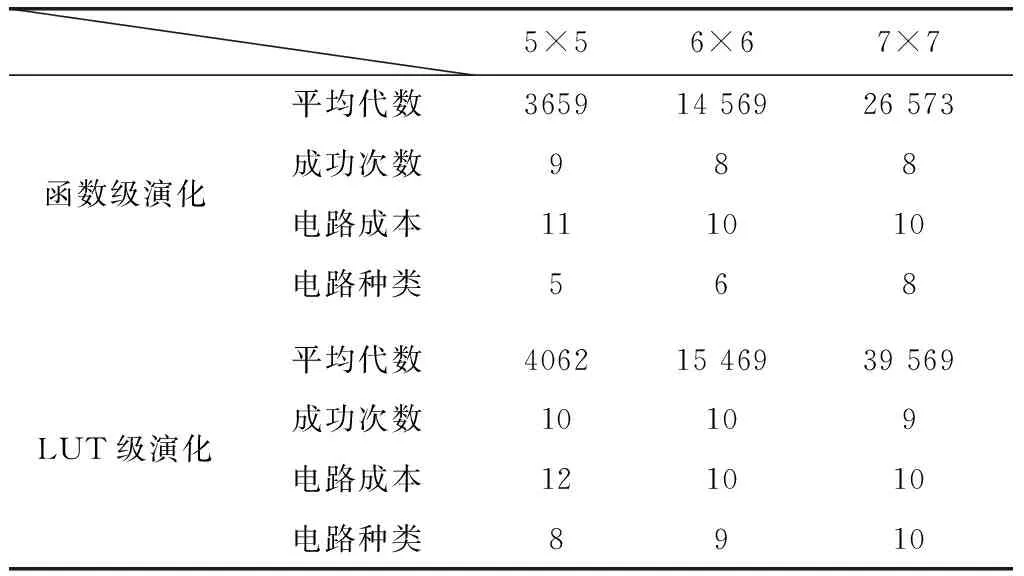
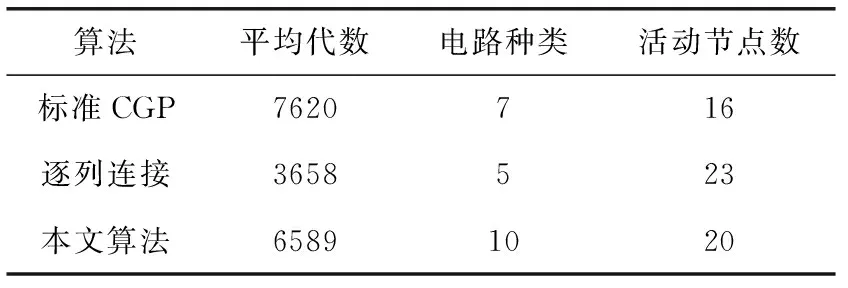
表3 演化设计二位乘法器的实验结果
从表3可以看出,在两种不同的演化平台上,对于逻辑功能较复杂的乘法器电路,LUT级演化同样具有很强的演化能力,其成功率往往高于函数级演化。但是演化平均代数却弱于函数级演化,说明由于其编码的特殊性,使得演化算法的收敛性降低。
(3)实验结果分析
通过以上两个实验获得的结果可以看出,基于LUT级的电路演化方法与基于函数级的电路演化方法具有同等的效力,最终均能够演化出期望的目标电路。但是LUT级演化具有以下3个方面的特点:
1)对于逻辑简单的加法器电路,LUT级演化所需要的平均代数要小于函数级演化,但是如果虚拟可重构电路的规模或电路的输入输出数量增大,见表3,这种优势会明显下降。因为对于简单的组合逻辑而言,随机变动函数功能会对目标电路的生成起到促进作用,但是当虚拟可重构阵列的规模扩大时,优于代表函数功能的染色体所参与的随机变异行为,会使得算法的收敛性呈下降趋势。
2)对于逻辑复杂的乘法器电路,LUT级演化所表现的这种收敛性下降趋势就更加明显。这时,预先定义基本函数单元的演化方式就比函数单元功能随机变异的演化方式有了某种优势。然而在电路演化的成功率上却相反,LUT级演化虽然收敛性下降,但是最终还是能演化出目标电路,而函数级演化由于函数单元的功能相对固定,因此在演化过程中容易陷入局部最优,而导致长期处于适应值停滞阶段,终而无法演化出目标电路。
3)在同等规模的虚拟可重构电路基础上,通过LUT级演化方式成功演化出的目标电路的种类要多于函数级演化方式,并且随着虚拟可重构电路规模的增大,生成电路的种类会更多。显然是因为LUT级演化中,函数集并非确定的,在演化过程中,会有很多新颖的函数进来参与组合电路的生成,所以生成电路的多样性大大的增强,而这一特性,对于将演化硬件用于容错系统的设计有着非常积极的意义。
2 电路演化效率的关键因素
电路演化的效率体现在两点:演化算法的收敛性和电路演化的成功率。其中算法的收敛性与染色体的编码和演化算子的设计有密切的关系。在CGP编码中,对节点的编码方式和染色体的演化算子的改进,成为有效提高电路演化效率的方法之一。
2.1 相对节点位置编码
演化算法在求解问题时,对潜在解采用的交叉和变异操作有可能会产生非法个体,即不满足客观环境的无效解。演化硬件同样如此,在设计演化算子时如何避免产生非法个体是首要考虑的问题。在CGP编码中,我们尽管在生成初始化种群的过程中采取措施保证随机生成的所有个体都是合法的电路,但是随后的演化过程却极容易导致非法电路。
究其原因,在前文中已经提到,是由于每个逻辑单元的连接编码的变异范围不一致所导致。因此,如果能够使得连接编码的范围一致,这个问题便会迎刃而解。
文献[18]证明了在组合逻辑中,任何的组合逻辑函数都可以通过增加了节点的连接层次但是不改变其逻辑功能,将节点的连接深度缩小,并不损害对目标电路的求解的完备性。因此,文献[19]中将CGP函数级演化中节点的连接方式限制为逐列连接。这种逐列连接的方式结构固然简单,但很可能造成在最终的得出电路中大量的模块没有被实际利用。如前所述,由于每一个模块的实际连接数一般为2或3,所以对于一个要求由m bits输入的模块组成的阵列,m的值越大,就越可能有更多的模块没有被实际连接。同时,每一个模块由于只有一个输出,且只能被紧随其后的那一列模块所连接,模块的功能没有被多列复用,也是造成许多模块被“浪费”的重要原因,而且也会限制电路种群的多样性。
采用相对节点位置编码的一个必要条件是每个逻辑单元的连接深度必须一样。因此,本文对虚拟可重构电路中逻辑单元之间的连线方式做出了限制,令每个逻辑单元向前连接的最大深度为2,如图4所示。
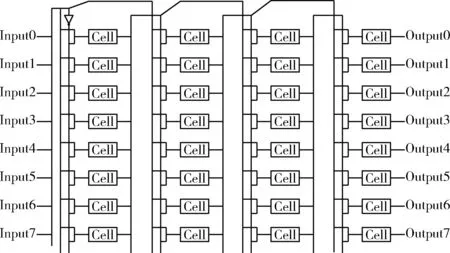
图4 固定连接深度的虚拟可重构阵列图
设定每一列中的模块都可以与其前两列中的模块相连,即每一列模块的输出,都可以被其后两列的模块所复用。这样,在一个由m行n列构成的阵列中,每个模块的输入就是2×m bits,每个模块中的多路选择器为2×m选1。
例如,设计一个8×5的虚拟可重构电路,由于每列均可与前两列相连,所以每个模块中将是16选1的多路选择器。对于第一列,由于输入信号只有8位,所以需另外构造8位数据,组成16位信号输入到第一列,供多路选择器选择,这里采用加入一个非门的形式,先将输入信号翻转,然后再与原信号组合,输入第一列;对于第二列,模块的输入信号则是第一列的输出结果加上原始输入信号;之后的各列,均由前一列的输出信号加上更前一列的输出信号组成输入信号。如图5所示。
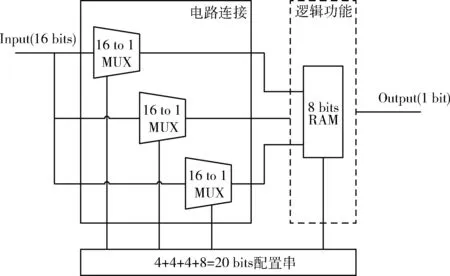
图5 改进后的逻辑单元结构
这样改进了连线方式与编码方案有以下几个优点:
(1)可以保证每一个逻辑单元的连线部分的配置串,其取值范围相同,这样在进行演化操作时,不会产生非法个体,不需要浪费时间对其取值进行约束,和对该个体进行评价,有利于加快演化速度。
(2)从某种程度上保持生成电路的多样性,不完全将高连接深度的目标电路从解空间中排除。
(3)能在一定程度上减少活动节点的覆盖率,这同样是因为保证了一定的高连接深度的目标电路的生成。
每个16选1多路选择器需要4位配置串来决定它的连线通路,所以对于这样一个演化模块,一共需要3×4+8=20 bits的配置串,即该模块的染色体长度为20,如图6所示。
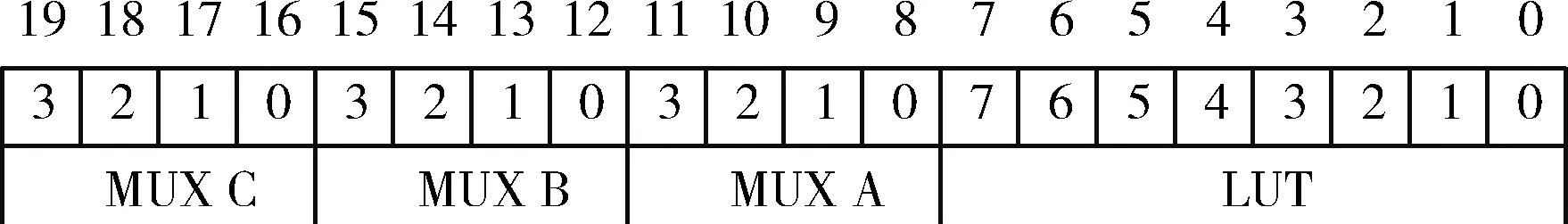
图6 染色体的组成
2.2 不等概率变异算子
文献[20]证明了越是逻辑功能复杂的数字电路,其节点的平均连接深度往往越低,即复杂的逻辑函数,需要靠更多层次的节点连接才能实现,因若能在演化过程中对符合这种特征的染色体进行优先选择将有利于提高收敛速度,有利于电路的快速生成。
因此,本文在采用演化策略时引入一种新的变异算子(unequal probability),使得逻辑单元能以不同的概率与位于其前列的其它逻辑单元相连接,如果两个逻辑单元离得较近,则连接的概率越高,反之越低,即每一个逻辑单元的变异策略均倾向于低连接深度。这种变异算子的改进能够大大降低演化算法的搜索空间,排除出不符合这一特征的“较差个体”,从而加快电路演化的收敛速度,且同时能够保持一定的生成电路的多样性,也就是在创造性设计和演化收敛速度之间达到一种平衡。
这种变异算子的核心思想是在染色体变异时,并不是随机地改变表示逻辑单元之间连接的基因位,而是那些在阵列中离的近的节点之间相互连接的概率就越大。设用于虚拟可重构电路由m行n列的组成,为了防止反馈循环,故只允单向连接。
令Cj表示位于阵列中的第j列的逻辑单元; P(j,i) 表示第j列的逻辑单元连接到位于其前i列的逻辑单元的概率,有:
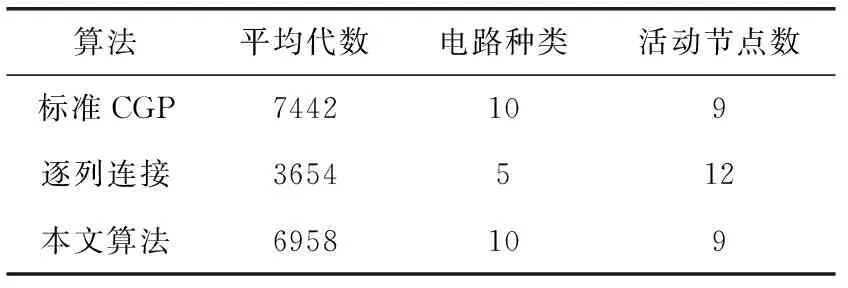
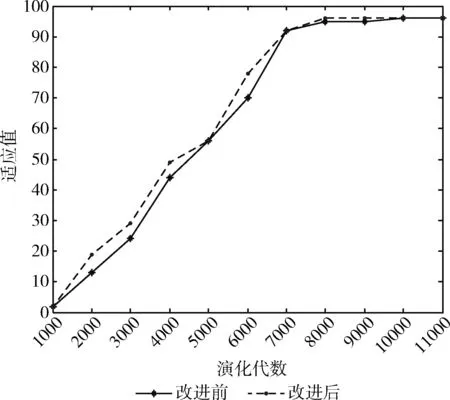
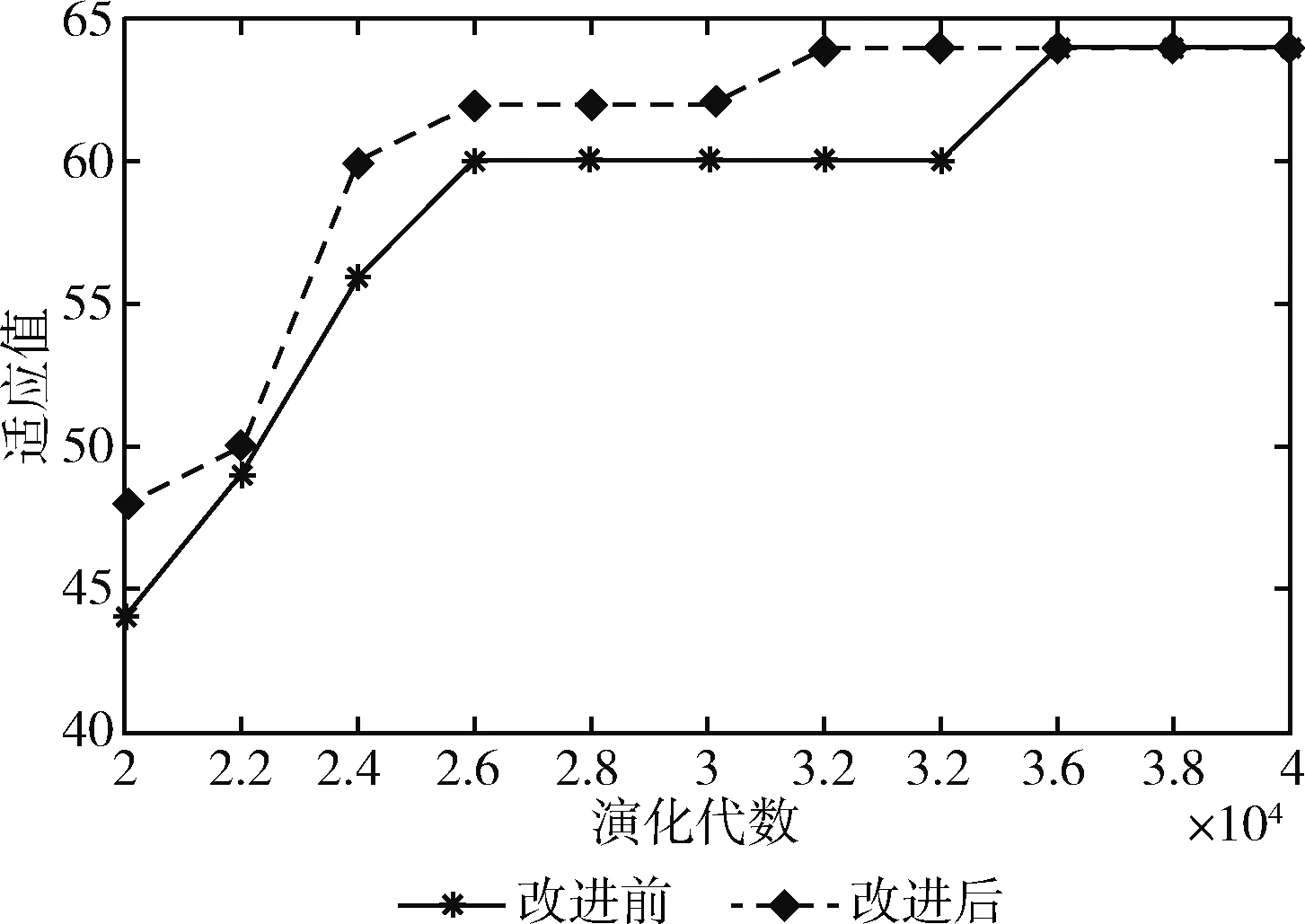
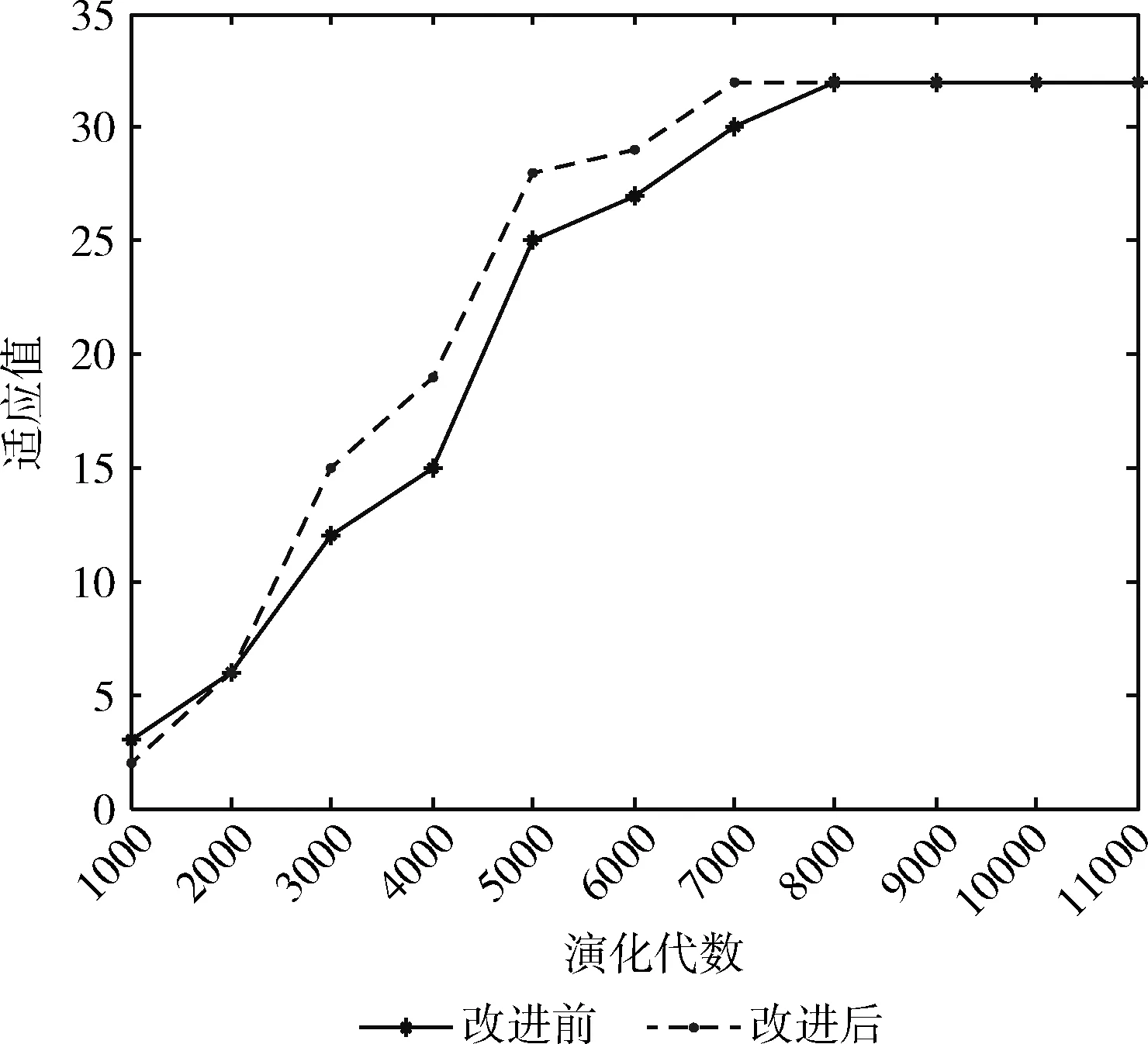
若i1>i2,则P(j,i1) 图7展示了不同连接深度的基因位所具有的不同的遗传概率,即连接深度较高的个体将具有较小的概率被选择进入下一代种群。该算子在演化算法过程中的实现步骤为: 图7 连接编码的不同变异概率 (1)分析染色体的组成,找到每个染色体中,表示逻辑单元连接的基因位,如图6所示的染色体中,第19~第8位这些基因,代表了逻辑单元的连接编码; (2)分析第(1)步中找到了每一位基因的值,是否大于某个值,此值表示的是前一列的输出节点个数。例如2.1节提出的8×5的虚拟可重构电路,如果基因位大于7,则表示该输入接口连接的是前2列上的某个输出节点,而如果基因位小于等于7,则表示该输入接口连接的是前1列上的某个输出节点; (3)对于连接值偏大的基因,给予更高的变异概率,使其能够调整为低连接深度,对于连接值偏小的基因,给予更低的变异概率,使其能够保持当前的低连接深度; (4)在演化算法选择操作时,优先选择具有更多低连接深度基因的个体,例如采用锦标赛选择算子时,可以将低连接深度基因的个数,作为锦标策略。 通过以上对逻辑单元的连接深度、染色体编码和变异算子3个方面的改进,其目的是在既保证生成电路的多样性的同时,也能提高电路演化的收敛速度。下面通过3个目标电路的演化实验来验证这一新的电路演化设计方法的有效性。 (1)加法器的演化 在前文提出的基于LUT设计的逻辑单元的基础上,采用8×4的虚拟可重构阵列结构。种群规模PopSize=128,最大迭代次数MaxGeneration=50 000,与前一列节点连接的变异概率Pm=0.1,与前两列节点连接的变异概率Pm=0.05,采用大小为4的锦标赛选择算子。表4中是3种不同算法下演化硬件找到目标电路的演化算法平均运行代数、找到的不同电路结构个数以及最优电路的成本(活动节点的个数)。 表4 改进后演化设计二位全加器的实验结果 图8比较了演化设计二位全加器时,改进后的算法与标准CGP编码在算法收敛性上的差异。 图8 演化设计二位全加器的算法收敛性 (2)乘法器的演化 在前文提出的基于LUT设计的逻辑单元的基础上,采用8×8的虚拟可重构阵列结构。种群规模PopSize=128,最大迭代次数MaxGeneration=50 000,与前一列节点连接的变异概率Pm=0.1,与前两列节点连接的变异概率Pm=0.3,采用大小为4的锦标赛选择算子。与表4中的各项性能指标含义相同,实验结果见表5。 表5 改进后演化设计二位乘法器的实验结果 图9比较了演化设计二位乘法器时,改进后的算法与标准CGP编码在算法收敛性上的差异。 图9 演化设计二位乘法器算法收敛性 (3)奇偶校验电路的演化 奇偶校验电路也是目前最常用的用于演化硬件测试的组合逻辑电路。下面以四位奇偶校验电路为例来进行实验。 在前文提出的基于LUT设计的逻辑单元的基础上,采用8×4的虚拟可重构阵列结构。种群规模PopSize=128,最大迭代次数MaxGeneration=50 000,与前一列节点连接的变异概率Pm=0.1,与前两列节点连接的变异概率Pm=0.05,采用大小为4的锦标赛选择算子。实验结果见表6。 表6 改进后演化设计四位奇偶校验电路的实验结果 图10比较了演化设计四位奇偶校验电路时,改进后的算法与标准CGP编码在算法收敛性上的差异。 图10 演化设计四位奇偶校验电路的算法收敛性 通过比较分析上述3个实例的实验结果,我们可以得出如下结论: (1)对于相同规模的目标电路,改进后的算法比其它两种演化能得到更多的不同结构的目标电路。虽然连接深度的减少又会对生成电路多样性产生负面影响,但逻辑单元所实现的具体的功能也在不断的演化,所演化出的函数功能更加丰富,不拘泥于某几个固定的函数,能够同时搜索出最优的连接与函数的组合。因此,对生成电路多样性的保持起到了良好的作用。 (2)算法的收敛性上,逐列连接的效果是最好的,但却以牺牲更多的冗余资源为代价,活动节点的个数最多,且生成电路的种类却最少。而本文改进的方法在这两个方面进行了折中考虑,既保持了电路的多样性,在演化算法收敛性上,也比CGP编码方式有了明显提高。 (3)通过实验发现,虽然有一些“较优”的个体,只需要很少的连接深度即可以实现目标电路,对冗余资源的消耗最少,然而这样的个体是很少数的,且要演化出这样的结果,往往需要耗费大量的时间,因此,这样的演化目标,是不适合于电路的容错自修复的。而通过较少连接层次实现的目标电路,通过多消耗一定的冗余资源为代价,能够快速提高电路演化的收敛性,这种在冗余资源的消耗量和电路收敛速度上的同时“优化”,特别适合于电路的容错与局部自修复。 最后。对于规模不大但逻辑较为复杂的电路,采用LUT级演化方法都能快速有效地得到相应功能的电路。但是随着电路规模的增大,例如图像空域滤波器电路,直接使用LUT级演化方法也不能得到理想的结果,原因主要有两点:第一,因为每个逻辑单元中的LUT的输入引脚和输出引脚都是1 bit的,而图像空域滤波器电路的输入引脚共有8×9=72 bit,此时只有极大的扩充虚拟可重构电路的规模,才能满足运算的需要,但是图像的每个像素点的8 bit数据是一个整体,在LUT上进行的运算的粒度太细,既无必要,也极大浪费搜索时间。第二,如果将LUT的输入和输出的位宽扩大,虽然扩大了LUT的运算粒度,但是其配置串会呈指数级增长,同样无法演化出所期望的电路。但LUT级演化设计方法可以快速生成局部子电路,可以通过这种方式来动态调整函数的功能,易于跳出演化过程中局部最优,这对解决电路的收敛性问题将发挥很大的积极的作用。并且将LUT级演化与本章提出的演化算法相结合,在演化小规模电路中所体现的优越性,对于实现大规模电路中的局部容错系统的设计有着积极的意义。 本文在对演化硬件在线演化方法已有研究的基础上,提出了一种数字电路的函数级演化方法,将虚拟可重构电路中逻辑单元的函数功能采用LUT的方式实现,可以使得函数功能也能编码为染色体,进而参与演化操作。该方法可以在无需事先针对目标电路进行分析的前提下,实现数字电路的演化。实验结果表明,这种实现方式与传统函数级演化方法具有同样的有效性,并且由于函数功能也能参与演化,因而有利于提高生成的目标电路的多样性。从生成电路的多样性和电路演化的收敛速度等方面考虑,设计了相应的虚拟可重构电路结构以及演化算子。最后,用3个实例验证了上述方法的有效性,通过实验分析比较得出改进后的电路演化设计方法,对规模不大的目标电路设计具有优势,特别适合于电路的局部容错与自修复。最后文中分析并指出了下一阶段要研究的目标,即在目标电路为逻辑较复杂的大规模电路时,可以采用电路分解模型,分解出一定数量的等效子电路集合,而利用LUT级演化设计方法可以快速生成这些局部子电路,其在演化小规模电路中所体现的优越性,对于实现大规模电路中的局部容错系统的设计有着积极的意义。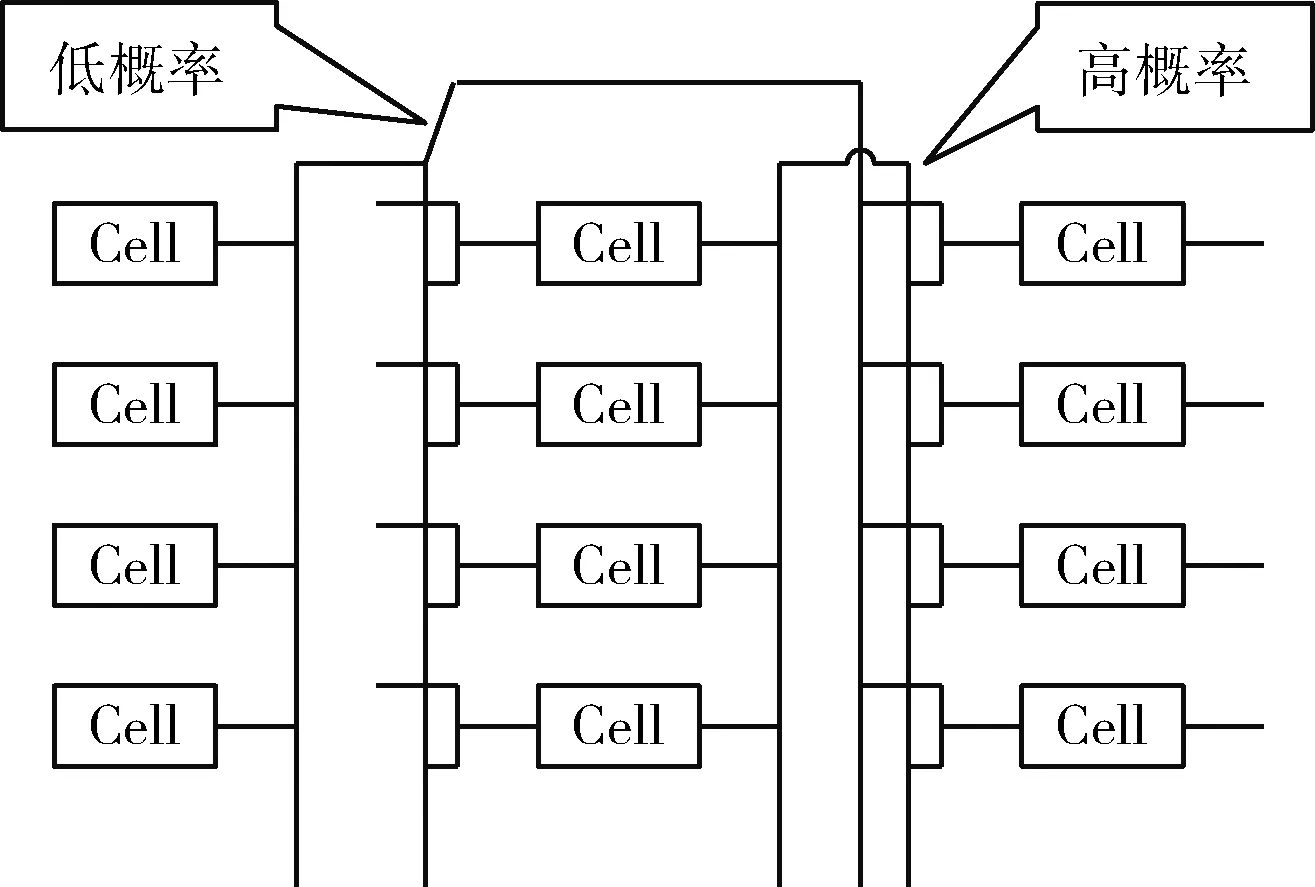
3 实验与分析
3.1 实验与算法设计
3.2 实验分析
4 结束语
猜你喜欢
法律方法(2022年2期)2022-10-20
数学物理学报(2022年5期)2022-10-09
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
中国生殖健康(2020年7期)2020-12-10
校园英语·上旬(2020年1期)2020-05-09
37°女人(2017年11期)2017-11-14
卷宗(2017年16期)2017-08-30
