
基于YOLOv3与CRNN的自然场景文本识别
2022-08-16 03:27吴启明宋雨桐
计算机工程与设计 2022年8期
吴启明,宋雨桐
(1.河池学院 计算机与信息工程学院,广西 宜州 546300; 2.华中科技大学 计算机科学与技术学院,湖北 武汉 430074)
0 引 言
自然场景中文本区域偏转角度及文本区域边缘复杂多样,而且受限于采集图像时光照环境和采集设备的性能,图像中会包含一些噪声数据,影响了最终识别效果。因此,寻找一种在自然场景中的文本检测与识别技术显得尤为重要。
文本检测与识别技术在国内外已经有相关团队和学者在研究[1-6],比如Jiri Matas团队,视觉几何团队(VGG)以及微软亚洲研究院(MSRA)等,学者中有华南理工大学金连文教授、华中科技大学白翔教授、中国科学院大学叶齐祥教授等,他们在自然场景文本检测研究中获得了重大成果。
为了降低自然场景中图像包含的噪声以及文本区域偏转角度对识别效率的影响,本文借鉴了已有成果后提出使用YOLOv3[7]与CRNN[8]模型解决在自然场景下中文和英文文本的检测与识别问题。降低文本区域偏转角度对识别效率影响的具体实现为,在一系列固定宽度的文本框中使用文字朝向检测算法,检测出朝向为0、90、180、270度文本框,再使用小角度估算函数对其它角度的文本框进行微调[9]。然后使用YOLOv3检测单个固定宽度的小文本框,并采用文本框聚类算法连接这些小文本框,以此获得完整的文本检测框。最后使用CRNN模型识别这些文本检测框中的内容,为了解决识别结果文本行中没有空格的问题,采用Viterbi算法[10]对英文文本进行分词,增强阅读体验。为了提高实验的说服力,本文在相同的实验场景中把CTPN[11]与DenseNet模型和YOLOv3与CRNN模型的检测与识别结果进行对比分析,进一步验证YOLOv3与CRNN模型在自然场景文本检测识别任务中的优越性。为了展示检测与识别结果,本文设计了文本检测与识别系统,方便给用户呈现识别检测结果。
1 算法实现
1.1 文字朝向检测算法
先采用VGG16网络模型进行迁移训练检测文字朝向。VGG16网络模型见表1,共有5段卷积层,前2段(B1、B2)有2个卷积层,后3段(B3、B4、B5)有3个卷积层,每段结尾连接最大池化层(MP)来缩小图片尺寸,最终由两个全连接层(F1、F2)及softmax进行四分类角度(0°,90°,180°和270°)预测。
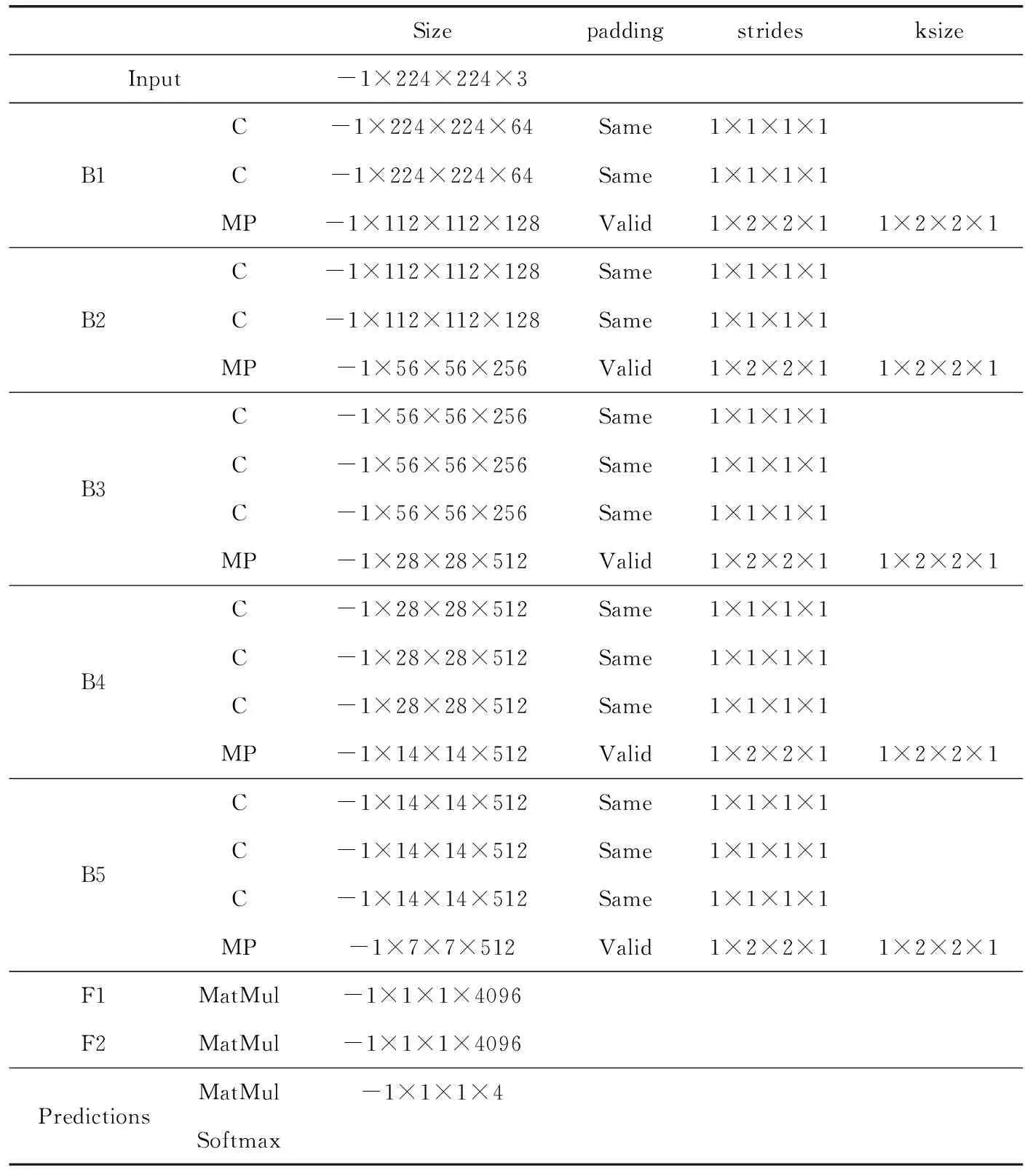
表1 VGG16网络模型具体参数
首先要对图像预处理,需要去除噪声并剪切,最终输出尺寸为(224,224,3)的图像,接下来进行零均值化处理,处理完的图像加载到VGG16网络输入层(Input),用于预测文字朝向并旋转调整。VGG16模型实现框架为keras,初始学习率为0.000 01,损失函数为交叉熵函数,优化方法为随机梯度下降法,在此基础上使用10万张图片训练模型并进行测试,实验准确率为95.10%。
图1为未加入文字朝向检测算法与加入文字朝向检测算法的结果对比。除四分类角度(0°,90°,180°和270°)外其它角度,本文采用小角度估算函数预测并旋转图像,为了保证计算速度规定只能在(-15,15)度范围内调整。

图1 文字朝向检测算法使用结果对比
倾斜角度计算步骤为,首先将图像灰度化,同时等比例缩放到(600-900)像素范围内。然后进行归一化处理。最后计算每行图像的均值与方差向量,如果图像中没有文本倾斜情况,此时方差最大,对应的角度就是倾斜角度。
1.2 YOLOv3文本区域检测算法
1.2.1 YOLOv3模型文本检测网络框架
传统YOLOv3目标检测算法更适用于一般物体的检测,将其用于自然场景文本文字检测任务中并不能发挥其优势。相对于自然场景中的常规物体,自然场景中的文本行长度、尺寸比例更加复杂多样,为文本行定位增加了难度。为了解决上述问题,先检测单个固定宽度的小文本段,继而再将这些小文本段聚类,得到一条文本行。
图2为YOLOv3网络结构,其中使用75个卷积层来分析文本特征。而且网络结构不包含全连接层,所以可以输入任意大小的图像。此外整个YOLOv3结构中也没有出现池化层,因此通过调整卷积核的步长stride=(2,2) 来替代池化层实现下采样的效果,并且往下一层传递时尺度不变。同时YOLOv3通过借鉴ResNet网络对残差信息的学习方式来优化检测速度。
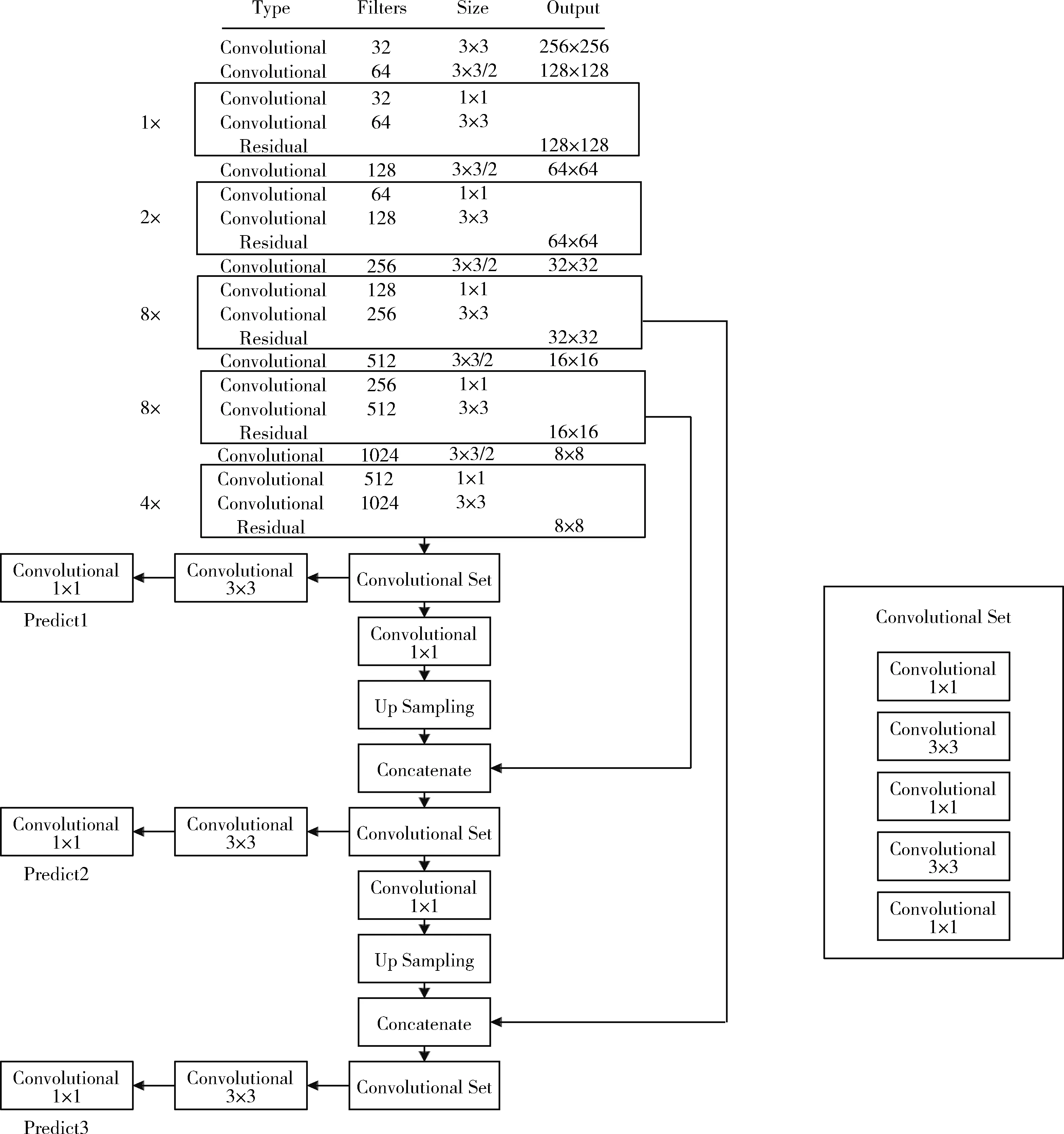
图2 YOLOv3文本检测网络结构
同时为了提高检测精度,本文也借鉴了类似FPN网络的思路,首先将每种尺度预测3个边界框,然后按照anchor设计方式得到9个聚类中心,最后将这9个聚类分给3个尺寸的边界框。
1.2.2 YOLOv3模型训练
(1)环境配置
实验环境配置如下:
实验采用的硬件环境为12 G内存,i7处理器windows 10 ×64;CUDA 8.0.61;CUDNN 5.1.10;开发环境为python 3.6;编辑环境为Pytorch 1.0.1;调用的函数库为opencv 3.4.2.16;开发框架为keras 2.1.5。
(2)训练数据集


图3 txt格式标签
由于YOLOv3模型限定输入文件格式为xml,因此本论文使用python程序将txt格式的标签文件转换为xml格式标签文件,最终效果如图4所示。可以看出xml格式标签文件中包含了文本的分类标签、文本区域起始点的坐标、文本图像的大小、文本的内容、文本区域偏离起始点的角度及文本区域长宽。为解决在识别过程中出现的中文乱码显示问题,首先将xml格式的文本采用HTML实体编码,然后再解码成汉字。

图4 xml格式标签
(3)模型训练
基于keras和tensorflow加载YOLOv3模型实现迁移学习。cluster_number为9,最小分隔宽度值为8, scales[416,512,608,608,608,768,960,1024],迁移训练完成后再通过K-means进行计算,得出anchors为 {8,11, 8,22, 8,34, 8,49, 8,70, 8,98, 8,142, 8,228, 8,522}。
使用GPU训练YOLOv3模型,设置输入图像尺寸为608×608,初始学习率为0.001,训练过程中按0.1倍进行调整。epoch设定为100,batch_size设定为32。经过实验得出YOLOv3的loss和confidence_loss值如图5所示。
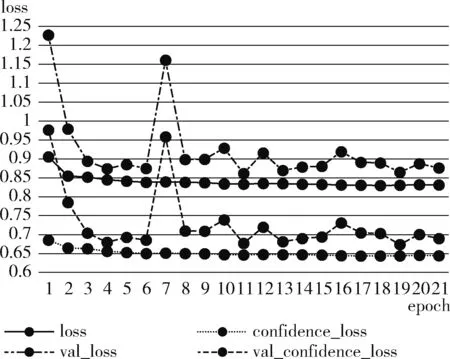
图5 YOLOv3的loss值和confidence_loss值
由图5可知,YOLOv3模型在训练过程中,loss由0.9056降至0.8313后波动逐渐减小,confidence_loss由0.6857降至0.6443后波动逐渐减小,说明loss值随着训练次数的增加有序下降,最终趋于收敛。相对而言验证集的损失值曲线val_loss波动幅度较大,但随着迭代次数的增加最终趋于收敛,表明YOLOv3模型在ICDAR2017数据集中的检测效果趋于稳定。最终将训练好的YOLOv3模型用于检测,结果如图6所示。

图6 YOLOv3模型检测出的text_proposal
1.3 文本框聚类算法
YOLOv3模型输出一系列固定宽度的文本框,然后将这些固定宽度的文本框采用文本线构造算法连接起来。
假设某图有图7所示的A文本框和B文本框,采用如下算法构造文本行:
(1)按x坐标对文本框index依次排序;
(2)计算每个固定宽度的文本框boxi的pair(boxi), 组成pair(boxi,boxj);
(3)通过pair(boxi,boxj) 建立连接图,最终得到一个文本检测框。
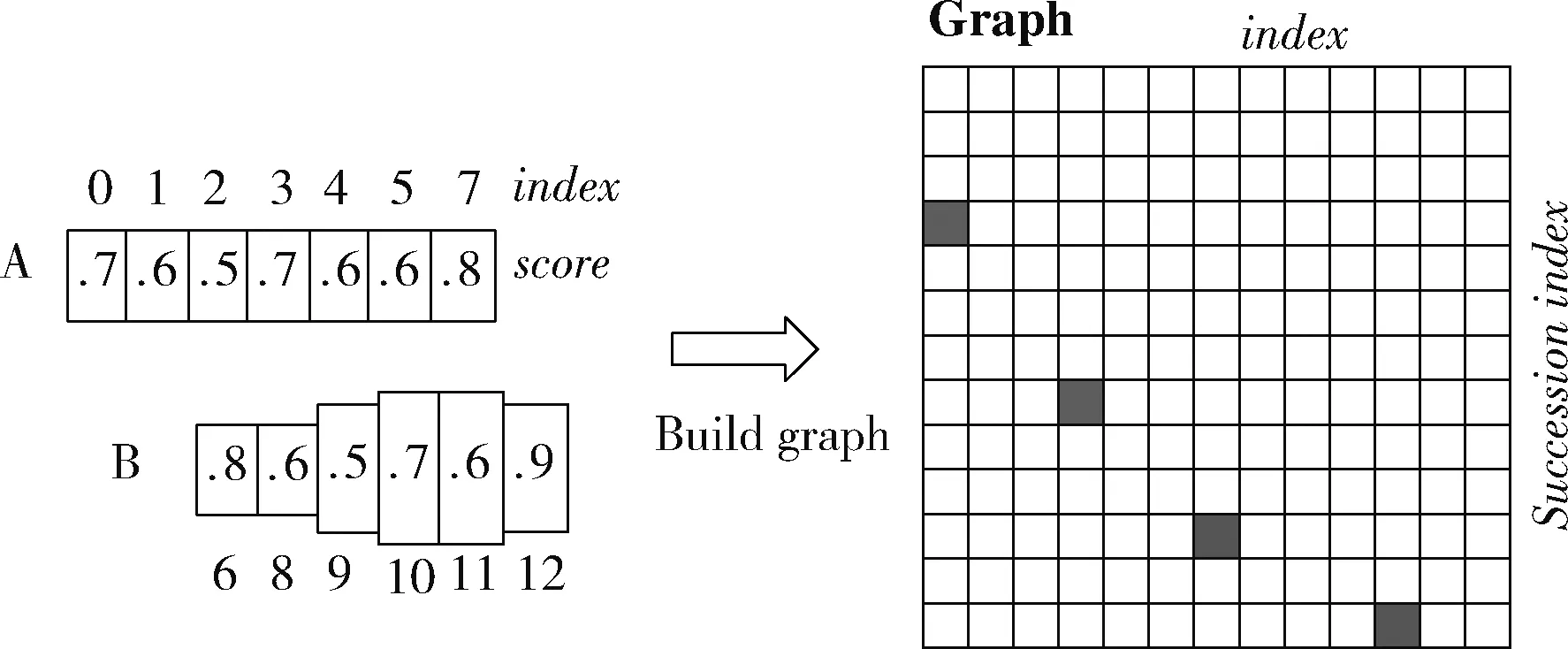
图7 文本框聚类算法构造文本行
文本框聚类算法建立文本框boxi的pair(boxi,boxj) 步骤为:
(1)正向寻找
1)寻找在水平正方向上与文本框boxi距离小于50的文本框为候选文本框集合;
2)从步骤1)的候选文本框中挑出满足boxi水平方向overlapv>0.7的文本框;
3)从步骤2)的文本框中挑出满足softmax score最大的boxj。
(2)反向寻找
1)寻找在水平正负方向上与文本框boxi距离小于50的文本框为候选文本框集合;
2)从上述步骤1)的候选文本框中挑出满足boxi水平方向overlapv>0.7的文本框;
3)从上述步骤2)的文本框中挑出满足softmax score最大的boxk。
(3)对比scorei和scorek
判断scorei≥scorek是否为最长连接,如果是最长连接,设置Graph(i,j)=True; 否则将继续寻找该连接所在的最长连接。
在进行文本区域检测时,借鉴“微分”思想将待检测文本分割成一系列等宽的文本框,然后再由文本线构造算法合并成一个图8所示的完整文本检测框。

图8 检测的文本框聚类结果
1.4 CRNN文本识别算法
主要研究基于CRNN的自然场景文本识别,CRNN可在不依赖词典的情况下实现识别不定长文本序列。研究发现基于CRNN的自然场景文本识别任务准确率较高。
1.4.1 CRNN文本识别算法原理
CRNN文本识别算法在自然场景的文本识别中集成了特征提取、序列建模和转录功能。
如图9所示在自然场景文本识别中CRNN包括了卷积层(Conv)、循环层(ReCurrent Layers)和转录层(Transcription Layers),主要用于特征提取、序列建模和转录功能。
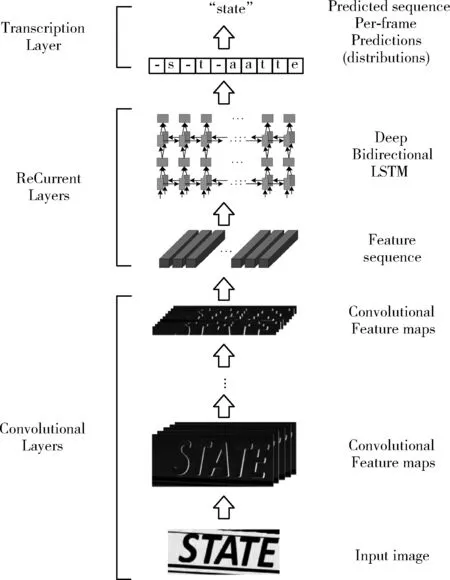
图9 CRNN识别原理
首先在卷积层中获得输入图像的特征序列,然后在循环层中对这些特征序列进行每帧预测,最后在转录层将其转换成标签。
图9的卷积层(Conv)中包含Conv和MaxPool,用于将输入图像(32,100,3)变成一组卷积特征矩阵(1,25,512),然后用BN网络对这些卷积特征矩阵进行归一化。图10所示归一化后的特征向量与特征图之间一一对应且从左向右依次排列。
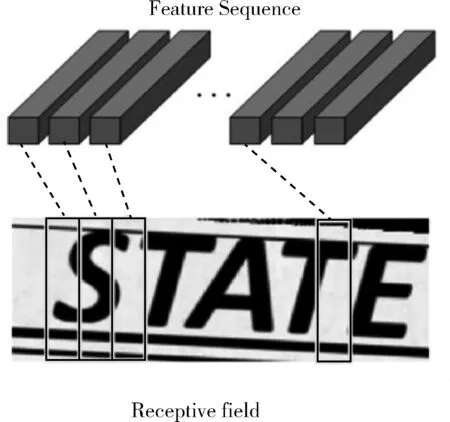
图10 特征序列
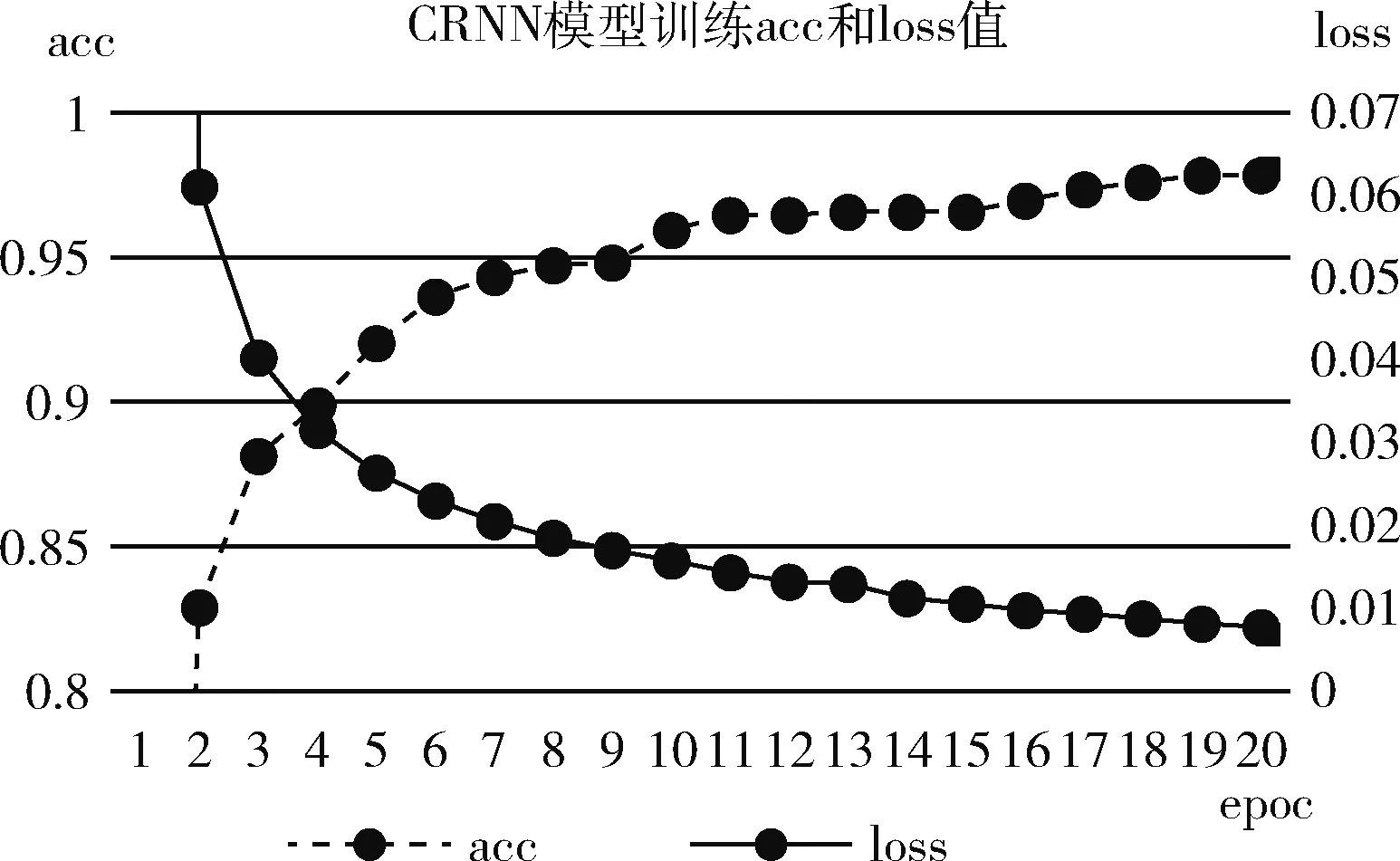
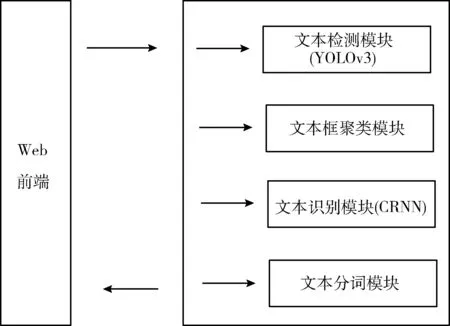
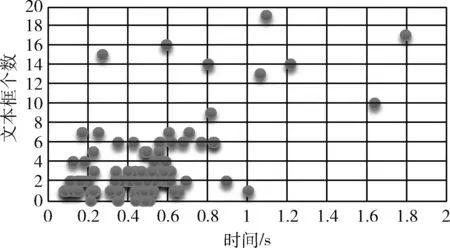
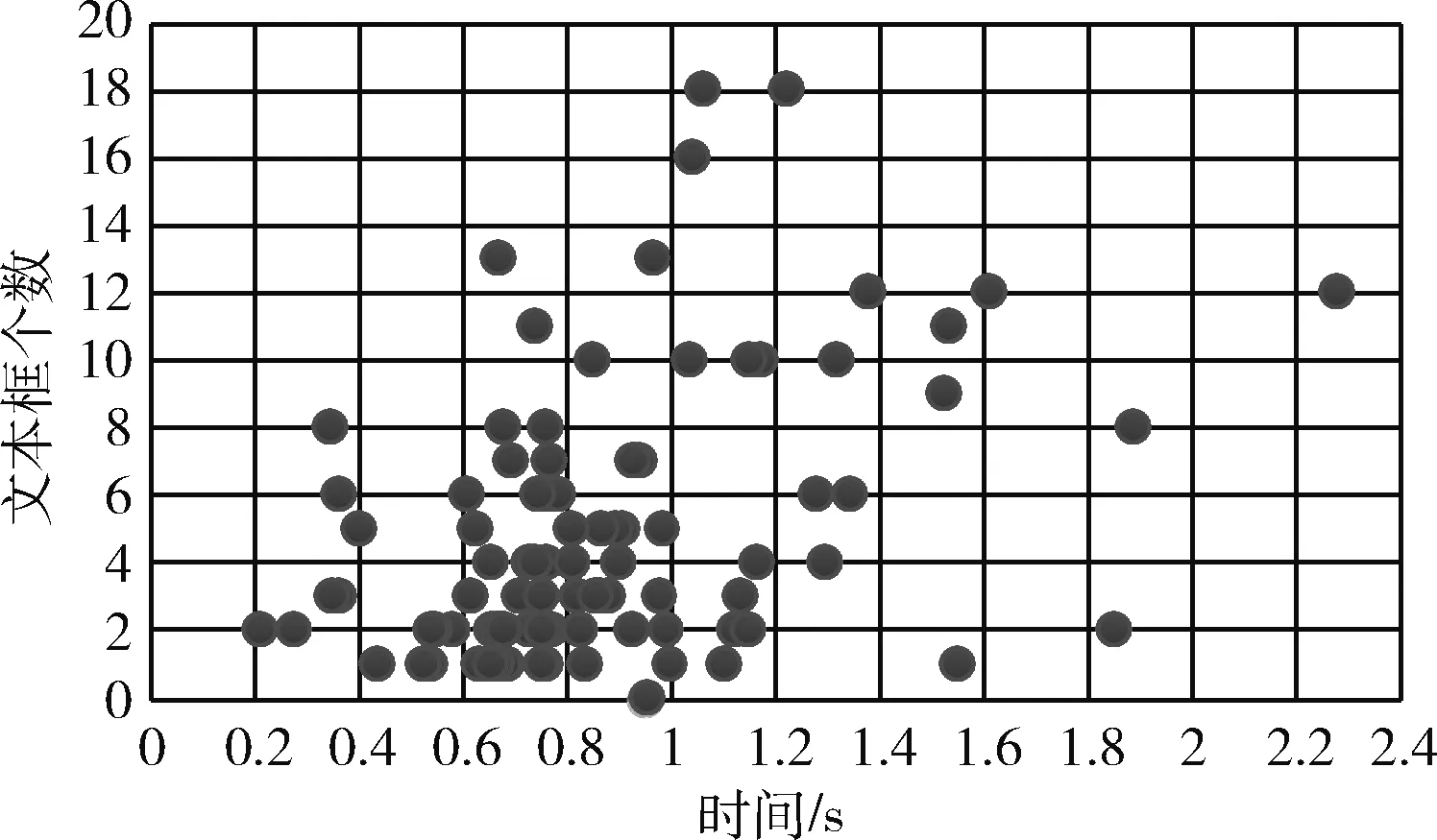
图11所示,在循环层中通过深度双向LSTM结构,对每帧xt预测其特征序列X=x1,…,xt的标签yt。 深度双向LSTM网络可以记忆长段序列输入,本文设置最大时间序列长度T为25,设置xt(1 图11 深度双向LSTM结构 循环层的预测结果标签yt, 通过CRNN顶部的转录层转换为标签序列。CRNN顶部的转录层使用CTC算法计算损失函数,理论上可以简化训练过程从而加快收敛。 CRNN顶部的转录层分为有词典转录和无词典转录;无词典转录模式下,主要通过预测结果标签中概率最大的标签来确定该目标文本的标签;有词典转录模式下,首先定位目标文本,然后通过模糊匹配确定该目标文本的标签。 转录层通过每帧预测结果标签yt来表明标签序列y=y1,…,yt。 并且y=y1,…,yt中的任意结果标签yt∈R|L′|都是集合L′=L∪{blank} 的一个概率分布。首先在序列π∈L′T上定义映射函数B用于去除空标签和重复标签,然后将去除空标签和重复标签的序列π∈L′T写入序列1,就比如序列“--hh-e-l-ll-oo--”经过映射函数B移除空标签和重复标签后变成“hello”。条件概率为将所有序列π∈L′T通过映射函数B映射到序列l的概率之和 (1) 相比于先前的专家学者在自然场景文本识别领域的研究,CRNN文本识别算法具有4种独特的属性: (1)CRNN模型可实现端到端训练。 (2)CRNN模型不需要字符分割,可以自动识别任意长度的文本序列。 (3)CRNN模型在有词典状态和无词典状态均有良好的鲁棒性和准确性。 (4)CRNN模型更适用于自然场景问题中。在IIIT-5K、街景文本和ICDAR数据集中验证了其优越的性能。 1.4.2 CRNN模型文本识别网络框架 CRNN网络详细参数见表2。为了在中文训练和英文训练中更好兼容,调整CRNN模型中后两个MaxPool2d层的stride为2×1,进而增加了特征序列的长度,提高了不同宽度下的字符识别效果。同时为了使网络收敛速度加快,本文在模型第3个卷积层之后加入Batchnorm2d层。 表2 CRNN模型文本识别网络 1.4.3 CRNN模型训练 (1)训练数据集 采用的图像数据集中包含字符6031个,针对包含字符的单张图像,依次进行预处理、模糊处理、灰度处理、部分遮挡处理、背景处理。然后再针对图像中字符本身的特点选择对图像进行拉伸或变换处理。最终生成360万张大小280×32的文本图片,其中每张图片包含10个字符。 (2)模型训练 图12 CRNN模型训练所得验证集精确度和loss值 分析上图可知,随着训练次数的增加模型的准确率逐渐提高,loss值逐渐下降,并呈收敛趋势,表明训练逐渐趋于稳定。 最终利用训练好的CRNN模型进行识别,结果如图13所示。 图13 CRNN模型识别结果 如图14(a)为输入数据,图14(b)为CRNN网络返回的无空格数据,此类数据无法正确分割英文单词,因此本文采用动态规化算法(Viterbi)[9]分隔英文单词。 通过Viterbi找到隐含状态序列,即位于马尔可夫信息源上下文和隐马尔可夫模型(HMM)中生成概率最高的序列维特比路径。 假设HMM中的整个状态空间表示为S(i∈S), 其中状态i初始概率为πi, 从状态i到j的概率表示为ai,j。 观察到的值为y1,y2,…,yt。 通过下面的迭代关系给出产生观察值的最可能状态序列x1,x2,…,xt P1,k=πk-P(y1|k) (2) 式(2)中的P(y1|k) 表示处于隐状态k所对应值y1的产生概率,πk表示k的初始概率 (3) 式(3)中的Pt,k表示在0~t中的最大序列概率值,此时的k为最终状态;然后用参数x的反向指针获得维特比路径。 式(3)所示,Viterbi对于当前状态最佳值的计算依赖于当前状态的 |S| 个值和前一状态的 |S| 个值,总共有T个状态,每个状态需要计算O(|S|2) 次,因此总时间复杂度为O(T×|S|2)。 通过对比图14(a)的输入图片和图14(b)的识别结果,发现识别结果中的英文字符串没有空格,导致难以分割单词从而降低可读性。图14(c)使用Viterbi算法,结果显示英文字符串被分词,由此可证Viterbi算法可以解决英文字符串的分词问题。 图15为文本检测识别系统架构,其中YOLOv3网络负责文字检测模块,CRNN网络负责文字识别模块。 图15 系统架构 文字检测与识别系统为B/S架构,图16所示从Web页面上传图片后先存储到数据库,然后从数据库批量读取待识别图片,并使用文字朝向算法预测角度并旋转,再通过YOLOv3模型将图片中的文字输出为定长的文本框,将这些文本框使用聚类算法连接成一个文本行,之后将文本行送入CRNN模型识别,识别出的结果使用Viterbi分词算法进行分词处理,最后在前端页面展示分词处理结果。 图16 系统前端页面 YOLOv3与CRNN模型在不同的自然场景文本图像识别中均有良好的效果,并且识别速度快,能够满足实际的识别需求。图17为选取100幅场景文本图像在YOLOv3与CRNN模型中进行测试,得到检测时间与文本框个数间的关系。 图17 YOLOv3与CRNN模型文本框检测个数和 检测与识别的时间关系 分析上图得出,在自然场景文本图像检测与识别中,模型在0.7 s内就能检测出大部分文本框,多次实验发现平均在1 s以内就能检测出大部分文本框,因此设定阈值0为1 s,以阈值为标准剔除超过阈值的数据,最终求得平均检测时间为0.4258 s。 基于DenseNet,使用keras框架搭建模型并训练。在GPU环境中运行5个epoch,batch_size取128,实验识别率为97.3%。 经过实验得出DenseNet模型与CTPN检测用时7.934 s,检测与识别共用时12.994 s。DenseNet在训练集中准确率较高,但加入Viterbi分词算法后英文文本的识别准确率会降低,由此可证在DenseNet模型中加入Viterbi算法后会降低其识别准确率。 这里存在一个问题,由于DenseNet模型是用于识别低像素图片,因此采用DenseNet模型,需要首先压缩图片像素,然后再检测识别,这样降低像素的方式如果出现图片中字符较多的情况会导致检测性能下降,从而影响后续的识别效果。 为了进一步分析CTPN与DenseNet模型识别结果,采用与YOLOv3与CRNN模型实验中相同的100幅场景文本图像进行测试,得到CTPN与DenseNet模型文本框个数与识别时间的关系。 图18所示,在自然场景文本图片识别任务中DenseNet与CTPN模型在2 s内可识别出大多数文本框个数,在0.2 s~1.4 s之间识别出的文本框数最多。在1.6 s内基本上能够完成文本框识别,由此给定阈值为1.6 s,以阈值为标准,删除大于阈值的数据,最终求得平均检测识别时间为0.8250 s。 图18 DenseNet与CTPN与文本框检测个数 及检测与识别的时间关系 提出两种检测与识别模型,并设计相关实验,最终得出CRNN与YOLOv3模型的以下特点: (1)检测方面,CTPN模型的检测精度比YOLOv3模型低。具体表现在CTPN模型在大间距字符文本行中检测精度低,而且会出现边缘检测不准确的情况。同时CTPN模型在检测方向上也有限制,只能检测水平方向的文本,而YOLOv3模型在多文字朝向检测场景中仍然保持很好的检测效果。 (2)识别方面,CRNN模型在中英文混合的自然场景中识别准确率比DenseNet模型高,说明CRNN模型有较强的鲁棒性;而且DenseNet模型只能读取低分辨率图片,一旦图片中字符数量增多时识别准确率就会降低,这就导致最终识别准确率降低。 (3)检测与识别速度方面,通过在相同数据集上测试。表3为相同的实验环境和场景文本数据集中,CTPN与DenseNet模型和YOLOv3与CRNN模型检测与识别时间对比,实验结果表明CRNN模型与YOLOv3的检测与识别速度明显优于CTPN与DenseNet模型。 表3 CTPN与DenseNet模型和YOLOv3与 CRNN模型检测与识别时间对比/s 综上所述,通过对比两种模型的识别结果得出,在自然场景中的中英文文本图像检测与识别任务中,YOLOv3与CRNN模型不论是检测与识别准确率和检测与识别速度方面都具有显著的优势。 为了提升现有的自然场景图片文本检测与识别技术,本文提出使用CRNN与YOLOv3模型进行自然场景下的文本检测识别,实验采用文字朝向检测算法和小角度估算函数提升了文字朝向检测算法的准确率,并使用YOLOv3和文本框聚类算法确定待识别文本行,最终使用CRNN识别文本。相比较传统的DenseNet与CTPN模型,CRNN与YOLOv3模型的识别准确率和识别效率都最优。 虽提升了自然场景文本的识别准确率和识别效率,但仍有不足之处需要更深入探究,具体如下: (1)由于中文数据集中缺少繁体字,手写体及弯曲文本,导致CRNN模型对这类中文字体识别准确率低,从而降低了整体识别准确率,接下来将在数据集中补充这类中文字体。 (2)在模糊图像中的识别准确率较低,可以尝试对模糊图像进行增强处理,或许可以提高识别准确率。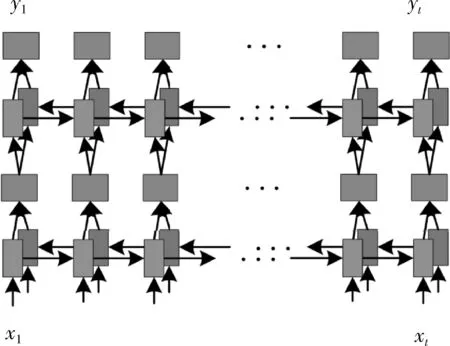
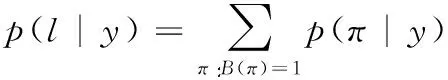
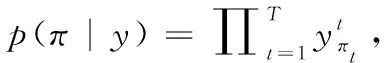

1.5 Viterbi分词算法
2 检测与识别系统框架
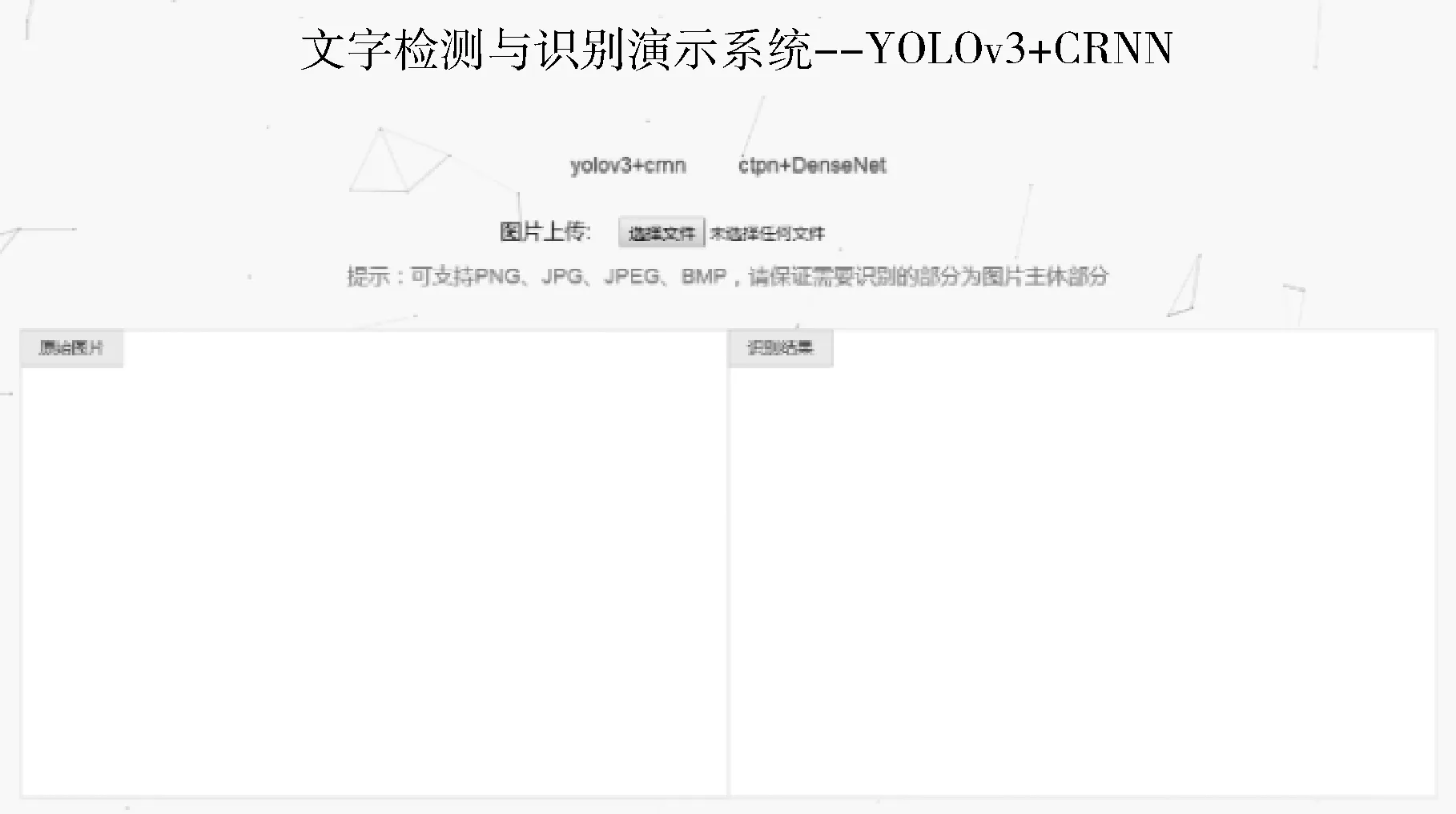
3 识别结果对比分析
3.1 YOLOv3与CRNN模型识别结果
3.2 CTPN与DenseNet模型识别结果
3.3 两种模型识别结果对比分析

4 结束语
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电脑爱好者(2020年22期)2020-11-20
电脑爱好者(2019年10期)2019-10-30
车迷(2018年11期)2018-08-30
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2018年3期)2018-05-09
电脑爱好者(2016年23期)2017-01-05
Coco薇(2015年11期)2015-11-09
